Demonstração de 10 minutos: Coletar feedback humano
Este tutorial mostra como coletar feedback do usuário final, adicionar anotações de desenvolvedor, criar sessões de revisão com especialistas e usar esse feedback para avaliar a qualidade do seu aplicativo GenAI.
O que você vai conseguir
Ao final deste tutorial, você:
- Instrumentar um aplicativo GenAI com rastreamento MLflow
- Coletar feedback do usuário final, simulado usando o SDK neste exemplo
- Adicione feedback do desenvolvedor interativamente por meio da interface do usuário
- veja o feedback junto com seus rastros
- Colete feedback de especialistas criando uma sessão de rótulo para revisão estruturada de especialistas
Configuração do ambiente
Instale o pacote necessário:
mlflow[databricks]Use a versão mais recente do MLflow para obter mais recursos e melhorias.openaiEste aplicativo usará o cliente da API OpenAI para acessar modelos hospedados no Databricks.
%pip install -q --upgrade "mlflow[databricks]>=3.1.0" databricks-openai
dbutils.library.restartPython()
Crie um experimento MLflow. Se você estiver usando um Databricks Notebook, pode pular esta etapa e usar o experimento default do Notebook. Caso contrário, siga o início rápido de configuração do ambiente para criar o experimento e conectar-se ao servidor de acompanhamento MLflow .
Etapa 1: criar e rastrear um aplicativo simples
Primeiro, crie um aplicativo GenAI simples usando um LLM com rastreamento MLflow. O aplicativo usa a API da OpenAI para acessar um endpoint do Foundation Model hospedado no Databricks.
from databricks_openai import DatabricksOpenAI
import mlflow
# Enable automatic tracing for the OpenAI client
mlflow.openai.autolog()
# Create an OpenAI client that is connected to Databricks-hosted LLMs.
client = DatabricksOpenAI()
# Create a RAG app with tracing
@mlflow.trace
def my_chatbot(user_question: str) -> str:
# Retrieve relevant context
context = retrieve_context(user_question)
# Generate response using LLM with retrieved context
response = client.chat.completions.create(
model="databricks-claude-sonnet-4", # If using OpenAI directly, use "gpt-4o" or "gpt-3.5-turbo"
messages=[
{"role": "system", "content": "You are a helpful assistant. Use the provided context to answer questions."},
{"role": "user", "content": f"Context: {context}\n\nQuestion: {user_question}"}
],
temperature=0.7,
max_tokens=150
)
return response.choices[0].message.content
@mlflow.trace(span_type="RETRIEVER")
def retrieve_context(query: str) -> str:
# Simulated retrieval. In production, this could search a vector database
if "mlflow" in query.lower():
return "MLflow is the largest open source AI engineering platform for agents, LLMs, and ML models. MLflow enables teams of all sizes to debug, evaluate, monitor, and optimize their AI applications while controlling costs and managing access to models and data. With over 30 million monthly downloads, thousands of organizations rely on MLflow each day to ship AI to production with confidence."
return "General information about machine learning and data science."
# Run the app to generate a trace
response = my_chatbot("What is MLflow?")
print(f"Response: {response}")
# Get the trace ID for the next step
trace_id = mlflow.get_last_active_trace_id()
print(f"Trace ID: {trace_id}")
Etapa 2: coletar feedback do usuário final
Quando os usuários interagem com seu aplicativo, eles podem fornecer feedback por meio de elementos da interface, como botões de polegar para cima/para baixo. Este início rápido simula um usuário final dando feedback negativo usando o SDK diretamente.
from mlflow.entities.assessment import AssessmentSource, AssessmentSourceType
# Simulate end-user feedback from your app
# In production, this could be triggered when a user clicks thumbs down in your UI
mlflow.log_feedback(
trace_id=trace_id,
name="user_feedback",
value=False, # False for thumbs down - user is unsatisfied
rationale="Missing details about MLflow's key features like Projects and Model Registry",
source=AssessmentSource(
source_type=AssessmentSourceType.HUMAN,
source_id="enduser_123", # In production, this is the actual user ID
),
)
print("End-user feedback recorded!")
# In a real app, you could:
# 1. Return the trace_id with your response to the frontend
# 2. When user clicks thumbs up/down, call your backend API
# 3. Your backend calls mlflow.log_feedback() with the trace_id
Etapa 3: visualizar o feedback na UI
Inicie a interface de usuário do MLflow para ver seus traços com feedback:
- Navegue até seu experimento MLflow.
- Acesse a tab registros .
- Clique no seu rastreamento.
- A caixa de diálogo de detalhes do rastreamento é exibida. Em Avaliações , no lado direito da caixa de diálogo, o
user_feedbackmostrafalse, indicando que o usuário marcou a resposta com o polegar para baixo.

o passo 4: Adicionar anotação do desenvolvedor usando a UI
Como desenvolvedor, você também pode adicionar seus próprios comentários e notas diretamente na interface do usuário:
-
Na tab de registros , clique em um rastreamento para abri-lo.
-
Clique em qualquer extensão (escolha a extensão raiz para feedback em nível de rastreamento).
-
Em Assessments (Avaliações ) tab, à direita, clique em Add new assessment (Adicionar nova avaliação ) e preencha os dados a seguir:
- Tipo :
Feedback. - Nome :
accuracy_score. - Valor :
.75. - Justificativa :
This answer includes the core elements of ML lifecycle management, experiment tracking, packaging, and deployment. However, it does not mention the model registry, project packaging, integration with Generative AI and LLMs, or unique features available in Databricks-managed MLflow, which are now considered essential to a complete description of the platform.
- Tipo :
-
Clique em Criar .
Após refresh a página, as colunas referentes às novas avaliações aparecerão na tabela de registros.
Etapa 5: enviar rastreamento para análise de um especialista
O feedback negativo do usuário final da Etapa 2 indica um possível problema de qualidade, mas somente especialistas do domínio podem confirmar se realmente há um problema e fornecer a resposta correta. Crie uma sessão de rótulo para obter feedback de especialistas autorizados:
from mlflow.genai.label_schemas import create_label_schema, InputCategorical, InputText
from mlflow.genai.labeling import create_labeling_session
# Define what feedback to collect
accuracy_schema = create_label_schema(
name="response_accuracy",
type="feedback",
title="Is the response factually accurate?",
input=InputCategorical(options=["Accurate", "Partially Accurate", "Inaccurate"]),
overwrite=True
)
ideal_response_schema = create_label_schema(
name="expected_response",
type="expectation",
title="What would be the ideal response?",
input=InputText(),
overwrite=True
)
# Create a labeling session
labeling_session = create_labeling_session(
name="quickstart_review",
label_schemas=[accuracy_schema.name, ideal_response_schema.name],
)
# Add your trace to the session
# Get the most recent trace from the current experiment
traces = mlflow.search_traces(
max_results=1 # Gets the most recent trace
)
labeling_session.add_traces(traces)
# Share with reviewers
print(f"Trace sent for review!")
print(f"Share this link with reviewers: {labeling_session.url}")

Os revisores especialistas agora podem fazer o seguinte:
-
Abra o URL do aplicativo de avaliação.
-
Veja seu rastreamento com a pergunta e a resposta (incluindo qualquer feedback do usuário final).
-
Avalie se a resposta é realmente precisa.
-
Forneça a resposta correta em
expected_responsepara a pergunta "O que é MLflow?":MLflow is the largest open source AI engineering platform for agents, LLMs, and ML models. MLflow enables teams of all sizes to debug, evaluate, monitor, and optimize their AI applications while controlling costs and managing access to models and data. With over 30 million monthly downloads, thousands of organizations rely on MLflow each day to ship AI to production with confidence. -
Envie suas avaliações de especialistas como verdade fundamental.
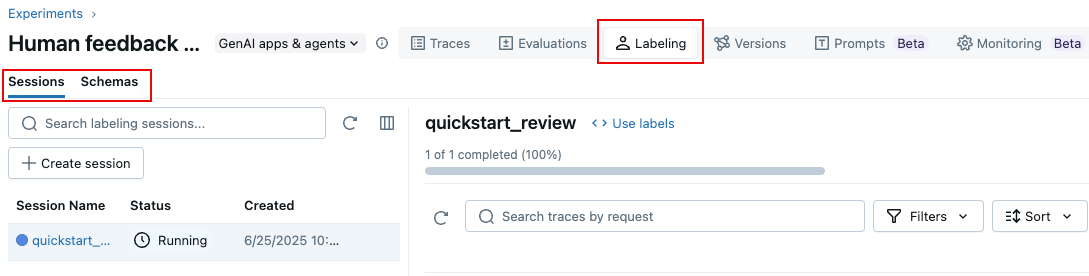
O senhor também pode usar a interface de usuário do MLflow 3 para criar uma sessão de rótulo, como segue:
- Na página do experimento, clique no rótulo tab.
- À esquerda, use a guia Sessions and Schemas para adicionar um novo esquema de rótulo e criar uma nova sessão.
Etapa 6: use o feedback para avaliar seu aplicativo
Após os especialistas fornecerem feedback, use o rótulo expected_response deles para avaliar seu aplicativo com o avaliador Correctness do MLflow:
Este exemplo utiliza diretamente os rastreamentos para avaliação. Na sua aplicação, Databricks recomenda adicionar rastreamentos de rótulos a um conjunto de dados de avaliação MLflow , que fornece acompanhamento de versão e linhagem. Aprenda sobre como construir um conjunto de dados de avaliação.
from mlflow.genai.scorers import Correctness
# Get traces from the labeling session
labeled_traces = mlflow.search_traces(
run_id=labeling_session.mlflow_run_id, # Labeling Sessions are MLflow Runs
)
# Evaluate your app against expert expectations
eval_results = mlflow.genai.evaluate(
data=labeled_traces,
predict_fn=my_chatbot, # The app we created in Step 1
scorers=[Correctness()] # Compares outputs to expected_response
)
O marcador de correção compara os resultados do seu aplicativo com o expected_response fornecido por especialistas, fornecendo feedback quantitativo sobre o alinhamento com as expectativas dos especialistas.

Próximas etapas
Saiba mais detalhes sobre a coleta de diferentes tipos de feedback humano:
- rótulo during development - Aprenda técnicas avançadas de anotação para desenvolvimento
- Verificação de vibração com especialistas do domínio - Teste seu aplicativo interativamente com especialistas
- Colete feedback de especialistas do domínio - Configure processos sistemáticos de revisão de especialistas