Sparklyr
Databricks suporta Sparklyr em Notebook, Job e RStudio Desktop. Este artigo descreve como o senhor pode usar o site Sparklyr e fornece exemplos de scripts que podem ser executados. Para obter mais informações, consulte a interface do R para Apache Spark.
Requisitos
Databricks distribui a versão estável mais recente do Sparklyr a cada lançamento do Databricks Runtime. O senhor pode usar o Sparklyr no Databricks R Notebook ou dentro do RStudio Server hospedado no Databricks importando a versão instalada do Sparklyr.
No RStudio Desktop, o Databricks Connect permite que o senhor se conecte Sparklyr a partir de sua máquina local para Databricks clusterizar e executar o código Apache Spark. Consulte Usar Sparklyr e RStudio Desktop com Databricks Connect.
Conecte o site Sparklyr ao clustering Databricks
Para estabelecer uma conexão Sparklyr, o senhor pode usar "databricks" como o método de conexão em spark_connect().
Não são necessários parâmetros adicionais para spark_connect() nem é necessário chamar spark_install() porque o Spark já está instalado em um cluster Databricks.
# Calling spark_connect() requires the sparklyr package to be loaded first.
library(sparklyr)
# Create a sparklyr connection.
sc <- spark_connect(method = "databricks")
Barras de progresso e Spark UI com Sparklyr
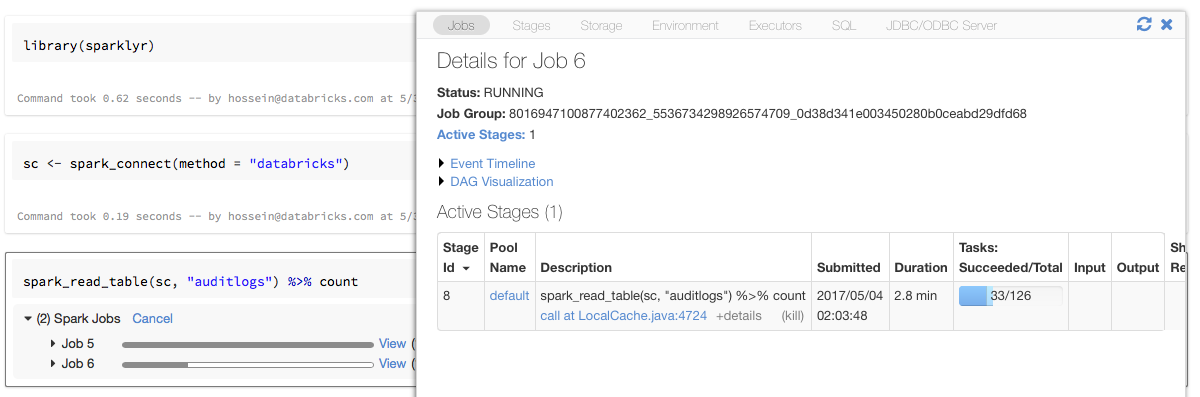
Se o senhor atribuir o objeto de conexão Sparklyr a uma variável denominada sc, como no exemplo acima, verá barras de progresso Spark no Notebook após cada comando que acionar o Spark Job.
Além disso, o senhor pode clicar no link ao lado da barra de progresso para view o Spark UI associado ao trabalho Spark fornecido.
Uso Sparklyr
Depois que o senhor instalar o Sparklyr e estabelecer a conexão, todos os outros Sparklyr API funcionarão normalmente. Consulte o Notebook de exemplo para ver alguns exemplos.
Sparklyr é normalmente usado junto com outros pacotes tidyverse, como o dplyr. A maioria desses pacotes está pré-instalada no site Databricks para sua conveniência. O senhor pode simplesmente importá-los e começar a usar a API.
Use Sparklyr e SparkR juntos
SparkR e Sparklyr podem ser usados juntos em um único Notebook ou Job. O senhor pode importar SparkR junto com Sparklyr e usar sua funcionalidade. No Databricks Notebook, a conexão SparkR é pré-configurada.
Algumas das funções do SparkR mascaram uma série de funções do dplyr:
> library(SparkR)
The following objects are masked from 'package:dplyr':
arrange, between, coalesce, collect, contains, count, cume_dist,
dense_rank, desc, distinct, explain, filter, first, group_by,
intersect, lag, last, lead, mutate, n, n_distinct, ntile,
percent_rank, rename, row_number, sample_frac, select, sql,
summarize, union
Se o SparkR for importado após a importação do dplyr, o senhor poderá fazer referência às funções no dplyr usando
para os nomes totalmente qualificados, por exemplo, dplyr::arrange().
Da mesma forma, se o senhor importar o dplyr depois do SparkR, as funções do SparkR serão mascaradas pelo dplyr.
Como alternativa, o senhor pode desconectar seletivamente um dos dois pacotes quando não precisar dele.
detach("package:dplyr")
Consulte também Comparando SparkR e Sparklyr.
Use Sparklyr no trabalho spark-submit
A tarefa Spark Submit está obsoleta e será removida. Somente clientes que atualmente usam spark-submit podem criar este tipo de tarefa. Como alternativa, você pode usar uma tarefa do Notebook que contém seu código R.
O senhor pode executar scripts que usam Sparklyr em Databricks como spark-submit Job, com pequenas modificações no código. Algumas das instruções acima não se aplicam ao uso do Sparklyr no spark-submit Job em Databricks. Em particular, o senhor deve fornecer o URL mestre do Spark para spark_connect. Por exemplo:
library(sparklyr)
sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>")
...
Recurso não suportado
Databricks não é compatível com os métodos Sparklyr, como spark_web() e spark_log(), que exigem um navegador local. No entanto, como o Spark UI está integrado ao Databricks, o senhor pode inspecionar facilmente o Spark Job e o logs.
Consulte o driver de computação e worker logs .
Notebook de exemplo: Sparklyr demonstration
Sparklyr Caderno de anotações
Para obter exemplos adicionais, consulte Trabalhar com DataFrames e tabelas no R.