Tutorial: EDA técnicas usando o Databricks Notebook
Use Python em um notebook do Databricks para realizar análise exploratória de dados (EDA): carregar e limpar um dataset, explorar suas características e visualizar tendências para gerar percepções.
O Notebook usado neste site tutorial examina os dados globais de energia e emissões e demonstra como carregar, limpar e explorar dados.
O senhor pode acompanhar usando o exemplo de Notebook ou criar seu próprio Notebook do zero.
O que é EDA?
A análise exploratória de dados (EDA) é uma etapa inicial essencial no processo de ciência de dados que envolve a análise e a visualização de dados para:
- Descubra suas principais características.
- Identifique padrões e tendências.
- Detecte anomalias.
- Entenda as relações entre variáveis.
EDA fornece percepções no site dataset, facilitando decisões informadas sobre análises estatísticas ou modelagem adicionais.
Com o Databricks Notebook, o data scientists pode executar o EDA usando ferramentas conhecidas. Por exemplo, este tutorial usa alguns Python biblioteca comuns para manipular e graficar dados, inclusive:
- Numpy : uma biblioteca fundamental para computação numérica, que oferece suporte a matrizes e matrizes e uma ampla gama de funções matemáticas para operar nessas estruturas de dados.
- Pandas : uma biblioteca avançada de análise e manipulação de dados, desenvolvida com base em NumPy, que oferece estruturas de dados como DataFrames para lidar com dados estruturados de forma eficiente.
- Plotly : uma biblioteca gráfica interativa que permite a criação de visualizações interativas de alta qualidade para análise e apresentação de dados.
- Matplotlib : uma biblioteca abrangente para criar visualizações estáticas, animadas e interativas em Python.
Databricks também fornece recursos integrados para ajudar você a explorar seus dados na saída do Notebook, como filtrar e pesquisar dados em tabelas e ampliar visualizações. Você também pode usar o Genie Code para ajudá-lo a escrever código para EDA.
Antes de começar
Para concluir este tutorial, o senhor precisa do seguinte:
- O senhor deve ter permissão para usar um recurso existente no site compute ou criar um novo recurso no site compute. Veja computar.
- [Opcional] Este tutorial descreve como usar o Genie Code para ajudar você a gerar código. Consulte Usar o código Genie para obter mais informações.
Faça o download do arquivo dataset e importe o arquivo CSV
Este tutorial demonstra as técnicas de EDA examinando dados globais de energia e emissões. Para acompanhar, download o conjunto de dados de consumo de energia do Our World in Data do Kaggle. Este tutorial usa o arquivo owid-energy-data.csv.
Para importar o dataset para seu Databricks workspace:
-
Na barra lateral do site workspace, clique em workspace para navegar até o navegador workspace.
-
Arraste e solte o arquivo CSV,
owid-energy-data.csv, em seu workspace.Isso abre o modal de importação . Observe a pasta Target listada aqui. Isso é definido como sua pasta atual no navegador workspace e se torna o destino do arquivo importado.
-
Clique em Importar . O arquivo deve aparecer na pasta de destino em seu site workspace.
-
O senhor precisa do caminho do arquivo para carregar o arquivo no Notebook posteriormente. Localize o arquivo em seu navegador workspace. Para copiar o caminho do arquivo para sua área de transferência, clique com o botão direito do mouse no nome do arquivo e selecione Copiar URL/caminho > Caminho completo.
Criar um novo Notebook
Para criar um novo Notebook na página inicial da pasta do usuário, clique em ![]() New na barra lateral e selecione Notebook no menu.
New na barra lateral e selecione Notebook no menu.
Na parte superior, ao lado do nome do Notebook, selecione Python como o idioma default para o Notebook.
Para saber mais sobre como criar e gerenciar o Notebook, consulte gerenciar o Notebook.
Adicione cada um dos exemplos de código deste artigo a uma nova célula em seu Notebook. Ou use o Notebook de exemplo fornecido para acompanhar o site tutorial.
Carregar arquivo CSV
Em uma nova célula do Notebook, carregue o arquivo CSV. Para fazer isso, importe numpy e pandas. Esses são úteis Python biblioteca para ciência de dados e análise.
Crie um Pandas DataFrame a partir do dataset para facilitar o processamento e a visualização. Substitua o caminho do arquivo abaixo por aquele que o senhor copiou anteriormente.
import numpy as np
import pandas as pd # Data processing, CSV file I/O (e.g. pd.read_csv)
df=pd.read_csv('/Workspace/Users/demo@databricks.com/owid-energy-data.csv') # Replace the file path here with the workspace path you copied earlier
execução da célula. A saída deve retornar o endereço Pandas DataFrame, incluindo uma lista de cada coluna e seu tipo.

Entenda os dados
Compreender os conceitos básicos do site dataset é fundamental para qualquer projeto de ciência de dados. Envolve se familiarizar com a estrutura, os tipos e a qualidade dos dados disponíveis.
Em um Notebook Databricks, o senhor pode usar o comando display(df) para exibir o dataset.
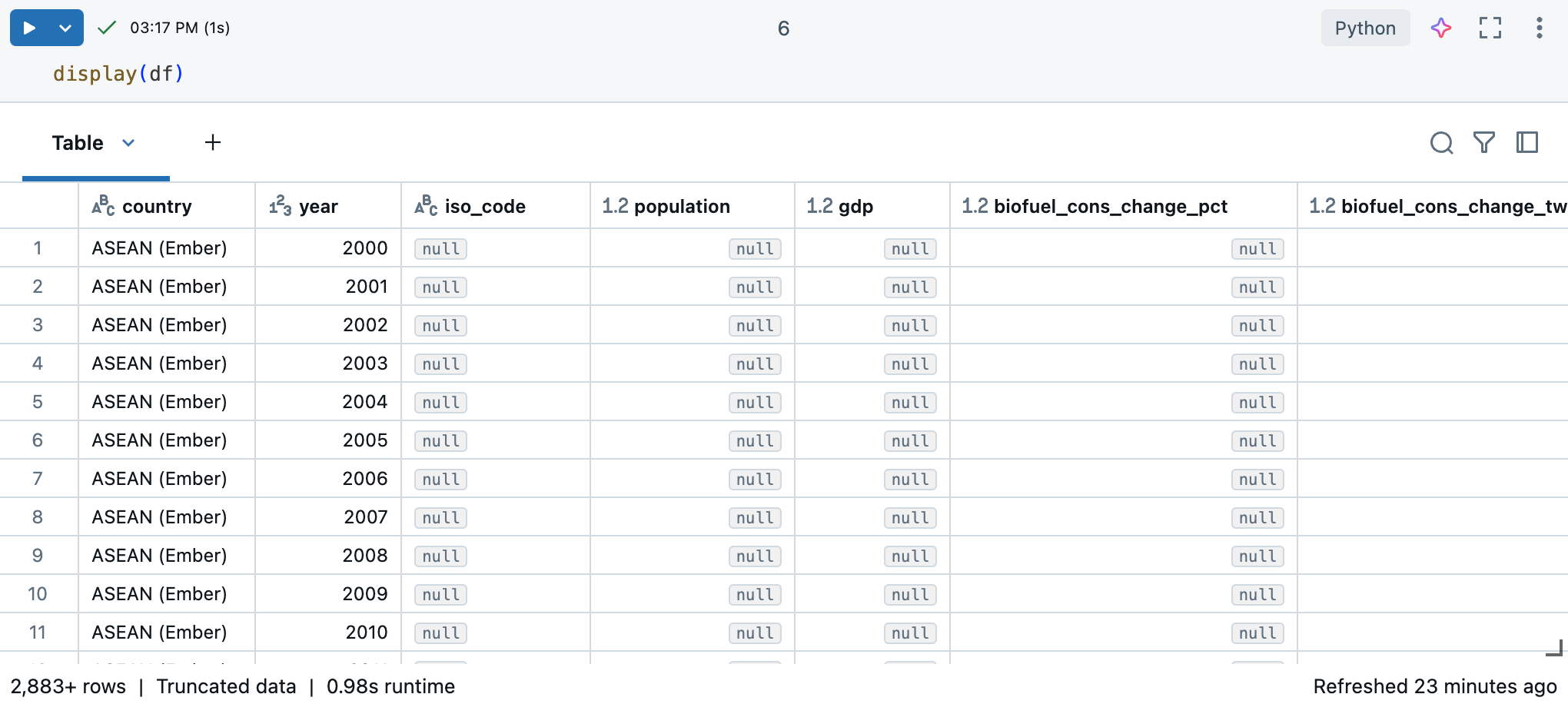
Como o site dataset tem mais de 10.000 linhas, esse comando retorna um dataset truncado. À esquerda de cada coluna, você pode ver o tipo de dados da coluna. Para saber mais, consulte Formatar colunas.
Use Pandas para percepções de dados
Para entender seu dataset de forma eficaz, use o seguinte Pandas comando:
-
O comando
df.shaperetorna as dimensões do DataFrame, dando ao senhor uma visão geral rápida do número de linhas e colunas.
-
O comando
df.dtypesfornece os tipos de dados de cada coluna, o que ajuda a entender o tipo de dados com os quais o senhor está lidando. Você também pode ver o tipo de dados de cada coluna na tabela de resultados.
-
O comando
df.describe()gera estatísticas descritivas para colunas numéricas, como média, desvio padrão e percentis, que podem ajudar a identificar padrões, detectar anomalias e compreender a distribuição dos seus dados. Use-o comdisplay()para ver estatísticas resumidas em um formato tabular com o qual você possa interagir. Consulte Explore o uso de dados na tabela de saída do Notebook Databricks.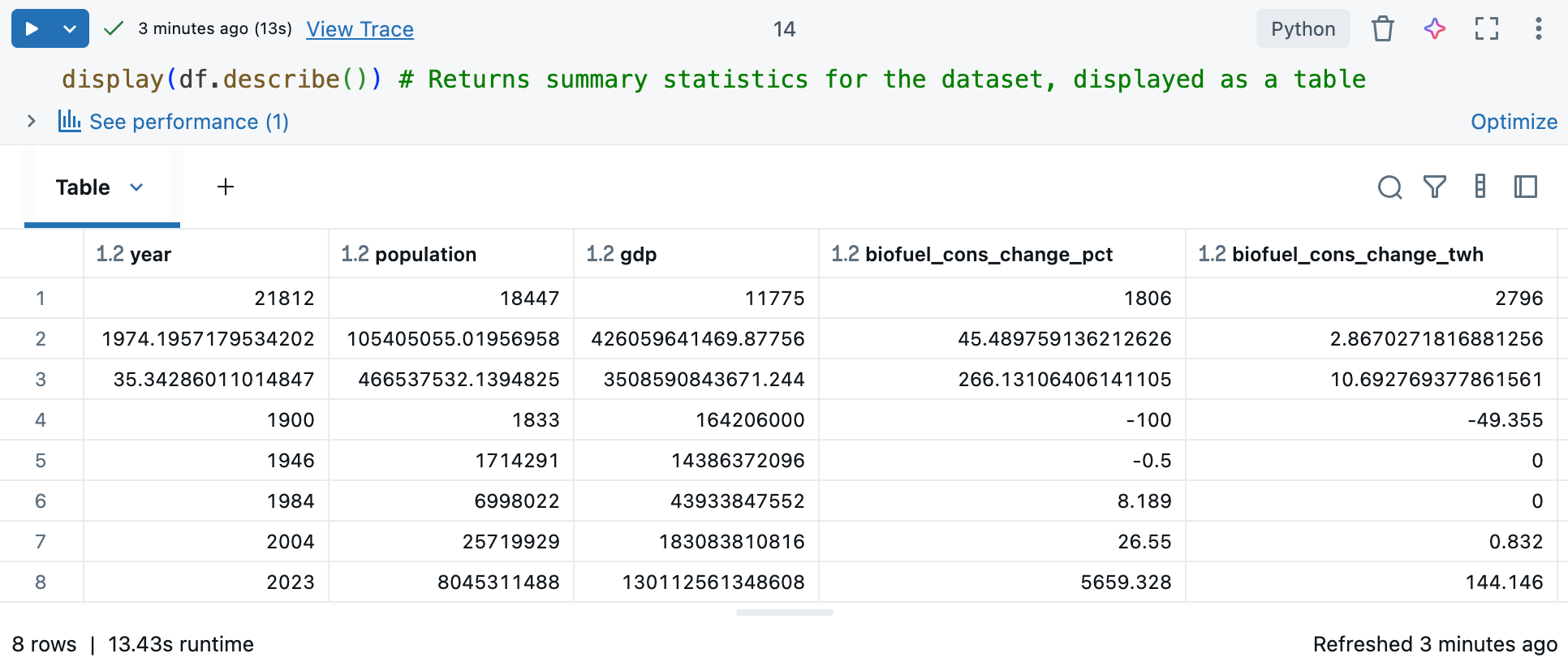
Gerar um perfil de dados
Disponível no Databricks Runtime 9.1 LTSe acima.
Databricks O notebook inclui recursos integrados de perfil de dados. Ao visualizar um DataFrame com a função de exibição do Databricks, o senhor pode gerar um perfil de dados a partir da saída da tabela.
# Display the DataFrame, then click "+ > Data Profile" to generate a data profile
display(df)
Clique em + > perfil de dados ao lado da tabela na saída. Essa execução é um novo comando que gera um perfil dos dados no site DataFrame.
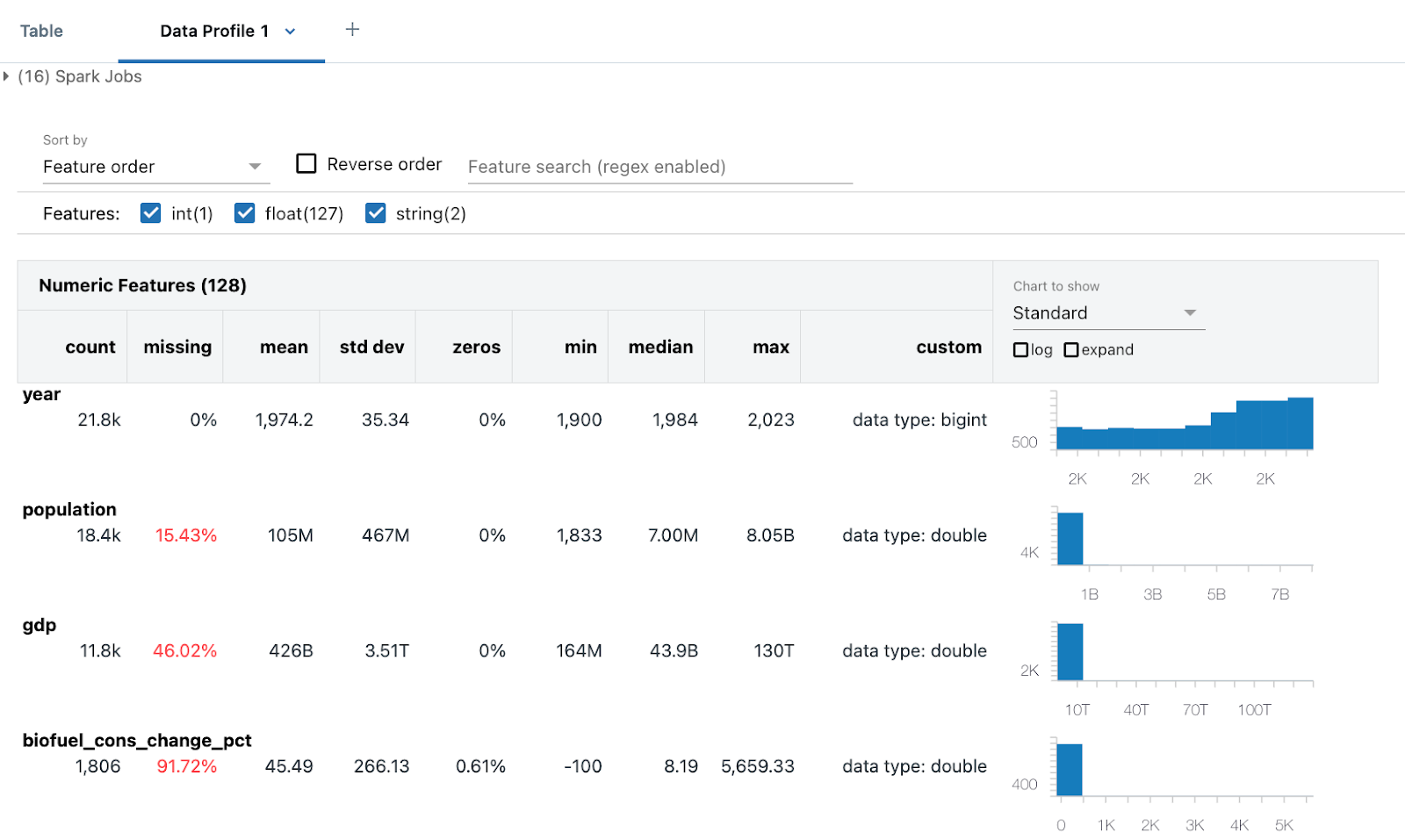
O perfil de dados inclui estatísticas resumidas para colunas numéricas, de cadeias de caracteres e de datas, bem como histogramas das distribuições de valores para cada coluna. O senhor também pode gerar perfis de dados programaticamente; consulte summarize comando (dbutils.data.summarize).
Limpe os dados
A limpeza dos dados é uma etapa essencial do EDA para garantir que o dataset seja preciso, consistente e esteja pronto para uma análise significativa. Esse processo envolve várias key tarefas para garantir que os dados estejam prontos para análise, inclusive:
- Identificação e remoção de dados duplicados.
- Tratamento de valores ausentes, o que pode envolver substituí-los por um valor específico ou remover as linhas afetadas.
- padronizar os tipos de dados (por exemplo, converter strings para
datetime) por meio de conversões e transformações para garantir a consistência. Talvez você também queira converter dados em um formato que seja mais fácil de trabalhar.
Essa fase de limpeza é essencial, pois melhora a qualidade e a confiabilidade dos dados, permitindo uma análise mais precisa e perspicaz.
Dica: Use Genie Code para ajudar na tarefa de limpeza de dados.
Use o Genie Code para ajudar a gerar código. Crie uma nova célula de código e clique no link gerar ou use o ícone do Genie Code no canto superior direito para abrir o Genie Code. Insira uma query para o Genie Code. O Genie Code pode gerar código Python ou SQL ou gerar uma descrição de texto. Para obter resultados diferentes, clique em Gerar novamente .
Por exemplo, experimente as seguintes instruções para usar o Genie Code e limpar os dados:
- Verifique se
dfcontém colunas ou linhas duplicadas. Imprima as duplicatas. Em seguida, exclua as duplicatas. - Em que formato estão as colunas de data? Mude para
'YYYY-MM-DD'. - Não vou usar a coluna
XXX. Exclua isso.
Veja Obtenha ajuda de programação da Genie Code.
Remover dados duplicados
Verifique se os dados têm linhas ou colunas duplicadas. Em caso afirmativo, remova-os.
Use o Genie Code para gerar código para você.
Tente inserir o seguinte comando: “Verifique se df contém colunas ou linhas duplicadas.” Imprima as cópias. Em seguida, exclua os duplicados.” O Genie Code pode gerar um código semelhante ao exemplo abaixo.
# Check for duplicate rows
duplicate_rows = df.duplicated().sum()
# Check for duplicate columns
duplicate_columns = df.columns[df.columns.duplicated()].tolist()
# Print the duplicates
print("Duplicate rows count:", duplicate_rows)
print("Duplicate columns:", duplicate_columns)
# Drop duplicate rows
df = df.drop_duplicates()
# Drop duplicate columns
df = df.loc[:, ~df.columns.duplicated()]
Nesse caso, o site dataset não tem dados duplicados.
Lidar com valores nulos ou ausentes
Uma forma comum de tratar valores NaN ou Null é substituí-los por 0 para facilitar o processamento matemático.
df = df.fillna(0) # Replace all NaN (Not a Number) values with 0
Isso garante que todos os dados ausentes no site DataFrame sejam substituídos por 0, o que pode ser útil para análises de dados subsequentes ou etapas de processamento em que os valores ausentes possam causar problemas.
Reformatar datas
As datas geralmente são formatadas de várias maneiras em diferentes conjuntos de dados. Eles podem estar no formato de data, strings, ou inteiros.
Para essa análise, trate a coluna year como um número inteiro. O código a seguir é uma forma de fazer isso:
# Ensure the 'year' column is converted to the correct data type (integer for year)
df['year'] = pd.to_datetime(df['year'], format='%Y', errors='coerce').dt.year
# Confirm the changes
df.year.dtype
Isso garante que a coluna year contenha somente valores inteiros de anos, com todas as entradas inválidas convertidas em NaT (Não é uma hora).
Explore o uso de dados na tabela de saída do Notebook “ Databricks ”.
Databricks fornece recurso integrado para ajudá-lo a explorar o uso de dados na tabela de saída.
Em uma nova célula, use display(df) para exibir o site dataset como uma tabela.
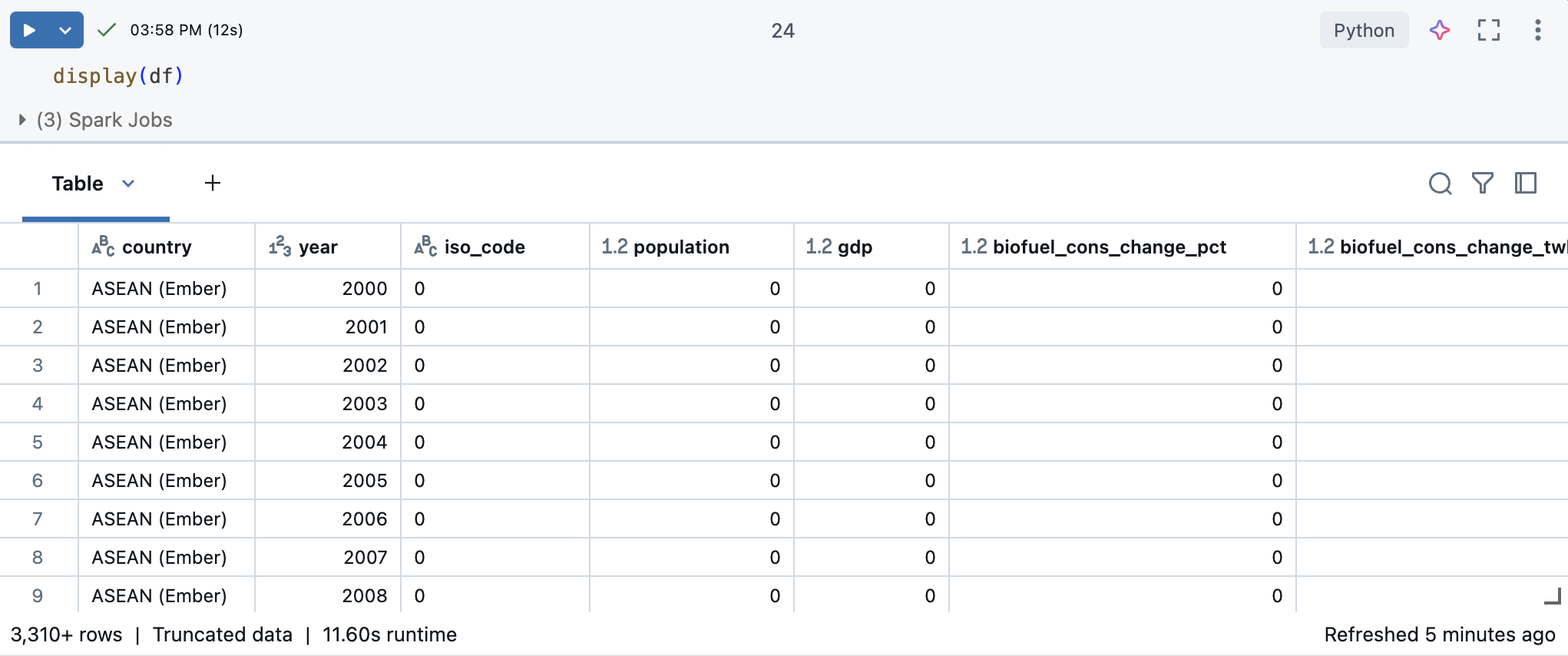
Usando a tabela de saída, você pode explorar seus dados de várias maneiras:
- Pesquisar os dados em busca de uma cadeia de caracteres ou valor específico
- Filtrar para condições específicas
- Crie visualizações usando o dataset
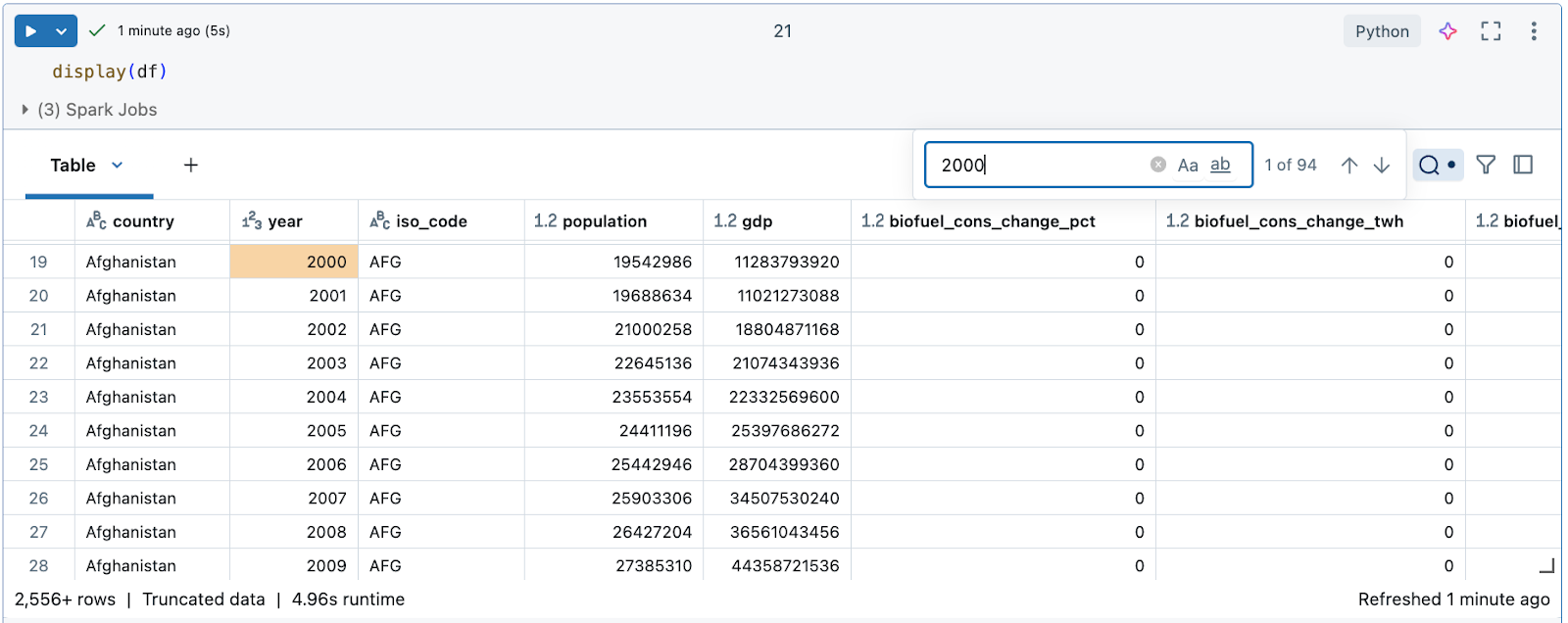
Pesquisar os dados em busca de uma cadeia de caracteres ou valor específico
Clique no ícone de pesquisa no canto superior direito da tabela e insira sua pesquisa.
Filtrar para condições específicas
O senhor pode usar os filtros da tabela integrada para filtrar suas colunas de acordo com condições específicas. Há várias maneiras de criar um filtro. Consulte Filtrar resultados.
Use o Genie Code para criar filtros. Clique no ícone de filtro no canto superior direito da tabela. Insira sua condição de filtro. O Genie Code gera um filtro automaticamente para você.
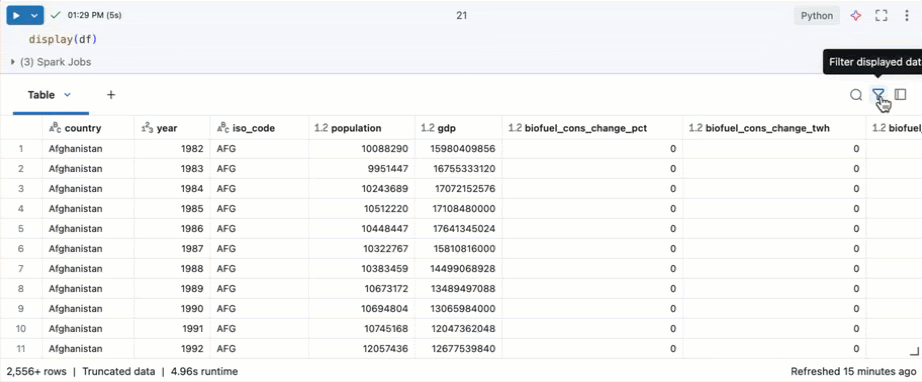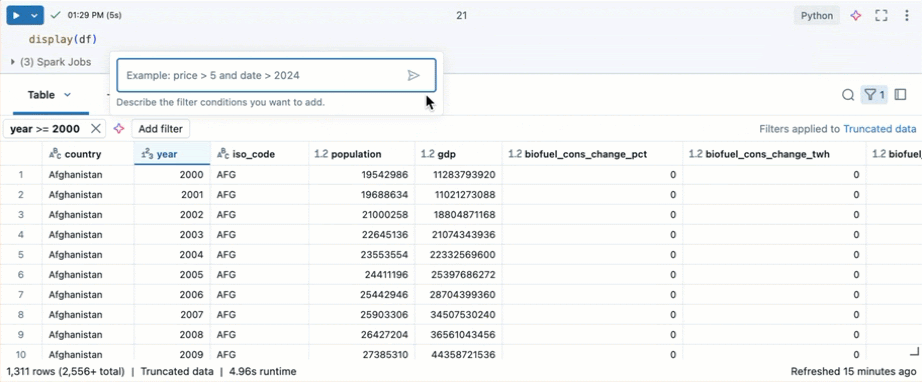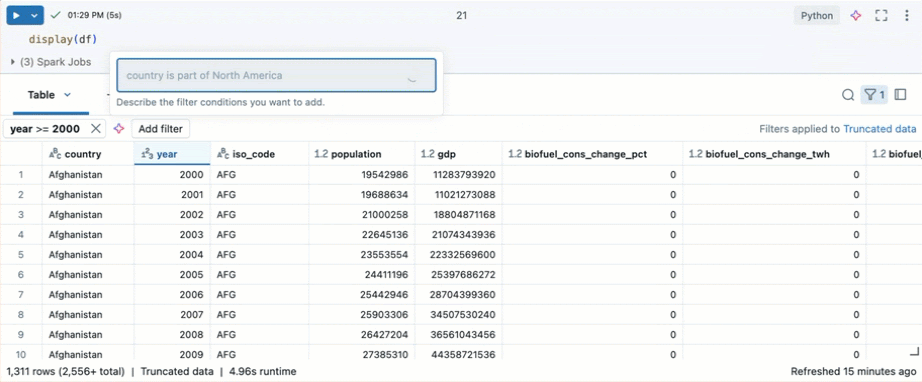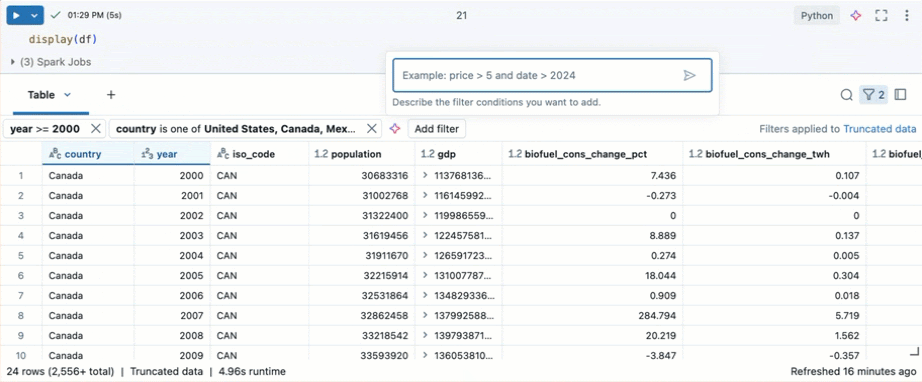
Crie visualizações usando o dataset
Na parte superior da tabela de saída, clique em + > Visualization para abrir o editor de visualização.
Selecione o tipo de visualização e as colunas que você gostaria de visualizar. O editor exibe uma visualização prévia do gráfico com base na sua configuração. Por exemplo, a imagem abaixo mostra como adicionar vários gráficos de linha para view o consumo de várias fontes de energia renovável ao longo do tempo.
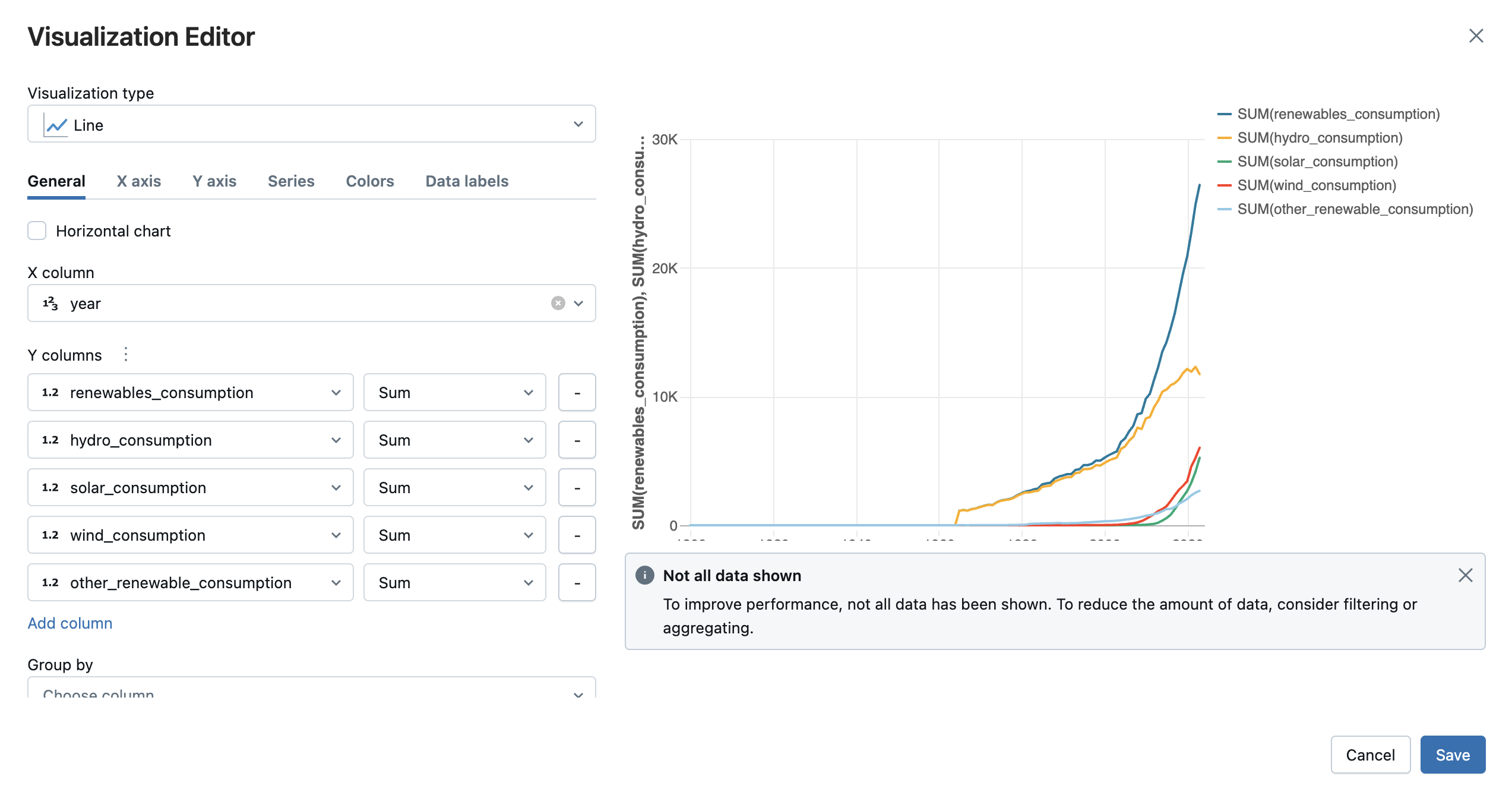
Clique em Save (Salvar) para adicionar a visualização como tab na saída da célula.
Consulte Criar uma nova visualização.
Explore e visualize o uso de dados Python biblioteca
A exploração de visualizações de uso de dados é um aspecto fundamental do site EDA. As visualizações ajudam a descobrir padrões, tendências e relacionamentos dentro dos dados que podem não ser imediatamente aparentes apenas por meio da análise numérica. Use uma biblioteca como Plotly ou Matplotlib para técnicas de visualização comuns, incluindo gráficos de dispersão, gráficos de barras, gráficos de linhas e histogramas. Essas ferramentas visuais permitem que o site data scientists identifique anomalias, compreenda as distribuições de dados e observe as correlações entre as variáveis. Por exemplo, o gráfico de dispersão pode destacar discrepâncias, enquanto o gráfico de séries temporais pode revelar tendências e sazonalidade.
- Crie uma matriz para países exclusivos
- Gráfico das tendências de emissões dos 10 maiores emissores (2000-2022)
- Filtrar e traçar as emissões por região
- Calcular e gráfico o crescimento da participação da energia renovável
- Graficar por dispersão: Mostrar o impacto da energia renovável para os principais emissores
- Modelo de consumo global de energia projetado
Crie uma matriz para países exclusivos
Examine os países incluídos no site dataset criando uma matriz para países exclusivos. A criação de uma matriz mostra as entidades listadas como country.
# Get the unique countries
unique_countries = df['country'].unique()
unique_countries
Saída:

entendimento:
A coluna country inclui várias entidades, incluindo países do mundo, países de alta renda, Ásia e Estados Unidos, que nem sempre são diretamente comparáveis. Pode ser mais útil filtrar os dados por região.
Gráfico das tendências de emissões dos 10 maiores emissores (2000-2022)
Digamos que você queira focar sua investigação nos 10 países com as maiores emissões de gases de efeito estufa nos anos 2000. Você pode filtrar os dados dos anos que deseja analisar e dos 10 principais países com mais emissões e, em seguida, usar o plotly para criar um gráfico de linhas mostrando suas emissões ao longo do tempo.
import plotly.express as px
# Filter data to include only years from 2000 to 2022
filtered_data = df[(df['year'] >= 2000) & (df['year'] <= 2022)]
# Get the top 10 countries with the highest emissions in the filtered data
top_countries = filtered_data.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
# Filter the data for those top countries
top_countries_data = filtered_data[filtered_data['country'].isin(top_countries)]
# Plot emissions trends over time for these countries
fig = px.line(top_countries_data, x='year', y='greenhouse_gas_emissions', color='country',
title="Greenhouse Gas Emissions Trends for Top 10 Countries (2000 - 2022)")
fig.show()
Saída:
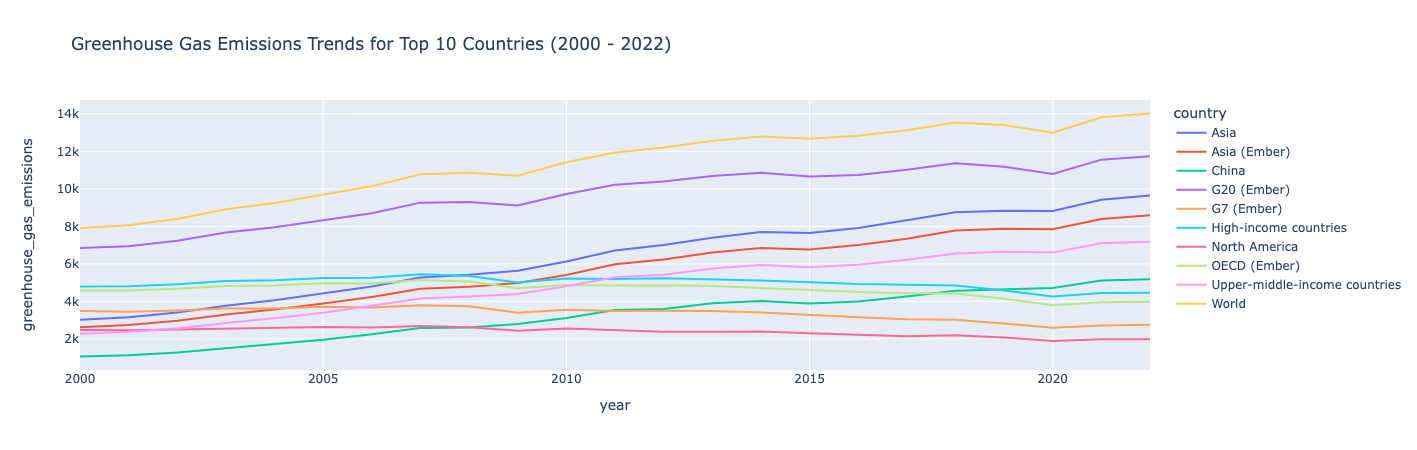
entendimento:
As emissões de gases de efeito estufa aumentaram de 2000 a 2022, com exceção de alguns países onde as emissões foram relativamente estáveis, com um ligeiro declínio nesse período.
Filtrar e traçar as emissões por região
Filtre os dados por região e calcule as emissões totais de cada região. Em seguida, graficar os dados como um gráfico de barras:
# Filter out regional entities
regions = ['Africa', 'Asia', 'Europe', 'North America', 'South America', 'Oceania']
# Calculate total emissions for each region
regional_emissions = df[df['country'].isin(regions)].groupby('country')['greenhouse_gas_emissions'].sum()
# Plot the comparison
fig = px.bar(regional_emissions, title="Greenhouse Gas Emissions by Region")
fig.show()
Saída:
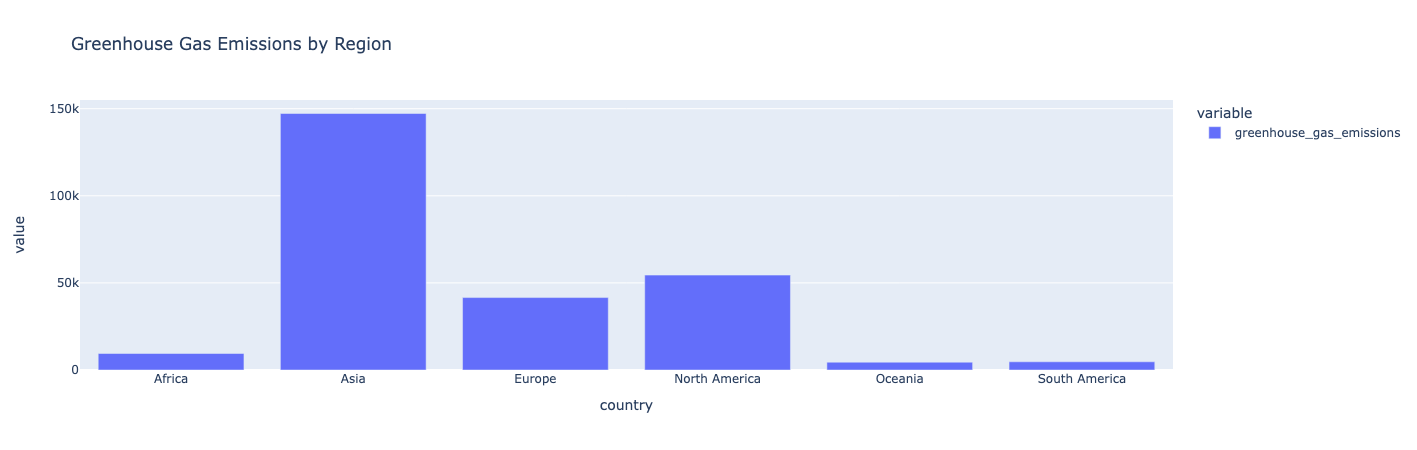
entendimento :
A Ásia tem as maiores emissões de gases de efeito estufa. Oceania, América do Sul e África produzem as menores emissões de gases de efeito estufa.
Calcular e gráfico o crescimento da participação da energia renovável
Crie um novo recurso/coluna que calcule a participação da energia renovável como uma proporção do consumo de energia renovável em relação ao consumo de energia primária. Em seguida, classifique os países com base em sua participação média de energia renovável. Para os 10 principais países, graficar sua participação na energia renovável ao longo do tempo:
# Calculate the renewable energy share and save it as a new column called "renewable_share"
df['renewable_share'] = df['renewables_consumption'] / df['primary_energy_consumption']
# Rank countries by their average renewable energy share
renewable_ranking = df.groupby('country')['renewable_share'].mean().sort_values(ascending=False)
# Filter for countries leading in renewable energy share
leading_renewable_countries = renewable_ranking.head(10).index
leading_renewable_data = df[df['country'].isin(leading_renewable_countries)]
# filtered_data = df[(df['year'] >= 2000) & (df['year'] <= 2022)]
leading_renewable_data_filter=leading_renewable_data[(leading_renewable_data['year'] >= 2000) & (leading_renewable_data['year'] <= 2022)]
# Plot renewable share over time for top renewable countries
fig = px.line(leading_renewable_data_filter, x='year', y='renewable_share', color='country',
title="Renewable Energy Share Growth Over Time for Leading Countries")
fig.show()
Saída:
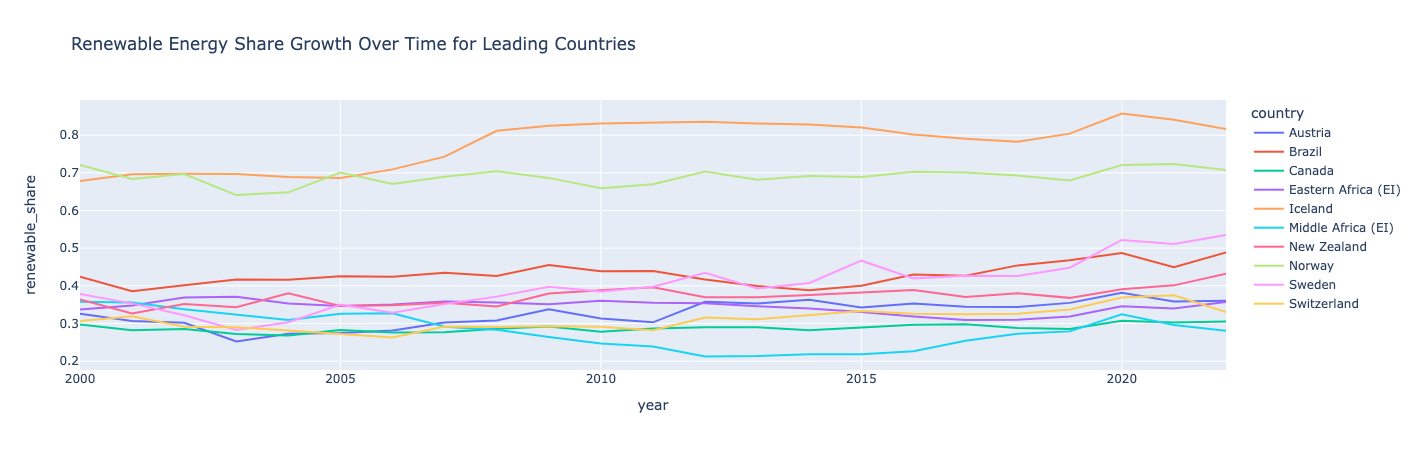
entendimento:
A Noruega e a Islândia lideram o mundo em energia renovável, com mais da metade de seu consumo proveniente de energia renovável.
A Islândia e a Suécia registaram o maior crescimento na sua quota de energias renováveis. Todos os países apresentaram oscilações ocasionais, demonstrando que o crescimento da participação das energias renováveis não é necessariamente linear. A África Central registrou uma queda no início da década de 2010, mas se recuperou em 2020.
Graficar por dispersão: Mostrar o impacto da energia renovável para os principais emissores
Filtre os dados para os 10 maiores emissores e, em seguida, use um gráfico de dispersão para observar a participação da energia renovável em relação às emissões de gases de efeito estufa ao longo do tempo.
# Select top emitters and calculate renewable share vs. emissions
top_emitters = df.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
top_emitters_data = df[df['country'].isin(top_emitters)]
# Plot renewable share vs. greenhouse gas emissions over time
fig = px.scatter(top_emitters_data, x='renewable_share', y='greenhouse_gas_emissions',
color='country', title="Impact of Renewable Energy on Emissions for Top Emitters")
fig.show()
Saída:
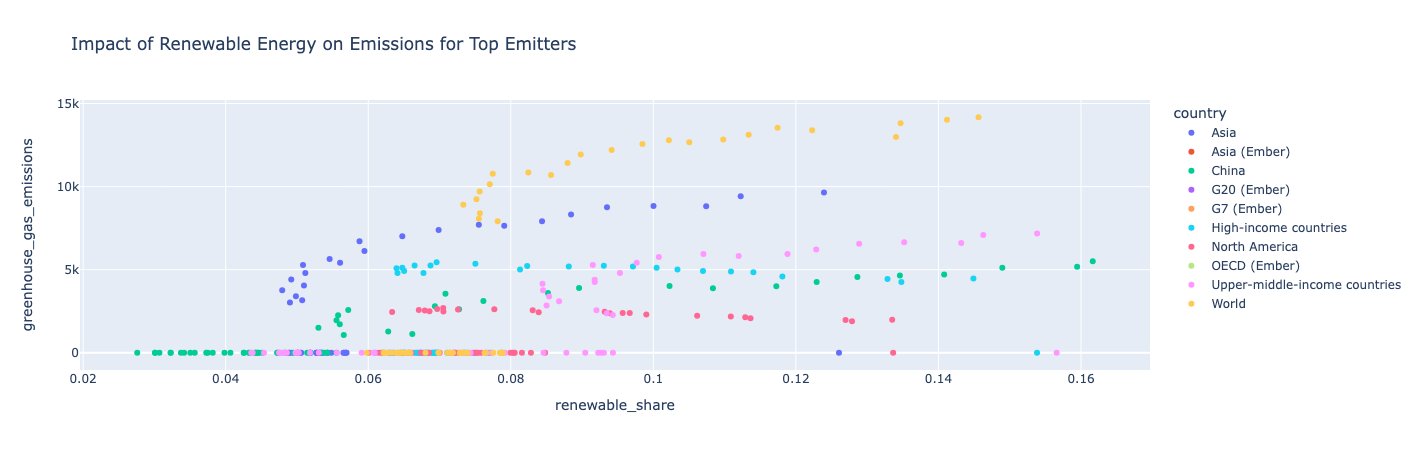
entendimento:
Como um país usa mais energia renovável, ele também tem mais emissões de gases de efeito estufa, o que significa que seu consumo total de energia aumenta mais rápido do que o consumo renovável. A América do Norte é uma exceção, pois suas emissões de gases de efeito estufa permaneceram relativamente constantes ao longo dos anos, à medida que sua participação renovável continuou a aumentar.
Modelo de consumo global de energia projetado
Agregue o consumo global de energia primária por ano e, em seguida, crie um modelo de média móvel integrada autorregressiva (ARIMA) para projetar o consumo total de energia global para os próximos anos. Graficar o histórico e a previsão de consumo de energia usando o site Matplotlib.
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt
# Aggregate global primary energy consumption by year
global_energy = df[df['country'] == 'World'].groupby('year')['primary_energy_consumption'].sum()
# Build an ARIMA model for projection
model = ARIMA(global_energy, order=(1, 1, 1))
model_fit = model.fit()
forecast = model_fit.forecast(steps=10) # Projecting for 10 years
# Plot historical and forecasted energy consumption
plt.plot(global_energy, label='Historical')
plt.plot(range(global_energy.index[-1] + 1, global_energy.index[-1] + 11), forecast, label='Forecast')
plt.xlabel("Year")
plt.ylabel("Primary Energy Consumption")
plt.title("Projected Global Energy Consumption")
plt.legend()
plt.show()
Saída:
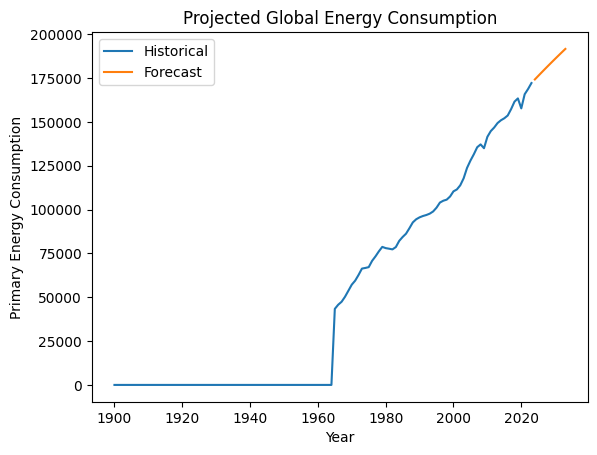
entendimento:
Esse modelo projeta que o consumo global de energia continuará aumentando.
Exemplo de notebook
Use o Notebook a seguir para executar as etapas deste artigo. Para obter instruções sobre como importar um Notebook para um Databricks workspace, consulte Importar um Notebook.
tutorial: EDA com dados globais de energia
Próximas etapas
Agora que o senhor já realizou uma análise exploratória inicial dos dados em seu site dataset, experimente as próximas etapas:
- Consulte o Apêndice no Notebook de exemplo para ver outros exemplos de visualização do site EDA.
- Se o senhor encontrar algum erro durante a execução deste tutorial, tente usar o depurador integrado para analisar seu código. Consulte Caderno de depuração.
- Compartilhe seu Notebook com sua equipe para que eles possam entender sua análise. Dependendo das permissões que o senhor lhes der, eles podem ajudar a desenvolver o código para aprofundar a análise ou adicionar comentários e sugestões para uma investigação mais aprofundada.
- Depois de finalizar sua análise, crie um painel do Notebook ou um arquivo AI/BI dashboard de visualização com as key visualizações para compartilhar com as partes interessadas. com as visualizações do para compartilhar com as partes interessadas.