Criar compartilhamentos para o OpenSharing
Esta página explica como criar compartilhamentos para o OpenSharing.
Um compartilhamento é um objeto protegível no Unity Catalog que você usa para compartilhar os seguintes ativos de dados com um ou mais destinatários:
- Tabelas e partições de tabela
- Tabelas de streaming
- Tabelas Iceberg gerenciadas
- Tabelas Iceberg externas
- Esquemas e tabelas estrangeiros
- Views, incluindo views dinâmicas que restringem o acesso nos níveis de linha e coluna
- Visualizações materializadas
- Volumes
- UDFs Python
- cadernos
- modelos de AI
- Genie Agents
Se você compartilhar um esquema (banco de dados) inteiro, o destinatário poderá acessar todas as tabelas, tabelas de transmissão, views, views materializadas, modelos e volumes no esquema no momento em que você o compartilhar, juntamente com quaisquer ativos de dados e AI adicionados ao esquema no futuro.
Um compartilhamento pode conter ativos de dados e AI de apenas um metastore do Unity Catalog. Você pode adicionar ou remover ativos de dados e AI de um compartilhamento a qualquer momento.
Antes de criar um compartilhamento, verifique se você configurou o OpenSharing para sua account (para provedores).
Para saber mais sobre o modelo de compartilhamento, consulte Compartilhamentos, provedores e destinatários.
Requisitos
Verifique se você atende aos requisitos listados para cada tarefa que deseja concluir.
Ao adicionar ativos de dados a um compartilhamento, o Databricks recomenda que você use um grupo como proprietário do compartilhamento.
Tarefa | Requisitos |
|---|---|
Criar um compartilhamento |
|
Adicione o seguinte a um compartilhamento:
|
|
Compartilhe um esquema inteiro ou um esquema externo |
|
Adicionar volumes a um compartilhamento. |
|
Adicionar UDFs Python a um compartilhamento |
|
Adicionar modelos a um compartilhamento |
|
Adicionar arquivos de notebook a um compartilhamento |
|
Compute requirements
- Se você usar um Notebook Databricks para criar o compartilhamento, seu recurso de compute deve usar o Databricks Runtime 11.3 LTS ou acima e ter um modo de acesso padrão ou dedicado (anteriormente compartilhado e de usuário único).
- Se você usar instruções SQL para adicionar um esquema a um compartilhamento (ou atualizar ou remover um esquema), você deve usar um SQL warehouse ou compute executando o Databricks Runtime 13.3 LTS ou acima. Fazer o mesmo usando o Catalog Explorer não tem requisitos de compute.
Criar um objeto de compartilhamento
Verifique se você atende aos requisitos antes de criar um objeto de compartilhamento.
Para criar um compartilhamento, use o Catalog Explorer, a CLI do Databricks Unity Catalog ou o comando SQL CREATE SHARE em um Notebook do Databricks ou no editor de consultas SQL do Databricks.
- Catalog Explorer
- SQL
- CLI
-
No seu Databricks workspace, clique em
 Catálogo .
Catálogo . -
No topo do painel Catálogo , clique no ícone de
 engrenagem e selecione OpenSharing .
engrenagem e selecione OpenSharing .Alternativamente, no canto superior direito, clique em **Share > OpenSharing**.
-
Na tab Compartilhados por mim , clique no botão Share data .
-
Na página Criar compartilhamento , insira o Nome do compartilhamento e um comentário opcional.
-
Clique em Salvar e continuar .
Você pode continuar a adicionar ativos de dados, ou pode parar e voltar mais tarde.
-
Na tab Adicionar ativos de dados , selecione os ativos de dados que deseja compartilhar.
Para obter instruções detalhadas, requisitos adicionais e limitações relacionadas, consulte:
- Adicionar tabelas a um compartilhamento
- Adicionar tabelas de transmissão a um compartilhamento.
- Adicionar tabelas Iceberg gerenciadas a um compartilhamento
- Adicionar esquemas ou tabelas estrangeiras a um compartilhamento
- Adicionar volumes a um compartilhamento.
- Adicionar exibições a um compartilhamento
- Adicionar views materializadas a um compartilhamento
- Adicionar modelos a um compartilhamento
-
Clique em Salvar e continuar .
-
Na tab Adicionar notebooks , selecione os notebooks que deseja compartilhar.
Para obter instruções detalhadas, consulte Adicionar arquivos de notebook a um compartilhamento.
-
Clique em Salvar e continuar .
-
Na tab **Adicionar destinatários**, selecione os destinatários com quem deseja compartilhar.
Para obter instruções detalhadas, consulte Gerenciar acesso a compartilhamentos de dados do OpenSharing (para provedores).
-
Clique em **Compartilhar dados** para compartilhar os dados com os destinatários.
Se você ainda não criou destinatários, clique em Compartilhar dados , crie destinatários e conceda acesso a eles posteriormente.
Execute o seguinte comando em um Notebook ou no editor de consultas SQL do Databricks:
CREATE SHARE [IF NOT EXISTS] <share-name>
[COMMENT "<comment>"];
Agora é possível adicionar tabelas, tabelas de transmissão, volumes, views, views materializadas e modelos ao compartilhamento.
Para obter instruções detalhadas, requisitos adicionais e limitações relacionadas, consulte:
- Adicionar tabelas a um compartilhamento
- Adicionar tabelas de transmissão a um compartilhamento.
- Adicionar tabelas Iceberg gerenciadas a um compartilhamento
- Adicionar esquemas ou tabelas estrangeiras a um compartilhamento
- Adicionar volumes a um compartilhamento.
- Adicionar exibições a um compartilhamento
- Adicionar views materializadas a um compartilhamento
- Adicionar modelos a um compartilhamento
Execute o seguinte comando usando a CLI do Databricks.
databricks shares create <share-name>
Você pode usar --comment para adicionar um comentário ou --json para adicionar ativos ao compartilhamento. Para obter detalhes, consulte as seções a seguir.
Agora é possível adicionar tabelas, tabelas de transmissão, volumes, views, views materializadas e modelos ao compartilhamento.
Para obter instruções detalhadas, requisitos adicionais e limitações relacionadas, consulte:
- Adicionar tabelas a um compartilhamento
- Adicionar tabelas de transmissão a um compartilhamento.
- Adicionar tabelas Iceberg gerenciadas a um compartilhamento
- Adicionar esquemas ou tabelas estrangeiras a um compartilhamento
- Adicionar volumes a um compartilhamento.
- Adicionar exibições a um compartilhamento
- Adicionar views materializadas a um compartilhamento
- Adicionar modelos a um compartilhamento
Adicionar tabelas a um compartilhamento
Verifique se você atende aos requisitos antes de adicionar tabelas a um compartilhamento.
Se você é um administrador do workspace e herdou as permissões USE SCHEMA e USE CATALOG no esquema e no catálogo que contêm a tabela do grupo de administradores do workspace, então você não pode adicionar a tabela a um compartilhamento. Você deve primeiro conceder a si mesmo as permissões USE SCHEMA e USE CATALOG no esquema e no catálogo.
Comentários da tabela, comentários da coluna e restrições de chave primária estão incluídos em compartilhamentos que são compartilhados com um destinatário usando o compartilhamento Databricks-to-Databricks em ou após 25 de julho de 2024. Se você quiser começar a compartilhar comentários e restrições através de um compartilhamento que foi compartilhado com um destinatário antes da data de lançamento, você deve revogar e conceder novamente o acesso do destinatário para acionar o compartilhamento de comentários e restrições.
Para adicionar tabelas a um compartilhamento, use o Catalog Explorer, a CLI do Databricks Unity Catalog ou comandos SQL em um Notebook do Databricks ou no editor de consultas SQL do Databricks.
- Catalog Explorer
- SQL
- CLI
-
No seu Databricks workspace, clique em
Catálogo . -
No topo do painel Catálogo , clique no ícone de
engrenagem e selecione OpenSharing .Alternativamente, no canto superior direito, clique em **Share > OpenSharing**.
-
Na tab Compartilhados por mim , localize o compartilhamento ao qual você deseja adicionar uma tabela e clique no seu nome. Você pode adicionar tabelas com acompanhamento de linha ativado. Os destinatários podem consultar as colunas de acompanhamento de linha.
-
Clique em **Gerenciar ativos > Editar ativos**.
-
Na página Editar ativos , selecione um esquema inteiro (banco de dados) ou tabelas individuais.
-
Para selecionar uma tabela, primeiro selecione o catálogo, depois o esquema que contém a tabela, e então a própria tabela.
Você pode pesquisar tabelas por nome, nome da coluna ou comentário usando a pesquisa do workspace. Consulte Pesquisar objetos do workspace.
-
Para selecionar um esquema, primeiro selecione o catálogo e depois o esquema.
Para informações detalhadas sobre compartilhamento de esquemas, consulte Adicionar esquemas a um compartilhamento.
-
-
**História**: Compartilhe o histórico da tabela para permitir que os destinatários realizem query de viagem do tempo, leiam a tabela com Spark transmissão estructurada, ou executem transações. Para compartilhamentos Databricks-to-Databricks, o log Delta da tabela também é compartilhado para melhorar o desempenho. Consulte Melhore o desempenho da leitura da tabela com o compartilhamento de histórico. O compartilhamento de história requer o Databricks Runtime 12.2 LTS ou acima.
Se você também quiser que seus clientes possam consultar o feed de dados de alteração (CDF) de uma tabela usando a função table_changes(), você deve habilitar o CDF na tabela antes de compartilhá-la WITH HISTORY.
-
(Opcional) Clique
 em sob as colunas **Alias** ou **Partição** para adicionar um alias ou partição. Alias e partições não estão disponíveis se você selecionar um esquema inteiro. O histórico da tabela está incluído por default se selecionar um esquema inteiro.
em sob as colunas **Alias** ou **Partição** para adicionar um alias ou partição. Alias e partições não estão disponíveis se você selecionar um esquema inteiro. O histórico da tabela está incluído por default se selecionar um esquema inteiro.- Alias : Um nome de tabela alternativo para tornar o nome da tabela mais legível. O alias é o nome da tabela que o destinatário vê e deve usar nas consultas. Os destinatários não podem usar o nome real da tabela se um alias for especificado.
- Partição: Compartilhe apenas parte da tabela. Por exemplo,
(column = 'value'). Consulte Especifique partições de tabela para compartilhar e Use as propriedades do destinatário para fazer filtragem de partição.
-
Clique em Salvar .
Execute o seguinte comando em um Notebook ou no editor de consultas do Databricks SQL para adicionar uma tabela:
ALTER SHARE <share-name> ADD TABLE <catalog-name>.<schema-name>.<table-name> [COMMENT "<comment>"]
[PARTITION(<clause>)] [AS <alias>]
[WITH HISTORY | WITHOUT HISTORY];
Execute o seguinte para adicionar um esquema inteiro. O comando ADD SCHEMA exige um SQL warehouse ou compute executando o Databricks Runtime 13.3 LTS ou acima. Para obter informações detalhadas sobre o compartilhamento de esquemas, consulte Adicionar esquemas a um compartilhamento.
ALTER SHARE <share-name> ADD SCHEMA <catalog-name>.<schema-name>
[COMMENT "<comment>"];
As opções incluem o seguinte. PARTITION e AS <alias> não estão disponíveis se você selecionar um esquema inteiro.
-
PARTITION(<clause>): se você deseja compartilhar apenas parte da tabela, você pode especificar uma partição. Por exemplo,(column = 'value')Consulte Especifique partições de tabela para compartilhar e Use propriedades de destinatário para fazer filtragem de partição. -
AS <alias>: Um nome de tabela alternativo, ou alias para tornar o nome da tabela mais legível. O alias é o nome da tabela que o destinatário vê e deve usar nas consultas. Os destinatários não podem usar o nome real da tabela se um alias for especificado. Use o formato<schema-name>.<table-name>. -
WITH HISTORYouWITHOUT HISTORY: quandoWITH HISTORYé especificado, compartilhe a tabela com histórico completo, permitindo que os destinatários realizem consultas de viagem do tempo, leituras de transmissão e executem transações. Para compartilhamentos Databricks-to-Databricks, o compartilhamento de histórico também compartilha o log Delta da tabela para melhorar o desempenho. O comportamento default para o compartilhamento de tabela éWITH HISTORYse o seu compute estiver executando o Databricks Runtime 16.2 ou acima eWITHOUT HISTORYpara versões anteriores do Databricks Runtime. Para o compartilhamento de esquema, o default éWITH HISTORYindependentemente da versão do Databricks Runtime.WITH HISTORYeWITHOUT HISTORYexigem Databricks Runtime 12.2 LTS ou acima. Veja também Melhorar o desempenho da leitura da tabela com o compartilhamento de histórico.
Se, além de fazer consultas de viagem do tempo e leituras de transmissão, você quiser que seus destinatários consultem o feed de dados alterados (CDF) de uma tabela usando a função table_changes(), você deve habilitar o CDF na tabela antes de compartilhá-la WITH HISTORY.
Para obter mais informações sobre as opções de ALTER SHARE, consulte ALTER SHARE.
Para adicionar uma tabela, execute o seguinte comando usando a CLI do Databricks.
databricks shares update <share-name> \
--json '{
"updates": [
{
"action": "ADD",
"data_object": {
"name": "<table-full-name>",
"data_object_type": "TABLE",
"shared_as": "<table-alias>"
}
}
]
}'
Para adicionar um esquema, execute o seguinte comando da CLI do Databricks:
databricks shares update <share-name> \
--json '{
"updates": [
{
"action": "ADD",
"data_object": {
"name": "<schema-full-name>",
"data_object_type": "SCHEMA"
}
}
]
}'
Para tabelas, e apenas tabelas, é possível omitir "data_object_type".
Para saber mais sobre as opções listadas neste exemplo, consulte as instruções na tab SQL.
Para saber mais sobre parâmetros adicionais, execute databricks shares update --help ou consulte PATCH /api/2.1/unity-catalog/shares/ na referência da API REST.
Para obter informações sobre como remover tabelas de um compartilhamento, consulte Atualizar compartilhamentos.
Elegibilidade do token da nuvem
Databricks usa tokens de nuvem (credenciais de nuvem temporárias e com escopo de caminho) para dar aos destinatários acesso de leitura direto a arquivos de tabela Delta compartilhados. No protocolo de compartilhamento Databricks-para-Open, isso também é chamado de *modo de acesso baseado em diretório*. Visualizações, visualizações materializadas, tabelas estrangeiras, tabelas de transmissão, volumes, notebooks, UDFs do Python e modelos de AI não são compatíveis. Quais tabelas se qualificam depende do protocolo de compartilhamento.
**Compartilhamento Databricks-to-Databricks**: os tokens de cloud são usados quando todas as seguintes condições são verdadeiras:
- A tabela é compartilhada
WITH HISTORY(história completa desde o início). - A tabela é compartilhada sem um filtro de partição.
Compartilhamento Databricks-para-aberto : tokens de cloud (modo de acesso baseado em diretório) são usados quando todas as condições a seguir são verdadeiras:
- O objeto compartilhado é uma tabela Delta gerenciada ou externa .
- A tabela é compartilhada
WITH HISTORY(história completa desde o início). - A tabela é compartilhada sem um filtro de partição.
- A tabela não é uma tabela CCv2.
- A tabela não usa armazenamento default.
Para compartilhamentos Databricks-to-Databricks, os cloud tokens são trocados diretamente entre metastores do Unity Catalog sem tokens portadores de longa duração, resultando em um desempenho comparável ao acesso direto à tabela de origem. Para compartilhamento Databricks-para-Open, o servidor OpenSharing inclui o local de armazenamento em cloud da tabela e accessModes: ["url", "dir"] nas respostas de lista e metadados. Os destinatários abertos podem chamar o endpoint Gerar Credenciais de Tabela Temporária para obter credenciais e ler diretamente do armazenamento em cloud.
Quando o acesso com cloud tokens é usado, os destinatários recebem credenciais com escopo para o diretório raiz da tabela Delta compartilhada. Isso concede acesso de leitura tanto aos arquivos de dados quanto ao log Delta. O log Delta contém o histórico de commit de cada versão da tabela, informações sobre o committer e dados excluídos que não foram submetidos a vacuum.
Especifique partições de tabela para compartilhar
Para compartilhar apenas parte de uma tabela ao adicioná-la a um compartilhamento, forneça uma especificação de partição. Especifique as partições ao adicionar uma tabela a um compartilhamento ou atualizar um compartilhamento, usando o Catalog Explorer, a CLI do Databricks Unity Catalog ou comandos SQL em um notebook do Databricks ou no editor de consultas do Databricks SQL. Consulte Adicionar tabelas a um compartilhamento e Atualizar compartilhamentos.
Exemplo
O exemplo de SQL a seguir compartilha parte dos dados na tabela inventory, particionados pelas colunas year, month e date:
- Dados para o ano de 2021.
- Dados de dezembro de 2020.
- Dados de 25 de dezembro de 2019.
ALTER SHARE share_name
ADD TABLE inventory
PARTITION (year = "2021"),
(year = "2020", month = "Dec"),
(year = "2019", month = "Dec", date = "2019-12-25");
Use propriedades do destinatário para fazer filtragem de partição
É possível compartilhar uma partição de tabela que corresponda às propriedades do destinatário de dados, também conhecido como compartilhamento de partição parametrizado.
As propriedades default incluem:
databricks.accountId: A account Databricks à qual um destinatário de dados pertence (apenas para compartilhamento Databricks-to-Databricks).databricks.metastoreId: O metastore do Unity Catalog ao qual um destinatário de dados pertence (somente compartilhamento Databricks-to-Databricks).databricks.name: O nome do destinatário dos dados.
Você pode criar qualquer propriedade personalizada ao criar ou atualizar um destinatário.
A filtragem por propriedade de destinatário permite que você compartilhe as mesmas tabelas, usando o mesmo compartilhamento, entre várias accounts, workspaces e usuários do Databricks, mantendo os limites de dados entre eles.
Por exemplo, se suas tabelas incluírem uma coluna de ID da conta do Databricks, é possível criar um único compartilhamento com partições de tabela definidas pelo ID da conta do Databricks. Ao compartilhar, o OpenSharing entrega dinamicamente a cada destinatário apenas os dados associados à Databricks account de cada destinatário.
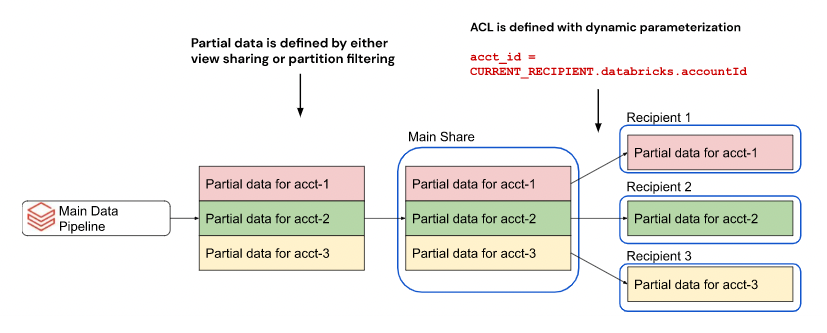
Sem a capacidade de particionar dinamicamente por propriedade, você teria que criar um compartilhamento separado para cada destinatário.
Para especificar uma partição que filtra por propriedades do destinatário ao criar ou atualizar um compartilhamento, você pode usar o Catalog Explorer ou a função CURRENT_RECIPIENT SQL em um Notebook do Databricks ou no editor de consultas do Databricks SQL:
As propriedades do destinatário estão disponíveis no Databricks Runtime 12.2 ou acima.
- Catalog Explorer
- SQL
-
No seu Databricks workspace, clique em
Catálogo . -
No topo do painel Catálogo , clique no ícone de
engrenagem e selecione OpenSharing .Alternativamente, no canto superior direito, clique em **Share > OpenSharing**.
-
Na tab Compartilhados por mim, localize o compartilhamento que você deseja atualizar e clique no nome dele.
-
Clique em Gerenciar ativos > Adicionar ativos de dados .
-
Na página **Adicionar tabelas**, selecione o catálogo e o banco de dados que contêm a tabela e, em seguida, selecione a tabela.
Se você não tem certeza de qual catálogo e banco de dados contêm a tabela, pode pesquisá-la por nome, nome da coluna ou comentário usando a pesquisa do workspace. Consulte Pesquisar objetos do workspace.
-
(Opcional) Clique em
em Coluna de Partição para adicionar uma partição.Na caixa de diálogo Adicionar partição à tabela , adicione a especificação de partição baseada em propriedades usando a seguinte sintaxe:
(<column-name> = CURRENT_RECIPIENT().<property-key>)Por exemplo,
(country = CURRENT_RECIPIENT().country) -
Clique em Salvar .
Execute o seguinte comando em um Notebook ou no editor de consultas SQL do Databricks:
ALTER SHARE <share-name> ADD TABLE <catalog-name>.<schema-name>.<table-name>
PARTITION (<column-name> = CURRENT_RECIPIENT().<property-key>);
Por exemplo,
ALTER SHARE acme ADD TABLE acme.default.some_table
PARTITION (country = CURRENT_RECIPIENT().country);
Adicione tabelas com vetores de exclusão ou mapeamento de coluna a um compartilhamento
Visualização
Esse recurso está em Prévia Pública.
Vetores de exclusão são um recurso de otimização de armazenamento que você pode habilitar em tabelas Delta. Consulte Vetores de exclusão no Databricks.
A Databricks também oferece suporte ao mapeamento de colunas para tabelas Delta. Consulte Renomear e eliminar colunas com o mapeamento de colunas do Delta Lake.
Para compartilhar uma tabela com vetores de exclusão ou mapeamento de coluna, é preciso compartilhá-la com história. Consulte Adicionar tabelas a um compartilhamento.
Ao compartilhar uma tabela com vetores de exclusão ou mapeamento de coluna, os destinatários podem consultar a tabela usando um SQL warehouse, um compute executando o Databricks Runtime 14,1 ou acima, ou um compute que está executando o delta-sharing-spark de código aberto 3,1 ou acima. Consulte Ler tabelas com vetores de exclusão ou mapeamento de coluna ativados e Ler tabelas com vetores de exclusão ou mapeamento de coluna ativados.
Adicione esquemas a um compartilhamento
Verifique se você atende aos requisitos antes de adicionar esquemas a um compartilhamento.
Adicionar um esquema inteiro a um compartilhamento fornece aos seus destinatários acesso a todos os ativos de dados no esquema no momento em que você cria o compartilhamento, bem como a quaisquer ativos que são adicionados ao esquema ao longo do tempo. Isso inclui todas as tabelas, views e volumes no esquema. Tabelas compartilhadas desta forma sempre incluem história completa.
Compartilhar esquemas com um destinatário
Para adicionar um esquema a um compartilhamento, siga as instruções em Adicionar tabelas a um compartilhamento, prestando atenção ao conteúdo que especifica como adicionar um esquema.
Adicionar, atualizar ou remover um esquema usando SQL requer um SQL warehouse ou compute executando Databricks Runtime 13.3 LTS ou superior. Fazer o mesmo usando o Catalog Explorer não tem requisitos de compute.
Limitações
-
Você pode compartilhar esquemas mesmo que eles incluam ativos de dados não aceitos. Esses ativos são filtrados e não são compartilhados com os destinatários. Os ativos de dados não aceitos incluem o seguinte:
- Tabelas que usam clustering líquido com filtragem de partição
- Tabelas R2 com ponto de verificação V2
- Tabelas com agrupamentos habilitados
- Tabelas com filtros de linha ou máscaras de coluna
SHALLOW CLONEtabelas- Restrições de chave estrangeira em tabelas compartilhadas
-
Aliases de tabela, partições e aliases de volume não estão disponíveis se você compartilhar um esquema inteiro. Se você criou aliases ou partições para quaisquer ativos no esquema, eles são removidos quando você adiciona o esquema inteiro ao compartilhamento.
-
Se quiser especificar opções avançadas para uma tabela ou volume no esquema, você deve compartilhar a tabela ou o volume usando SQL e dar à tabela ou ao volume um alias com um nome de esquema diferente.
-
O aliasing em nível de esquema não é suportado. Esquemas com o mesmo nome de catálogos diferentes não podem ser adicionados ao mesmo compartilhamento. Em vez disso, compartilhe tabelas individuais com nomes de esquema atribuídos.
Adicione tabelas e esquemas protegidos por políticas ABAC a um compartilhamento
O controle de acesso baseado em atributos (ABAC) é um modelo de governança de dados que oferece controle de acesso flexível, escalável e centralizado em todo o Databricks.
É possível compartilhar uma tabela ou esquema protegido por políticas ABAC como tabelas padrão. Para saber como aplicar políticas ABAC aos seus ativos de dados, consulte Criar e gerenciar políticas de filtro de linha e máscara de coluna.
No entanto, você deve ser um usuário privilegiado . Um usuário privilegiado é o proprietário do compartilhamento e um usuário que está excluído das políticas ABAC aplicadas ao ativo de dados. A política não governa o acesso do destinatário. Destinatários têm acesso total ao ativo compartilhado. Limitações ABAC se aplicam.
Adicione tabelas de transmissão a um compartilhamento
Tabelas de transmissão são tabelas Delta regulares com suporte extra para transmissão ou processamento incremental de dados. Tabelas de transmissão são projetadas para fontes de dados somente de acréscimo e processam as entradas apenas uma vez. Consulte Usar tabelas de transmissão autônomas.
Verifique se você atende aos requisitos antes de adicionar tabelas de transmissão a um compartilhamento.
Requisitos adicionais
-
Você deve habilitar o **compute Serverless para fluxos de trabalho, notebooks e Lakeflow pipelines** na account onde o compartilhamento de tabelas de transmissão está configurado. Consulte Conectar-se ao compute serverless.
-
Se seu workspace tiver ligações de catálogo de workspace habilitadas, verifique se o workspace tem acesso de leitura e gravação ao catálogo em que a tabela de transmissão está. Para obter mais informação, consulte Vinculação de workspace-catálogo.
-
As tabelas de transmissão compartilháveis devem ser definidas em tabelas Delta ou em outras tabelas ou exibições de transmissão compartilháveis.
-
Você deve usar um SQL warehouse ou um compute no Databricks Runtime 13.3 LTS ou acima ao adicionar uma tabela de transmissão a um compartilhamento.
Limitações
-
A tabela de transmissão não pode ter filtros de linha e máscaras de coluna.
- A tabela base da tabela de transmissão pode ter filtros de linha e máscaras de coluna.
-
A tabela de transmissão não pode ter filtros de partição. Em vez disso, crie uma view sobre a tabela de transmissão.
-
Destinatários de Compartilhamento Databricks-to-Open podem apenas ler o Snapshot atual da tabela de transmissão. Viagem do tempo, histórico de consultas, leituras por transmissão e CDF não são suportados para destinatários abertos. Se os seus destinatários precisarem de CDF, recomenda-se compartilhar uma tabela Delta regular com o CDF ativado.
-
Se o destinatário não tiver acesso direto aos dados subjacentes,
LIMITcláusulas e pushdown de predicado não serão suportados. O sistema materializa completamente todos os resultados da consulta antes de retorná-los ao destinatário, independentemente dos filtros de consulta. Consulte Os destinatários têm acesso direto aos dados subjacentes em views compartilhadas, views materializadas e tabelas de transmissão? -
Limitações gerais para tabelas de transmissão também se aplicam. Consulte limitações da tabela de transmissão.
Compartilhe tabelas de transmissão com um destinatário
Para adicionar tabelas de transmissão a um compartilhamento:
- Catalog Explorer
- SQL
- CLI
-
No seu Databricks workspace, clique em
Catálogo . -
No topo do painel Catálogo , clique no ícone de
engrenagem e selecione OpenSharing .Alternativamente, no canto superior direito, clique em **Share > OpenSharing**.
-
Na tab Compartilhado por mim, localize o compartilhamento ao qual você deseja adicionar uma tabela de transmissão e clique no nome dele.
-
Clique em **Gerenciar ativos > Editar ativos**.
-
Na página **Editar ativos**, pesquise ou procure a tabela de transmissão que você deseja compartilhar e selecione-a.
-
(Opcional) Na coluna **Alias**, clique em
para especificar um alias, ou nome de tabela de transmissão alternativo, para tornar o nome da tabela de transmissão mais legível. O alias é o nome que o destinatário vê e deve usar nas query. Os destinatários não podem usar o nome real da tabela de transmissão se um alias for especificado. -
Clique em Salvar .
Execute o seguinte comando em um notebook ou no editor de consultas SQL do Databricks.
ALTER SHARE <share_name> ADD TABLE <st_name> [COMMENT <comment>] [AS <shared_st_name>];
Execute o seguinte comando da CLI do Databricks.
databricks shares update <share-name> \
--json '{
“updates”: [
{
“action”: “ADD”,
“data_object”: {
“name”: “<st-full-name>",
“data_object_type”: “TABLE”,
“comment”: “<comment>”
}
}
]
}'
Para obter informações sobre como remover tabelas de transmissão de um compartilhamento, consulte Atualizar compartilhamentos.
Adicionar tabelas Iceberg gerenciadas a um compartilhamento
Visualização
Esse recurso está em Prévia Pública.
Apache Iceberg é um formato de tabela de código aberto para cargas de trabalho de analítica. No Databricks, você pode criar tabelas Iceberg no Unity Catalog, conhecidas como tabelas Iceberg gerenciadas.
Verifique se você atende aos requisitos antes de adicionar tabelas Iceberg gerenciadas a um compartilhamento. Limitações de tabelas Iceberg e tabelas Iceberg gerenciadas se aplicam. Consulte Limitações.
A Databricks não oferece suporte ao compartilhamento de tabelas Iceberg gerenciadas com clientes Iceberg externos.
Para adicionar tabelas Iceberg gerenciadas a um compartilhamento:
- Catalog Explorer
- SQL
- CLI
-
No seu Databricks workspace, clique em
Catálogo . -
No topo do painel Catálogo , clique no ícone de
engrenagem e selecione OpenSharing .Alternativamente, no canto superior direito, clique em **Share > OpenSharing**.
-
Na tab Compartilhado por mim , encontre o compartilhamento ao qual deseja adicionar uma tabela Iceberg gerenciada e clique em seu nome.
-
Clique em Gerenciar ativos > Editar ativos .
-
Na página **Editar ativos**, pesquise ou navegue até a tabela Iceberg gerenciada que você deseja compartilhar e selecione-a.
-
(Opcional) Na coluna **Alias**, clique em
para especificar um alias, ou nome de tabela gerenciada Iceberg alternativo, para tornar o nome mais legível. O alias é o nome que o destinatário vê e deve usar nas query. Os destinatários não podem usar o nome real da tabela gerenciada Iceberg se um alias for especificado. -
Clique em Salvar .
Execute o seguinte comando em um notebook ou no editor de consultas SQL do Databricks. Opcionalmente, especifique <shared_iceberg_table_name> para expor a tabela Iceberg gerenciada sob um nome diferente.
ALTER SHARE <share_name> ADD TABLE <managed_iceberg_name> [COMMENT <comment>] [AS <shared_iceberg_table_name>];
Execute o seguinte comando da CLI do Databricks.
databricks shares update <share-name> \
--json '{
“updates”: [
{
“action”: “ADD”,
“data_object”: {
“name”: “<managed-iceberg-full-name>",
“data_object_type”: “TABLE”,
“comment”: “<comment>”
}
}
]
}'
Adicionar esquemas ou tabelas externos a um compartilhamento
Beta
Este recurso está em Beta. Os administradores do espaço de trabalho podem controlar o acesso a esse recurso na página Pré-visualizações . Consulte Gerenciar prévias do Databricks.
O Lakehouse Federation permite usar o Databricks para executar consultas em fontes de dados externas. É possível criar esquemas e tabelas estrangeiras, que contêm dados e metadados gerenciados por sistemas externos, com o Unity Catalog adicionando governança de dados para consultar essas tabelas. Para saber mais sobre como conectar a fontes externas, consulte Conectar-se a Bancos de Dados e Catálogos Externos.
O OpenSharing permite compartilhar com segurança dados externos do seu local de origem, sem copiar dados para a Databricks, configurações de rede complexas ou transferências de credenciais.
Verifique se atende aos requisitos antes de adicionar esquemas ou tabelas externos a um compartilhamento.
Requisitos adicionais
-
É preciso habilitar o **Compartilhamento de Federação Lakehouse** nas suas Visualizações de nível de account. Consulte Gerenciar prévias do Databricks.
-
Você deve habilitar o compute serverless para fluxos de trabalho, notebooks e Lakeflow Pipelines na account em que o compartilhamento de esquema ou tabela externa está configurado. Consulte Conectar-se ao compute serverless.
-
Ao fazer o compartilhamento de esquemas e tabelas estrangeiras, os dados são consultados e materializados temporariamente no lado do provedor. Por padrão, os dados materializados são armazenados em um esquema oculto usando o armazenamento padrão do Databricks. Verifique se atende aos requisitos e observe as limitações do armazenamento default.
Para obter detalhes sobre a disponibilidade regional do armazenamento default, consulte Disponibilidade serverless.
Para desativar o uso do armazenamento default do Databricks e usar seu próprio armazenamento para materialização temporária, abra um caso de suporte.
Tabelas externas que são muito grandes para materializar não podem ser compartilhadas. Se a materialização exceder os limites, a consulta falhará.
- Se você optar por usar o armazenamento default, você deve habilitar a pré-visualização OpenSharing for Default Storage – Expanded Access no nível da account. Consulte Gerenciar prévias do Databricks.
Limitações
- Tabelas externas compartilhadas não oferecem suporte a cláusulas
LIMITou pushdown de predicado. O sistema materializa completamente todos os resultados de consulta antes de retorná-los ao destinatário, independentemente dos filtros de consulta.
Padrões de uso recomendados
Os resultados da consulta são gerados sob demanda para cada consulta, portanto, o compartilhamento de tabelas e esquemas estrangeiros pode não ser tão eficiente em termos de custo em comparação com o compartilhamento de tabelas ou views materializadas. A Databricks recomenda o seguinte para melhorar o desempenho:
- Mantenha o tamanho dos resultados de query típicos inferior a 10 GB.
- Use consultas exploratórias ad-hoc em vez de despejos de dados frequentes.
- Ao usar o compartilhamento de tokens na cloud, considere compartilhar views materializadas criadas a partir de tabelas externas para melhor custo-benefício e desempenho.
Compartilhe o esquema ou a tabela externa com um destinatário
Para adicionar esquemas ou tabelas estrangeiras a um compartilhamento, use o Catalog Explorer, a CLI do Databricks Unity Catalog ou comandos SQL em um notebook Databricks ou o editor de consultas Databricks SQL.
- Catalog Explorer
- SQL
- CLI
-
No seu Databricks workspace, clique em
Catálogo . -
No topo do painel Catálogo , clique no ícone de
engrenagem e selecione OpenSharing .Alternativamente, no canto superior direito, clique em **Share > OpenSharing**.
-
Na **tab Compartilhados por mim**, encontre o compartilhamento ao qual deseja adicionar uma tabela ou esquema externo e clique em seu nome.
-
Clique em **Gerenciar ativos > Editar ativos**.
-
Na página Editar ativos , pesquise ou navegue pela tabela ou esquema estrangeiro que se deseja compartilhar e selecione-o.
-
(Opcional) Na coluna Alias , clique em
para especificar um alias, ou nome alternativo de esquema ou tabela estrangeiro, para tornar o nome do esquema ou da tabela estrangeira mais legível. O alias é o nome que o destinatário vê e deve usar nas query. Os destinatários não podem usar o nome real do esquema ou da tabela estrangeira se um alias for especificado. -
Clique em Salvar .
ALTER SHARE <share-name>
ADD {TABLE | SCHEMA} {federated_catalog.federated_schema.federated_table | federated_catalog.federated_schema}
[COMMENT "<comment>"]
[AS <alias>];
As opções incluem:
AS <alias>: Um nome alternativo, ou alias, para tornar o nome do ativo de dados mais legível. O alias é o nome do ativo de dados que o destinatário vê e deve usar nas consultas. Os destinatários não podem usar o nome real se um alias for especificado. Use o formato<catalog-name>.<schema-name>.<view-name>.COMMENT "<comment>": Comentários aparecem na IU do Catalog Explorer e ao listar e exibir detalhes de ativos de dados usando instruções SQL.
Para obter mais informações sobre as opções de ALTER SHARE, consulte ALTER SHARE.
databricks shares update <share-name> \
--json '{
“updates”: [
{
“action”: “ADD”,
“data_object”: {
“name”: “<federated-data-asset-full-name>",
“data_object_type”: “{TABLE | SCHEMA}”,
"shared_as": "<foreign-data-asset-alias>",
“comment”: “<comment>”
}
}
]
}'
Adicionar tabelas Iceberg estrangeiras a um compartilhamento
Visualização
Esse recurso está em Prévia Pública.
Tabelas Iceberg externas são tabelas federadas de catálogos Iceberg externos usando o Lakehouse Federation. Para saber mais sobre as tabelas Apache Iceberg no Databricks, consulte O que é Apache Iceberg no Databricks?.
Antes de começar, verifique se você atende aos requisitos gerais e crie um compartilhamento. É possível também compartilhar tabelas externas do Iceberg com destinatários usando clientes externos do Iceberg. Para obter mais informações, consulte Habilitar compartilhamento para clientes Iceberg externos.
Para verificar se os destinatários recebem os dados mais recentes, atualize periodicamente suas tabelas Iceberg externas. Qualquer consulta SELECT ou comando REFRESH TABLE atualiza os metadados da tabela.
A Databricks recomenda configurar um Job agendado para que a tabela Iceberg externa na Databricks permaneça em sincronia com a fonte remota do Iceberg. Para mais informações sobre programar refreshes, consulte Programar uma consulta.
Requisitos adicionais
- Você deve habilitar a pré-visualização do Compartilhamento do Lakehouse Federation no nível da account. Consulte Gerenciar prévias do Databricks.
- Se você estiver compartilhando tabelas Iceberg externas com destinatários abertos que não usam clientes Iceberg, você deve usar armazenamento default. É necessário habilitar a prévia **OpenSharing for Default Storage – Expanded Access** no nível da conta. Consulte Gerenciar prévias do Databricks.
- Ao **compartilhamento** com destinatários abertos que não usam clientes Iceberg, os dados compartilhados são primeiro filtrados e materializados usando seu compute e armazenamento. Pode acarretar custos adicionais. Para mais informações, consulte Como posso incorrer e verificar os custos do OpenSharing? e Os destinatários têm acesso direto aos dados subjacentes em visualizações compartilhadas, visualizações materializadas e tabelas de transmissão?.
- Tabelas Iceberg externas devem ter o Delta uniforme habilitado. Se o UniForm não estiver ativado, a tabela não pode ser adicionada a um compartilhamento. Veja leia tabelas do Delta Lake com clientes Iceberg usando o UniForm.
Limitações
- Partições não são aceitas.
- Ao compartilhamento com destinatários abertos que não utilizam um cliente Iceberg, as cláusulas
LIMITe o pushdown de predicados não são suportados. O sistema materializa totalmente todos os resultados de consulta antes de retorná-los ao destinatário, independentemente dos filtros de consulta.
Adicione uma tabela Iceberg externa a um compartilhamento
Tabelas Iceberg externas são automaticamente compartilhadas com o histórico completo.
Para adicionar uma tabela Iceberg externa a um compartilhamento:
- Catalog Explorer
- SQL
- CLI
-
No seu Databricks workspace, clique em
Catálogo . -
No topo do painel Catálogo , clique no ícone de
engrenagem e selecione OpenSharing .Alternativamente, no canto superior direito, clique em **Share > OpenSharing**.
-
Na tab Compartilhados por mim , localize o compartilhamento ao qual você deseja adicionar uma tabela Iceberg externa e clique em seu nome.
-
Clique em Gerenciar ativos > Editar ativos .
-
Na página Editar ativos , pesquise ou navegue pela tabela Iceberg estrangeira que você deseja compartilhar e selecione-a.
-
(Opcional) Na coluna Alias , clique em
para especificar um alias. O alias é o nome que o destinatário vê e deve usar em queries. -
Clique em Salvar .
Execute o seguinte comando em um notebook ou no editor de consultas SQL do Databricks. Opcionalmente, especifique <shared_table_name> para expor a tabela Iceberg externa sob um nome diferente.
ALTER SHARE <share_name> ADD TABLE <foreign_iceberg_table_name> [COMMENT <comment>] [AS <shared_table_name>];
Execute o seguinte comando da CLI do Databricks.
databricks shares update <share-name> \
--json '{
"updates": [
{
"action": "ADD",
"data_object": {
"name": "<foreign-iceberg-table-full-name>",
"data_object_type": "TABLE",
"comment": "<comment>"
}
}
]
}'
Adicionar views a um compartilhamento
Views são objetos somente leitura criados a partir de uma ou mais tabelas ou outras views. Uma view pode ser criada a partir de tabelas e outras views contidas em vários esquemas e catálogos em um metastore do Unity Catalog. Consulte Criar e gerenciar views.
Ao compartilhar views, os dados são consultados e materializados temporariamente. Os dados materializados são armazenados no local de armazenamento do esquema pai ou catálogo da view, ou no local raiz do metastore.
Verifique se atende aos requisitos antes de adicionar views a um compartilhamento.
Requisitos adicionais
-
Você deve habilitar o **Serverless compute para fluxos de trabalho, Notebooks e LakeFlow Pipelines** na account onde o compartilhamento de view está configurado. Consulte Conectar-se ao compute serverless.
-
As views compartilháveis devem ser definidas em tabelas Delta, outras views compartilháveis ou views materializadas locais e tabelas de transmissão. As views compartilháveis não podem ser definidas em tabelas estrangeiras.
-
Você deve usar um SQL warehouse ou um compute no Databricks Runtime 13.3 LTS ou acima ao adicionar uma view a um compartilhamento.
-
Se seu workspace tiver as vinculações de workspace-catálogo habilitadas, verifique se o workspace tem acesso de leitura e gravação ao catálogo. Para obter mais informação, consulte Vinculação de workspace-catálogo.
-
Ao compartilhar visualizações, os dados podem ser consultados e materializados temporariamente no lado do provedor, dependendo do tipo de compute do destinatário e do relacionamento da account. Os dados materializados são armazenados no local de armazenamento do esquema pai ou catálogo da view, ou no local raiz do metastore. Para obter detalhes sobre quando a materialização ocorre e quem a paga, consulte Os destinatários têm acesso direto aos dados subjacentes em views compartilhadas, views materializadas e tabelas de transmissão? e Como faço para incorrer e consultar os custos do OpenSharing?
-
Se o local de armazenamento tiver configurações de rede personalizadas, como um firewall ou um link privado, é necessário verificar se os destinatários estão na lista de permissões para se conectar ao local de armazenamento. Para obter instruções sobre a configuração de regras de firewall para compute serverless, consulte Limitar a saída de rede para seu workspace usando um firewall.
Limitações
- Você não pode compartilhar views que referenciam tabelas compartilhadas ou views compartilhadas.
- Não é possível compartilhar views que referenciam tabelas externas, incluindo tabelas Iceberg externas.
- Se o destinatário não tiver acesso direto aos dados subjacentes,
LIMITcláusulas e pushdown de predicado não serão suportados. O sistema materializa completamente todos os resultados da consulta antes de retorná-los ao destinatário, independentemente dos filtros de consulta. Consulte Os destinatários têm acesso direto aos dados subjacentes em views compartilhadas, views materializadas e tabelas de transmissão?
Compartilhar visualizações com um destinatário
Esta seção descreve como adicionar views a um compartilhamento usando o Catalog Explorer, Databricks CLI ou comandos SQL em um Notebook do Databricks ou no editor de consultas do Databricks SQL. Se você preferir usar a API REST do Unity Catalog, consulte PATCH /api/2.1/unity-catalog/shares/ na referência da API REST.
- Catalog Explorer
- SQL
- CLI
-
No seu Databricks workspace, clique em
Catálogo . -
No topo do painel Catálogo , clique no ícone de
engrenagem e selecione OpenSharing .Alternativamente, no canto superior direito, clique em **Share > OpenSharing**.
-
Na tab Compartilhado por mim , localize o compartilhamento ao qual você deseja adicionar uma exibição e clique em seu nome.
-
Clique em Gerenciar ativos > Adicionar ativos de dados .
-
Na página **Adicionar tabelas**, pesquise ou navegue pela view que deseja compartilhar e selecione-a.
-
(Opcional) Clique em
sob a coluna Alias para especificar um nome de view alternativo, ou Alias , para tornar o nome da view mais legível. O alias é o nome que o destinatário vê e deve usar nas consultas. Os destinatários não podem usar o nome real da view se um alias for especificado. -
Clique em Salvar .
Execute o seguinte comando em um Notebook ou no editor de consultas SQL do Databricks:
ALTER SHARE <share-name> ADD VIEW <catalog-name>.<schema-name>.<view-name>
[COMMENT "<comment>"]
[AS <alias>];
As opções incluem:
AS <alias>: Um nome de view alternativo, ou alias, para tornar o nome da view mais legível. O alias é o nome da view que o destinatário vê e deve usar nas queries. Os destinatários não podem usar o nome da view real se um alias for especificado. Use o formato<schema-name>.<view-name>.COMMENT "<comment>": Comentários aparecem na UI do Catalog Explorer e ao listar e exibir detalhes da view usando instruções SQL.
Para obter mais informações sobre as opções de ALTER SHARE, consulte ALTER SHARE.
Execute o seguinte comando CLI do Databricks:
databricks shares update <share-name> \
--json '{
"updates": [
{
"action": "ADD",
"data_object": {
"name": "<view-full-name>",
"data_object_type": "VIEW",
"shared_as": "<view-alias>"
}
}
]
}'
"shared_as": "<view-alias>" é opcional e fornece um nome de view alternativo, ou alias, para tornar o nome da view mais legível. O alias é o nome da view que o destinatário vê e deve usar nas queries. Os destinatários não podem usar o nome da view real se um alias for especificado. Use o formato <schema-name>.<view-name>.
Para saber mais sobre parâmetros adicionais, execute databricks shares update --help ou consulte PATCH /api/2.1/unity-catalog/shares/ na referência da API REST.
Para obter informações sobre como remover o view de um compartilhamento, consulte Atualizar compartilhamentos.
Adicionar views dinâmicas a um compartilhamento para filtrar linhas e colunas
Você pode usar views dinâmicas para configurar o controle de acesso refinado aos dados da tabela, incluindo:
- Segurança no nível de colunas ou linhas.
- mascaramento de dados.
Ao criar uma view dinâmica que usa a função CURRENT_RECIPIENT(), você pode limitar o acesso do destinatário de acordo com as propriedades que você especifica na definição do destinatário.
Esta seção oferece exemplos de restrição do acesso do destinatário aos dados da tabela nos níveis de linha e coluna usando uma view dinâmica.
Requisitos
- Verifique se você atende aos requisitos para adicionar uma view a um compartilhamento.
- Versão do Databricks Runtime : A função
CURRENT_RECIPIENTé compatível com o Databricks Runtime 14.2 e acima.
Limitações
- Todas as limitações para compartilhamento de view se aplicam.
- Quando um provedor compartilha uma view que usa a função
CURRENT_RECIPIENT, o provedor não pode consultar a view diretamente devido ao contexto de compartilhamento. Para testar essa view dinâmica, o provedor deve compartilhar a view consigo mesmo e consultar a view como um destinatário. - Os provedores não podem criar uma view que faça referência a uma view dinâmica.
Defina uma propriedade de destinatário
Nestes exemplos, a tabela a ser compartilhada tem uma coluna chamada country, e apenas destinatários com uma propriedade country correspondente podem view certas linhas ou colunas.
Você pode definir as propriedades do destinatário usando o Catalog Explorer ou comandos SQL em um Notebook do Databricks ou no editor de consultas SQL.
- Catalog Explorer
- SQL
-
No seu Databricks workspace, clique em
Catálogo . -
No topo do painel Catálogo , clique no ícone de
engrenagem e selecione OpenSharing .Alternativamente, no canto superior direito, clique em **Share > OpenSharing**.
-
Na tab Destinatários , encontre o destinatário ao qual deseja adicionar as propriedades e clique no nome.
-
No canto inferior direito da página, em Propriedades do destinatário , clique no lápis
 ao lado de databricks.metastoreID para um destinatário Databricks ou ao lado de databricks.name para um destinatário aberto.
ao lado de databricks.metastoreID para um destinatário Databricks ou ao lado de databricks.name para um destinatário aberto. -
Na caixa de diálogo **Editar propriedades do destinatário**, insira o nome da coluna como uma key (neste
countrycaso,) e o valor pelo qual você deseja filtrar como o valor (porCAexemplo,). -
Clique em Salvar .
Para definir a propriedade no destinatário, use ALTER RECIPIENT. Neste exemplo, a propriedade country é definida como CA.
ALTER RECIPIENT recipient1 SET PROPERTIES ('country' = 'CA');
Crie uma view dinâmica com permissão em nível de linha para destinatários
Neste exemplo, apenas os destinatários com uma propriedade country correspondente podem visualizar determinadas linhas.
CREATE VIEW my_catalog.default.view1 AS
SELECT * FROM my_catalog.default.my_table
WHERE country = CURRENT_RECIPIENT('country');
Outra opção é o provedor de dados manter uma tabela de mapeamento separada que mapeia os campos da tabela de fatos para as propriedades do destinatário. Isso permite que as propriedades do destinatário e os campos da tabela de fatos sejam desacoplados para maior flexibilidade.
Criar uma view dinâmica com permissão em nível de coluna para destinatários
Neste exemplo, somente os destinatários que correspondem à propriedade country podem visualizar determinadas colunas. Outros veem os dados retornados como REDACTED:
CREATE VIEW my_catalog.default.view2 AS
SELECT
CASE
WHEN CURRENT_RECIPIENT('country') = 'US' THEN pii
ELSE 'REDACTED'
END AS pii
FROM my_catalog.default.my_table;
Compartilhe a view dinâmica com um destinatário
Para compartilhar a view dinâmica com um destinatário, use os mesmos comandos SQL ou procedimento da UI que você usaria para uma view padrão. Consulte Adicionar exibições a um compartilhamento.
Adicionar views materializadas a um compartilhamento
Assim como as views, as views materializadas são os resultados de uma consulta e você pode acessá-las como faria com uma tabela. Ao contrário das views regulares, os resultados de uma view materializada refletem o estado dos dados quando a view materializada foi atualizada pela última vez. Para obter mais detalhes sobre views materializadas, consulte Usar views materializadas autônomas.
Verifique se atende aos requisitos antes de adicionar views materializadas a um compartilhamento.
Requisitos adicionais
-
Você deve habilitar o compute Serverless para fluxos de trabalho, Notebooks e Lakeflow Pipelines na account onde o compartilhamento de materialized view está configurado. Consulte Conectar-se ao compute serverless.
-
Se o seu workspace tiver vinculações de catálogo de workspace habilitadas, verifique se o workspace tem acesso de leitura e gravação ao catálogo que contém a view materializada. Para obter mais informação, consulte Vinculação de workspace-catálogo.
-
As views materializadas compartilháveis devem ser definidas em tabelas Delta ou em outras tabelas de transmissão, views ou views materializadas compartilháveis.
-
Você deve usar um SQL warehouse ou um compute no Databricks Runtime 13.3 LTS ou acima ao adicionar uma view materializada a um compartilhamento.
Limitações
- A visualização materializada não pode ter filtros de linha, mas a tabela base da visualização materializada pode ter filtros de linha e máscaras de coluna.
- A view materializada não pode ter filtros de partição. Em vez disso, crie uma view sobre a view materializada.
- Os destinatários do compartilhamento Databricks-para-aberto podem ler apenas o Snapshot atual da view materializada. Leituras de transmissão não são compatíveis para destinatários abertos.
- Se o destinatário não tiver acesso direto aos dados subjacentes,
LIMITcláusulas e pushdown de predicado não serão suportados. O sistema materializa completamente todos os resultados da consulta antes de retorná-los ao destinatário, independentemente dos filtros de consulta. Consulte Os destinatários têm acesso direto aos dados subjacentes em views compartilhadas, views materializadas e tabelas de transmissão? - Limitações gerais para visualizações materializadas também se aplicam. Consulte Limitações das visualizações materializadas.
Compartilhe views materializadas com um destinatário
Esta seção descreve como adicionar views materializadas a um compartilhamento usando o Catalog Explorer, Databricks CLI ou comandos SQL em um Notebook do Databricks ou no editor de consultas do Databricks SQL. Se você preferir usar a API REST, consulte PATCH /api/2.1/unity-catalog/shares/ na referência da API REST.
- Catalog Explorer
- SQL
- CLI
-
No seu Databricks workspace, clique em
Catálogo . -
No topo do painel Catálogo , clique no ícone de
engrenagem e selecione OpenSharing .Alternativamente, no canto superior direito, clique em **Share > OpenSharing**.
-
Na **tab Compartilhados por mim**, localize o compartilhamento ao qual você deseja adicionar uma materialized view e clique no nome dele.
-
Clique em **Gerenciar ativos > Editar ativos**.
-
Na página Editar ativos , pesquise ou navegue pela view materializada que você deseja compartilhar e selecione-a.
-
(Opcional) Na coluna **Alias**, clique em
para especificar um alias ou nome alternativo de view materializada para tornar o nome da view materializada mais legível. O alias é o nome que o destinatário vê e deve usar nas consultas. Os destinatários não podem usar o nome real da view materializada se um alias for especificado. -
Clique em Salvar .
Execute o seguinte comando em um notebook ou no editor de consultas SQL do Databricks.
ALTER SHARE <share_name> ADD MATERIALIZED VIEW <mv_name> [COMMENT <comment>] [AS <shared_mv_name>];
databricks shares update <share-name> \
--json '{
“updates”: [
{
“action”: “ADD”,
“data_object”: {
“name”: “<mat-view-full-name>”,
“data_object_type”: “MATERIALIZED_VIEW”,
“comment”: “<comment>”
}
}
]
}'
Para obter informações sobre a remoção de exibições materializadas de um compartilhamento, consulte Atualizar compartilhamentos.
Adicione volumes a um compartilhamento
Volumes são objetos do Unity Catalog que representam um volume lógico de armazenamento em um local de armazenamento de objetos em nuvem. Eles se destinam principalmente a fornecer governança sobre ativos de dados não tabulares. Consulte O que são volumes do Unity Catalog?.
Verifique se você atende aos requisitos antes de adicionar volumes a um compartilhamento.
Requisitos adicionais
- O compartilhamento de volume é compatível apenas no compartilhamento Databricks-to-Databricks.
- Você deve usar um SQL warehouse na versão 2023.50 ou acima ou um recurso de compute no Databricks Runtime 14.1 ou acima ao adicionar um volume a um compartilhamento.
- Se o armazenamento de volume no lado do provedor tiver configurações de rede personalizadas (como um firewall ou link privado), então o provedor deve verificar se os endereços do plano de dados do destinatário estão devidamente permitidos para poder se conectar ao local de armazenamento do volume. O Catalog Explorer pode não exibir os volumes corretamente para o destinatário.
Os comentários do volume estão incluídos em compartilhamentos que são compartilhados com um destinatário usando o compartilhamento Databricks-to-Databricks em ou após 25 de julho de 2024. Caso se deseje começar a compartilhar comentários por meio de um compartilhamento que foi compartilhado com um destinatário antes da data de lançamento, é necessário revogar e conceder novamente o acesso ao destinatário para acionar o compartilhamento de comentários.
Compartilhar volumes com um destinatário
Esta seção descreve como adicionar volumes a um compartilhamento usando o Catalog Explorer, a CLI do Databricks ou comandos SQL em um Notebook do Databricks ou editor de consulta SQL. Se preferir usar a API REST do Unity Catalog, consulte PATCH /api/2.1/unity-catalog/shares/ na referência da API REST.
- Catalog Explorer
- SQL
- CLI
-
No seu Databricks workspace, clique em
Catálogo . -
No topo do painel Catálogo , clique no ícone de
engrenagem e selecione OpenSharing .Alternativamente, no canto superior direito, clique em **Share > OpenSharing**.
-
Na tab **Compartilhado por mim**, encontre o compartilhamento ao qual você deseja adicionar um volume e clique em seu nome.
-
Clique em **Gerenciar ativos > Editar ativos**.
-
Na página **Editar ativos**, pesquise ou navegue pelo volume que deseja compartilhar e selecione-o.
Alternativamente, você pode selecionar o esquema inteiro que contém o volume. Consulte Adicionar esquemas a um compartilhamento.
-
(Opcional) Clique
em na coluna **Alias** para especificar um nome de volume alternativo, ou **Alias**, para tornar o nome do volume mais legível.Aliases não estão disponíveis se você selecionar um esquema inteiro.
O alias é o nome que o destinatário vê e deve usar em consultas. Se um alias for especificado, os destinatários não poderão usar o nome real do volume.
-
Clique em Salvar .
Execute o seguinte comando em um Notebook ou no editor de consultas SQL do Databricks:
ALTER SHARE <share-name> ADD VOLUME <catalog-name>.<schema-name>.<volume-name>
[COMMENT "<comment>"]
[AS <alias>];
As opções incluem:
AS <alias>: Um nome de volume alternativo, ou alias, para tornar o nome do volume mais legível. O alias é o nome do volume que o destinatário vê e deve usar em queries. Os destinatários não podem usar o nome real do volume se um alias for especificado. Use o formato<schema-name>.<volume-name>.COMMENT "<comment>": Os comentários aparecem na interface do usuário do Catalog Explorer e quando você lista e exibe detalhes do volume usando instruções SQL.
Para obter mais informações sobre as opções de ALTER SHARE, consulte ALTER SHARE.
Execute o seguinte comando usando Databricks CLI 0.210 ou acima:
databricks shares update <share-name> \
--json '{
"updates": [
{
"action": "ADD",
"data_object": {
"name": "<volume-full-name>",
"data_object_type": "VOLUME",
"string_shared_as": "<volume-alias>"
}
}
]
}'
"string_shared_as": "<volume-alias>" é opcional e fornece um nome de volume alternativo, ou alias, para tornar o nome do volume mais legível. O alias é o nome do volume que o destinatário vê e deve usar em queries. Os destinatários não podem usar o nome real do volume se um alias for especificado. Use o formato <schema-name>.<volume-name>.
Para saber mais sobre parâmetros adicionais, execute databricks shares update --help ou consulte PATCH /api/2.1/unity-catalog/shares/ na referência da API REST.
Para obter informações sobre como remover volumes de um compartilhamento, consulte Atualizar compartilhamentos.
Adicionar UDFs em Python a um compartilhamento
Funções definidas pelo usuário (UDFs) permitem reutilizar e compartilhar código que estende a funcionalidade integrada no Databricks. Para saber como criar UDFs Python, consulte Funções escalares definidas pelo usuário - Python.
Verifique se você atende aos requisitos antes de adicionar UDFs Python a um compartilhamento.
Limitações adicionais
- Você não pode compartilhar UDFs Python com um destinatário aberto.
Compartilhar UDFs em Python com um destinatário
Esta seção descreve como adicionar UDFs Python a um compartilhamento usando o Catalog Explorer, a CLI do Databricks ou comandos SQL em um Notebook do Databricks ou editor de consultas SQL. Se você preferir usar a API REST do Unity Catalog, consulte PATCH /api/2.1/unity-catalog/shares/ na referência da API REST.
- Catalog Explorer
- SQL
- CLI
-
No seu Databricks workspace, clique em
Catálogo . -
No topo do painel Catálogo , clique no ícone de
engrenagem e selecione OpenSharing .Alternativamente, no canto superior direito, clique em **Share > OpenSharing**.
-
Na **tab Compartilhado por mim**, localize o compartilhamento ao qual você deseja adicionar um UDF Python e clique em seu nome.
-
Clique em **Gerenciar ativos > Editar ativos**.
-
Na página Editar ativos , pesquise ou navegue pelo Python UDF que você deseja compartilhar e selecione-o.
Alternativamente, você pode selecionar todo o esquema que contém a UDF Python. Consulte Adicionar esquemas a um compartilhamento.
-
(Opcional) Clique
em sob a coluna **Alias** para especificar um nome de UDF Python alternativo, ou **Alias**, para tornar o nome da UDF Python mais legível.Aliases não estão disponíveis se você selecionar um esquema inteiro.
O alias é o nome que o destinatário vê e deve usar em consultas. Se um alias for especificado, os destinatários não poderão usar o nome real do Python UDF.
-
Clique em Salvar .
Execute o seguinte comando, que usa ADD MODEL, em um Notebook ou no editor de consultas do Databricks SQL:
ALTER SHARE <share-name> ADD MODEL <catalog-name>.<schema-name>.<python-udf-name>
[AS <alias>];
As opções incluem:
AS <alias>: Um nome alternativo de UDF Python, ou alias, para tornar o nome da UDF Python mais legível. O alias é o nome da UDF Python que o destinatário vê e deve usar nas consultas. Os destinatários não podem usar o nome real da UDF Python se um alias for especificado. Use o formato<schema-name>.<python-udf-name>.
Para obter mais informações sobre as opções de ALTER SHARE, consulte ALTER SHARE.
Execute o seguinte comando, que especifica o tipo de objeto como modelo, usando a CLI do Databricks 0.210 ou acima:
databricks shares update <share-name> \
--json '{
"updates": [
{
"action": "ADD",
"data_object": {
"name": "<python-udf-full-name>",
"data_object_type": "MODEL",
"string_shared_as": "<python-udf-alias>"
}
}
]
}'
"string_shared_as": "<python-udf-alias>" é opcional e fornece um nome de Python UDF alternativo, ou alias, para tornar o nome do Python UDF mais legível. O alias é o nome da UDF Python que o destinatário vê e deve usar nas consultas. Os destinatários não podem usar o nome real da UDF Python se um alias for especificado. Use o formato <schema-name>.<python-udf-name>.
Para saber mais sobre parâmetros adicionais, execute databricks shares update --help ou consulte PATCH /api/2.1/unity-catalog/shares/ na referência da API REST.
Adicionar modelos a um compartilhamento
Verifique se você atende aos requisitos antes de adicionar modelos a um compartilhamento.
Comentários do modelo e comentários da versão do modelo são incluídos em compartilhamentos feitos usando o compartilhamento Databricks-to-Databricks.
Requisitos adicionais
- O compartilhamento de modelos é suportado apenas no compartilhamento Databricks-to-Databricks.
- Você deve usar um SQL warehouse na versão 2023.50 ou superior ou um recurso de compute no Databricks Runtime 14.0 ou superior ao adicionar um modelo a um compartilhamento.
Compartilhe modelos com um destinatário.
Esta seção descreve como adicionar modelos a um compartilhamento usando o Catalog Explorer, a CLI do Databricks ou comandos SQL em um Notebook do Databricks ou no editor de consultas SQL. Se preferir usar a API REST do Unity Catalog, consulte PATCH /api/2.1/unity-catalog/shares/ na referência da API REST.
Para adicionar modelos a um compartilhamento:
- Catalog Explorer
- SQL
- CLI
-
No seu Databricks workspace, clique em
Catálogo . -
No topo do painel Catálogo , clique no ícone de
engrenagem e selecione OpenSharing .Alternativamente, no canto superior direito, clique em **Share > OpenSharing**.
-
Na guia Compartilhados por mim , localize o compartilhamento ao qual deseja adicionar um modelo e clique em seu nome.
-
Clique em **Gerenciar ativos > Editar ativos**.
-
Na página Editar ativos , pesquise ou navegue pelo modelo que você deseja compartilhar e selecione-o.
Alternativamente, você pode selecionar o esquema inteiro que contém o modelo. Consulte Adicionar esquemas a um compartilhamento.
-
(Opcional) Clique em
sob a coluna Alias para especificar um nome de modelo alternativo, ou Alias , para tornar o nome do modelo mais legível.Aliases não estão disponíveis se você selecionar um esquema inteiro.
O alias é o nome que o destinatário vê e deve usar nas consultas. Os destinatários não podem usar o nome real do modelo se um alias for especificado.
-
Clique em Salvar .
Execute o seguinte comando em um Notebook ou no editor de consultas SQL do Databricks:
ALTER SHARE <share-name> ADD MODEL <catalog-name>.<schema-name>.<model-name>
[COMMENT "<comment>"]
[AS <alias>];
As opções incluem:
AS <alias>: Um nome de modelo alternativo, ou alias, para tornar o nome do modelo mais legível. O alias é o nome do modelo que o destinatário vê e deve usar em queries. Os destinatários não podem usar o nome real do modelo se um alias for especificado. Use o formato<schema-name>.<model-name>.COMMENT "<comment>": Os comentários aparecem na UI do Catalog Explorer e quando você lista e exibe detalhes do modelo usando instruções SQL.
Para obter mais informações sobre as opções de ALTER SHARE, consulte ALTER SHARE.
Execute o seguinte comando usando Databricks CLI 0.210 ou acima:
databricks shares update <share-name> \
--json '{
"updates": [
{
"action": "ADD",
"data_object": {
"name": "<model-full-name>",
"data_object_type": "MODEL",
"string_shared_as": "<model-alias>"
}
}
]
}'
"string_shared_as": "<model-alias>" é opcional e fornece um nome de modelo alternativo, ou alias, para tornar o nome do modelo mais legível. O alias é o nome do modelo que o destinatário vê e deve usar nas consultas. Os destinatários não podem usar o nome real do modelo se um alias for especificado. Use o formato <schema-name>.<model-name>.
Para saber mais sobre parâmetros adicionais, execute databricks shares update --help ou consulte PATCH /api/2.1/unity-catalog/shares/ na referência da API REST.
Para obter informações sobre como remover modelos de um compartilhamento, consulte Atualizar compartilhamentos.
Adicionar arquivos de notebook a um compartilhamento
Verifique se você atende aos requisitos antes de adicionar arquivos de Notebook a um compartilhamento.
Utilize o Catalog Explorer para adicionar um arquivo de notebook a um compartilhamento.
-
No seu Databricks workspace, clique em
Catálogo . -
Clique no botão OpenSharing > .
-
Na tab **Compartilhado por mim**, localize o compartilhamento ao qual deseja adicionar um Notebook e clique no nome dele.
-
Clique em Gerenciar ativos e selecione Adicionar arquivo de Notebook .
-
Na página Adicionar arquivo de Notebook , clique no ícone de arquivo para procurar o Notebook que você deseja compartilhar.
- Clique no arquivo que você deseja compartilhar e clique em Selecionar .
- (Opcionalmente) especifique um alias amigável para o arquivo no campo Compartilhar como . Este é o identificador que os destinatários veem.
- Em Local de armazenamento , insira o local externo no armazenamento em cloud onde você deseja armazenar o Notebook. Você pode especificar um subcaminho sob o local externo definido. Se você não especificar um local externo, o Notebook será armazenado no local de armazenamento em nível de metastore (ou “local raiz do metastore”). Se nenhum local raiz for definido para o metastore, você deverá inserir um local externo aqui. Consulte Adicionar armazenamento gerenciado a um metastore existente.
-
Clique em Salvar .
O arquivo de Notebook compartilhado agora aparece na lista Arquivos de Notebook na tab Ativos .
Remover arquivos de notebook de compartilhamentos
Para remover um arquivo de notebook de um compartilhamento:
-
No seu Databricks workspace, clique em
Catálogo . -
No topo do painel Catálogo , clique no ícone de
engrenagem e selecione OpenSharing .Alternativamente, no canto superior direito, clique em **Share > OpenSharing**.
-
Na tab Compartilhados por mim, encontre o compartilhamento que inclui o Notebook e clique no nome do compartilhamento.
-
Na tab Ativos , encontre o arquivo do Notebook que você deseja remover do compartilhamento.
-
Clique no
 menu kebab à direita da linha e selecione **Excluir arquivo de notebook**.
menu kebab à direita da linha e selecione **Excluir arquivo de notebook**. -
Na caixa de diálogo de confirmação, clique em Excluir .
Atualizar arquivos de notebook em compartilhamentos
Para atualizar um Notebook que você já compartilhou, você deve adicioná-lo novamente, dando a ele um novo apelido no campo Compartilhar como . A Databricks recomenda que você use um nome que indique o status revisado do Notebook, como <old-name>-update-1. Poderá ser necessário notificar o destinatário sobre a alteração. O destinatário deve selecionar e clonar o novo Notebook para aproveitar sua atualização.
Habilitar compartilhamento para clientes Iceberg externos
Você pode compartilhar tabelas Delta, tabelas Iceberg externas, views, views materializadas e tabelas de transmissão com clientes Iceberg externos que usam a API REST de Catálogo Apache Iceberg.
Antes de compartilhar, certifique-se de que você atende aos requisitos do OpenSharing necessários para adicionar seu ativo de dados a um compartilhamento.
Este recurso é diferente do compartilhamento de tabelas Iceberg gerenciadas.
Limitações adicionais
- Tabelas com vetores de exclusão ativados não são suportadas.
- Tabelas Iceberg gerenciadas não são suportadas.
- ativos que usam armazenamento default não podem ser compartilhados com clientes Iceberg externos. Consulte Armazenamento default no Databricks.
Compartilhar com clientes Iceberg externos
Para compartilhar ativos de dados com clientes Iceberg externos:
-
Se você estiver compartilhando uma tabela Delta, configure cada tabela Delta com
IcebergCompatV3para expô-la como uma tabela compatível com Iceberg. Isso permite a geração assíncrona de metadados Iceberg junto com as operações Delta padrão. Verifique se você atende aos requisitos para o compartilhamento de tabelas Delta com clientes Iceberg e observe as limitações. Para saber como habilitar as leituras Iceberg, consulte Habilitar leituras Iceberg (UniForm).Se estiver compartilhando com o Snowflake, apenas tabelas habilitadas para uniforme aparecerão para o destinatário. Outras tabelas são filtradas.
- Use
DESCRIBE HISTORYpara confirmar que a geração de metadados do Iceberg foi concluída antes que a tabela possa ser consultada de clientes Iceberg. - O tipo de autenticação OIDC não é compatível.
-
Adicione o ativo de dados a um compartilhamento. Para obter instruções detalhadas, consulte:
A materialização de dados do lado do provedor é acionada se views, views materializadas ou tabelas de transmissão forem compartilhadas, o que pode levar ao acúmulo de custos de compute. Para obter mais informações, consulte Como incorro e verifico os custos de Compartilhamento Aberto?.
- Compartilhe com o destinatário aberto. Para obter instruções sobre como criar um destinatário e conceder a ele acesso ao compartilhamento, consulte Criar um objeto destinatário para usuários que não são do Databricks usando tokens de portador (compartilhamento Databricks para Aberto) ou Habilitar a federação do Open ID Connect (OIDC) para destinatários do OpenSharing.