Ler dados compartilhados com tokens de portador
Esta página descreve como ler dados compartilhados com você usando o protocolo de *compartilhamento aberto* OpenSharing com tokens de portador. Inclui instruções para ler dados compartilhados utilizando as seguintes ferramentas:
Neste modelo de compartilhamento, você usa um arquivo de credenciais, compartilhado com um membro da sua equipe pelo provedor de dados, para obter acesso de leitura seguro aos dados compartilhados. O acesso persiste enquanto a credencial for válida e o provedor continuar a compartilhar os dados. Os provedores gerenciam a expiração e a rotação de credenciais. As atualizações dos dados estão disponíveis quase em tempo real. É possível ler e fazer cópias dos dados compartilhados, mas não é possível modificar os dados de origem.
Se os dados foram compartilhados com você usando Databricks-to-Databricks OpenSharing, você não precisa de um arquivo de credencial para acessar os dados, e esta página não se aplica a você. Em vez disso, consulte Ler dados compartilhados usando o Databricks-to-Databricks OpenSharing (para destinatários).
As seções a seguir descrevem como usar os clientes Apache Spark, pandas, Power BI e Iceberg para acessar e ler dados compartilhados usando o arquivo de credenciais. Para ver a lista completa de conectores do OpenSharing e informações sobre como usá-los, consulte a documentação de código aberto do OpenSharing. Se você tiver problemas para acessar os dados compartilhados, entre em contato com o provedor de dados.
Antes de começar
Um membro da equipe deve fazer o download do arquivo de credencial compartilhado pelo provedor de dados e usar um canal seguro para o compartilhamento desse arquivo ou de sua localização. Consulte Obter acesso no modelo de compartilhamento Databricks-para-Open.
Para documentação específica do conector, consulte a página de downloads de credenciais.
Clientes Iceberg: Lêem dados compartilhados
Use clientes Iceberg externos, como Snowflake, Trino, Flink e Spark, para ler ativos de dados compartilhados com acesso de cópia zero usando a API de Catálogo REST do Apache Iceberg.
Obter credenciais de conexão
Antes de acessar ativos de dados compartilhados com clientes Iceberg externos, colete as seguintes credenciais:
- O endpoint do Catálogo REST do Iceberg
- Um token do portador válido
- O nome do compartilhamento
- (Opcional) O nome do namespace ou esquema
- (Opcional) O nome da tabela
O endpoint do Catálogo REST do Iceberg (icebergEndpoint) e o token Bearer são encontrados no arquivo de credenciais compartilhado com você por seu provedor de dados. Para obter mais informações, consulte Antes de começar. O nome do compartilhamento, namespace e nome da tabela podem ser descobertos programaticamente usando APIs do OpenSharing.
O icebergEndpoint é encontrado no arquivo de credenciais e tem o formato <workspace-url>/api/2.0/delta-sharing/metastores/<metastore-id>/iceberg.
Os exemplos a seguir mostram como obter as credenciais adicionais. Insira o endpoint, o endpoint Iceberg e o token Bearer do arquivo de credenciais, quando necessário:
// List shares
curl -X GET "<endpoint>/shares" \
-H "Authorization: Bearer <bearerToken>"
// List namespaces
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces" \
-H "Authorization: Bearer <bearerToken>"
// List tables
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces/<namespace>/tables" \
-H "Authorization: Bearer <bearerToken>"
Este método sempre recupera a lista de ativos mais atualizada. No entanto, exige acesso à internet e pode ser mais difícil de integrar em ambientes sem código.
Configurar catálogo Iceberg
Após obter as credenciais de conexão necessárias, configure seu cliente para usar os endpoints do Catálogo REST do Iceberg para criar e consultar tabelas.
-
Para cada compartilhamento, crie uma integração de catálogo.
SQLUSE ROLE ACCOUNTADMIN;
CREATE OR REPLACE CATALOG INTEGRATION <CATALOG_PLACEHOLDER>
CATALOG_SOURCE = ICEBERG_REST
TABLE_FORMAT = ICEBERG
REST_CONFIG = (
CATALOG_URI = '<icebergEndpoint>',
WAREHOUSE = '<share_name>',
ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS
)
REST_AUTHENTICATION = (
TYPE = BEARER,
BEARER_TOKEN = '<bearerToken>'
)
ENABLED = TRUE; -
Opcionalmente, adicione
REFRESH_INTERVAL_SECONDSpara manter os metadados atualizados. Defina o valor com base na frequência de atualização do seu catálogo.SQLREFRESH_INTERVAL_SECONDS = 30 -
Após o catálogo ser configurado, crie um banco de dados a partir do catálogo. Isto cria automaticamente todos os esquemas e tabelas nesse catálogo.
SQLCREATE DATABASE <DATABASE_PLACEHOLDER>
LINKED_CATALOG = (
CATALOG = <CATALOG_PLACEHOLDER>
); -
Para confirmar que o compartilhamento foi bem-sucedido, consulte uma tabela no banco de dados. Será possível ver os dados compartilhados do Databricks.
Se o resultado estiver vazio ou ocorrer um erro, siga estas etapas comuns de solução de problemas:
- Verifique novamente os privilégios, o status de geração de Snapshot e as credenciais REST.
- Entre em contato com seu provedor de dados.
- Consulte a documentação específica para seu cliente Iceberg.
Exemplo: Acessar tabelas compartilhadas usando diferentes clientes Iceberg
Os exemplos a seguir mostram como acessar tabelas compartilhadas usando clientes Iceberg externos, como Snowflake, Apache Spark, PyIceberg e API REST, após obter suas credenciais de conexão. Para saber mais sobre como obter credenciais de conexão, consulte Antes de começar.
- Snowflake
- Apache Spark
- PyIceberg
- REST API
Para ler ativos de dados compartilhados no Snowflake, faça o upload do arquivo de credencial que você baixou e gere o comando SQL necessário:
-
Do seu link de ativação do OpenSharing, clique no ícone do Snowflake.
-
Na página de integração do Snowflake, faça upload do arquivo de credencial que você recebeu do provedor de dados.
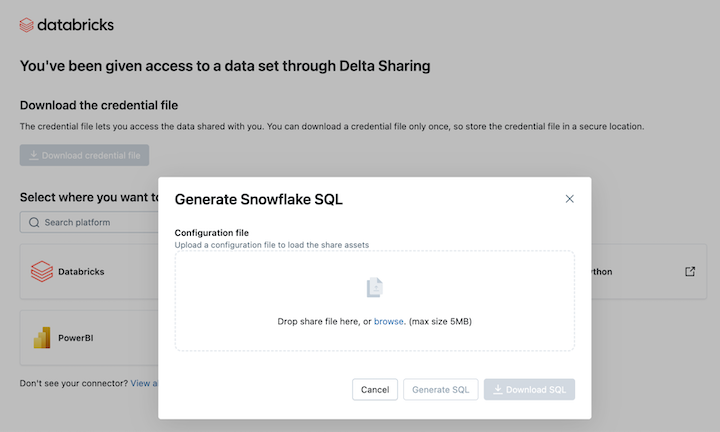
-
Após carregar a credencial, escolha o compartilhamento que você deseja acessar no Snowflake.
-
Clique em Gerar SQL após selecionar os ativos desejados.
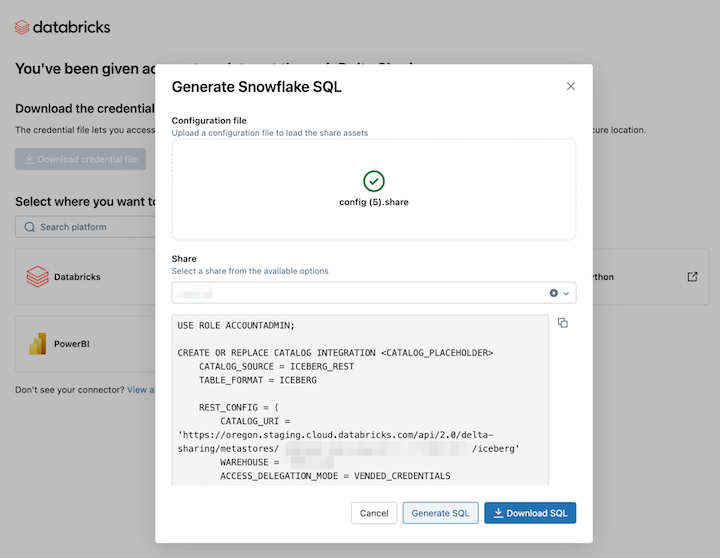
-
Copie e cole o SQL gerado em sua planilha do Snowflake. Substitua
CATALOG_PLACEHOLDERpelo nome do catálogo que deseja usar eDATABASE_PLACEHOLDERpelo nome do banco de dados que deseja usar.
Limitações
A conexão com o Catálogo REST do Iceberg no Snowflake tem as seguintes limitações:
- O arquivo de metadados não é atualizado automaticamente com o Snapshot mais recente. É necessário contar com o Refresh automático ou com os refreshes manuais.
- R2 não é compatível.
- Todas as limitações do cliente Iceberg aplicam-se.
Para acessar tabelas compartilhadas usando o Apache Spark, configure a API REST Catalog do Iceberg com as seguintes configurações. Substitua <spark-catalog-name> por um nome para seu catálogo e forneça suas credenciais de conexão:
"spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
# Configuration for accessing tables shared using Delta Sharing
"spark.sql.catalog.<spark-catalog-name>":"org.apache.iceberg.spark.SparkCatalog",
"spark.sql.catalog.<spark-catalog-name>.type": "rest",
"spark.sql.catalog.<spark-catalog-name>.uri": "<icebergEndpoint>",
"spark.sql.catalog.<spark-catalog-name>.token": "<bearerToken>",
"spark.sql.catalog.<spark-catalog-name>.warehouse":"<share_name>",
"spark.sql.catalog.<spark-catalog-name>.scope":"all-apis"
PyIceberg é uma implementação Python para acessar tabelas Iceberg sem usar uma JVM. O PyIceberg requer pyarrow para operações de tabela, como ler dados e inspecionar metadados de tabela. Instale o PyIceberg com o extra pyarrow:
pip install "pyiceberg[pyarrow]"
Para acessar tabelas compartilhadas, adicione a seguinte configuração de catálogo ao seu arquivo de configuração PyIceberg:
catalog:
delta_sharing:
type: rest
uri: <icebergEndpoint>
warehouse: <share_name>
token: <bearerToken>
Use uma chamada de API REST como o exemplo curl a seguir para carregar uma tabela e recuperar seus metadados, juntamente com credenciais temporárias para acessar os arquivos de dados:
curl -X GET -H "Authorization: Bearer <bearerToken>" -H "Accept: application/json" \
<icebergEndpoint>/v1/shares/<share_name>/namespaces/<schema_name>/tables/<table_name>
A resposta inclui os metadados da tabela Iceberg, o local S3 e credenciais temporárias da AWS que permitem ao seu cliente ler os arquivos de dados:
{
"metadata-location": "s3://bucket/path/to/iceberg/table/metadata/file",
"metadata": <iceberg-table-metadata-json>,
"config": {
"expires-at-ms": "<epoch-ts-in-millis>",
"s3.access-key-id": "<temporary-s3-access-key-id>",
"s3.session-token": "<temporary-s3-session-token>",
"s3.secret-access-key": "<temporary-secret-access-key>",
"client.region": "<aws-bucket-region-for-metadata-location>"
}
}
Limitações do cliente Iceberg
Aplicam-se as seguintes limitações ao consultar dados OpenSharing de clientes Iceberg:
- Ao listar tabelas em um namespace, se o namespace contiver mais de 100 views compartilhadas, a resposta é limitada às primeiras 100 views.
Apache Spark: Ler dados compartilhados
Siga estes passos para acessar o uso compartilhado de dados Spark 3.x ouacima.
Estas instruções assumem que você tem acesso ao arquivo de credencial que foi compartilhado pelo provedor de dados. Consulte Obter acesso no modelo de compartilhamento Databricks-para-Open.
Certifique-se de que seu arquivo de credencial esteja acessível pelo Apache Spark usando um caminho absoluto. O caminho pode se referir a um objeto cloud ou a um volume do Unity Catalog.
Se estiver usando o Spark em um Workspace do Databricks habilitado para o Unity Catalog e tiver utilizado a interface do usuário de importação de provedores para importar o provedor e o compartilhamento, as instruções nesta seção não se aplicam a você. É possível acessar tabelas compartilhadas da mesma forma que qualquer outra tabela registrada no Unity Catalog. Não é necessário instalar o conector Python delta-sharing ou fornecer o caminho para o arquivo de credencial. Consulte Importar um provedor e ler dados compartilhados no Databricks.
Instalar os conectores OpenSharing Python e Spark
Para acessar metadados relacionados aos dados compartilhados, como a lista de tabelas compartilhadas com você, faça o seguinte. Este exemplo usa Python.
-
Instale o conector Python de compartilhamento Delta. Para obter informações sobre as limitações do conector Python, consulte Limitações do conector Python do OpenSharing.
Bashpip install delta-sharing -
Instale o conector Apache Spark.
Listar tabelas compartilhadas usando Spark
Listar as tabelas no compartilhamento. No exemplo a seguir, substitua <profile-path> pelo local do arquivo de credencial.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
O resultado é um array de tabelas, juntamente com os metadados para cada tabela. A seguinte saída mostra duas tabelas:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]
Se a saída estiver vazia ou não contiver as tabelas esperadas, contate o provedor de dados.
Acessar dados compartilhados usando Spark
Execute o seguinte, substituindo estas variáveis:
<profile-path>: o local do arquivo de credenciais.<share-name>: o valor deshare=para a tabela.<schema-name>: o valor deschema=para a tabela.<table-name>: o valor dename=para a tabela.<version-as-of>: opcional. A versão da tabela para carregar os dados. Só funciona se o provedor de dados compartilhar a história da tabela. Requerdelta-sharing-spark0.5.0 ouacima.<timestamp-as-of>: opcional. Carregue os dados na versão anterior ou no carimbo de data/hora fornecido. Só funciona se o provedor de dados compartilhar a história da tabela. Requerdelta-sharing-spark0.6.0 ouacima.
- Python
- Scala
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", version=<version-as-of>)
spark.read.format("deltaSharing")\
.option("versionAsOf", <version-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", timestamp=<timestamp-as-of>)
spark.read.format("deltaSharing")\
.option("timestampAsOf", <timestamp-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
spark.read.format("deltaSharing")
.option("versionAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
spark.read.format("deltaSharing")
.option("timestampAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
Acessar feed de dados de alteração compartilhado usando Spark
Se a história da tabela foi compartilhada e o feed de dados alterados (CDF) está habilitado na tabela de origem, acesse o feed de dados alterados executando o seguinte e substituindo essas variáveis. Requer delta-sharing-spark 0.5.0 ou acima.
Um parâmetro de início deve ser fornecido.
<profile-path>: o local do arquivo de credenciais.<share-name>: o valor deshare=para a tabela.<schema-name>: o valor deschema=para a tabela.<table-name>: o valor dename=para a tabela.<starting-version>: opcional. A versão inicial da query, inclusiva. Especifique como um Long.<ending-version>: opcional. A versão final da consulta, inclusive. Se a versão final não for fornecida, a API usa a versão mais recente da tabela.<starting-timestamp>: opcional. O carimbo de data/hora inicial da consulta, que é convertido em uma versão criada maior ou igual a este carimbo de data/hora. Especifique como uma string no formatoyyyy-mm-dd hh:mm:ss[.fffffffff].<ending-timestamp>: opcional. O carimbo de data/hora final da consulta, que é convertido em uma versão criada antes ou igual a este carimbo de data/hora. Especifique como uma string no formatoyyyy-mm-dd hh:mm:ss[.fffffffff]
- Python
- Scala
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingVersion", <starting-version>)\
.option("endingVersion", <ending-version>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingTimestamp", <starting-timestamp>)\
.option("endingTimestamp", <ending-timestamp>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingVersion", <starting-version>)
.option("endingVersion", <ending-version>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingTimestamp", <starting-timestamp>)
.option("endingTimestamp", <ending-timestamp>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Se a saída estiver vazia ou não contiver os dados esperados, entre em contato com o provedor de dados.
Acesse uma tabela compartilhada usando Spark transmissão estructurada
Se a história da tabela for compartilhada com você, você poderá ler os dados compartilhados por transmissão. Requer delta-sharing-spark 0.6.0 ouacima.
Opções compatíveis:
ignoreDeletes: Ignora transações que excluem dados.ignoreChanges: Reprocessar atualizações se os arquivos foram reescritos na tabela de origem devido a uma operação de alteração de dados, comoUPDATE,MERGE INTO,DELETE(dentro de partições) ouOVERWRITE. Linhas inalteradas ainda podem ser emitidas. Portanto, os consumidores downstream devem ser capazes de lidar com as duplicidades. As exclusões não são propagadas downstream.ignoreChangessubsumeignoreDeletes. Portanto, se usarignoreChanges, sua transmissão não é interrompida por exclusões nem por atualizações na tabela de origem.startingVersion: A versão da tabela compartilhada de onde começar. Todas as alterações da tabela a partir desta versão (inclusive) são lidas pela fonte de transmissão.startingTimestamp: O timestamp de onde começar. Todas as alterações da tabela confirmadas no ou após o timestamp (inclusive) são lidas pela origem de transmissão. Exemplo:"2023-01-01 00:00:00.0".maxFilesPerTrigger: O número de arquivos novos a serem considerados em cada micro-batch.maxBytesPerTrigger: A quantidade de dados processada em cada micro-lote. Essa opção define um "soft max", o que significa que um lote processa aproximadamente essa quantidade de dados e pode processar mais do que o limite para fazer a consulta de transmissão avançar nos casos em que a menor unidade de entrada é maior que esse limite.readChangeFeed: Leia por transmissão o feed de dados de alteração da tabela compartilhada.
Triggers compatíveis:
Trigger.ProcessingTime: O trigger default, usado quando nenhum trigger explícito é especificado. Os dados são processados em micro-lotes contínuos.Trigger.AvailableNow: A query captura a versão do lado do servidor da tabela compartilhada no começar, processa o backlog como múltiplos microlotes que respeitammaxFilesPerTriggeremaxVersionsPerRpc, e termina quando a versão capturada é esgotada. Requerdelta-sharing-spark1.4.0 ou superior. Versões mais antigas revertem para um wrapperTrigger.AvailableNowque não respeitamaxVersionsPerRpc.Trigger.Once: Obsoleto; useTrigger.AvailableNowem vez disso. Comdelta-sharing-sparkversões abaixo de 1.4.0,Trigger.AvailableNowrecorre a um wrapper que não respeitamaxVersionsPerRpc.
Exemplos de consultas de transmissão estructurada
- Python
- Scala
spark.readStream.format("deltaSharing")\
.option("startingVersion", 0)\
.option("ignoreDeletes", true)\
.option("maxBytesPerTrigger", 10000)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.readStream.format("deltaSharing")
.option("startingVersion", 0)
.option("ignoreChanges", true)
.option("maxFilesPerTrigger", 10)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Consulte também conceitos de transmissão estructurada.
Ler tabelas com vetores de exclusão ou mapeamento de coluna habilitado
Visualização
Esse recurso está em Prévia Pública.
Vetores de exclusão são um recurso de otimização de armazenamento que seu provedor pode habilitar em tabelas Delta compartilhadas. Consulte Vetores de exclusão no Databricks.
A Databricks também oferece suporte ao mapeamento de colunas para tabelas Delta. Consulte Renomear e eliminar colunas com o mapeamento de colunas do Delta Lake.
Se o seu provedor compartilhou uma tabela com vetores de exclusão ou mapeamento de coluna ativado, você pode ler a tabela usando o compute que está executando delta-sharing-spark 3.1 ou acima. Se você estiver usando clusters Databricks, poderá executar leituras em lotes usando um cluster executando o Databricks Runtime 14.1 ou superior. Consultas CDF e de transmissão exigem o Databricks Runtime 14.2 ou acima.
Você pode executar consultas em lote como estão, porque elas podem resolver automaticamente responseFormat com base nos recursos da tabela compartilhada.
Para ler um feed de dados de alteração (CDF) ou para executar consultas de transmissão em tabelas compartilhadas com vetores de exclusão ou mapeamento de coluna ativado, você deve definir a opção adicional responseFormat=delta.
Os exemplos a seguir mostram consultas de lotes, CDF e transmissão:
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("...")
.master("...")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
val tablePath = "<profile-file-path>#<share-name>.<schema-name>.<table-name>"
// Batch query
spark.read.format("deltaSharing").load(tablePath)
// CDF query
spark.read.format("deltaSharing")
.option("readChangeFeed", "true")
.option("responseFormat", "delta")
.option("startingVersion", 1)
.load(tablePath)
// Streaming query
spark.readStream.format("deltaSharing").option("responseFormat", "delta").load(tablePath)
Ler colunas de acompanhamento de linha em tabelas compartilhadas
Se o provedor de dados habilitou o acompanhamento de linha em uma tabela compartilhada, você pode consultar as colunas de metadados de acompanhamento de linha usando Scala Spark. Consulte Acompanhamento de linha no Databricks para obter uma lista de colunas disponíveis.
Você deve definir a opção responseFormat como delta.
spark.read.format("deltaSharing")
.option("responseFormat", "delta")
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.select("_metadata.row_id")
.show()
Apenas o formato de resposta delta é suportado para consultar colunas de acompanhamento de linha no cliente Spark. Conectores de dump não são suportados.
Pandas: Ler dados compartilhados
Siga estes passos para acessar dados compartilhados em pandas 0.25.3 ou acima.
Estas instruções assumem que você tem acesso ao arquivo de credencial que foi compartilhado pelo provedor de dados. Consulte Obter acesso no modelo de compartilhamento Databricks-para-Open.
Se você estiver usando pandas em um workspace do Databricks que esteja habilitado para o Unity Catalog e tiver usado a interface do provedor de importação para importar e compartilhar o provedor, as instruções desta seção não se aplicam a você. Você pode acessar tabelas compartilhadas da mesma forma que acessaria qualquer outra tabela registrada no Unity Catalog. Você não precisa instalar o conector Python delta-sharing nem fornecer o caminho para o arquivo de credenciais. Consulte Importar um provedor e ler dados compartilhados no Databricks.
Instale o Conector Python do OpenSharing
Para acessar metadados relacionados aos dados compartilhados, como a lista de tabelas compartilhadas com você, você deve instalar o conector Python delta-sharing. Para obter informações sobre as limitações do conector Python, consulte Limitações do conector Python do OpenSharing.
pip install delta-sharing
Listar tabelas compartilhadas usando pandas
Para listar as tabelas no compartilhamento, execute o seguinte, substituindo <profile-path>/config.share pelo local do arquivo de credencial.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
Se a saída estiver vazia ou não contiver as tabelas esperadas, contate o provedor de dados.
Acessar dados compartilhados usando pandas
Para acessar dados compartilhados em pandas usando Python, execute o seguinte, substituindo as variáveis da seguinte forma:
<profile-path>: o local do arquivo de credenciais.<share-name>: o valor deshare=para a tabela.<schema-name>: o valor deschema=para a tabela.<table-name>: o valor dename=para a tabela.
import delta_sharing
delta_sharing.load_as_pandas(f"<profile-path>#<share-name>.<schema-name>.<table-name>")
Acessar um feed de dados de alteração compartilhado usando pandas
Para acessar o feed de dados alterados para uma tabela compartilhada em pandas usando Python, execute o seguinte, substituindo as variáveis da seguinte forma. Um feed de dados alterados pode não estar disponível, dependendo se o provedor de dados compartilhou ou não o feed de dados alterados para a tabela.
<starting-version>: opcional. A versão inicial da query, inclusive.<ending-version>: opcional. A versão final da consulta, inclusiva.<starting-timestamp>: opcional. O carimbo de data/hora inicial da consulta. Isso é convertido para uma versão criada maior ou igual a este carimbo de data/hora.<ending-timestamp>: opcional. O carimbo de data/hora final da consulta. Isso é convertido para uma versão criada antes ou igual a este carimbo de data/hora.
import delta_sharing
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
Se a saída estiver vazia ou não contiver os dados esperados, entre em contato com o provedor de dados.
Power BI: Ler dados compartilhados
O conector Power BI OpenSharing permite que os usuários descubram, analisem e visualizem conjuntos de dados compartilhados com eles por meio do protocolo OpenSharing.
Requisitos
- Power BI Desktop 2.99.621.0 ouacima.
- Acesso ao arquivo de credenciais que foi compartilhado pelo provedor de dados. Consulte Obter acesso no modelo de compartilhamento Databricks-para-Open.
Conectar ao Databricks
Para conectar-se ao Databricks usando o conector OpenSharing, faça o seguinte:
- Abra o arquivo de credencial compartilhado com um editor de texto para recuperar a URL do endpoint e o token.
- Inicie o Power BI Desktop.
- No menu **Obter Dados**, procure por **OpenSharing**.
- Selecione o conector e clique em Conectar .
- Insira a URL do endpoint que você copiou do arquivo de credenciais no campo URL do Servidor OpenSharing .
- Opcionalmente, na **tab** **Opções Avançadas**, defina um **Limite de linha** para o número máximo de linhas que você pode baixar. Isso é definido como 1 milhão de linhas por default.
- Clique em OK .
- Para Autenticação , copie o token recuperado do arquivo de credenciais em Token do portador .
- Clique em Conectar .
Limitações do conector de Compartilhamento Aberto do Power BI
O Conector de Compartilhamento Aberto do Power BI apresenta as seguintes limitações:
- Os dados que o conector carrega devem caber na memória da sua máquina. Para gerenciar este requisito, o conector limita o número de linhas importadas ao **Limite de Linhas** que você definiu na tab Opções Avançadas no Power BI Desktop.
Tableau: Ler dados compartilhados
O conector Tableau OpenSharing permite descobrir, analisar e visualizar datasets que são compartilhados com você por meio do protocolo aberto OpenSharing.
Requisitos
- Tableau Desktop e Tableau Server 2024.1 ou acima
- Acesso ao arquivo de credenciais que foi compartilhado pelo provedor de dados. Consulte Obter acesso no modelo de compartilhamento Databricks-para-Open.
Conectar ao Databricks
Para conectar-se ao Databricks usando o conector OpenSharing, faça o seguinte:
- Acesse Tableau Exchange, siga as instruções para baixar o OpenSharing Connector e coloque-o em uma pasta de área de trabalho apropriada.
- Abra o Tableau Desktop.
- Na página **Conectores**, procure por “OpenSharing by Databricks”.
- Selecione Upload Share file e escolha o arquivo de credencial que foi compartilhado pelo provedor.
- Clique em **Obter Dados**.
- No Data Explorer, selecione a tabela.
- Opcionalmente, adicione filtros SQL ou limites de linha.
- Clique em **Obter Dados da Tabela**.
Limitações
O Conector Tableau OpenSharing apresenta as seguintes limitações:
- Os dados que o conector carrega devem caber na memória da sua máquina. Para gerenciar este requisito, o conector limita o número de linhas importadas ao limite de linha que você definiu no Tableau.
- Todas as colunas são retornadas como tipo
String. - O filtro SQL só funciona se o seu servidor de Compartilhamento aberto oferecer suporte a predicateHint.
- Vetores de exclusão não são suportados.
- Mapeamento de coluna não é compatível.
Limitações do conector Python do OpenSharing
Estas limitações são específicas para o conector Python OpenSharing:
- O conector Python do OpenSharing 1.1.0+ Suporta consultas de Snapshot em tabelas com mapeamento de coluna, mas as consultas CDF em tabelas com mapeamento de coluna não são suportadas.
- O conector Python do OpenSharing falha em consultas CDF com
use_delta_format=Truese o esquema foi alterado durante o intervalo de versão consultado.
Limitações da tabela de transmissão
É possível ler apenas o Snapshot atual de uma tabela de transmissão compartilhada. Os seguintes recursos não são compatíveis para tabelas de transmissão no compartilhamento Databricks-to-Open.
- Consultando os dados de história da tabela
- Consultando o feed de dados de alteração (CDF) da tabela.
- Usando a tabela como fonte para transmissão estruturada do Spark
Limitações da visualização materializada
Só é possível ler o instantâneo atual de uma view materializada compartilhada. O uso de uma view materializada como fonte para transmissão estructurada do Spark não é compatível no compartilhamento Databricks-para-Open.
Solicitar uma nova credencial
Se sua URL de ativação de credencial ou credencial baixada for perdida, corrompida ou comprometida, ou se sua credencial expirar sem que seu provedor envie uma nova, entre em contato com seu provedor para solicitar uma nova credencial.
Se for um destinatário Databricks que importou a credencial como um objeto de provedor no Unity Catalog, aplique a nova credencial usando a API REST Databricks. Consulte Girar credenciais para destinatários abertos.