Agentes de rastreamento implantados no Databricks
Implante aplicativos de AI no Databricks para que os rastreamentos de produção sejam capturados automaticamente. Você pode implantar aplicativos de AI no Databricks usando Agentes Personalizados (recomendado) ou Model Serving de CPU personalizado. Independentemente do método de implantação escolhido, o Databricks registra rastreamentos no seu experimento do MLflow para visualização em tempo real.
Para aplicativos implantados fora Databricks, consulte Agentes de rastreamento implantados fora do Databricks.
Escolha um local de armazenamento de rastreamento
Databricks logs os rastreamentos do experimento MLflow que você configurou com mlflow.set_experiment(...) durante a implantação. Os rastreamentos estão disponíveis para visualização em tempo real na interface do usuário do MLflow.
Para armazenamento durável, governado e consultável, a Databricks recomenda vincular o experimento a um local de rastreamento do Unity Catalog para que os rastreamentos cheguem às tabelas Delta do Unity Catalog. Este é o backend recomendado para produção. Consulte Armazenar rastreamentos OpenTelemetry no Unity Catalog.
Se você não usar um local de rastreamento do Unity Catalog, os rastreamentos serão armazenados como artefatos, para os quais você pode especificar um local de armazenamento personalizado. Por exemplo, se você criar um experimento de workspace com artifact_location definido para um volume do Unity Catalog, o acesso aos dados de rastreamento será governado pelos privilégios de volume do Unity Catalog.
Qualquer identidade que leia dados de rastreamento armazenados em um volume do Unity Catalog deve ter o privilégio READ VOLUME nesse volume, além do acesso ao experimento do MLflow. Isso inclui a identidade usada por sua carga de trabalho de produção ou de serviço, não apenas usuários interativos.
Implantar com Agentes Personalizados (recomendado)
Quando você fizer o deploy de aplicativos de IA generativa usando Agentes Personalizados, o MLflow Tracing funciona automaticamente sem configuração adicional. Os rastreamentos são armazenados no experimento do MLflow do agente.
Configure o(s) local(is) de armazenamento para os rastreamentos:
- Se o senhor planeja usar o monitoramento de produção para armazenar traços nas tabelas Delta, certifique-se de que ele esteja ativado para o seu workspace.
- Crie um MLflow Experiment para armazenar os traços de produção do seu aplicativo.
Em seguida, no seu notebook Python, instrumente seu agente com o MLflow Tracing e use Agentes Personalizados para implantar seu agente:
- Instale a versão mais recente de
mlflow[databricks]em seu ambiente Python. - Conecte-se ao experimento MLflow usando
mlflow.set_experiment(...). - Envolva seu código de agente usando MLflow
ResponsesAgent. No código do seu agente, habilite MLflow Tracing usando instrumentação automática ou manual . - Registre seu agente como um modelo MLflow e registre-o em Unity Catalog.
- Certifique-se de que
mlflowesteja nas dependências Python do modelo, com a mesma versão de pacote usada no ambiente do Notebook. - Use
agents.deploy(...)para implantar o modelo Unity Catalog (agente) em um modelo de serviço endpoint.
Se você implantar um agente a partir de um Notebook armazenado em uma pasta Git Databricks, o rastreamento em tempo real MLflow 3 não funcionará por default.
Para habilitar o rastreamento em tempo real, defina o experimento como um experimento não associado ao Git usando mlflow.set_experiment() antes de executar agents.deploy().
Este Notebook demonstra a implantação dos passos acima.
Agentes Personalizados e MLflow Tracing Notebook
implantado com serviço de CPU personalizado (alternativa)
Se você não puder usar Agentes Personalizados, implante seu agente usando o Model Serving de CPU personalizado.
Primeiro, configure o (s) local (s) de armazenamento para rastreamentos:
- Se o senhor planeja usar o monitoramento de produção para armazenar traços nas tabelas Delta, certifique-se de que ele esteja ativado para o seu workspace.
- Crie um MLflow Experiment para armazenar os traços de produção do seu aplicativo.
Em seguida, no Notebook Python, instale seu agente com MLflow Tracing e use a UI servindo modelo ou APIs para implantar seu agente:
- Registre seu agente como um modelo MLflow com instrumentação de rastreamento automática ou manual .
- implantado o modelo para servir a CPU.
- provisionamento a entidade de serviço ou Personal access token (PAT) com acesso
CAN_EDITao experimento MLflow. - Na página do endpoint de serviço da CPU, acesse "Edit endpoint." Para cada modelo implantado a ser rastreado, adicione a seguinte variável de ambiente:
ENABLE_MLFLOW_TRACING=trueMLFLOW_EXPERIMENT_ID=<ID of the experiment you created>- Se o senhor provisionar uma entidade de serviço, defina
DATABRICKS_CLIENT_IDeDATABRICKS_CLIENT_SECRET. Se o senhor provisionar um PAT, definaDATABRICKS_HOSTeDATABRICKS_TOKEN.
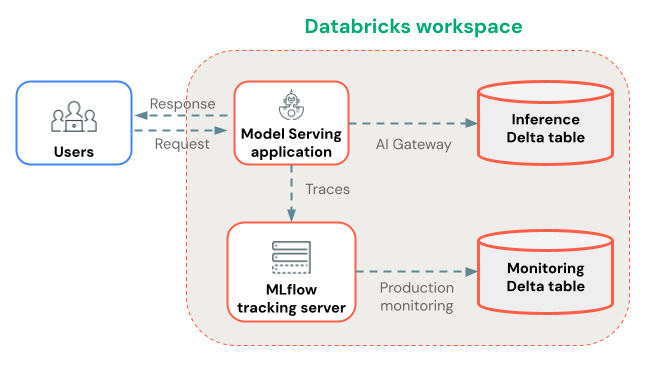
Armazene rastreando a produção a longo prazo.
Após os rastreamentos serem registrados em seu experimento MLflow , você pode, opcionalmente, armazená-los a longo prazo em tabelas Delta usando o monitoramento de produção (em versão beta).
Benefícios do monitoramento da produção para armazenamento de traços:
- Armazenamento durável : Armazene rastros em tabelas Delta para retenção a longo prazo, além do ciclo de vida do artefato do experimento MLflow.
- Sem limites de tamanho de rastreamento : Ao contrário de outros métodos de armazenamento, o monitoramento de produção lida com rastreamentos de qualquer tamanho.
- Avaliação automatizada da qualidade : execução de avaliadores MLflow em rastreamentos de produção para monitorar continuamente a qualidade da aplicação.
- Sincronização rápida : os rastreamentos são sincronizados com as tabelas Delta aproximadamente a cada 15 minutos.
Alternativamente, você pode usar tabelas de inferência habilitadas para AI Gateway para armazenar rastreamentos. No entanto, esteja ciente das limitações nos tamanhos de rastreamento e nos atrasos de sincronização.
Recursos adicionais
- Visualizar rastreamentos na interface do usuário Databricks MLflow - visualizar rastreamentos na interface do usuário MLflow .
- Monitoramento da produção - Armazene rastros em tabelas Delta para retenção a longo prazo e avalie automaticamente com ferramentas de pontuação.
- Adicione contexto aos rastreamentos - Anexe metadados para acompanhamento de solicitações, sessões de usuário e dados de ambiente.