Conjunto dataset referência para avaliação
Conjuntos de dados de avaliação no MLflow definem os dados de teste estruturados usados para avaliar seu aplicativo GenAI: inputs, verdade fundamental opcional expectations e campos de linhagem, como origem e tags. Esta página documenta o esquema do dataset e links para os métodos e classes do SDK mais frequentemente usados.
Para informações gerais e exemplos de como usar conjuntos de dados de avaliação, consulte Avalie aplicativos GenAI durante o desenvolvimento.
Esquema dataset de avaliação
O conjunto de dados de avaliação deve usar o esquema descrito nesta seção.
Campos principais
Os seguintes campos são usados tanto na abstração dataset de avaliação quanto se você passar os dados diretamente.
Coluna | Tipo de dados | Descrição | Obrigatório |
|---|---|---|---|
|
| Entradas para o seu aplicativo (por exemplo, pergunta do usuário, contexto), armazenadas como um JSON-seralizável | Sim |
|
| O rótulo da verdade fundamental, armazenado como um JSON-seralizable | Opcional |
expectations chave reservada
expectations tem várias chaves reservadas que são usadas por juízes LLM integrados: guidelines, expected_facts e expected_response.
campo | Usado por | Descrição |
|---|---|---|
|
| Lista de fatos que devem aparecer |
|
| Saída esperada exata ou similar |
|
| Regras de linguagem natural a serem seguidas |
|
| Documentos que devem ser recuperados |
Campos adicionais
Os seguintes campos são usados pela abstração dataset de avaliação para rastrear a linhagem e o histórico de versões.
Coluna | Tipo de dados | Descrição | Obrigatório |
|---|---|---|---|
| string | O identificador exclusivo do registro. | Definido automaticamente se não for fornecido. |
| carimbo de data/hora | A hora em que o registro foi criado. | Definido automaticamente ao inserir ou atualizar. |
| string | O usuário que criou o registro. | Definido automaticamente ao inserir ou atualizar. |
| carimbo de data/hora | A hora em que o registro foi atualizado pela última vez. | Definido automaticamente ao inserir ou atualizar. |
| string | O usuário que atualizou o registro pela última vez. | Definido automaticamente ao inserir ou atualizar. |
| struct | A fonte do registro dataset . Consulte o campo Origem. | Opcional |
| dict [str, Qualquer] | tags de valor-chave para o registro dataset. | Opcional |
Campo de origem
O campo source rastreia a origem de um registro dataset . Cada registro pode ter apenas um tipo de origem.
Fonte humana : Registro criado manualmente por uma pessoa.
{
"source": {
"human": {
"user_name": "jane.doe@company.com" # user who created the record
}
}
}
Fonte do documento : Registro sintetizado a partir de um documento
{
"source": {
"document": {
"doc_uri": "s3://bucket/docs/product-manual.pdf", # URI or path to the source document
"content": "The first 500 chars of the document..." # Optional, excerpt or full content from the document
}
}
}
Origem do rastreamento : Registro criado a partir de um rastreamento de produção
{
"source": {
"trace": {
"trace_id": "tr-abc123def456". # unique identifier of the source trace
}
}
}
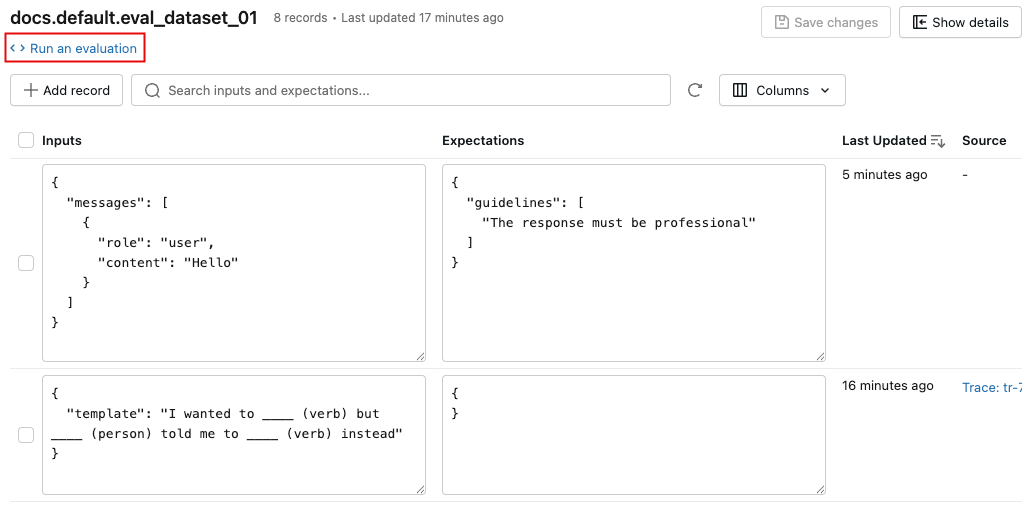
Interface do usuário dataset de avaliação MLflow
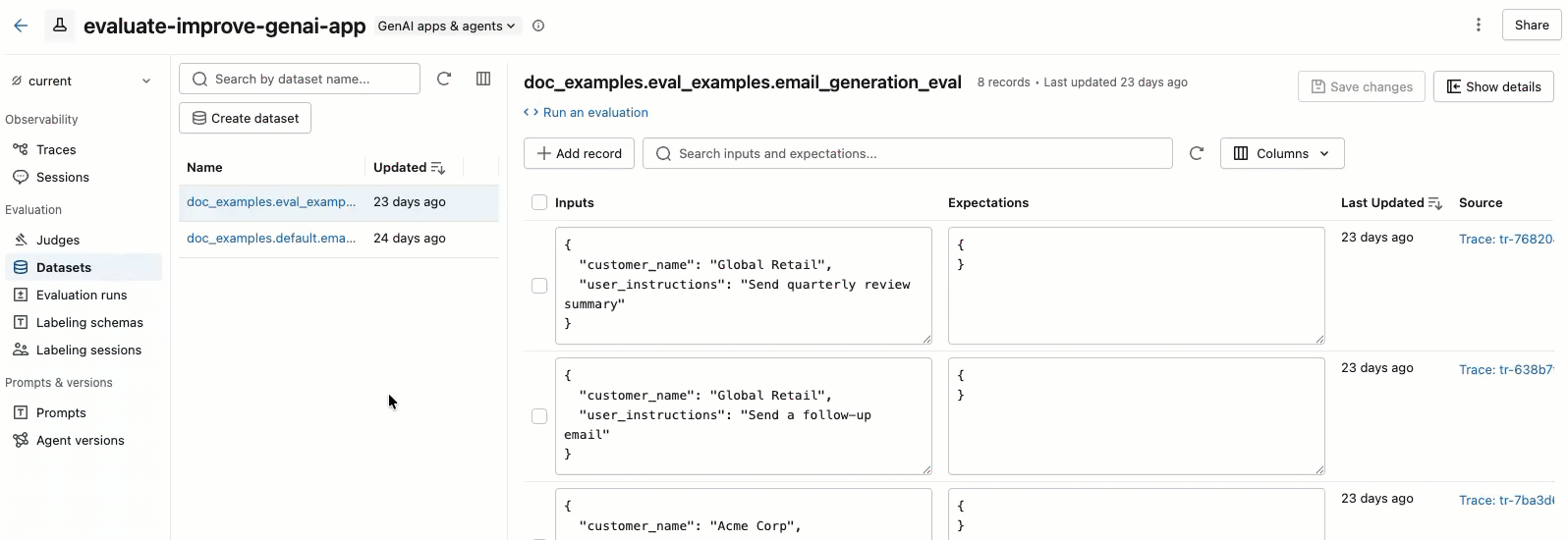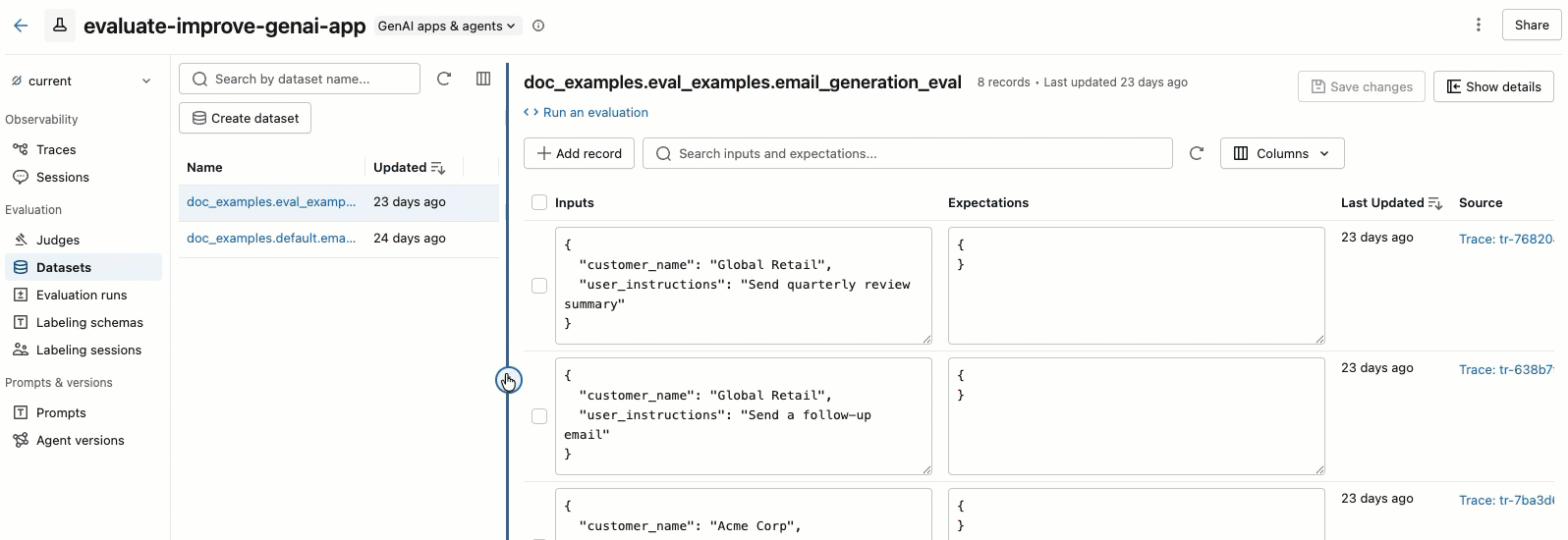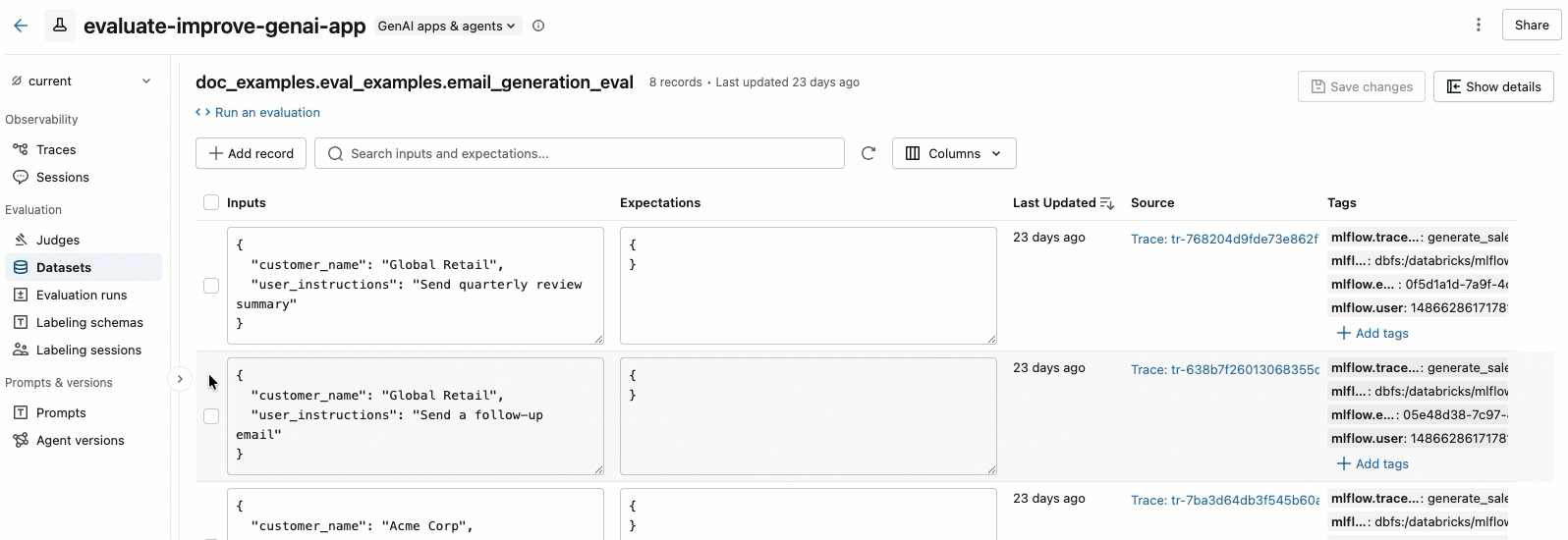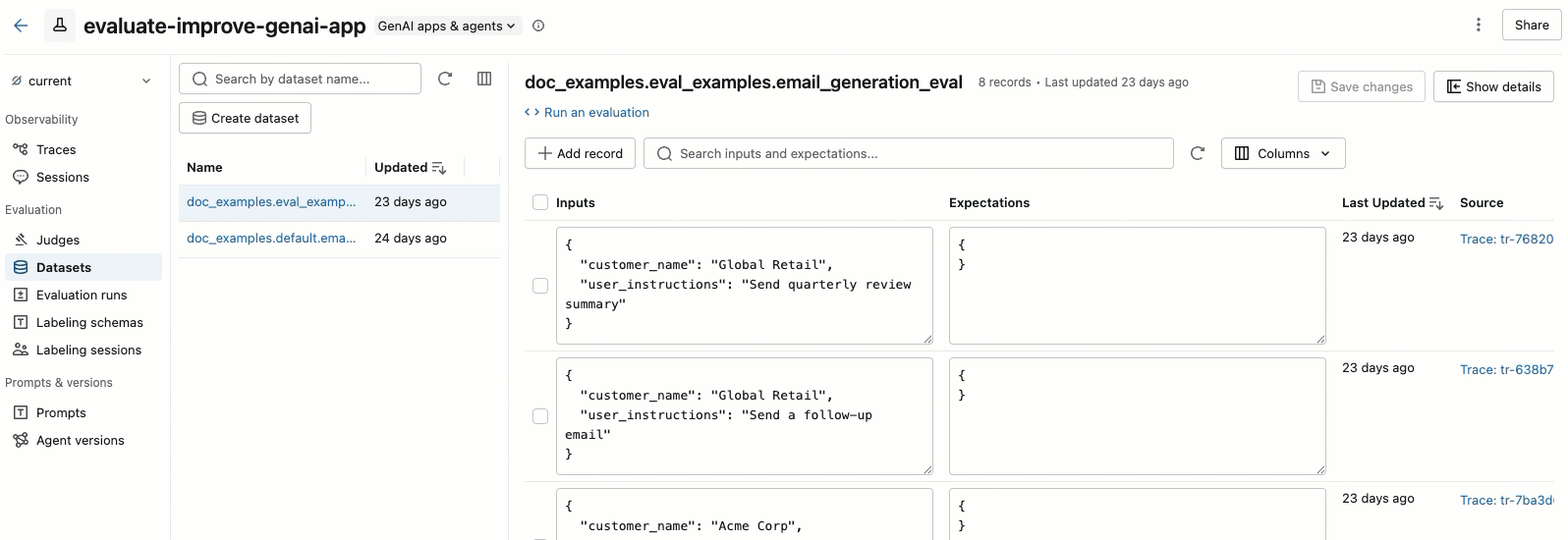
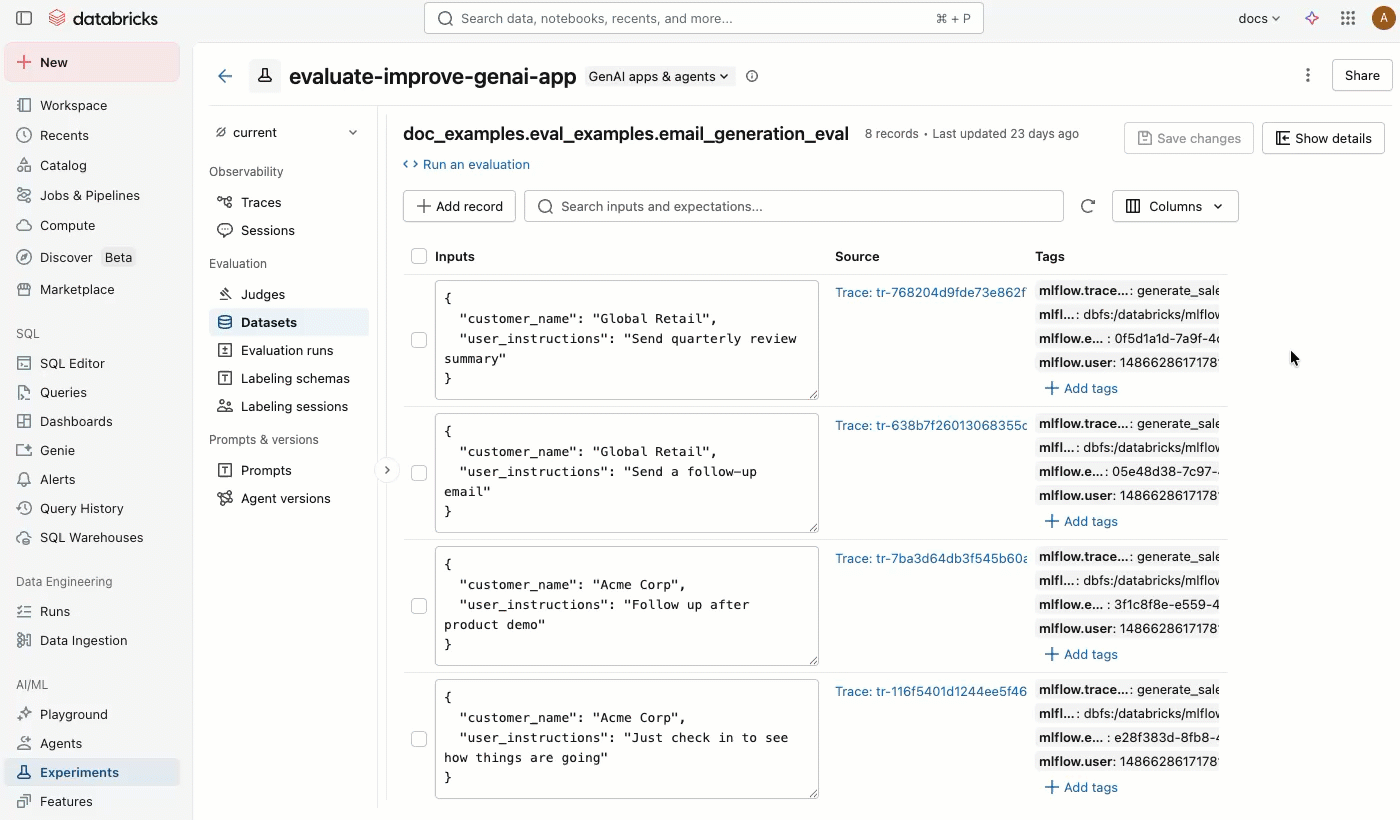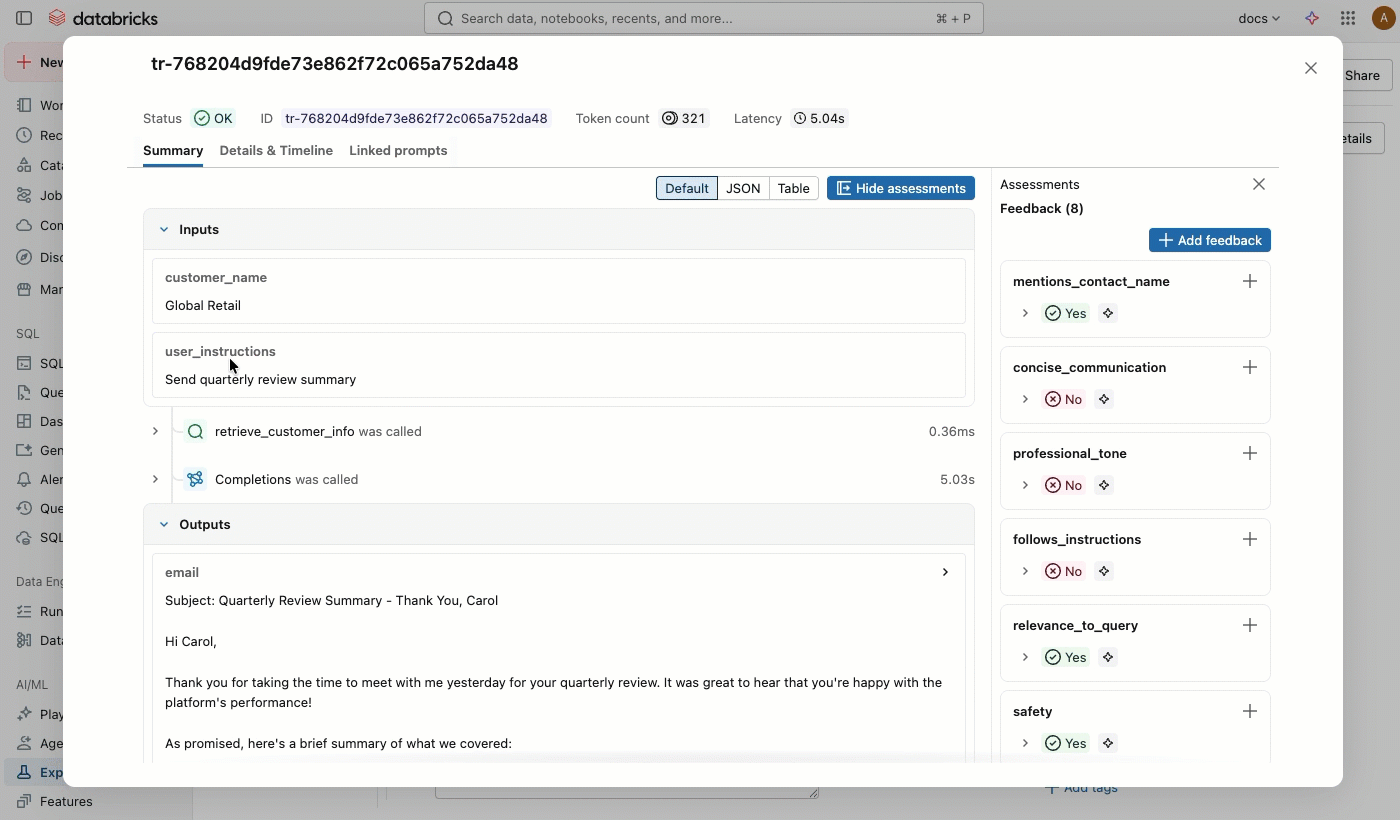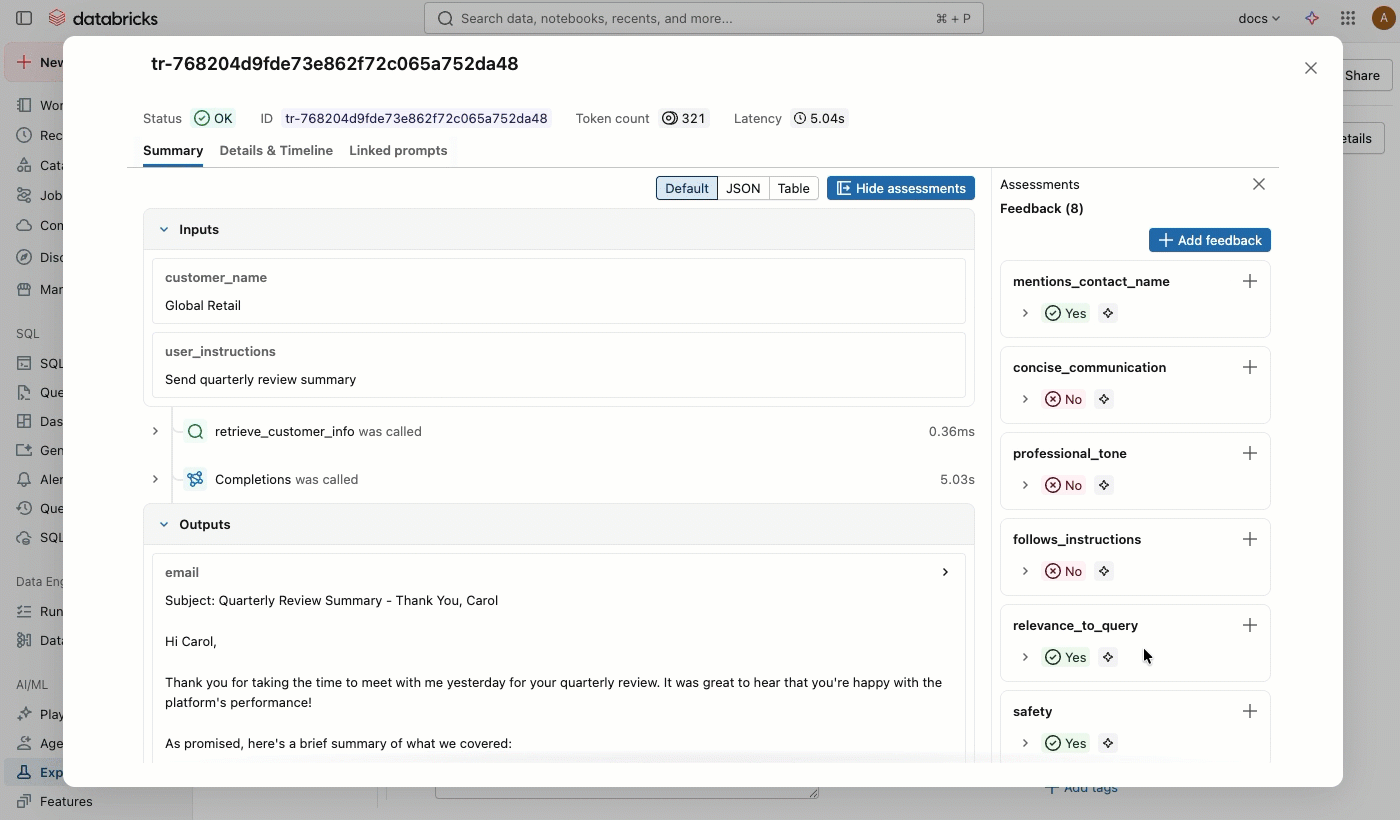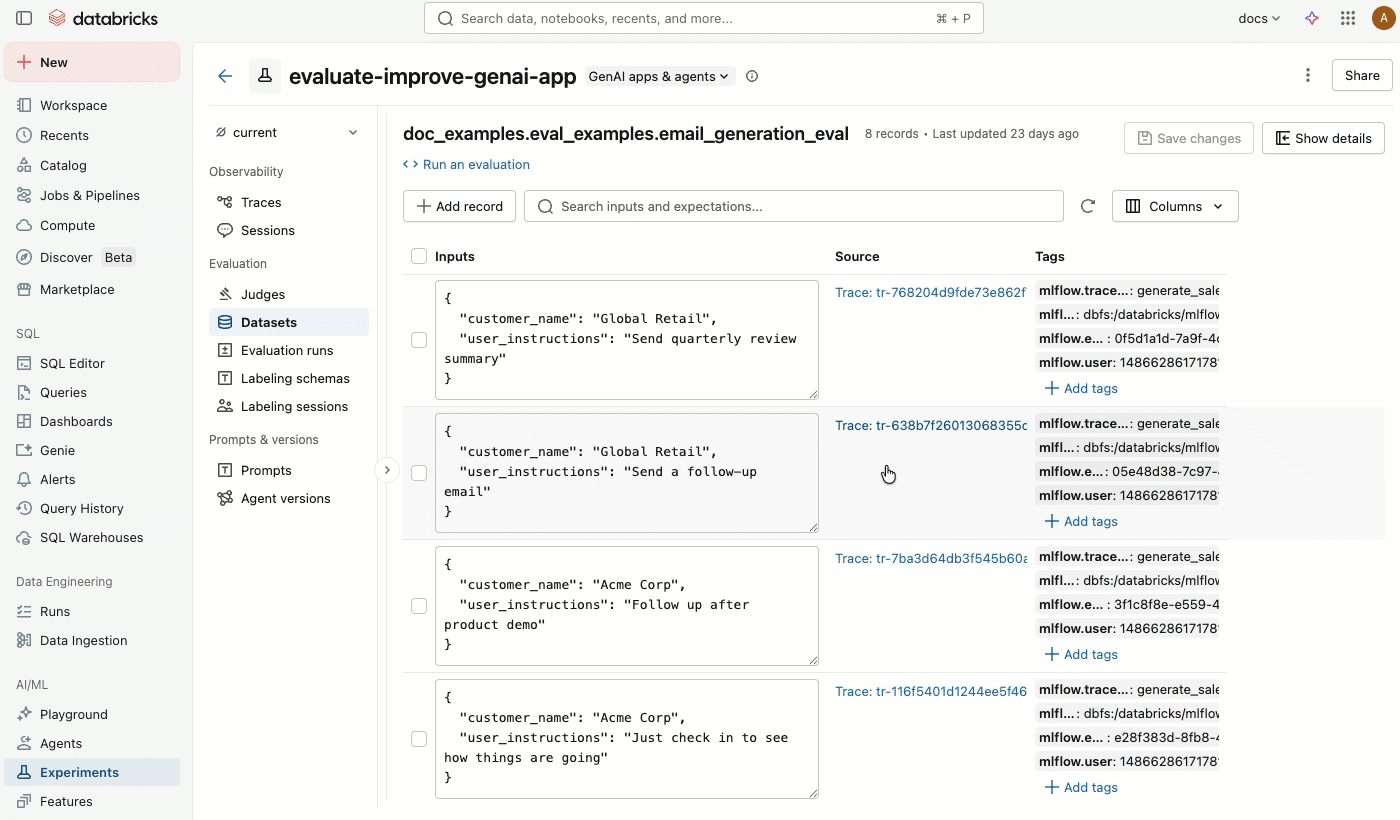
A tab Conjunto de dados" na página de experimentos MLflow fornece uma interface visual para gerenciar seu conjunto de dados de avaliação e seus registros. A página utiliza um layout de painel dividido: o painel esquerdo lista todos os conjuntos de dados de avaliação associados ao experimento, e o painel direito mostra os registros do dataset selecionado. Você pode pesquisar, classificar, criar, editar e excluir conjuntos de dados e registros diretamente da interface do usuário, sem escrever nenhum código.
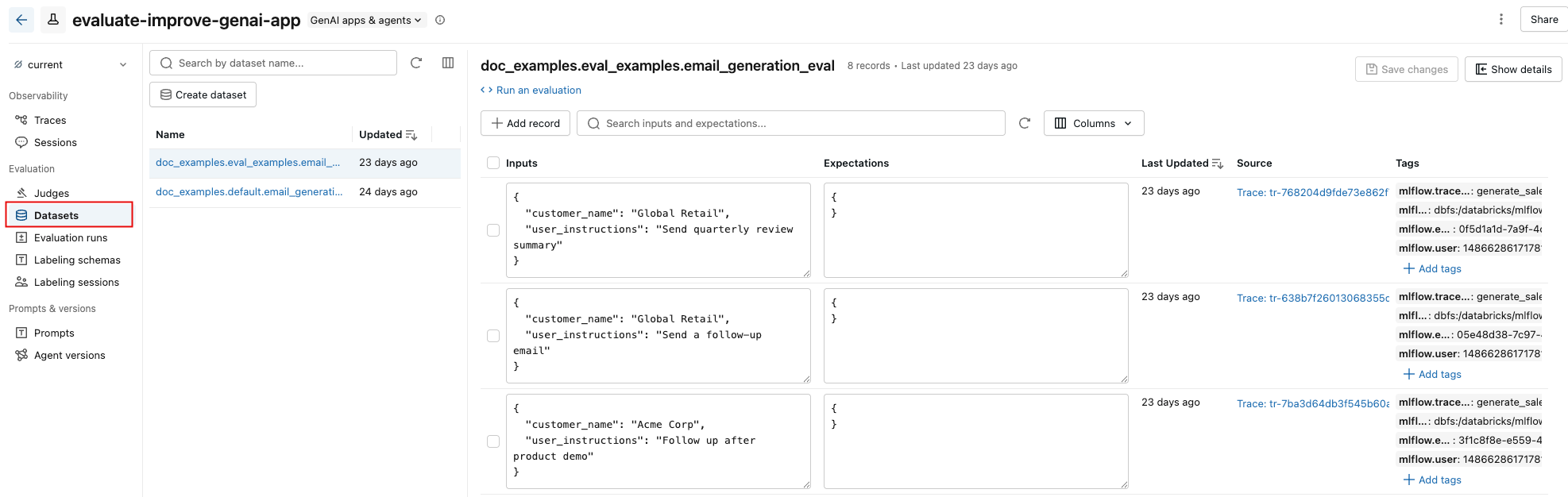
No painel direito, você pode editar as entradas e expectativas dos registros diretamente no arquivo, adicionar tags a registros individuais, view o rastreamento de origem para registros criados a partir de rastreamentos de produção e obter um trecho de código Python pronto para uso para executar uma avaliação no dataset.
Visão geral da interface do usuário dataset de avaliação
-
Na barra lateral, clique em Experimentos e abra seu experimento.
-
Clique na tab do conjunto de dados . O painel esquerdo mostra todos os dados de avaliação para este experimento. Por default, os conjuntos de dados são classificados pela data da última atualização. Utilize a barra de pesquisa para filtrar por nome dataset .
-
Clique no nome de um dataset para view seus registros no painel direito. Você pode precisar rolar a tela para a direita e para a esquerda para view todas as colunas.
-
Para ampliar o painel direito, passe o cursor sobre o separador de painéis e clique na seta apontando para a esquerda. Clique na seta novamente para retornar à view default .
-
Para selecionar as colunas que aparecem, clique no botão Colunas . Selecione ou desmarque as caixas de seleção. Quando terminar, clique em qualquer lugar do menu suspenso.

Criar um datasetde avaliação
-
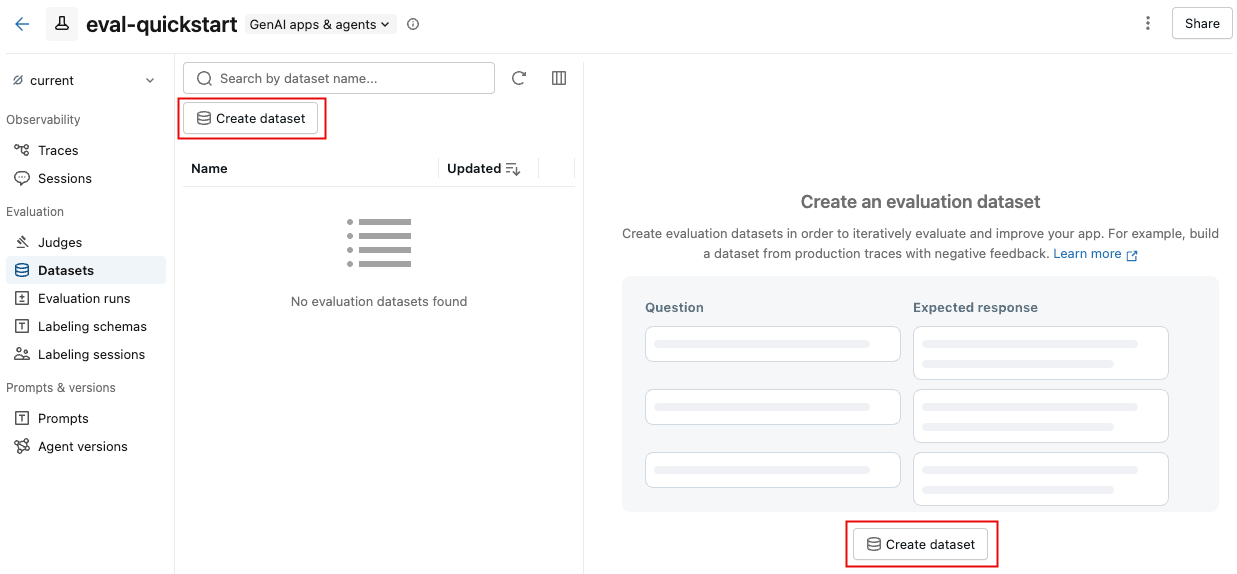
Na tab de dados , clique em Criar dataset .
-
Na caixa de diálogo, clique em Selecionar esquema para escolher um esquema Unity Catalog onde você tenha permissões
CREATE TABLE. -
Insira um nome de tabela para o dataset. Uma pré-visualização do nome completo dataset (
catalog.schema.table_name) aparece abaixo da entrada. -
Clique em Criar conjunto de dados .
Adicionar registros dataset
Para adicionar rastreamentos existentes a um dataset de avaliação, consulte Criar um dataset usando a interface do usuário.
Editar registros dataset
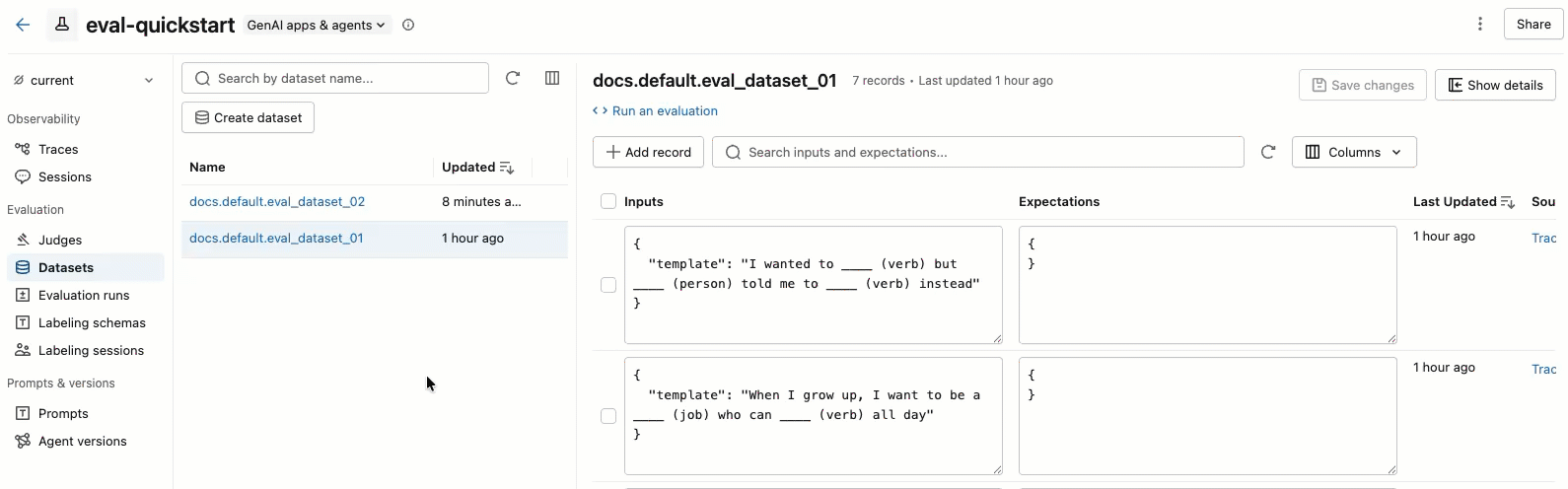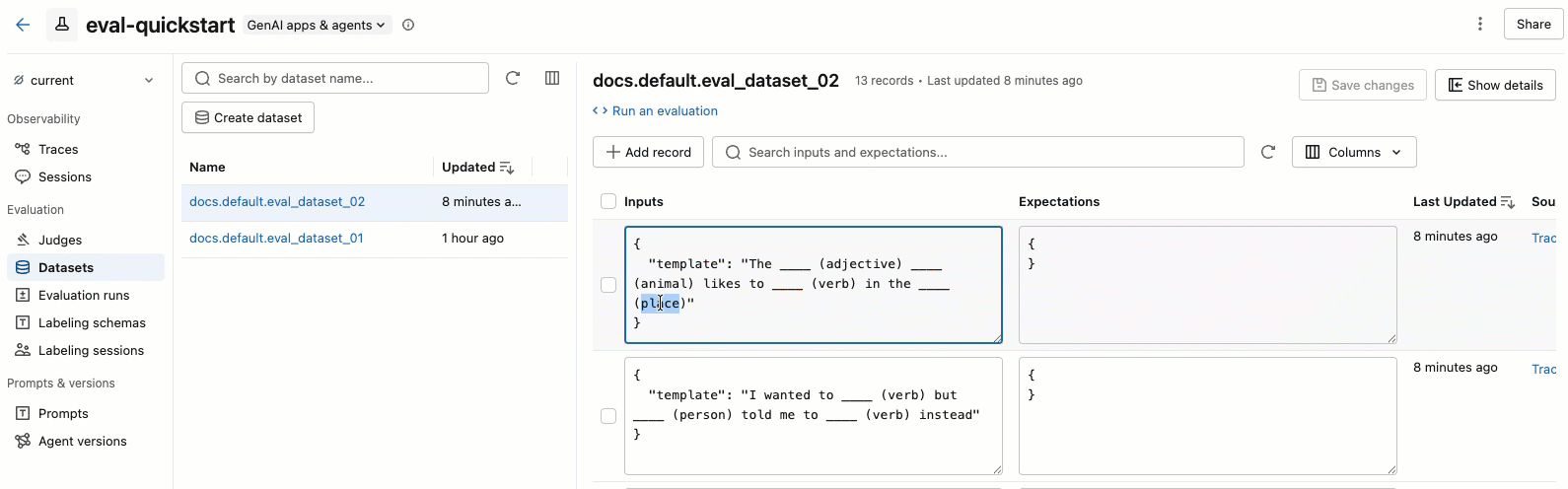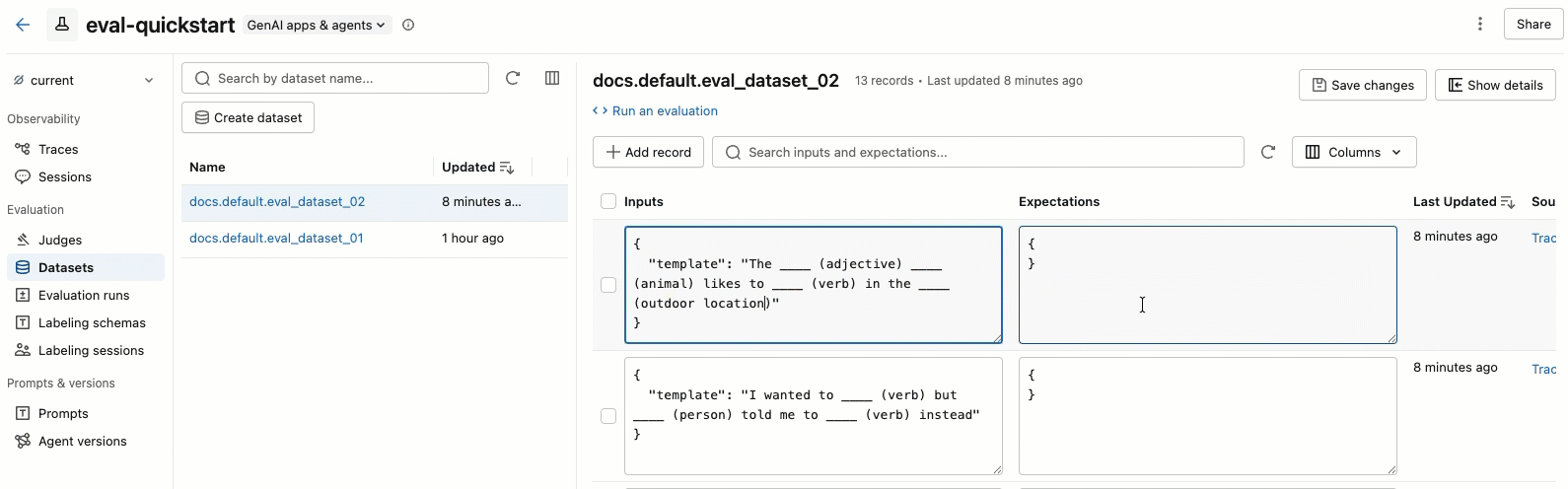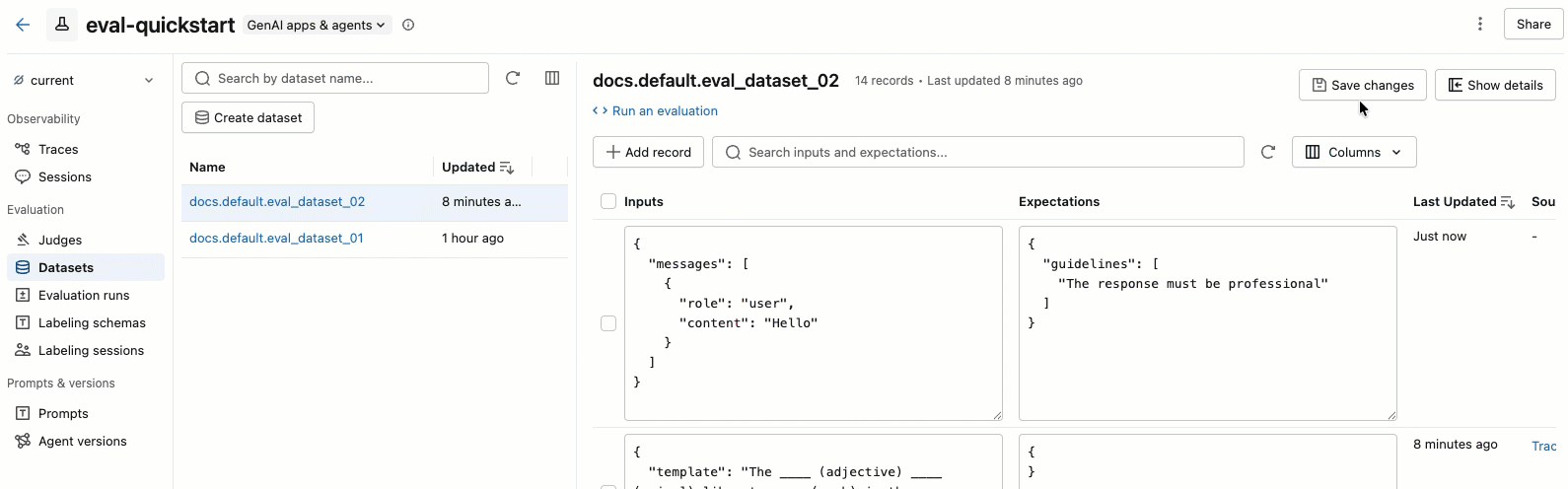
O vídeo mostra os seguintes passos:
- Selecione um dataset no painel esquerdo para view seus registros.
- Você pode editar os campos Entradas e Expectativas diretamente na tabela. Esses campos aceitam JSON e validam sua entrada enquanto você digita.
- Para adicionar uma nova linha, clique em Adicionar registro . Uma nova linha com valores default aparece no topo da tabela.
- Para salvar todas as alterações pendentes, clique em Salvar alterações no canto superior direito.
Excluir registros ou conjunto de dados
- Para excluir registros, use as caixas de seleção para selecionar um ou mais registros e clique em Excluir (N) .
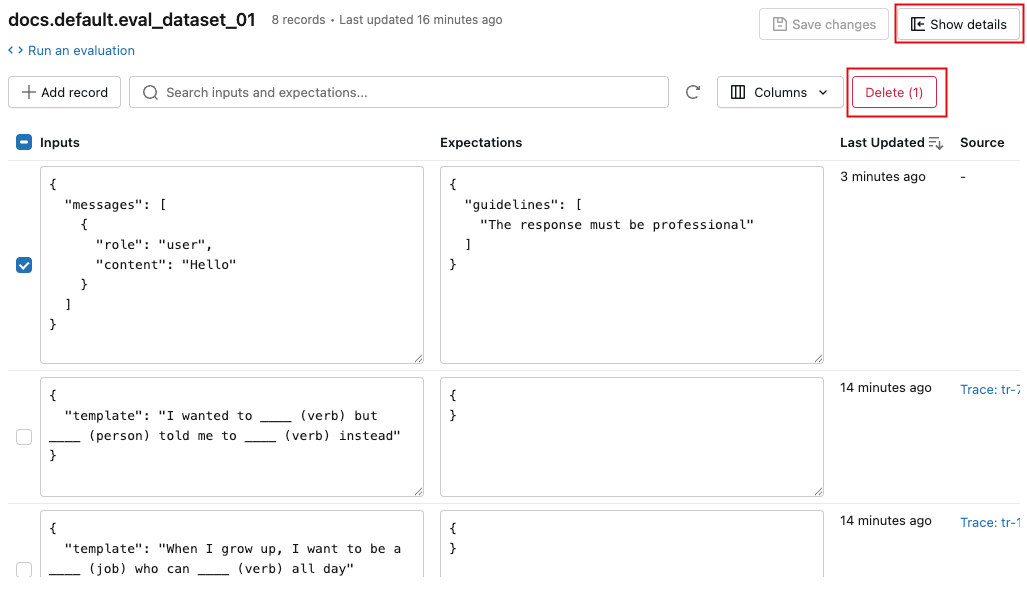
- Para excluir um dataset, clique em Mostrar detalhes para abrir o painel de detalhes e, em seguida, clique em Excluir dataset na parte inferior do painel. Você também pode excluir um dataset do menu kebab.
 na lista dataset .
na lista dataset .
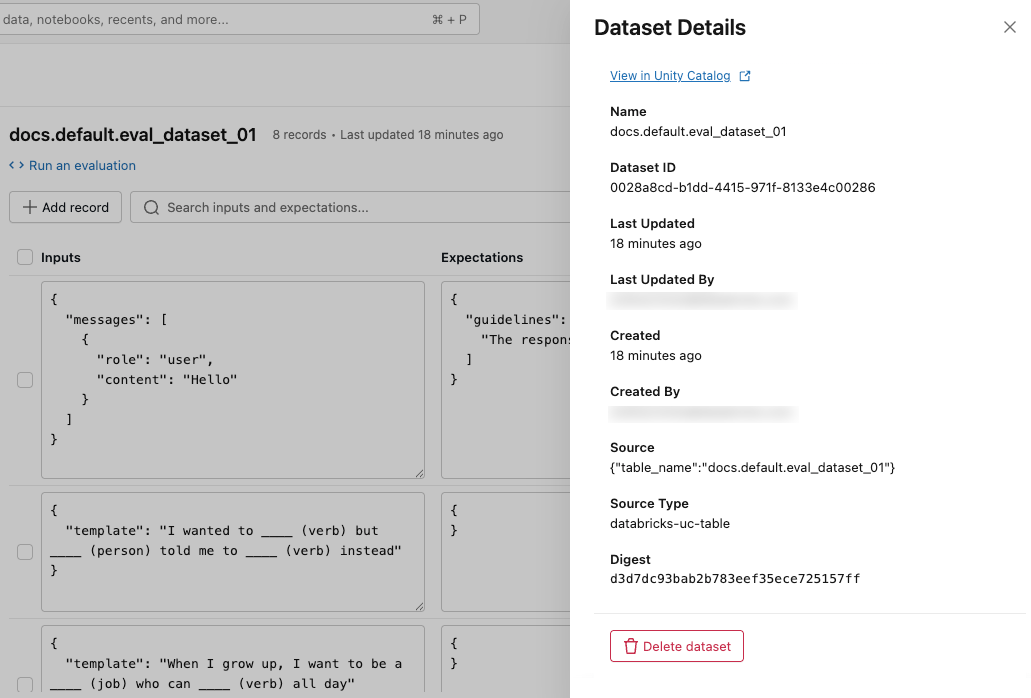
Ver detalhes dataset
Para view os metadados do dataset, clique em Mostrar detalhes no canto superior direito. Um painel é aberto, incluindo o nome dataset , ID, data de criação, última atualização, fonte e um link para view o dataset no Unity Catalog.
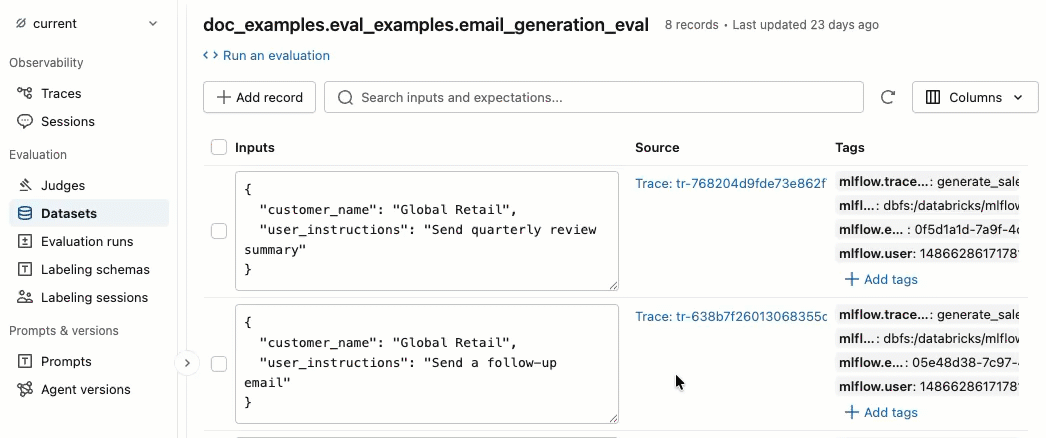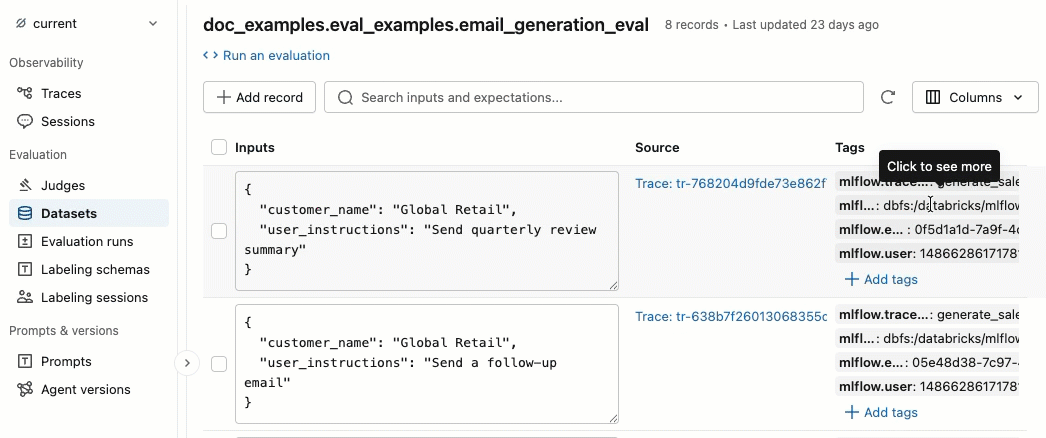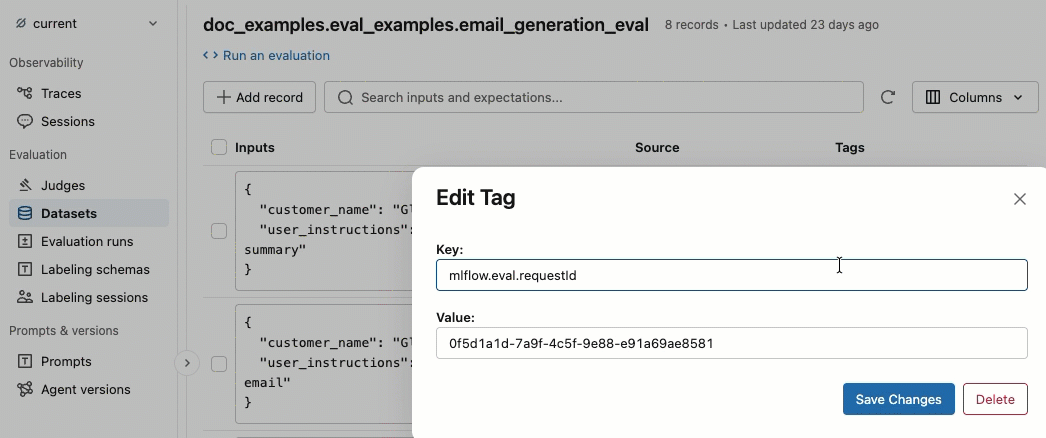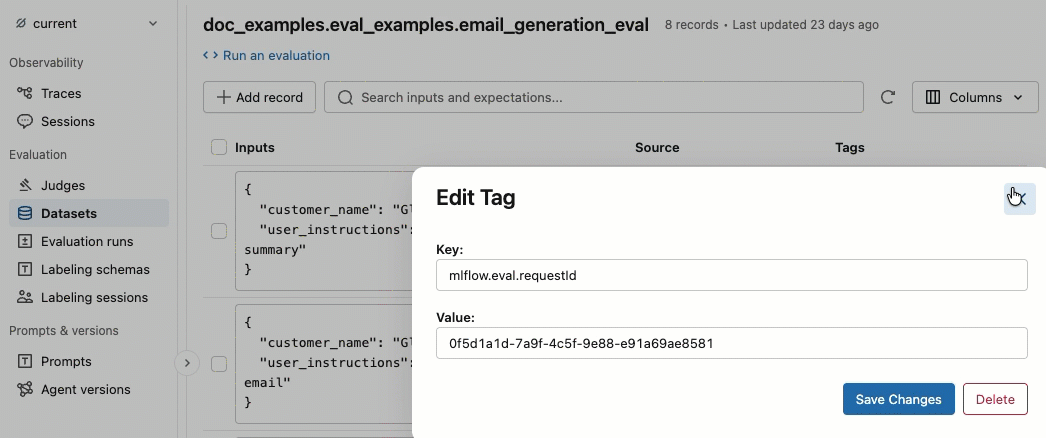
Adicionar e excluir tags
Na coluna de etiquetas , clique em uma tag para editá-la ou clique em Adicionar tags para adicionar uma nova tag.
visualizar rastreamento de origem
Na coluna Origem , clique no rastreamento para abrir uma janela interativa que mostra o rastreamento completo e as avaliações.
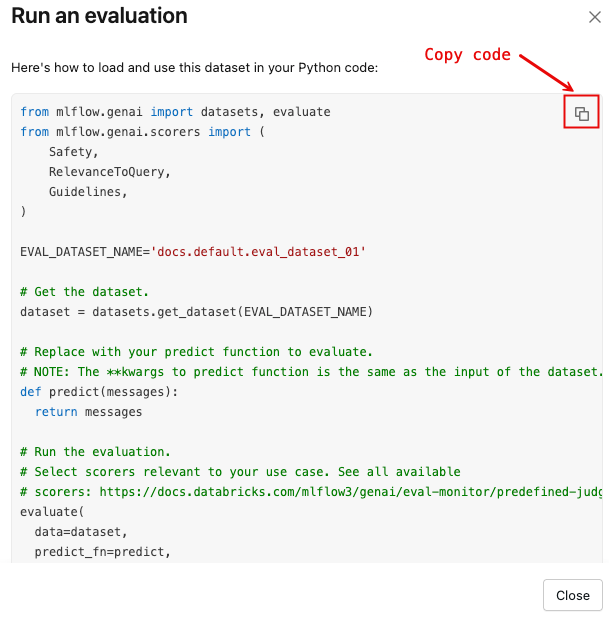
execução de uma avaliação usando o dataset
Para abrir uma caixa de diálogo com um código Python padrão que carrega o dataset e executa mlflow.genai.evaluate() com um conjunto default de avaliadores:
-
Clique em executar uma avaliação .
-
Clique no ícone de copiar, mostrado na imagem a seguir, para copiar o trecho para a sua área de transferência.
Referência SDK dataset de avaliaçãoMLflow
O SDK do conjunto de dados de avaliação fornece acesso programático para criar, gerenciar e usar conjuntos de dados para avaliação do aplicativo GenAI. Para obter detalhes, consulte a referência da API: mlflow.genai.datasets. Alguns dos métodos e classes mais frequentemente utilizados são os seguintes:
mlflow.genai.datasets.create_datasetmlflow.genai.datasets.get_datasetmlflow.genai.datasets.delete_datasetEvaluationDataset. Esta classe fornece métodos para interagir e modificar conjuntos de dados de avaliação.