Rastreando txtai
O txtai é um banco de dados de embeddings completo para pesquisa semântica, LLM orquestração e fluxo de trabalho do modelo de linguagem.
MLflow Tracing oferece funcionalidade de rastreamento automático para txtai. O rastreamento automático para txtai pode ser ativado chamando a função mlflow.autolog, e o MLflow capturará rastreamentos para invocação de LLM, embeddings, AI Search e os registrará no experimento MLflow ativo.
Pré-requisitos
Para usar o MLflow Tracing com o txtai, o senhor precisa instalar o MLflow, a biblioteca txtai e a extensão mlflow-txtai.
- Development
- Production
Para ambientes de desenvolvimento, instale o pacote completo do MLflow com os extras do Databricks, txtai, e mlflow-txtai:
pip install --upgrade "mlflow[databricks]>=3.1" txtai mlflow-txtai
O pacote completo do mlflow[databricks] inclui todos os recursos para desenvolvimento local e experimentação no Databricks.
Para implantações de produção, instale mlflow-tracing, txtai e mlflow-txtai:
pip install --upgrade mlflow-tracing txtai mlflow-txtai
O pacote mlflow-tracing é otimizado para uso na produção.
O MLflow 3 é altamente recomendado para obter a melhor experiência de rastreamento com o txtai.
Antes de executar os exemplos, você precisará configurar seu ambiente:
Para usuários fora do Databricks Notebook : Defina seu Databricks variável de ambiente:
export DATABRICKS_HOST="https://your-workspace.cloud.databricks.com"
export DATABRICKS_TOKEN="your-personal-access-token"
Para usuários do Databricks Notebook : Essas credenciais são definidas automaticamente para o senhor.
API chave : Verifique se a chave do provedor LLM API está definida:
export OPENAI_API_KEY="your-openai-api-key"
# Add other provider keys as needed if using txtai with different models
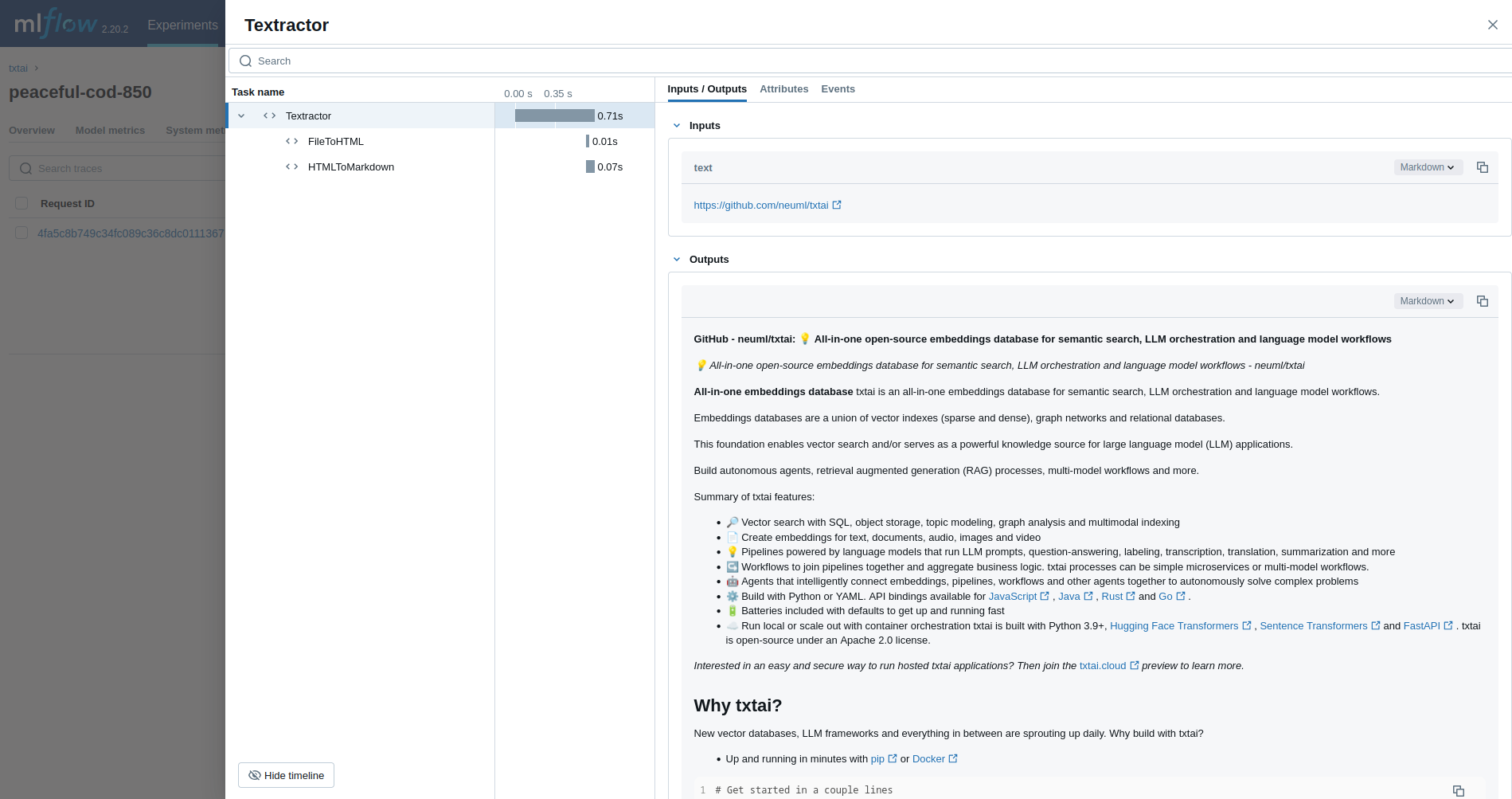
Exemplo básico
O primeiro exemplo rastreia um pipeline do Textractor.
Em serverless compute clusters, o autologging para estruturas de rastreamento genAI não é ativado automaticamente. Você deve habilitar explicitamente o registro automático chamando a função mlflow.<library>.autolog() apropriada para as integrações específicas que você deseja rastrear.
import mlflow
from txtai.pipeline import Textractor
import os
# Ensure any necessary LLM provider API keys are set in your environment if Textractor uses one
# For example, if it internally uses OpenAI:
# os.environ["OPENAI_API_KEY"] = "your-openai-key"
# Enable MLflow auto-tracing for txtai
mlflow.txtai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/txtai-demo")
# Define and run a simple Textractor pipeline.
textractor = Textractor()
textractor("https://github.com/neuml/txtai")
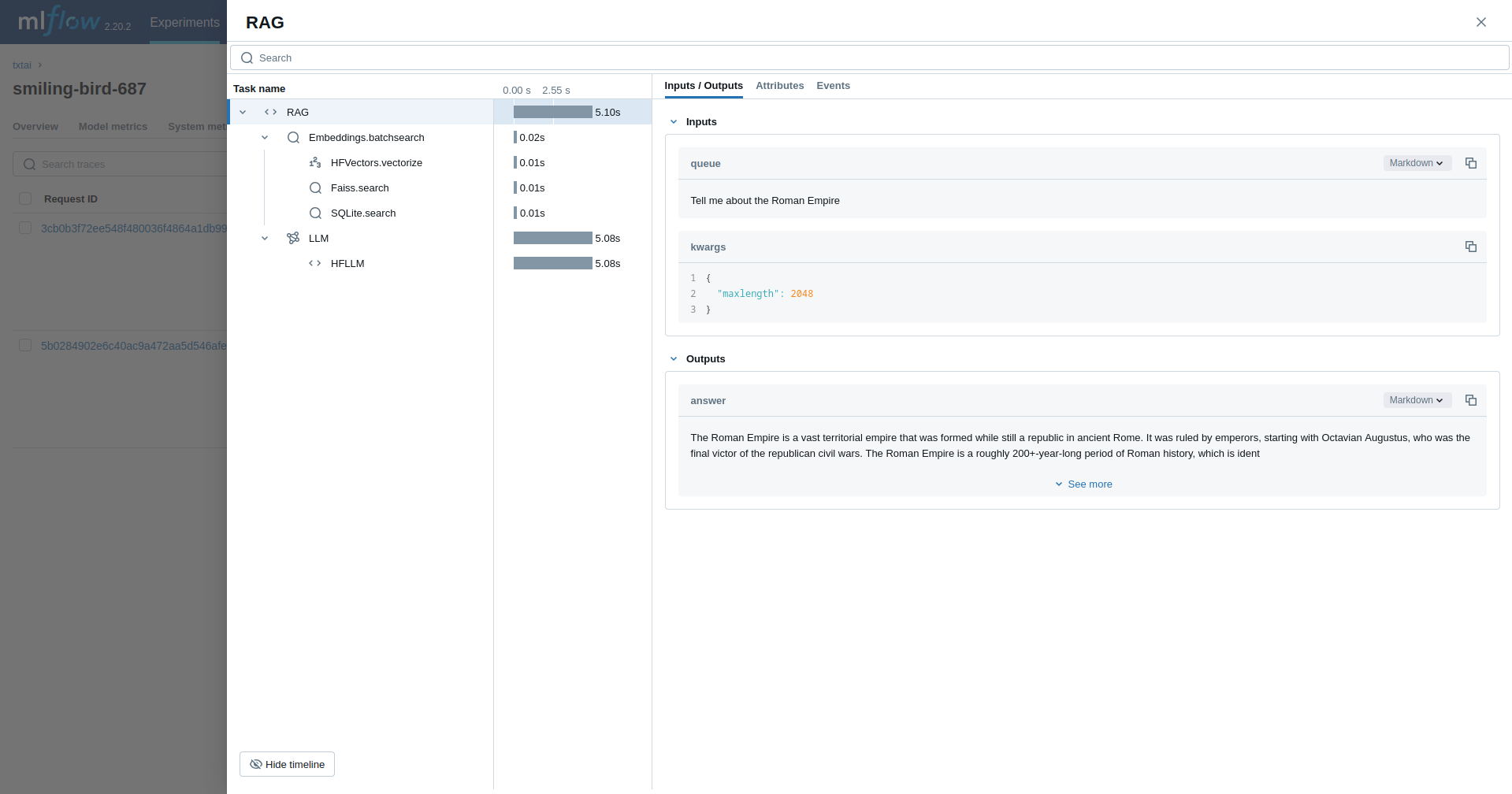
Geração aumentada de recuperação (RAG)
O próximo exemplo traça um pipeline RAG.
import mlflow
from txtai import Embeddings, RAG
import os
# Ensure your LLM provider API key (e.g., OPENAI_API_KEY for the Llama model via some services) is set
# os.environ["OPENAI_API_KEY"] = "your-key" # Or HUGGING_FACE_HUB_TOKEN, etc.
# Enable MLflow auto-tracing for txtai
mlflow.txtai.autolog()
# Set up MLflow tracking to Databricks if not already configured
# mlflow.set_tracking_uri("databricks")
# mlflow.set_experiment("/Shared/txtai-rag-demo")
wiki = Embeddings()
wiki.load(provider="huggingface-hub", container="neuml/txtai-wikipedia-slim")
# Define prompt template
template = """
Answer the following question using only the context below. Only include information
specifically discussed.
question: {question}
context: {context} """
# Create RAG pipeline
rag = RAG(
wiki,
"hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4",
system="You are a friendly assistant. You answer questions from users.",
template=template,
context=10,
)
rag("Tell me about the Roman Empire", maxlength=2048)
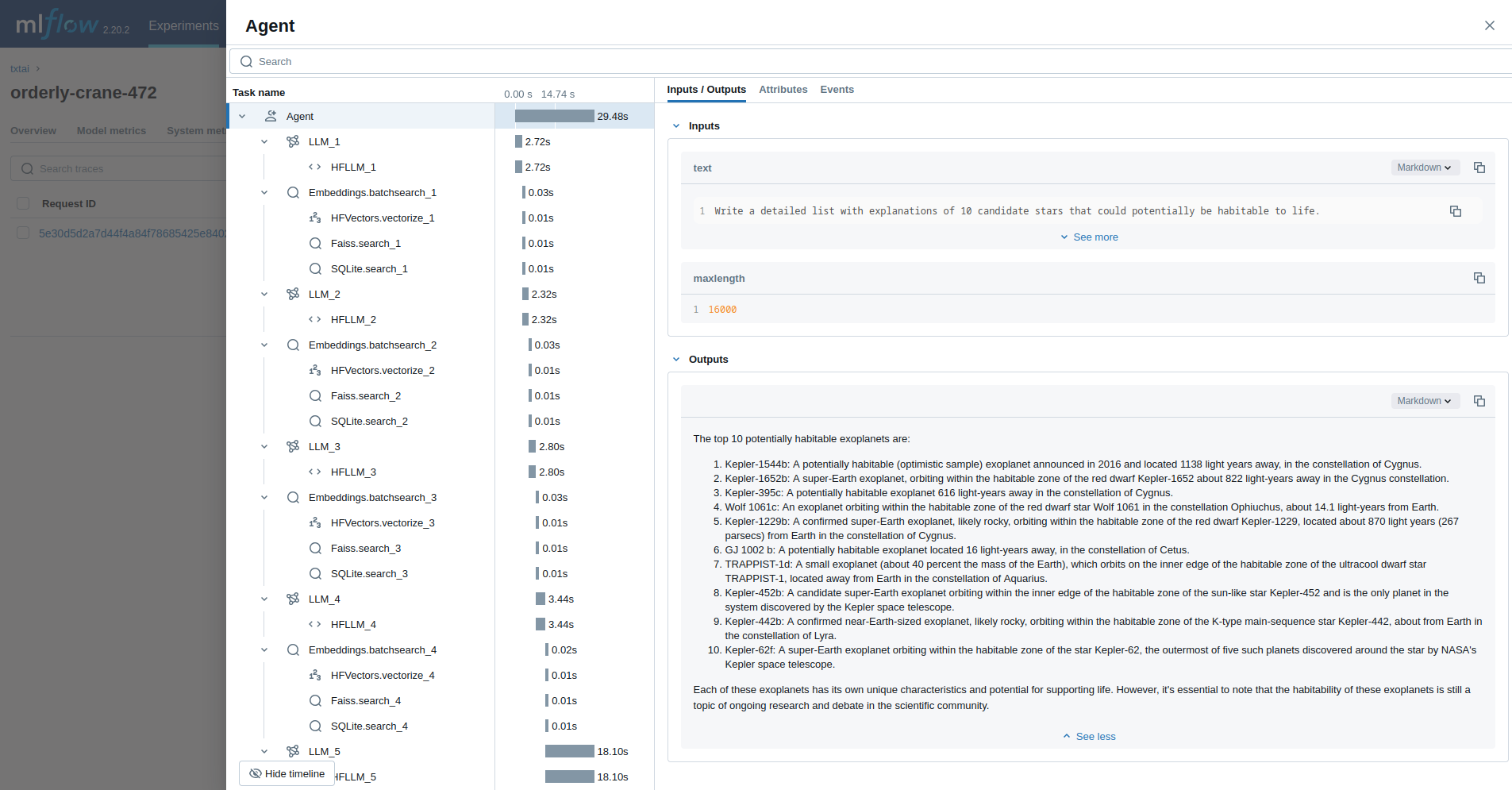
Agente
O último exemplo executa um agente txtai projetado para pesquisar questões sobre astronomia.
import mlflow
from txtai import Agent, Embeddings
import os
# Ensure your LLM provider API key (e.g., OPENAI_API_KEY for the Llama model via some services) is set
# os.environ["OPENAI_API_KEY"] = "your-key" # Or HUGGING_FACE_HUB_TOKEN, etc.
# Enable MLflow auto-tracing for txtai
mlflow.txtai.autolog()
# Set up MLflow tracking to Databricks if not already configured
# mlflow.set_tracking_uri("databricks")
# mlflow.set_experiment("/Shared/txtai-agent-demo")
def search(query):
"""
Searches a database of astronomy data.
Make sure to call this tool only with a string input, never use JSON.
Args:
query: concepts to search for using similarity search
Returns:
list of search results with for each match
"""
return embeddings.search(
"SELECT id, text, distance FROM txtai WHERE similar(:query)",
10,
parameters={"query": query},
)
embeddings = Embeddings()
embeddings.load(provider="huggingface-hub", container="neuml/txtai-astronomy")
agent = Agent(
tools=[search],
llm="hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4",
max_iterations=10,
)
researcher = """
{command}
Do the following.
- Search for results related to the topic.
- Analyze the results
- Continue querying until conclusive answers are found
- Write a Markdown report
"""
agent(
researcher.format(
command="""
Write a detailed list with explanations of 10 candidate stars that could potentially be habitable to life.
"""
),
maxlength=16000,
)
Recursos adicionais
Para mais exemplos e orientações sobre como usar txtai com o MLflow, consulte a documentação da extensão txtai do MLflow.
Recursos adicionais
- Entenda os conceitos de rastreamento - Saiba como o site MLflow captura e organiza os dados de rastreamento para o RAG e o fluxo de trabalho do agente
- Depure e observe seu aplicativo - Use a interface do usuário do Trace para analisar o comportamento do seu aplicativo txtai
- Avalie a qualidade do seu aplicativo - Configure a avaliação de qualidade para seus aplicativos de pesquisa semântica e RAG