Referência do avaliador baseado em código
Defina avaliadores personalizados baseados em código no MLflow usando o decorador @scorer ou a classe Scorer. Esta referência abrange suas assinaturas de função e classe, entradas, saídas, nomeação de métricas, tratamento de erros e como acessar segredos.
@scorer decorador
A maioria dos avaliadores baseados em código deve ser definida usando o decorador@scorer. A assinatura desses marcadores é a seguinte:
from mlflow.genai.scorers import scorer
from typing import Optional, Any
from mlflow.entities import Feedback
@scorer
def my_custom_scorer(
*, # All arguments are keyword-only
inputs: Optional[dict[str, Any]], # App's raw input, a dictionary of input argument names and values
outputs: Optional[Any], # App's raw output
expectations: Optional[dict[str, Any]], # Ground truth, a dictionary of label names and values
trace: Optional[mlflow.entities.Trace] # Complete trace with all spans and metadata
) -> Union[int, float, bool, str, Feedback, List[Feedback]]:
# Your evaluation logic here
Para obter mais flexibilidade do que o decorador @scorer permite, defina os avaliadores usando a classeScorer.
Entradas
Os avaliadores recebem o rastreamento completo do MLflow, contendo todos os spans, atributos e saídas. O MLflow também extrai dados comumente necessários e os passa como argumentos nomeados. Todos os argumentos de entrada são opcionais, portanto, declare apenas o que o seu avaliador precisa:
inputsA solicitação enviada ao seu aplicativo (por exemplo, consulta do usuário, contexto).outputsA resposta do seu aplicativo (por exemplo, texto gerado, chamadas de ferramentas).expectationsVerdade fundamental ou rótulo (por exemplo, resposta esperada, diretrizes).traceO rastreamento completo MLflow incluindo todos os spans, permite a análise de etapas intermediárias, latência, uso de ferramentas e muito mais. O rastreamento é passado para o avaliador personalizado como uma classemlflow.entities.traceinstanciada.
Ao executar mlflow.genai.evaluate(), os parâmetros inputs, outputs e expectations podem ser especificados no argumento data ou analisados a partir do rastreamento.
Os avaliadores registrados para monitoramento de produção sempre analisam os parâmetros inputs e outputs do rastreamento. expectations não está disponível.
Saídas
Os avaliadores podem retornar diferentes tipos de valores simples ou objetos de feedback mais complexos, dependendo das suas necessidades de avaliação.
Tipo de retorno | Exibição da interface do usuário do MLflow | Caso de uso |
|---|---|---|
| Aprovado/Reprovado | Avaliação binária |
| verdadeiro/falso | Verificações Boolean |
| Valor numérico | Pontuações, contagens |
Valor + justificativa | Avaliação detalhada | |
| Múltiplas métricas | Avaliação multiaspecto |
Valores simples
Valores simples são usados para avaliações diretas de aprovação/reprovação ou numéricas. Os exemplos a seguir mostram avaliadores simples para um aplicativo AI que retorna uma string como resposta.
@scorer
def response_length(outputs: str) -> int:
# Return a numeric metric
return len(outputs.split())
@scorer
def contains_citation(outputs: str) -> str:
# Return pass/fail string
return "yes" if "[source]" in outputs else "no"
Feedback valioso
Retorna um objeto Feedback ou uma lista de objetos Feedback para avaliações detalhadas com pontuações, justificativas e metadados.
from mlflow.entities import Feedback, AssessmentSource
@scorer
def content_quality(outputs):
return Feedback(
value=0.85, # Can be numeric, boolean, string, or other types
rationale="Clear and accurate, minor grammar issues",
# Optional: source of the assessment. Several source types are supported,
# such as "HUMAN", "CODE", "LLM_JUDGE".
source=AssessmentSource(
source_type="HUMAN",
source_id="grammar_checker_v1"
),
# Optional: additional metadata about the assessment.
metadata={
"annotator": "me@example.com",
}
)
Vários objetos de feedback podem ser retornados como uma lista. Cada feedback deve ter o campo name especificado, e esses nomes são exibidos como métricas separadas nos resultados da avaliação.
@scorer
def comprehensive_check(inputs, outputs):
return [
Feedback(name="relevance", value=True, rationale="Directly addresses query"),
Feedback(name="tone", value="professional", rationale="Appropriate for audience"),
Feedback(name="length", value=150, rationale="Word count within limits")
]
Comportamento de nomenclatura de métricas
Ao definir os marcadores, use nomes claros e consistentes que indiquem a finalidade de cada um. Esses nomes aparecem como nomes de métricas nos seus resultados de avaliação e monitoramento e nos painéis de controle. Siga as convenções de nomenclatura do MLflow, como safety_check ou relevance_monitor.
Ao definir os avaliadores usando o decorador @scorer ou a classeScorer, os nomes das métricas na execução da avaliação criada por `evaluation` e `monitoring` seguem estas regras:
- Se o avaliador retornar um ou mais objetos
Feedback, os camposFeedback.nameterão precedência, se especificados. - Para valores de retorno primitivos ou
Feedbacks sem nome, o nome da função (para o decorador@scorer) ou o campoScorer.name(para a classeScorer) é usado.
A tabela a seguir resume o comportamento da nomenclatura das métricas:
Valor de retorno |
|
|
|---|---|---|
Valor primitivo ( | Nome da função |
|
Feedback sem nome | Nome da função |
|
Feedback com nome |
|
|
|
|
|
Para fins de avaliação e monitoramento, todas as métricas devem ter nomes distintos. Se um avaliador retornar List[Feedback], então cada Feedback no List deve ter um nome distinto.
Para exemplos de comportamento de nomenclatura, consulte Convenções de nomenclatura em sistemas de pontuação.
Acesse os segredos dos marcadores de pontuação
Os avaliadores personalizados podem acessar os segredosDatabricks para usar com segurança a chave API e as credenciais. Isso é útil ao integrar serviços externos, como endpoints LLM personalizados que exigem autenticação, como Azure OpenAI, AWS Bedrock e outros. Essa abordagem funciona tanto para avaliação do desenvolvimento quanto para monitoramento da produção.
Por default, dbutils não está disponível no ambiente de tempo de execução do avaliador. Para acessar segredos no ambiente de tempo de execução do scorer, chame from databricks.sdk.runtime import dbutils de dentro da função scorer.
O exemplo a seguir mostra como acessar um segredo em um avaliador personalizado:
import mlflow
from mlflow.genai.scorers import scorer, ScorerSamplingConfig
from mlflow.entities import Trace, Feedback
@scorer
def custom_llm_scorer(trace: Trace) -> Feedback:
# Explicitly import dbutils to access secrets
from databricks.sdk.runtime import dbutils
# Retrieve your API key from Databricks secrets
api_key = dbutils.secrets.get(scope='my-scope', key='api-key')
# Use the API key to call your custom LLM endpoint
# ... your custom evaluation logic here ...
return Feedback(
value="yes",
rationale="Evaluation completed using custom endpoint"
)
# Register and start the scorer
custom_llm_scorer.register()
custom_llm_scorer.start(sampling_config = ScorerSamplingConfig(sample_rate=1))
Tratamento de erros
Quando um avaliador encontra um erro em um rastreamento, o MLflow pode capturar os detalhes do erro para esse rastreamento e, em seguida, continuar a execução normalmente. Para capturar detalhes de erros, o MLflow oferece duas abordagens:
- Permita que as exceções se propaguem (recomendado) para que o MLflow possa capturar as mensagens de erro para você.
- Trate as exceções explicitamente.
Permitir que as exceções se propaguem (recomendado)
A abordagem mais simples é deixar que as exceções sejam lançadas naturalmente. O MLflow captura automaticamente a exceção e cria um objeto Feedback com os seguintes detalhes do erro:
value:NoneerrorDetalhes da exceção, como objeto de exceção, mensagem de erro e rastreamento da pilha de chamadas.
As informações sobre o erro são exibidas nos resultados da avaliação. Abra a linha correspondente para ver os detalhes do erro.
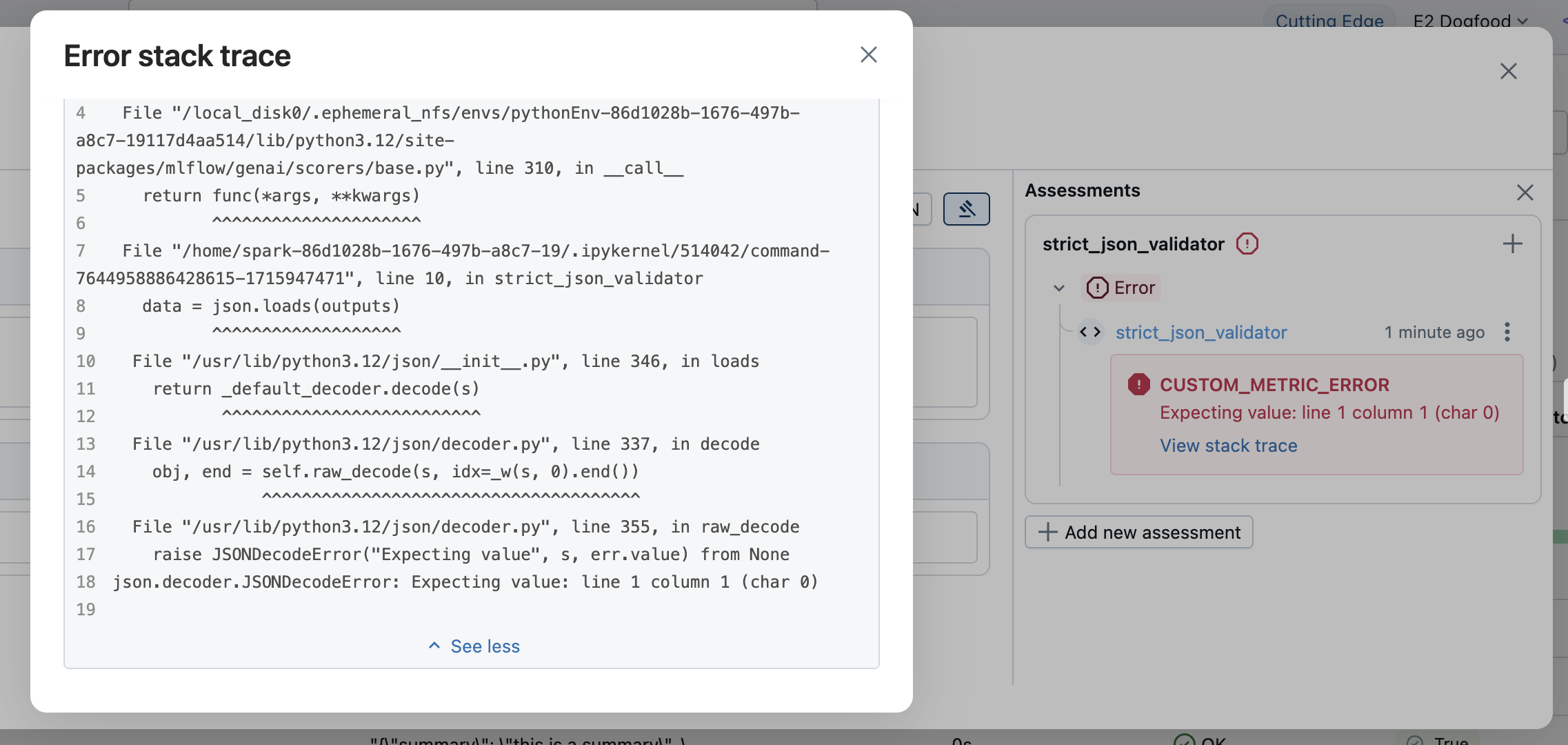
Trate as exceções explicitamente.
Para tratamento personalizado de erros ou para fornecer mensagens de erro específicas, capture exceções e retorne um Feedback com valor None e detalhes do erro:
from mlflow.entities import AssessmentError, Feedback
@scorer
def is_valid_response(outputs):
import json
try:
data = json.loads(outputs)
required_fields = ["summary", "confidence", "sources"]
missing = [f for f in required_fields if f not in data]
if missing:
return Feedback(
error=AssessmentError(
error_code="MISSING_REQUIRED_FIELDS",
error_message=f"Missing required fields: {missing}",
),
)
return Feedback(
value=True,
rationale="Valid JSON with all required fields"
)
except json.JSONDecodeError as e:
return Feedback(error=e) # Can pass exception object directly to the error parameter
O parâmetro error aceita os seguintes tipos de erros:
- Exceção em Python : Passe o objeto de exceção diretamente.
AssessmentError: Para relatórios de erros estruturados com códigos de erro.
Classe Scorer
Na maioria dos casos, o decorador@scorer é recomendado. Se a sua lógica exigir estado interno ou personalização adicional, use a classe base Scorer . A classe Scorer é um objeto Pydantic, então você pode definir campos adicionais e usá-los no método __call__ .
Os indicadores definidos usando a classe Scorer não são suportados para monitoramento de produção. Para mais detalhes, consulte Avaliadores baseados em código.
Você deve definir o campo name para definir o nome do tamanho. Se você retornar uma lista de objetos Feedback , então você deve definir o campo name em cada Feedback para evitar conflitos de nomes.
from mlflow.genai.scorers import Scorer
from mlflow.entities import Feedback
from typing import Optional
# Scorer class is a Pydantic object
class CustomScorer(Scorer):
# The `name` field is mandatory
name: str = "response_quality"
# Define additional fields
my_custom_field_1: int = 50
my_custom_field_2: Optional[list[str]] = None
# Override the __call__ method to implement the scorer logic
def __call__(self, outputs: str) -> Feedback:
# Your logic here
return Feedback(
value=True,
rationale="Response meets all quality criteria"
)
Gestão estatal
Ao escrever sistemas de pontuação usando a classe Scorer , esteja ciente das regras para gerenciar o estado com classes Python. Em particular, certifique-se de usar atributos de instância, e não atributos de classe mutáveis. O exemplo abaixo ilustra o compartilhamento incorreto de estado entre instâncias do avaliador.
from mlflow.genai.scorers import Scorer
from mlflow.entities import Feedback
# WRONG: Don't use mutable class attributes
class BadScorer(Scorer):
results = [] # Shared across all instances!
name: str = "bad_scorer"
def __call__(self, outputs, **kwargs):
self.results.append(outputs) # Causes issues
return Feedback(value=True)
# CORRECT: Use instance attributes
class GoodScorer(Scorer):
results: list[str] = None
name: str = "good_scorer"
def __init__(self):
self.results = [] # Per-instance state
def __call__(self, outputs, **kwargs):
self.results.append(outputs) # Safe
return Feedback(value=True)