Casos de uso
Beta
A partir de 15 de junho, o Lakebase está disponível em Beta no GCP. Consulte Disponibilidade regional para regiões compatíveis.
Dados de serviço lakehouse
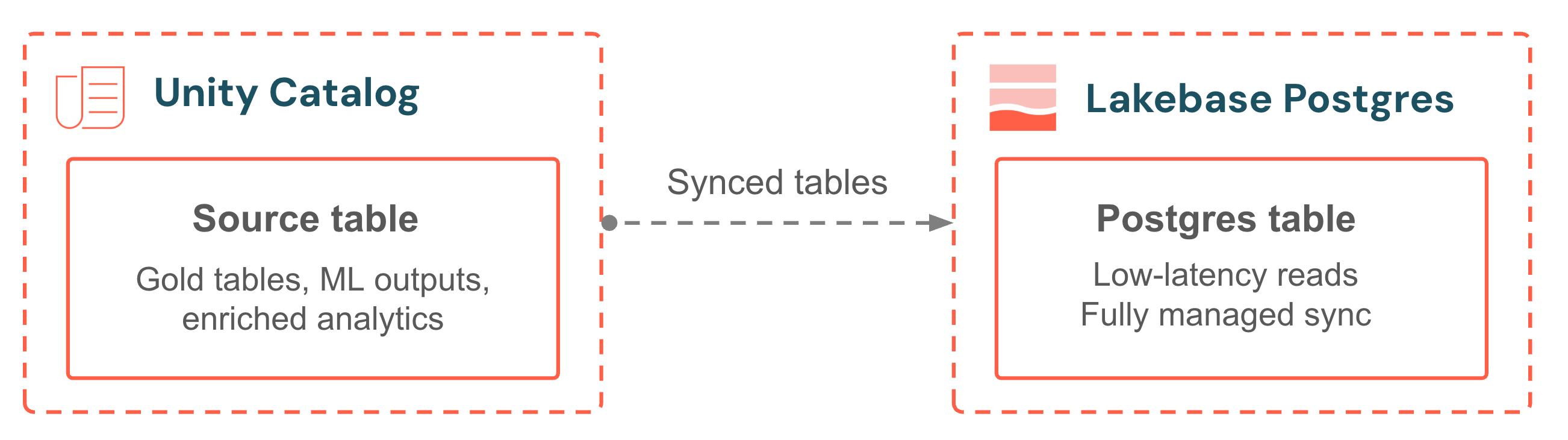
As tabelas sincronizadas trazem os dados do Unity Catalog para o seu banco de dados Lakebase, permitindo leituras transacionais de baixa latência. Selecione uma tabela de origem, escolha um modo de sincronização e o pipeline será totalmente gerenciado. Sem scripts de sincronização, sem orquestração externa, sem Job para monitorar. O modo contínuo mantém os dados a poucos segundos da fonte. O modo acionado equilibra a atualização e o custo com atualizações incrementais programadas. Seu aplicativo sempre fornece as análises mais recentes juntamente com seus próprios dados operacionais.
Primeiro os passos | Percurso de aprendizagem |
|---|---|
|
Backend da aplicação
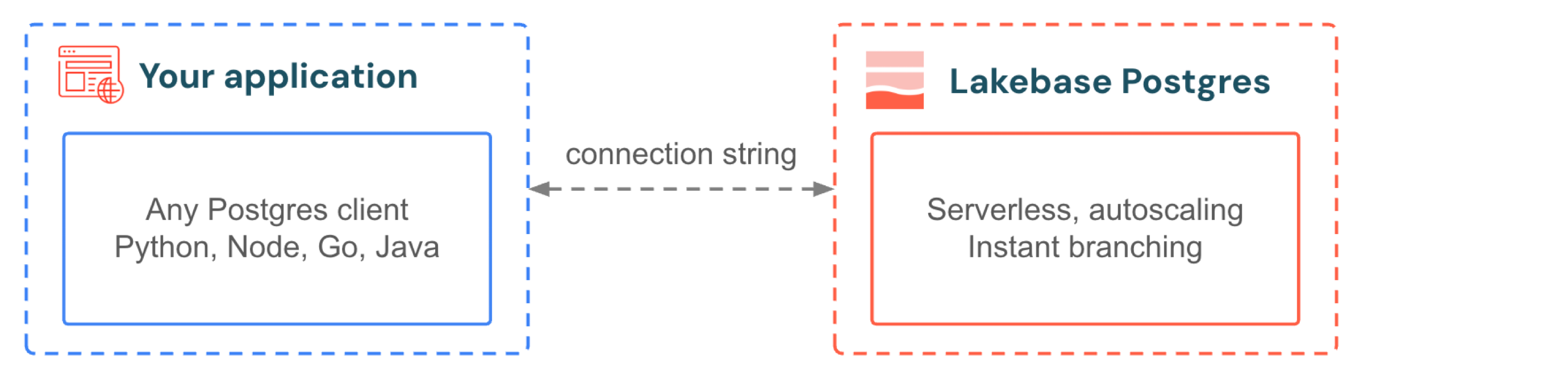
Seu aplicativo se conecta ao Lakebase da mesma forma que se conecta a qualquer banco de dados Postgres. Utilize os drivers e frameworks que você já conhece. Quando seu aplicativo recebe um pico de tráfego, o dimensionamento automático adiciona compute sem interromper as conexões. Quando o tráfego para, o recurso "escala-to-zero" suspende o banco de dados e o reativa em centenas de milissegundos na próxima consulta. Você não faz provisionamento para o pico e não paga pelo paraíso. Para o desenvolvimento, o branching fornece a cada desenvolvedor uma cópia isolada do banco de dados de produção, sem necessidade de preenchimento automático de dados, duplicação de armazenamento ou espera.
Primeiro os passos | Percurso de aprendizagem |
|---|---|
|
|
AgentesAI e ML
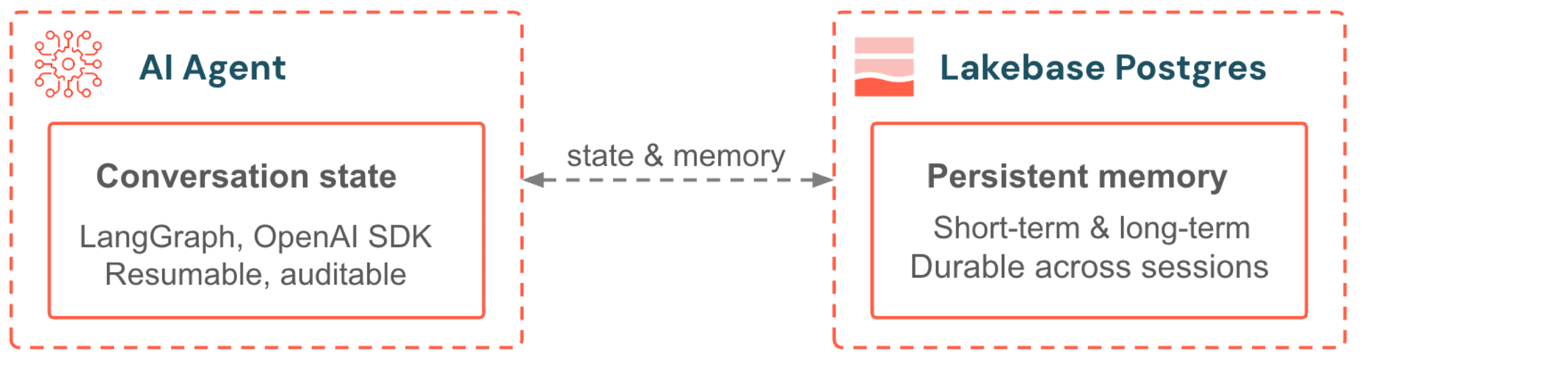
O Lakebase serve como o backend para a memória de agente de AI e o Feature Serving em tempo real. Agentes criados com LangGraph ou com o SDK de Agentes OpenAI armazenam o estado da conversa e a memória de longo prazo no Postgres. Modelos disponibilizados com Model Serving acessam dados de recurso por meio de Feature Stores Online que são alimentados pelo Dimensionamento Automático do Lakebase. Ambos se beneficiam do dimensionamento automático, do dimensionamento até zero e da governança do Unity Catalog.
Primeiro os passos | Percurso de aprendizagem |
|---|---|
|
|