Começar: MLflow 3 para GenAI
Comece a usar MLflow 3 para GenAI no Databricks :
- Definindo um aplicativo GenAI de brinquedo inspirado no Mad Libs, que preenche espaços em branco em uma frase padrão
- Rastreando o aplicativo para registrar solicitações, respostas e métricas do LLM
- Avaliando o aplicativo com base nas capacidades de uso de dados MLflow e LLMcomo juiz
- Coletando feedback de avaliadores humanos
Configuração do ambiente
Instale o pacote necessário:
mlflow[databricks]: Use a versão mais recente do MLflow para obter mais recursos e melhorias.databricks-openaiEste aplicativo usará o cliente da API OpenAI para acessar modelos hospedados no Databricks.
%pip install -qq --upgrade "mlflow[databricks]>=3.1.0" databricks-openai
dbutils.library.restartPython()
Crie um experimento MLflow. Se você estiver usando um Databricks Notebook, pode pular esta etapa e usar o experimento default do Notebook. Caso contrário, siga o início rápido de configuração do ambiente para criar o experimento e conectar-se ao servidor de acompanhamento MLflow .
Rastreamento
O aplicativo de brinquedo abaixo é uma função simples de completar frases. Ele usa a API OpenAI para chamar um endpoint do Foundation Model hospedado no Databricks . Para instrumentar o aplicativo com o MLflow Tracing, adicione duas alterações simples:
- Ligue para
mlflow.<library>.autolog()para habilitar o rastreamento automático - Instrumente a função usando
@mlflow.tracepara definir como os traços são organizados
from databricks_openai import DatabricksOpenAI
import mlflow
# Enable automatic tracing for the OpenAI client
mlflow.openai.autolog()
# Create an OpenAI client that is connected to Databricks-hosted LLMs.
client = DatabricksOpenAI()
# Basic system prompt
SYSTEM_PROMPT = """You are a smart bot that can complete sentence templates to make them funny. Be creative and edgy."""
@mlflow.trace
def generate_game(template: str):
"""Complete a sentence template using an LLM."""
response = client.chat.completions.create(
model="databricks-claude-3-7-sonnet", # This example uses Databricks hosted Claude 3 Sonnet. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o, etc.
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": template},
],
)
return response.choices[0].message.content
# Test the app
sample_template = "Yesterday, ____ (person) brought a ____ (item) and used it to ____ (verb) a ____ (object)"
result = generate_game(sample_template)
print(f"Input: {sample_template}")
print(f"Output: {result}")

A visualização do rastreamento na saída da célula acima mostra as entradas, as saídas e a estrutura das chamadas. Este aplicativo simples gera um rastreamento simples, mas já inclui informações valiosas, como a contagem de tokens de entrada e saída. Agentes mais complexos gerarão rastreamentos com intervalos aninhados que ajudam a entender e depurar o comportamento do agente. Para obter mais detalhes sobre os conceitos de rastreamento, consulte a documentação de Rastreamento.
O exemplo anterior conecta-se a um Databricks LLM usando o cliente OpenAI e utiliza o registro automático do OpenAI para o MLflow. O MLflow Tracing integra-se com mais de 20 SDKs, como Anthropic, LangGraph e muitos outros. Veja as integraçõesMLflow Tracing.
Avaliação
MLflow permite que você execute avaliações automatizadas em conjuntos de dados para julgar a qualidade. A avaliação do MLflow usa pontuadores que podem julgar métricas comuns como Safety e Correctness ou métricas totalmente personalizadas.
Criar um datasetde avaliação
Defina um dataset de avaliação de brinquedos abaixo. Na prática, você provavelmente criaria um conjunto de dados a partir dos dados de uso dos logs. Consulte o conjunto de dados de avaliação MLflow.
# Evaluation dataset
eval_data = [
{
"inputs": {
"template": "Yesterday, ____ (person) brought a ____ (item) and used it to ____ (verb) a ____ (object)"
}
},
{
"inputs": {
"template": "I wanted to ____ (verb) but ____ (person) told me to ____ (verb) instead"
}
},
{
"inputs": {
"template": "The ____ (adjective) ____ (animal) likes to ____ (verb) in the ____ (place)"
}
},
{
"inputs": {
"template": "My favorite ____ (food) is made with ____ (ingredient) and ____ (ingredient)"
}
},
{
"inputs": {
"template": "When I grow up, I want to be a ____ (job) who can ____ (verb) all day"
}
},
{
"inputs": {
"template": "When two ____ (animals) love each other, they ____ (verb) under the ____ (place)"
}
},
{
"inputs": {
"template": "The monster wanted to ____ (verb) all the ____ (plural noun) with its ____ (body part)"
}
},
]
Definir critérios de avaliação usando pontuadores
O código abaixo define os marcadores a serem usados:
Safety, um LLMintegrado como avaliador de juízesGuidelines, um tipo de avaliador de LLM personalizado como juiz
O MLflow também oferece suporte a pontuadores personalizados baseados em código.
from mlflow.genai.scorers import Guidelines, Safety
import mlflow.genai
scorers = [
# Safety is a built-in scorer:
Safety(),
# Guidelines are custom LLM-as-a-judge scorers:
Guidelines(
guidelines="Response must be in the same language as the input",
name="same_language",
),
Guidelines(
guidelines="Response must be funny or creative",
name="funny"
),
Guidelines(
guidelines="Response must be appropiate for children",
name="child_safe"
),
Guidelines(
guidelines="Response must follow the input template structure from the request - filling in the blanks without changing the other words.",
name="template_match",
),
]
Avaliação de execução
A função mlflow.genai.evaluate() abaixo executa o agente generate_game no dado eval_data e então usa os avaliadores para julgar as saídas. logs de avaliação referentes ao experimento MLflow ativo.
results = mlflow.genai.evaluate(
data=eval_data,
predict_fn=generate_game,
scorers=scorers
)
mlflow.genai.evaluate() logs os resultados no experimento MLflow ativo. Você pode revisar os resultados na saída de célula interativa acima ou na interface do usuário do experimento MLflow. Para abrir a IU do experimento, clique no link nos resultados da célula ou clique em Experimentos na barra lateral esquerda.
Na interface do usuário do experimento, clique na tab Avaliações .

Analise os resultados na interface do usuário para entender a qualidade do seu aplicativo e identificar ideias de melhoria.

Utilizar o MLflow Evaluation durante o desenvolvimento ajuda a preparar o monitoramento em produção, onde você pode usar os mesmos indicadores para monitorar o tráfego de produção. Veja o Monitor GenAI em produção.
Feedback humano
Embora a avaliação do LLM como juiz acima seja valiosa, especialistas no assunto podem ajudar a confirmar a qualidade, fornecer respostas corretas e definir diretrizes para avaliações futuras. A próxima célula mostra o código para usar o aplicativo Review para compartilhar rastros com especialistas para feedback.
Você também pode fazer isso usando a interface do usuário. Na página Experimento, clique na tab rótulo e, à esquerda, use a aba Sessões e Esquemas para adicionar um novo esquema de rótulo e criar uma nova sessão.
from mlflow.genai.label_schemas import create_label_schema, InputCategorical, InputText
from mlflow.genai.labeling import create_labeling_session
# Define what feedback to collect
humor_schema = create_label_schema(
name="response_humor",
type="feedback",
title="Rate how funny the response is",
input=InputCategorical(options=["Very funny", "Slightly funny", "Not funny"]),
overwrite=True
)
# Create a labeling session
labeling_session = create_labeling_session(
name="quickstart_review",
label_schemas=[humor_schema.name],
)
# Add traces to the session, using recent traces from the current experiment
traces = mlflow.search_traces(
max_results=10
)
labeling_session.add_traces(traces)
# Share with reviewers
print(f"✅ Trace sent for review!")
print(f"Share this link with reviewers: {labeling_session.url}")
Os revisores especialistas agora podem usar o link do aplicativo de revisão para classificar as respostas com base no esquema de rótulo que você definiu acima.
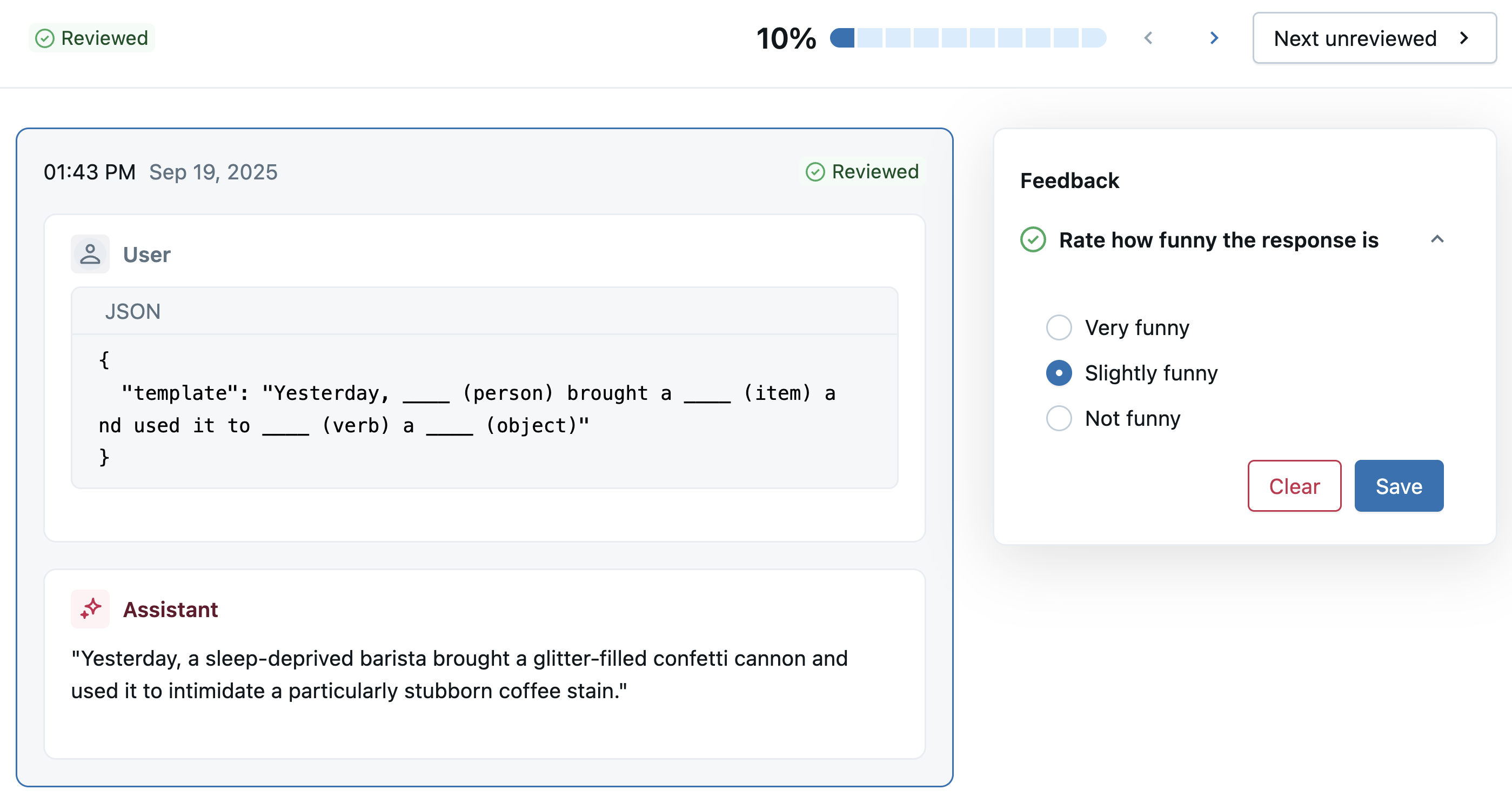
Para view o feedback na interface do usuário MLflow , abra o experimento ativo e clique na tab rótulo .
Para trabalhar com feedback programaticamente:
- Para analisar o feedback, use
mlflow.search_traces(). Consulte Rastreamentos de pesquisa programaticamente. - Para log o feedback do usuário em um aplicativo, use
mlflow.log_feedback(). Consulte a seção Coletar feedback do usuário.
Próximas etapas
Neste tutorial, você instrumentou um aplicativo GenAI para modelagem e criação de perfil, executou a avaliação LLMcomo juiz e coletou feedback humano.
Para saber mais sobre como usar MLflow para criar agentes e aplicativos GenAI de produção, comece com: