Referência de ocultação de PII de rastreamentos do OTel
Esta página descreve uma arquitetura de referência para redigir PII de spans do OpenTelemetry (OTel) armazenados no Unity Catalog. Abrange dois fluxos complementares: processamento em lotes do lado do servidor e redação baseada em view na leitura. Ambos os fluxos usam AI Functions e Spark Declarative Pipelines. Para obter instruções de implantação e ativos para download, consulte Redigir PII de rastreamentos do OpenTelemetry no Unity Catalog.
Parâmetros
Todos os componentes nesta solução são parametrizados para serem reutilizados entre ambientes.
Parâmetros da tabela
Parâmetro | Descrição | Exemplo |
|---|---|---|
| Catálogo do Unity Catalog que contém as tabelas OTel brutas. |
|
| Esquema do Unity Catalog que contém as tabelas OTel brutas. |
|
| Prefixo usado ao configurar o armazenamento de rastreamento OTel. |
|
| Catálogo do Unity Catalog para as tabelas de saída omitidas. |
|
| Esquema do Unity Catalog para as tabelas de saída anonimizadas. |
|
| TTL para dados não redigidos (compliance com GDPR). Defina como |
|
Nomes de tabela de origem derivados:
{source_catalog}.{source_schema}.{table_prefix}_otel_spans{source_catalog}.{source_schema}.{table_prefix}_otel_logs{source_catalog}.{source_schema}.{table_prefix}_otel_annotations
Regras de ocultação de PII
Parâmetro | Descrição | Exemplo |
|---|---|---|
| Lista de tipos de PII a serem ocultados. |
|
| Como mascarar PII: |
|
| Caractere usado para mascaramento |
|
| Campos OTel para aplicar a redação. |
|
| Chaves de atributo para ignorar a ocultação (por exemplo, |
|
| Padrões Regex para PII específicos do domínio. |
|
Fluxo 1: Processamento em Lote no Servidor (recomendado)
Este fluxo usa Spark Declarative Pipelines para materializar tabelas redigidas a partir das tabelas OTel brutas.
Por que usar um pipeline declarativo?
Consideração | LakeFlow Pipelines (tabela de transmissão) | Notebook e job agendado |
|---|---|---|
Processamento gradual | Integradas — tabelas de transmissão processam apenas novas linhas. | Gerenciamento manual de ponto de verificação com transmissão estructurada. |
Suporte para função de IA | Integrado em SQL. | Integrado em SQL. |
Monitoramento e alertas | UI de pipeline e log de eventos integrados. | Deve ser configurado separadamente. |
Nova tentativa e tratamento de falhas | Automático. | Manual. |
Linhagem | Acompanhamento automático da linhagem de dados do Unity Catalog. | Manual. |
computação sem servidor | Sim. | Sim (com jobs serverless). |
Sobrecarga de operações | Baixo — totalmente gerenciado. | Médio — gerenciar estado, agendamentos e alertas. |
Lakeflow pipelines com tabelas de transmissão são a melhor opção. Os intervalos OTel são somente de anexação, o que os torna ideais para a ingestão incremental de tabelas de transmissão. Funções de AI, como ai_mask, são integradas no SQL, tornando um pipeline SQL a implementação mais simples.
Arquitetura

Implementação
Etapa 1: Bloquear as tabelas brutas
Conceder acesso às tabelas brutas apenas para a entidade de serviço do pipeline e usuários administradores.
-- Restrict raw table access
GRANT USE CATALOG ON CATALOG ${source_catalog} TO `pii_pipeline_sp`;
GRANT USE SCHEMA ON SCHEMA ${source_catalog}.${source_schema} TO `pii_pipeline_sp`;
GRANT SELECT ON TABLE ${source_catalog}.${source_schema}.${table_prefix}_otel_spans TO `pii_pipeline_sp`;
GRANT SELECT ON TABLE ${source_catalog}.${source_schema}.${table_prefix}_otel_logs TO `pii_pipeline_sp`;
-- Revoke broader access
REVOKE SELECT ON TABLE ${source_catalog}.${source_schema}.${table_prefix}_otel_spans FROM `data_team`;
Etapa 2: Criar o pipeline SQL
Defina as tabelas de transmissão anonimizadas em pii_redaction_pipeline.sql.
-- =============================================================
-- Streaming Table: Redacted Spans
-- =============================================================
CREATE OR REFRESH STREAMING TABLE redacted_spans
COMMENT 'PII-redacted OTel spans'
TBLPROPERTIES (
'quality' = 'gold',
'pipelines.autoOptimize.zOrderCols' = 'trace_id,date'
)
AS
SELECT
trace_id,
span_id,
parent_span_id,
name,
kind,
start_time,
end_time,
status,
date,
record_id,
service_name,
time,
instrumentation_scope,
-- Redact span attributes (VARIANT field)
-- ai_mask replaces PII with masked values in free-text content
CASE
WHEN attributes IS NOT NULL THEN
ai_mask(
CAST(attributes AS STRING),
array(${pii_categories}) -- e.g. array('email','phone','ssn','name','address')
)
ELSE attributes
END AS attributes,
-- Redact resource attributes
CASE
WHEN resource:attributes IS NOT NULL THEN
named_struct(
'attributes',
ai_mask(
CAST(resource:attributes AS STRING),
array(${pii_categories})
),
'dropped_attributes_count',
resource:dropped_attributes_count
)
ELSE resource
END AS resource,
-- Redact events (may contain exception messages with PII)
CASE
WHEN events IS NOT NULL THEN
ai_mask(
CAST(events AS STRING),
array(${pii_categories})
)
ELSE events
END AS events,
-- Pass through links unchanged (typically just trace/span IDs)
links
FROM STREAM(${source_catalog}.${source_schema}.${table_prefix}_otel_spans);
-- =============================================================
-- Streaming Table: Redacted Logs
-- =============================================================
CREATE OR REFRESH STREAMING TABLE redacted_logs
COMMENT 'PII-redacted OTel logs'
AS
SELECT
trace_id,
span_id,
severity_number,
severity_text,
date,
record_id,
service_name,
time,
instrumentation_scope,
-- Redact log body
CASE
WHEN body IS NOT NULL THEN
ai_mask(
CAST(body AS STRING),
array(${pii_categories})
)
ELSE body
END AS body,
-- Redact log attributes
CASE
WHEN attributes IS NOT NULL THEN
ai_mask(
CAST(attributes AS STRING),
array(${pii_categories})
)
ELSE attributes
END AS attributes,
-- Redact resource attributes
CASE
WHEN resource:attributes IS NOT NULL THEN
named_struct(
'attributes',
ai_mask(
CAST(resource:attributes AS STRING),
array(${pii_categories})
),
'dropped_attributes_count',
resource:dropped_attributes_count
)
ELSE resource
END AS resource
FROM STREAM(${source_catalog}.${source_schema}.${table_prefix}_otel_logs);
-- =============================================================
-- Streaming Table: Annotations (passthrough — no PII expected)
-- =============================================================
CREATE OR REFRESH STREAMING TABLE redacted_annotations
COMMENT 'OTel annotations (passthrough, no PII redaction applied)'
AS
SELECT *
FROM STREAM(${source_catalog}.${source_schema}.${table_prefix}_otel_annotations);
Passo 3: crie o recurso do pipeline
Utilize a seguinte configuração como padrão.
{
"name": "otel-pii-redaction",
"catalog": "${target_catalog}",
"schema": "${target_schema}",
"serverless": true,
"continuous": false,
"channel": "CURRENT",
"configuration": {
"source_catalog": "<value>",
"source_schema": "<value>",
"table_prefix": "<value>",
"pii_categories": "'email','phone','ssn','credit_card','name','address'"
},
"libraries": [{ "file": { "path": "/Workspace/path/to/pii_redaction_pipeline.sql" } }]
}
Execute o pipeline no modo acionado (por exemplo, a cada 15 minutos ou a cada hora), dependendo dos seus requisitos de latência. Modo contínuo também é uma opção, mas aumenta o custo.
Etapa 4: Criar a view unificada nas tabelas editadas
-- Recreate the trace_unified view pointing at redacted tables
CREATE OR REPLACE VIEW ${target_catalog}.${target_schema}.${table_prefix}_trace_unified AS
SELECT
s.trace_id,
s.date,
min(s.start_time) AS request_time,
max(s.end_time) - min(s.start_time) AS execution_duration,
collect_list(
named_struct(
'span_id', s.span_id,
'parent_span_id', s.parent_span_id,
'name', s.name,
'kind', s.kind,
'start_time', s.start_time,
'end_time', s.end_time,
'status', s.status,
'attributes', s.attributes,
'events', s.events
)
) AS spans,
a.tags,
a.assessments
FROM ${target_catalog}.${target_schema}.redacted_spans s
LEFT JOIN ${target_catalog}.${target_schema}.redacted_annotations a
ON s.trace_id = a.target_id
GROUP BY s.trace_id, s.date, a.tags, a.assessments;
Etapa 5: conceder acesso mais amplo às tabelas redigidas
GRANT USE CATALOG ON CATALOG ${target_catalog} TO `data_team`;
GRANT USE SCHEMA ON SCHEMA ${target_catalog}.${target_schema} TO `data_team`;
GRANT SELECT ON SCHEMA ${target_catalog}.${target_schema} TO `data_team`;
Passo 6: configurar retenção nas tabelas brutas (opcional, para compliance com o GDPR)
Se retention_days estiver configurado (maior que 0), use auto time-to-live para excluir automaticamente as linhas expiradas. As tabelas de rastreamento OTel são tabelas Delta gerenciadas pelo Unity Catalog com time TIMESTAMP colunas, portanto, o auto-TTL é compatível. A otimização preditiva deve ser ativada no workspace (ou tabela).
ALTER TABLE ${source_catalog}.${source_schema}.${table_prefix}_otel_spans
DELETE ROWS ${retention_days} DAYS AFTER time;
ALTER TABLE ${source_catalog}.${source_schema}.${table_prefix}_otel_logs
DELETE ROWS ${retention_days} DAYS AFTER time;
O Databricks executa as operações DELETE, PURGE e VACUUM automaticamente em segundo plano — nenhum Job agendado é necessário.
O momento exato da exclusão não é garantido. Pode haver um buffer de até 6 dias entre a expiração da linha e a exclusão permanente, mais a duração da retenção de dados (default 7 dias). Se seus requisitos de compliance exigem cronogramas de exclusão rigorosos, use um Job agendado com DELETE manual e VACUUM como fallback. Consulte tempo de vida automático para obter detalhes sobre o cálculo de valores de configuração para um período de expiração de destino.
Fluxo 2: Anonimização baseada em view (sem duplicação de dados)
Este fluxo aplica ai_mask em uma view do Unity Catalog, portanto, a redação ocorre no momento da leitura e nenhuma cópia redigida é armazenada.
Quando usar
- O custo de armazenamento é uma preocupação primordial.
- Dados anonimizados são consultados com pouca frequência.
- É aceitável pagar o custo de compute em cada query.
Arquitetura
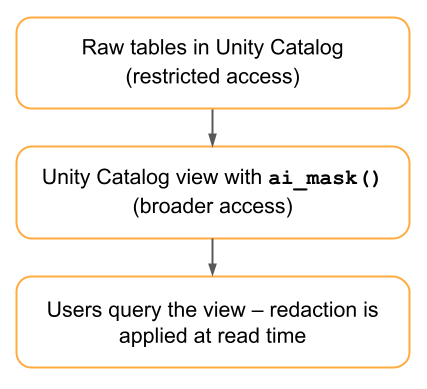
Implementação
CREATE OR REPLACE VIEW ${target_catalog}.${target_schema}.${table_prefix}_otel_spans_redacted
AS
SELECT
trace_id,
span_id,
parent_span_id,
name,
kind,
start_time,
end_time,
status,
date,
service_name,
time,
instrumentation_scope,
links,
ai_mask(
CAST(attributes AS STRING),
array(${pii_categories})
) AS attributes,
ai_mask(
CAST(events AS STRING),
array(${pii_categories})
) AS events,
named_struct(
'attributes',
ai_mask(CAST(resource:attributes AS STRING), array(${pii_categories})),
'dropped_attributes_count',
resource:dropped_attributes_count
) AS resource
FROM ${source_catalog}.${source_schema}.${table_prefix}_otel_spans;
Compensações
Aspecto | Vantagens | Desvantagens |
|---|---|---|
Armazenar | Não é permitida a duplicação. | — |
Compute | — |
|
Latência | Reflete imediatamente os novos dados. | Resposta de query mais lenta. |
Flexibilidade | As regras de redação são atualizadas instantaneamente. | — |
Comparação de Fluxo
Dimensão | Fluxo 1: pipeline em lotes | Fluxo 2: baseada em view |
|---|---|---|
Fidelidade de dados preservada | Sim (tabela bruta retida). | Sim (tabela bruta retida). |
Custo de armazenamento | 2x (com janelamento de tempo, ou cerca de 1x se o TTL automático se aplicar). | 1 vez |
Custo de compute | Uma vez por registro. | Por consulta. |
Desempenho da query | Rápido (pré-materializado). | Lento (recalcula). |
Latência e disponibilidade | Minutos (intervalo do pipeline). | Imediatamente. |
Lançamento da alteração da regra | Refresh do pipeline. | Instantâneo. |
GDPR compliance | TTL automático ou limpeza programada em tabelas brutas. | TTL automático ou limpeza programada em tabelas brutas. |
Melhor para | Uso principal na produção | Uso de baixo volume de query. |
recurso do Databricks | LakeFlow Pipelines. | Unity Catalog view e AI Functions. |
Abordagem recomendada
Use **Fluxo 1 (pipeline de lotes)** como a principal solução para a maioria das implantações corporativas:
- Preserva dados com fidelidade total para depuração autorizada.
- Otimiza o desempenho de queries por meio de materialização.
- Suporta compliance com o GDPR com retenção automática de TTL em dados brutos.
- Gerencia tanto a ocultação de PII quanto a filtragem de rastros em um único pipeline.
- É totalmente gerenciado com monitoramento e alertas integrados.
Use **Flow 2 (view-based)** como uma opção leve para cenários de baixo volume de consulta, ou como uma solução provisória rápida enquanto você configura o Flow 1.
Pré-requisitos
- AI Functions ativadas — exige um SQL warehouse ou serverless compute com acesso a AI Functions.
- Unity Catalog — Rastreamentos OTel devem ser armazenados em tabelas do Unity Catalog com a vinculação de rastreamento do MLflow ao Unity Catalog configurada. Consulte Armazenar rastreamentos OpenTelemetry no Unity Catalog.
- Entidade de serviço : para a execução de pipeline, com concessões apropriadas nas tabelas de origem.
- **Endpoint
ai_maskdo modelo básico** — usa um modelo de fundação. Verifique se o endpoint está disponível e dimensionado para a taxa de transferência.
Lista de verificação de implementação
- Validar o comportamento de
ai_maskem colunas VARIANT com dados de amostra de spans OTel. - Dimensione a taxa de transferência de
ai_maskpara definir o intervalo de agendamento do pipeline. - Defina as chaves de atributo permitidas que devem ignorar a ocultação.
- Configurar grupos de controle de acesso (acesso bruto versus acesso editado).
- Configurar TTL automático para retenção de tabela bruta (ou um Job agendado de
DELETEeVACUUM, se for necessário um tempo de exclusão rigoroso). - Construir um painel de monitoramento para a integridade do pipeline e cobertura de anonimização.