decoradores funcionais
O decorador @mlflow.trace permite criar um span para qualquer função. Os decoradores de função oferecem o caminho mais simples para adicionar rastreamento com alterações mínimas no código.
- O MLflow detecta as relações pai-filho entre funções, tornando-o compatível com integrações de rastreamento automático.
- Captura exceções durante a execução da função e as registra como eventos de intervalo.
- logs automaticamente o nome da função, suas entradas, saídas e tempo de execução.
- Pode ser usado em conjunto com o recurso de rastreamento automático.
Pré-requisitos
- MLflow 3
- MLflow 2.x
Esta página requer o seguinte pacote:
mlflow[databricks]3.1 e versões superiores: Funcionalidade principal MLflow com recurso GenAI e conectividade com Databricks .openai1.0.0 e versões superiores: (Opcional) Somente se o seu código personalizado interagir com OpenAI; substitua por outros SDKs, se necessário.
Instale os requisitos básicos:
%pip install --upgrade "mlflow[databricks]>=3.1"
# %pip install --upgrade "openai>=1.0.0" # Install if needed
Este guia requer o seguinte pacote:
mlflow[databricks]2.15.0 e versões superiores: Funcionalidade principal MLflow com conectividade Databricks .openai1.0.0 e versões superiores. (Opcional) Somente se o seu código personalizado interagir com a OpenAI.
Versão MLflow
A Databricks recomenda fortemente a instalação do MLflow 3.1 ou mais recente se estiver usando mlflow[databricks].
Instale os requisitos básicos:
%pip install --upgrade "mlflow[databricks]>=2.15.0,<3.0.0"
# pip install --upgrade "openai>=1.0.0" # Install if needed
Exemplo básico
O código a seguir é um exemplo mínimo de como usar o decorador para rastrear funções em Python.
Encomenda de decoração
Para garantir a observabilidade completa, o decorador @mlflow.trace deve ser geralmente o mais externo se forem usados vários decoradores. Consulte a seção "Usando @mlflow.trace com outros decoradores" para obter uma explicação detalhada e exemplos.
import mlflow
@mlflow.trace(span_type="func", attributes={"key": "value"})
def add_1(x):
return x + 1
@mlflow.trace(span_type="func", attributes={"key1": "value1"})
def minus_1(x):
return x - 1
@mlflow.trace(name="Trace Test")
def trace_test(x):
step1 = add_1(x)
return minus_1(step1)
trace_test(4)
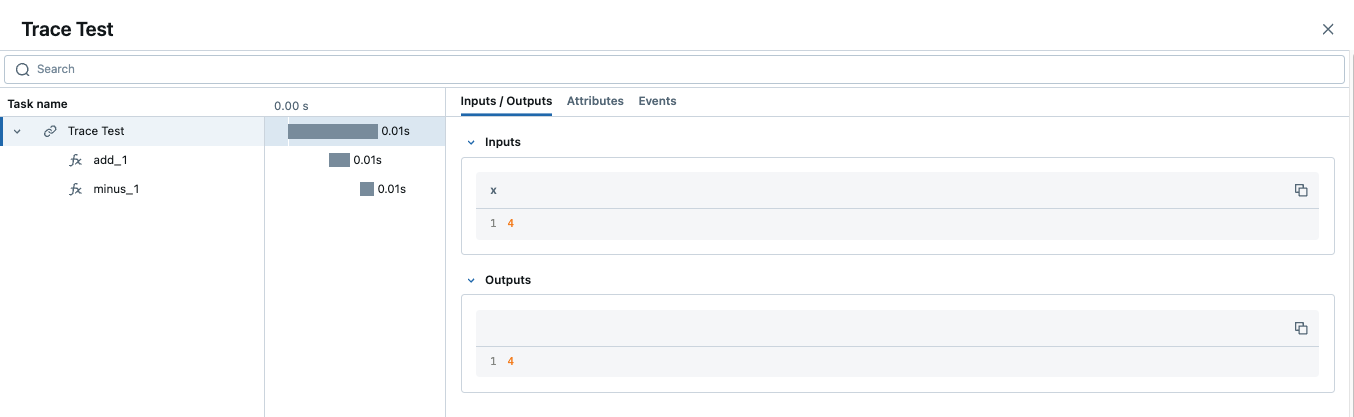
Quando um rastreamento contém vários intervalos com o mesmo nome, o MLflow acrescenta um sufixo de incremento automático a eles, como _1, _2.
Personalizar intervalos
O decorador @mlflow.trace aceita os seguintes argumentos para personalizar o span a ser criado:
nameparâmetro para substituir o nome do default (o nome da função decorada)span_typeparâmetro para definir o tipo de intervalo. Defina um dos tipos de span integrados ou uma string.attributesparâmetro para adicionar atributos personalizados ao span.
Encomenda de decoração
Ao combinar @mlflow.trace com outros decoradores (por exemplo, de frameworks web), é crucial que ele seja o mais externo. Para um exemplo claro de ordenação correta versus incorreta, consulte Usando @mlflow.trace com outros decoradores.
@mlflow.trace(
name="call-local-llm", span_type=SpanType.LLM, attributes={"model": "gpt-4o-mini"}
)
def invoke(prompt: str):
return client.invoke(
messages=[{"role": "user", "content": prompt}], model="gpt-4o-mini"
)
Alternativamente, você pode atualizar um span ativo ou em execução dinamicamente dentro da função usando a API mlflow.get_current_active_span .
@mlflow.trace(span_type=SpanType.LLM)
def invoke(prompt: str):
model_id = "gpt-4o-mini"
# Get the current span (created by the @mlflow.trace decorator)
span = mlflow.get_current_active_span()
# Set the attribute to the span
span.set_attributes({"model": model_id})
return client.invoke(messages=[{"role": "user", "content": prompt}], model=model_id)
Consulte Rastreamento de span com gerenciadores de contexto para obter mais exemplos de edição de objetos LiveSpan .
Use @mlflow.trace com outros decoradores
Ao aplicar vários decoradores a uma única função, é crucial colocar @mlflow.trace como o decorador mais externo (aquele no topo). Isso garante que o MLflow possa capturar toda a execução da função, incluindo o comportamento de quaisquer decoradores internos.
Se @mlflow.trace não for o decorador mais externo, sua visibilidade na execução da função pode ser limitada ou incorreta, potencialmente levando a rastreamentos incompletos ou representação incorreta das entradas, saídas e tempo de execução da função.
Considere o seguinte exemplo conceitual:
import mlflow
import functools
import time
# A hypothetical additional decorator
def simple_timing_decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
print(f"{func.__name__} executed in {end_time - start_time:.4f} seconds by simple_timing_decorator.")
return result
return wrapper
# Correct order: @mlflow.trace is outermost
@mlflow.trace(name="my_decorated_function_correct_order")
@simple_timing_decorator
# @another_framework_decorator # e.g., @app.route("/mypath") from Flask
def my_complex_function(x, y):
# Function logic here
time.sleep(0.1) # Simulate work
return x + y
# Incorrect order: @mlflow.trace is NOT outermost
@simple_timing_decorator
@mlflow.trace(name="my_decorated_function_incorrect_order")
# @another_framework_decorator
def my_other_complex_function(x, y):
time.sleep(0.1)
return x * y
# Example calls
if __name__ == "__main__":
print("Calling function with correct decorator order:")
my_complex_function(5, 3)
print("\nCalling function with incorrect decorator order:")
my_other_complex_function(5, 3)
No exemplo my_complex_function (ordem correta), @mlflow.trace capturará a execução completa, incluindo o tempo adicionado por simple_timing_decorator. Em my_other_complex_function (ordem incorreta), o rastreamento capturado pelo MLflow pode não refletir com precisão o tempo total de execução ou pode perder modificações nas entradas/saídas feitas por simple_timing_decorator antes que @mlflow.trace as veja.
Adicionar tags de rastreamento
É possível adicionar tags aos rastreamentos para fornecer metadados adicionais no nível do rastreamento. Existem algumas maneiras diferentes de definir tags em um rastreamento. Consulte o guia para anexar tags personalizadas para obter informações sobre outros métodos.
@mlflow.trace
def my_func(x):
mlflow.update_current_trace(tags={"fruit": "apple"})
return x + 1
Personalize as pré-visualizações de solicitações e respostas na interface do usuário.
A tab Traces na interface do usuário MLflow exibe uma lista de rastreamentos, e as colunas Request e Response mostram uma pré-visualização da entrada e saída de ponta a ponta de cada rastreamento. Isso permite que você entenda rapidamente o que cada traço representa.
Por default, essas pré-visualizações são truncadas para um número fixo de caracteres. No entanto, você pode personalizar o que é mostrado nessas colunas usando os parâmetros request_preview e response_preview dentro da função mlflow.update_current_trace() . Isso é particularmente útil para entradas ou saídas complexas, onde o truncamento default pode não mostrar as informações mais relevantes.
Abaixo está um exemplo de como configurar uma pré-visualização de solicitação personalizada para um rastreamento que processa um documento longo e instruções do usuário, com o objetivo de exibir as informações mais relevantes na coluna Request da interface do usuário:
import mlflow
@mlflow.trace(name="Summarization Pipeline")
def summarize_document(document_content: str, user_instructions: str):
# Construct a custom preview for the request column
# For example, show beginning of document and user instructions
request_p = f"Doc: {document_content[:30]}... Instr: {user_instructions[:30]}..."
mlflow.update_current_trace(request_preview=request_p)
# Simulate LLM call
# messages = [
# {"role": "system", "content": "Summarize the following document based on user instructions."},
# {"role": "user", "content": f"Document: {document_content}\nInstructions: {user_instructions}"}
# ]
# completion = client.chat.completions.create(model="gpt-4o-mini", messages=messages)
# summary = completion.choices[0].message.content
summary = f"Summary of document starting with '{document_content[:20]}...' based on '{user_instructions}'"
# Customize the response preview
response_p = f"Summary: {summary[:50]}..."
mlflow.update_current_trace(response_preview=response_p)
return summary
# Example Call
long_document = "This is a very long document that contains many details about various topics..." * 10
instructions = "Focus on the key takeaways regarding topic X."
summary_result = summarize_document(long_document, instructions)
# print(summary_result)
Ao definir request_preview e response_preview no rastreamento (normalmente o intervalo raiz), você controla como a interação geral é resumida na view principal da lista de rastreamentos, facilitando a identificação e a compreensão dos rastreamentos rapidamente.
Tratamento automático de exceções
Se um Exception for gerado durante o processamento de uma operação instrumentada por rastreamento, uma indicação será exibida na interface do usuário informando que a invocação não foi bem-sucedida.
Se bem-sucedido, um conjunto parcial de dados estará disponível para auxiliar em. Além disso, serão incluídos detalhes sobre a exceção que foi gerada.
dentro de Events do intervalo parcialmente preenchido, auxiliando ainda mais na identificação de onde os problemas estão ocorrendo em seu código.

Combine com rastreamento automático
O rastreamento manual integra-se perfeitamente com os recursos de rastreamento automático do MLflow. Consulte Combinar rastreamento manual e automático.
Rastreamento de fluxo de trabalho complexo
Para fluxo de trabalho complexo com vários passos, use intervalos aninhados para capturar o fluxo de execução detalhado:
@mlflow.trace(name="data_pipeline")
def process_data_pipeline(data_source: str):
# Extract phase
with mlflow.start_span(name="extract") as extract_span:
raw_data = extract_from_source(data_source)
extract_span.set_outputs({"record_count": len(raw_data)})
# Transform phase
with mlflow.start_span(name="transform") as transform_span:
transformed = apply_transformations(raw_data)
transform_span.set_outputs({"transformed_count": len(transformed)})
# Load phase
with mlflow.start_span(name="load") as load_span:
result = load_to_destination(transformed)
load_span.set_outputs({"status": "success"})
return result
Multithreading
MLflow Tracing é seguro para uso em múltiplas threads; default , os rastreamentos são isolados por thread. Mas você também pode criar um rastreamento que abranja várias threads com alguns passos adicionais.
MLflow utiliza o mecanismo ContextVar integrado do Python para garantir a segurança de threads, que não é propagada entre threads por default. Portanto, você precisa copiar manualmente o contexto da thread principal para a thread worker , conforme mostrado no exemplo abaixo.
import contextvars
from concurrent.futures import ThreadPoolExecutor, as_completed
import mlflow
from mlflow.entities import SpanType
import openai
client = openai.OpenAI()
# Enable MLflow Tracing for OpenAI
mlflow.openai.autolog()
@mlflow.trace
def worker(question: str) -> str:
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question},
]
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
temperature=0.1,
max_tokens=100,
)
return response.choices[0].message.content
@mlflow.trace
def main(questions: list[str]) -> list[str]:
results = []
# Almost same as how you would use ThreadPoolExecutor, but two additional steps
# 1. Copy the context in the main thread using copy_context()
# 2. Use ctx.run() to run the worker in the copied context
with ThreadPoolExecutor(max_workers=2) as executor:
futures = []
for question in questions:
ctx = contextvars.copy_context()
futures.append(executor.submit(ctx.run, worker, question))
for future in as_completed(futures):
results.append(future.result())
return results
questions = [
"What is the capital of France?",
"What is the capital of Germany?",
]
main(questions)
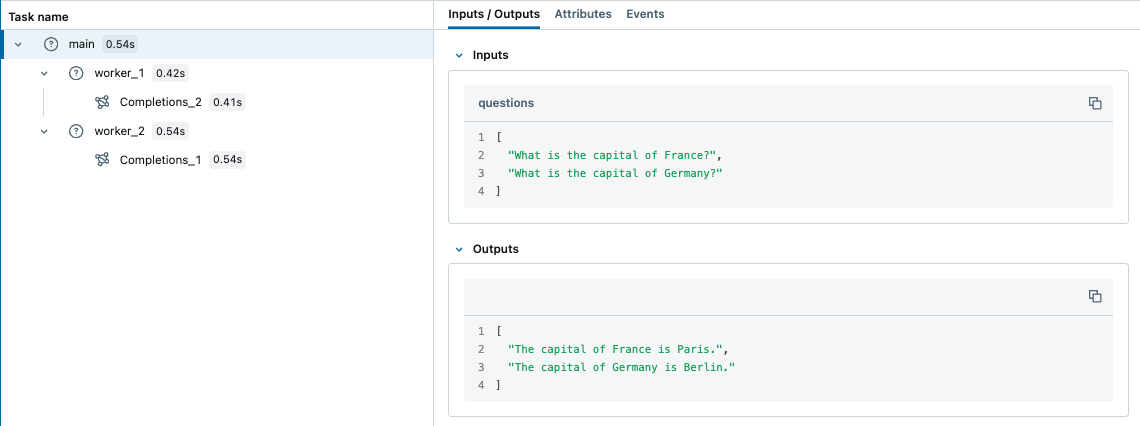
Em contraste, ContextVar é copiado para a tarefa assíncrona por default. Portanto, você não precisa copiar o contexto manualmente ao usar asyncio,
que pode ser uma maneira mais fácil de lidar com tarefas simultâneas de E/S em Python com MLflow Tracing.
transmissões saídas
O decorador @mlflow.trace pode ser usado para rastrear funções que retornam um gerador ou um iterador, desde o MLflow 2.20.2.
@mlflow.trace
def stream_data():
for i in range(5):
yield i
O exemplo acima irá gerar um rastreamento com um único intervalo para a função stream_data . Por default, MLflow captura todos os elementos gerados pelo gerador como uma lista na saída do span. No exemplo acima, a saída do span será [0, 1, 2, 3, 4].
O intervalo de uma função de transmissão começa quando o iterador retornado começa a ser consumido e termina quando o iterador se esgota ou quando uma exceção é lançada durante a iteração.
Utilizando redutores de saída
Se você quiser agregar os elementos em uma única saída span, você pode usar o parâmetro output_reducer para especificar uma função personalizada para agregar os elementos. A função personalizada deve receber como entrada uma lista de elementos retornados.
from typing import List, Any
@mlflow.trace(output_reducer=lambda x: ",".join(x))
def stream_data():
for c in "hello":
yield c
No exemplo acima, a saída do span será "h,e,l,l,o". Os blocos brutos ainda podem ser encontrados na tab Events do intervalo na interface de rastreamento MLflow , permitindo que você inspecione os valores individuais produzidos quando paralelo.
Padrões comuns de redução de saída
Aqui estão alguns padrões comuns para implementar redutores de saída:
Agregação de tokens
from typing import List, Dict, Any
def aggregate_tokens(chunks: List[str]) -> str:
"""Concatenate streaming tokens into complete text"""
return "".join(chunks)
@mlflow.trace(output_reducer=aggregate_tokens)
def stream_text():
for word in ["Hello", " ", "World", "!"]:
yield word
Agregação de métricas
def aggregate_metrics(chunks: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Aggregate streaming metrics into summary statistics"""
values = [c["value"] for c in chunks if "value" in c]
return {
"count": len(values),
"sum": sum(values),
"average": sum(values) / len(values) if values else 0,
"max": max(values) if values else None,
"min": min(values) if values else None
}
@mlflow.trace(output_reducer=aggregate_metrics)
def stream_metrics():
for i in range(10):
yield {"value": i * 2, "timestamp": time.time()}
Coleção de erros
def collect_results_and_errors(chunks: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Separate successful results from errors"""
results = []
errors = []
for chunk in chunks:
if chunk.get("error"):
errors.append(chunk["error"])
else:
results.append(chunk.get("data"))
return {
"results": results,
"errors": errors,
"success_rate": len(results) / len(chunks) if chunks else 0,
"has_errors": len(errors) > 0
}
Exemplo avançado: transmissão OpenAI
O exemplo a seguir é um exemplo avançado que usa o output_reducer para consolidar a saída ChatCompletionChunk de um OpenAI LLM em um único objeto de mensagem.
Recomendamos o uso do rastreamento automático do OpenAI para casos de uso em produção, pois ele lida com isso automaticamente. O exemplo abaixo é apenas para fins de demonstração.
import mlflow
import openai
from openai.types.chat import *
from typing import Optional
def aggregate_chunks(outputs: list[ChatCompletionChunk]) -> Optional[ChatCompletion]:
"""Consolidate ChatCompletionChunks to a single ChatCompletion"""
if not outputs:
return None
first_chunk = outputs[0]
delta = first_chunk.choices[0].delta
message = ChatCompletionMessage(
role=delta.role, content=delta.content, tool_calls=delta.tool_calls or []
)
finish_reason = first_chunk.choices[0].finish_reason
for chunk in outputs[1:]:
delta = chunk.choices[0].delta
message.content += delta.content or ""
message.tool_calls += delta.tool_calls or []
finish_reason = finish_reason or chunk.choices[0].finish_reason
base = ChatCompletion(
id=first_chunk.id,
choices=[Choice(index=0, message=message, finish_reason=finish_reason)],
created=first_chunk.created,
model=first_chunk.model,
object="chat.completion",
)
return base
@mlflow.trace(output_reducer=aggregate_chunks)
def predict(messages: list[dict]):
client = openai.OpenAI()
stream = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
stream=True,
)
for chunk in stream:
yield chunk
for chunk in predict([{"role": "user", "content": "Hello"}]):
print(chunk)
No exemplo acima, o span predict gerado terá uma única mensagem de conclusão de chat como saída, que é agregada pela função redutora personalizada.
Casos de uso no mundo real
Aqui estão exemplos adicionais de redutores de saída para cenários comuns do GenAI:
Resposta LLM com análise JSON
from typing import List, Dict, Any
import json
def parse_json_from_llm(content: str) -> str:
"""Extract and clean JSON from LLM responses that may include markdown"""
# Remove common markdown code block wrappers
if content.startswith("```json") and content.endswith("```"):
content = content[7:-3] # Remove ```json prefix and ``` suffix
elif content.startswith("```") and content.endswith("```"):
content = content[3:-3] # Remove generic ``` wrappers
return content.strip()
def json_stream_reducer(chunks: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Aggregate LLM streaming output and parse JSON response"""
full_content = ""
metadata = {}
errors = []
# Process different chunk types
for chunk in chunks:
chunk_type = chunk.get("type", "content")
if chunk_type == "content" or chunk_type == "token":
full_content += chunk.get("content", "")
elif chunk_type == "metadata":
metadata.update(chunk.get("data", {}))
elif chunk_type == "error":
errors.append(chunk.get("error"))
# Return early if errors occurred
if errors:
return {
"status": "error",
"errors": errors,
"raw_content": full_content,
**metadata
}
# Try to parse accumulated content as JSON
try:
cleaned_content = parse_json_from_llm(full_content)
parsed_data = json.loads(cleaned_content)
return {
"status": "success",
"data": parsed_data,
"raw_content": full_content,
**metadata
}
except json.JSONDecodeError as e:
return {
"status": "parse_error",
"error": f"Failed to parse JSON: {str(e)}",
"raw_content": full_content,
**metadata
}
@mlflow.trace(output_reducer=json_stream_reducer)
def generate_structured_output(prompt: str, schema: dict):
"""Generate structured JSON output from an LLM"""
# Simulate streaming JSON generation
yield {"type": "content", "content": '{"name": "John", '}
yield {"type": "content", "content": '"email": "john@example.com", '}
yield {"type": "content", "content": '"age": 30}'}
# Add metadata
trace_id = mlflow.get_current_active_span().request_id if mlflow.get_current_active_span() else None
yield {"type": "metadata", "data": {"trace_id": trace_id, "model": "gpt-4"}}
Geração de saída estruturada com OpenAI
Aqui está um exemplo completo de como usar redutores de saída com o OpenAI para gerar e analisar respostas JSON estruturadas:
import json
import mlflow
import openai
from typing import List, Dict, Any, Optional
def structured_output_reducer(chunks: List[Dict[str, Any]]) -> Dict[str, Any]:
"""
Aggregate streaming chunks into structured output with comprehensive error handling.
Handles token streaming, metadata collection, and JSON parsing.
"""
content_parts = []
trace_id = None
model_info = None
errors = []
for chunk in chunks:
chunk_type = chunk.get("type", "token")
if chunk_type == "token":
content_parts.append(chunk.get("content", ""))
elif chunk_type == "trace_info":
trace_id = chunk.get("trace_id")
model_info = chunk.get("model")
elif chunk_type == "error":
errors.append(chunk.get("message"))
# Join all content parts
full_content = "".join(content_parts)
# Base response
response = {
"trace_id": trace_id,
"model": model_info,
"raw_content": full_content
}
# Handle errors
if errors:
response["status"] = "error"
response["errors"] = errors
return response
# Try to extract and parse JSON
try:
# Clean markdown wrappers if present
json_content = full_content.strip()
if json_content.startswith("```json") and json_content.endswith("```"):
json_content = json_content[7:-3].strip()
elif json_content.startswith("```") and json_content.endswith("```"):
json_content = json_content[3:-3].strip()
parsed_data = json.loads(json_content)
response["status"] = "success"
response["data"] = parsed_data
except json.JSONDecodeError as e:
response["status"] = "parse_error"
response["error"] = f"JSON parsing failed: {str(e)}"
response["error_position"] = e.pos if hasattr(e, 'pos') else None
return response
@mlflow.trace(output_reducer=structured_output_reducer)
async def generate_customer_email(
customer_name: str,
issue: str,
sentiment: str = "professional"
) -> None:
"""
Generate a structured customer service email response.
Demonstrates real-world streaming with OpenAI and structured output parsing.
"""
client = openai.AsyncOpenAI()
system_prompt = """You are a customer service assistant. Generate a professional email response in JSON format:
{
"subject": "email subject line",
"greeting": "personalized greeting",
"body": "main email content addressing the issue",
"closing": "professional closing",
"priority": "high|medium|low"
}"""
user_prompt = f"Customer: {customer_name}\nIssue: {issue}\nTone: {sentiment}"
try:
# Stream the response
stream = await client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
stream=True,
temperature=0.7
)
# Yield streaming tokens
async for chunk in stream:
if chunk.choices[0].delta.content:
yield {
"type": "token",
"content": chunk.choices[0].delta.content
}
# Add trace metadata
if current_span := mlflow.get_current_active_span():
yield {
"type": "trace_info",
"trace_id": current_span.request_id,
"model": "gpt-4o-mini"
}
except Exception as e:
yield {
"type": "error",
"message": f"OpenAI API error: {str(e)}"
}
# Example usage
async def main():
# This will automatically aggregate the streamed output into structured JSON
async for chunk in generate_customer_email(
customer_name="John Doe",
issue="Product arrived damaged",
sentiment="empathetic"
):
# In practice, you might send these chunks to a frontend
print(chunk.get("content", ""), end="", flush=True)
Benefícios da integração
Este exemplo ilustra diversos padrões do mundo real:
- Atualizações da interface do usuário do Transmissão : os tokens podem ser exibidos à medida que chegam.
- Validação de saída estruturada : a análise JSON garante o formato da resposta.
- Resiliência a erros : Lida com erros de API e falhas de análise de forma adequada.
- Correlação de rastreamento : vincula a saída de transmissão aos rastreamentos MLflow para depuração
Agregação de resposta multimodelo
def multi_model_reducer(chunks: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Aggregate responses from multiple models"""
responses = {}
latencies = {}
for chunk in chunks:
model = chunk.get("model")
if model:
responses[model] = chunk.get("response", "")
latencies[model] = chunk.get("latency", 0)
return {
"responses": responses,
"latencies": latencies,
"fastest_model": min(latencies, key=latencies.get) if latencies else None,
"consensus": len(set(responses.values())) == 1
}
Testando redutores de saída
Os redutores de saída podem ser testados independentemente da estrutura de rastreamento, facilitando a garantia de que eles lidam corretamente com casos extremos:
import unittest
from typing import List, Dict, Any
def my_reducer(chunks: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Example reducer to be tested"""
if not chunks:
return {"status": "empty", "total": 0}
total = sum(c.get("value", 0) for c in chunks)
errors = [c for c in chunks if c.get("error")]
return {
"status": "error" if errors else "success",
"total": total,
"count": len(chunks),
"average": total / len(chunks) if chunks else 0,
"error_count": len(errors)
}
class TestOutputReducer(unittest.TestCase):
def test_normal_case(self):
chunks = [
{"value": 10},
{"value": 20},
{"value": 30}
]
result = my_reducer(chunks)
self.assertEqual(result["status"], "success")
self.assertEqual(result["total"], 60)
self.assertEqual(result["average"], 20.0)
def test_empty_input(self):
result = my_reducer([])
self.assertEqual(result["status"], "empty")
self.assertEqual(result["total"], 0)
def test_error_handling(self):
chunks = [
{"value": 10},
{"error": "Network timeout"},
{"value": 20}
]
result = my_reducer(chunks)
self.assertEqual(result["status"], "error")
self.assertEqual(result["total"], 30)
self.assertEqual(result["error_count"], 1)
def test_missing_values(self):
chunks = [
{"value": 10},
{"metadata": "some info"}, # No value field
{"value": 20}
]
result = my_reducer(chunks)
self.assertEqual(result["total"], 30)
self.assertEqual(result["count"], 3)
Considerações sobre o desempenho
- Os redutores de saída recebem todos os blocos na memória de uma só vez. Para transmissões muito grandes, considere implementar alternativas de transmissão ou estratégias de chunking.
- O intervalo permanece aberto até que o gerador seja totalmente consumido, o que afeta as métricas de latência.
- Os redutores devem ser apátridas e evitar efeitos colaterais para garantir um comportamento previsível.
Tipos de função suportados
O decorador @mlflow.trace atualmente suporta os seguintes tipos de funções:
Tipo de função | Apoiado |
|---|---|
Sincronizar | Sim |
Assíncrono | Sim (MLflow >= 2.16.0) |
Gerador | Sim (MLflow >= 2.20.2) |
Gerador Assíncrono | Sim (MLflow >= 2.20.2) |
Recursos adicionais
- Rastreamento de trechos - Rastreie blocos de código específicos com controle mais granular.
- APIs de cliente de baixo nível - Aprenda cenários avançados que exigem controle total.
- Depure e observe seu aplicativo - Use seu aplicativo rastreado manualmente para depuração.