Databricks SQL notas sobre a versão 2025
Os seguintes recursos e melhorias do Databricks SQL foram lançados em 2025.
Novembro de 2025
Databricks SQL version 2025.35 is rolling out in Current
November 20, 2025
Databricks SQL version 2025.35 is rolling out to the Current channel. See features in 2025.35.
Databricks SQL alerts are now in Public Preview
November 14, 2025
- Databricks SQL alerts: The latest version of Databricks SQL alerts, with a new editing experience, is now in Public Preview. See Databricks SQL alerts.
SQL Editor visualization fix
November 6, 2025
- Fixed tooltip display issue: Resolved an issue where tooltips were hidden behind the legend in Notebook and SQL Editor visualizations.
Outubro de 2025
Databricks SQL version 2025.35 is now available in Preview
October 30, 2025
Databricks SQL version 2025.35 is now available in the Preview channel. Review the following section to learn about new features, behavioral changes, and bug fixes.
EXECUTE IMMEDIATE using constant expressions
You can now pass constant expressions as the SQL string and as arguments to parameter markers in EXECUTE IMMEDIATE statements.
LIMIT ALL support for recursive CTEs
You can now use LIMIT ALL to remove the total size restriction on recursive common table expressions (CTEs).
st_dump function support
You can now use the st_dump function to get an array containing the single geometries of the input geometry. See st_dump function.
Polygon interior ring functions are now supported
You can now use the following functions to work with polygon interior rings:
st_numinteriorrings: Get the number of inner boundaries (rings) of a polygon. Seest_numinteriorringsfunction.st_interiorringn: Extract the n-th inner boundary of a polygon and return it as a linestring. Seest_interiorringnfunction.
Support MV/ST refresh information in DESCRIBE EXTENDED AS JSON
Databricks now generates a section for materialized view and streaming table refresh information in the DESCRIBE EXTENDED AS JSON output, including last refreshed time, refresh type, status, and schedule.
Add metadata column to DESCRIBE QUERY and DESCRIBE TABLE
Databricks now includes a metadata column in the output of DESCRIBE QUERY and DESCRIBE TABLE for semantic metadata.
For DESCRIBE QUERY, when describing a query with metric views, semantic metadata propagates through the query if dimensions are directly referenced and measures use the MEASURE() function.
For DESCRIBE TABLE, the metadata column appears only for metric views, not other table types.
Correct handling of null structs when dropping NullType columns
When writing to Delta tables, Databricks now correctly preserves null struct values when dropping NullType columns from the schema. Previously, null structs were incorrectly replaced with non-null struct values where all fields were set to null.
New alert editing experience
October 20, 2025
- New alert editing experience: Creating or editing an alert now opens in the new multi-tab editor, providing a unified editing workflow. See Databricks SQL alerts.
Visualizations fix
October 9, 2025
- Legend selection for aliased series names: Legend selection now works correctly for charts with aliased series names in SQL editor and notebooks.
Semantic metadata in metric views
October 2, 2025
You can now define semantic metadata in a metric view. Semantic metadata helps AI tools such as Genie Agents (formerly Genie Spaces) and AI/BI dashboards interpret and use your data more effectively.
To use semantic metadata, your metric view must use YAML specification version 1.1 or higher and run on Databricks Runtime 17.3 or above. The corresponding Databricks SQL version is 2025.30, available in the Preview channel for SQL warehouses.
See Agent metadata in metric views and Upgrade to YAML 1.1.
Setembro de 2025
Databricks SQL version 2025.30 is now available in Preview
September 25, 2025
Databricks SQL version 2025.30 is now available in the Preview channel. Review the following section to learn about new features, behavioral changes, and bug fixes.
UTF8 based collations now support LIKE operator
You can now use LIKE with columns that have one of the following collations enabled: UTF8_Binary, UTF8_Binary_RTRIM, UTF8_LCASE, UTF8_LCASE_RTRIM. See Collation.
ST_ExteriorRing function is now supported
You can now use the ST_ExteriorRing function to extract the outer boundary of a polygon and return it as a linestring. See st_exteriorring function.
Declare multiple session or local variables in a single DECLARE statement
You can now declare multiple session or local variables of the same type and default value in a single DECLARE statement. See DECLARE VARIABLE and BEGIN END compound statement.
Support TEMPORARY keyword for metric view creation
You can now use the TEMPORARY keyword when creating a metric view. Temporary metric views are visible only in the session that created them and are dropped when the session ends. See CREATE VIEW.
DESCRIBE CONNECTION shows environment settings for JDBC connections
Databricks now includes user-defined environment settings in the DESCRIBE CONNECTION output for JDBC connections that support custom drivers and run in isolation. Other connection types remain unchanged.
SQL syntax for Delta read options in streaming queries
You can now specify Delta read options for SQL-based streaming queries using the WITH clause. For example:
SELECT * FROM STREAM tbl WITH (SKIPCHANGECOMMITS=true, STARTINGVERSION=X);
Correct results for split with empty regex and positive limit
Databricks now returns correct results when using split function with an empty regex and a positive limit. Previously, the function incorrectly truncated the remaining string instead of including it in the last element.
Fix url_decode and try_url_decode error handling in Photon
In Photon, try_url_decode() and url_decode() with failOnError = false now return NULL for invalid URL-encoded strings instead of failing the query.
Agosto de 2025
Default warehouse setting is now available in Beta
August 28, 2025
Set a default warehouse that will be automatically selected in the compute selector across the SQL editor, AI/BI dashboards, Genie Agents (formerly Genie Spaces), Alerts, and Catalog Explorer. Individual users can override this setting by selecting a different warehouse before running a query. They can also define their own user-level default warehouse to apply across their sessions. See Set a default SQL warehouse for the workspace and Set a user-level default warehouse.
Databricks SQL version 2025.25 is rolling out in Current
August 21, 2025
Databricks SQL version 2025.25 is rolling out to the Current channel from August 20th, 2025 to August 28th, 2025. See features in 2025.25.
Databricks SQL version 2025.25 is now available in Preview
August 14, 2025
Databricks SQL version 2025.25 is now available in the Preview channel. Review the following section to learn about new features and behavioral changes.
Recursive common table expressions (rCTE) are generally available
Recursive common table expressions (rCTEs) are generally available. Navigate hierarchical data using a self-referencing CTE with UNION ALL to follow the recursive relationship.
Support for schema and catalog level default collation
You can now set a default collation for schemas and catalogs. This allows you to define a collation that applies to all objects created within the schema or catalog, ensuring consistent collation behavior across your data.
Support for Spatial SQL expressions and GEOMETRY and GEOGRAPHY data types
You can now store geospatial data in built-in GEOMETRY and GEOGRAPHY columns for improved performance of spatial queries. This release adds more than 80 new spatial SQL expressions, including functions for importing, exporting, measuring, constructing, editing, validating, transforming, and determining topological relationships with spatial joins. See ST geospatial functions, GEOGRAPHY type, and GEOMETRY type.
Support for schema and catalog level default collation
You can now set a default collation for schemas and catalogs. This allows you to define a collation that applies to all objects created within the schema or catalog, ensuring consistent collation behavior across your data.
Better handling of JSON options with VARIANT
The from_json and to_json functions now correctly apply JSON options when working with top-level VARIANT schemas. This ensures consistent behavior with other supported data types.
Support for TIMESTAMP WITHOUT TIME ZONE syntax
You can now specify TIMESTAMP WITHOUT TIME ZONE instead of TIMESTAMP_NTZ. This change improves compatibility with the SQL Standard.
Resolved subquery correlation issue
Databricks no longer incorrectly correlates semantically equal aggregate expressions between a subquery and its outer query. Previously, this could lead to incorrect query results.
Error thrown for invalid CHECK constraints
Databricks now throws an AnalysisException if a CHECK constraint expression cannot be resolved during constraint validation.
Stricter rules for stream-stream joins in append mode
Databricks now disallows streaming queries in append mode that use a stream-stream join followed by window aggregation, unless watermarks are defined on both sides. Queries without proper watermarks can produce non-final results, violating append mode guarantees.
New SQL editor is generally available
August 14, 2025
The new SQL editor is now generally available. The new SQL editor provides a unified authoring environment with support for multiple statement results, inline execution history, real-time collaboration, enhanced Databricks Assistant integration, and additional productivity features. See Write queries and explore data in the new SQL editor.
Fixed timeout handling for materialized views and streaming tables
August 14, 2025
New timeout behavior for materialized views and streaming tables created in Databricks SQL:
- Materialized views and streaming tables created after August 14, 2025 will have the warehouse timeout automatically applied.
- For materialized views and streaming tables created before August 14, 2025, run
CREATE OR REFRESHto synchronize the timeout setting with the timeout configuration of the warehouse. - All materialized views and streaming tables now have a default timeout of two days.
Julho de 2025
Preset date ranges for parameters in the SQL editor
July 31, 2025
In the new SQL editor, you can now choose from preset date ranges—such as This week, Last 30 days, or Last year when using timestamp, date, and date range parameters. These presets make it faster to apply common time filters without manually entering dates.
Jobs & Pipelines list now includes Databricks SQL pipelines
July 29, 2025
The Jobs & Pipelines list now includes pipelines for materialized views and streaming tables that were created with Databricks SQL.
Inline execution history in SQL editor
July 24, 2025
Inline execution history is now available in the new SQL editor, allowing you to quickly access past results without re-executing queries. Easily reference previous executions, navigate directly to past query profiles, or compare run times and statuses—all within the context of your current query.
Databricks SQL version 2025.20 is now available in Current
July 17, 2025
Databricks SQL version 2025.20 is rolling out in stages to the Current channel. For features and updates in this release, see 2025.20 features.
SQL editor updates
July 17, 2025
-
Improvements to named parameters: Date-range and multi-select parameters are now supported. For date range parameters, see Add a date range using
.minand.max. For multi-select parameters, see Pass multiple values as a string. -
Updated header layout in SQL editor: The run button and catalog picker have moved to the header, creating more vertical space for writing queries.
Git support for alerts
July 17, 2025
You can now use Databricks Git folders to track and manage changes to alerts. To track alerts with Git, place them in a Databricks Git folder. Newly cloned alerts only appear in the alerts list page or API after a user interacts with them. They have paused schedules and need to be explicitly resumed by users. See How Git integration works with alerts.
Databricks SQL version 2025.20 is now available in Preview
July 3, 2025
Databricks SQL version 2025.20 is now available in the Preview channel. Review the following section to learn about new features and behavioral changes.
Suporte a procedimentos SQL
Os scripts SQL agora podem ser encapsulados em um procedimento armazenado como um ativo reutilizável no Unity Catalog. O senhor pode criar um procedimento usando o comando CREATE PROCEDURE e, em seguida, chamá-lo usando o comando CALL.
Definir um agrupamento default para SQL Functions
O uso da nova cláusula DEFAULT COLLATION no comando CREATE FUNCTION comando define o agrupamento default usado para os parâmetros STRING, o tipo de retorno e os literais STRING no corpo da função.
Suporte para expressões de tabela comuns recursivas (RCTE)
Databricks agora oferece suporte à navegação de expressões de tabelas comuns recursivas (rCTEs) de uso de dados hierárquicos.
Use um CTE autorreferenciado com UNION ALL para acompanhar a relação recursiva.
Suporte ALL CATALOGS em SHOW SCHEMAS
A sintaxe SHOW SCHEMAS foi atualizada para aceitar a seguinte sintaxe:
SHOW SCHEMAS [ { FROM | IN } { catalog_name | ALL CATALOGS } ] [ [ LIKE ] pattern ]
Quando ALL CATALOGS é especificado em uma consulta SHOW, a execução percorre todos os catálogos ativos que suportam namespaces usando o gerenciador de catálogos (DSv2). Para cada catálogo, ele inclui os namespaces de nível superior.
Os atributos de saída e o esquema do comando foram modificados para adicionar uma coluna catalog indicando o catálogo do namespace correspondente. A nova coluna é adicionada ao final dos atributos de saída, como mostrado abaixo:
Saída anterior
| Namespace |
|------------------|
| test-namespace-1 |
| test-namespace-2 |
Nova saída
| Namespace | Catalog |
|------------------|----------------|
| test-namespace-1 | test-catalog-1 |
| test-namespace-2 | test-catalog-2 |
O Liquid clustering agora compacta vetores de deleção com mais eficiência
Delta As tabelas com o Liquid clustering agora aplicam alterações físicas de vetores de exclusão com mais eficiência quando o OPTIMIZE está em execução. Para obter mais detalhes, consulte Aplicar alterações nos arquivos de dados Parquet.
Permitir expressões não determinísticas nos valores das colunas UPDATE/INSERT para operações MERGE
O Databricks agora permite o uso de expressões não determinísticas em valores de coluna atualizados e inseridos das operações do site MERGE. No entanto, expressões não determinísticas nas condições das declarações MERGE não são suportadas.
Por exemplo, agora você pode gerar valores dinâmicos ou aleatórios para colunas:
MERGE INTO target USING source
ON target.key = source.key
WHEN MATCHED THEN UPDATE SET target.value = source.value + rand()
Isso pode ser útil para a privacidade dos dados, ofuscando os dados reais e preservando as propriedades dos dados (como valores médios ou outras colunas de cálculo).
Suporte à palavra-chave VAR para declarar e eliminar variáveis SQL
A sintaxe SQL para declarar e eliminar variáveis agora suporta a palavra-chave VAR, além de VARIABLE. Essa alteração unifica a sintaxe em todas as operações relacionadas a variáveis, o que melhora a consistência e reduz a confusão para os usuários que já usam VAR ao definir variáveis.
CREATE VIEW As cláusulas em nível de coluna agora geram erros quando a cláusula se aplica apenas à visualização materializada
CREATE VIEW comando que especifica uma cláusula em nível de coluna que só é válida para MATERIALIZED VIEWs agora gera um erro. As cláusulas afetadas para CREATE VIEW comando são as seguintes:
NOT NULL- Um tipo de dados especificado, como
FLOATouSTRING DEFAULTCOLUMN MASK
Junho de 2025
Databricks SQL Serverless engine upgrades
June 11, 2025
The following engine upgrades are now rolling out globally, with availability expanding to all regions over the coming weeks.
- Lower latency: Dashboards, ETL jobs, and mixed workloads now run faster, with up to 25% improvement. The upgrade is automatically applied to serverless SQL warehouses with no additional cost or configuration.
- Predictive Query Execution (PQE): PQE monitors tasks in real time and dynamically adjusts query execution to help avoid skew, spills, and unnecessary work.
- Photon vectorized shuffle: Keeps data in compact columnar format, sorts it within the CPU's high-speed cache, and processes multiple values simultaneously using vectorized instructions. This improves throughput for CPU-bound workloads such as large joins and wide aggregation.
User interface updates
June 5, 2025
- Query insights improvements: Visiting the Query History page now emits the
listHistoryQueriesevent. Opening a query profile now emits thegetHistoryQueryevent.
Maio de 2025
Metric views are in Public Preview
May 29, 2025
Unity Catalog metric views provide a centralized way to define and manage consistent, reusable, and governed core business metrics. They abstract complex business logic into a centralized definition, enabling organizations to define key performance indicators once and use them consistently across reporting tools like dashboards, Genie Agents (formerly Genie Spaces), and alerts. Use a SQL warehouse running on the Preview channel (2025.16) or other compute resource running Databricks Runtime 16.4 or above to work with metric views. See Unity Catalog metric views.
User interface updates
May 29, 2025
- New SQL editor improvements:
- New queries in Drafts folder: New queries are now created by default in the Drafts folder. When saved or renamed, they automatically move out of Drafts.
- Query snippets support: You can now create and reuse query snippets—predefined segments of SQL such as
JOINorCASEexpressions, with support for autocomplete and dynamic insertion points. Create snippets by choosing View > Query Snippets. - Audit log events: Audit log events are now emitted for actions taken in the new SQL editor.
- Filters impact on visualizations: Filters applied to result tables now also affect visualizations, enabling interactive exploration without modifying the SQL query.
New alert version in Beta
May 22, 2025
A new version of alerts is now in Beta. This version simplifies creating and managing alerts by consolidating query setup, conditions, schedules, and notification destinations into a single interface. You can still use legacy alerts alongside the new version. See Databricks SQL alerts.
User interface updates
May 22, 2025
- Tooltip formatting in charts: Tooltips in charts from the SQL editor and notebooks now follow the number formatting defined in the Data labels tab. See Visualizations in Databricks notebooks and SQL editor.
Databricks SQL version 2025.16 is now available
May 15, 2025
Databricks SQL version 2025.16 is now available in the Preview channel. Review the following section to learn about new features, behavioral changes, and bug fixes.
IDENTIFIER suporte agora disponível no Databricks SQL para operações de catálogo
Agora, o senhor pode usar a cláusula IDENTIFIER ao realizar as seguintes operações de catálogo:
CREATE CATALOGDROP CATALOGCOMMENT ON CATALOGALTER CATALOG
Essa nova sintaxe permite que o senhor especifique dinamicamente os nomes dos catálogos usando parâmetros definidos para essas operações, possibilitando um SQL fluxo de trabalho mais flexível e reutilizável. Como exemplo da sintaxe, considere CREATE CATALOG IDENTIFIER(:param), onde param é um parâmetro fornecido para especificar um nome de catálogo.
Para obter mais detalhes, consulte a cláusula IDENTIFIER.
Expressões agrupadas agora fornecem aliases transitórios gerados automaticamente
Os aliases gerados automaticamente para expressões agrupadas agora sempre incorporarão de forma determinística as informações do site COLLATE. Os aliases gerados automaticamente são transitórios (instáveis) e não devem ser usados como base. Em vez disso, como melhor prática, use expression AS alias de forma consistente e explícita.
UNION/EXCEPT/INTERSECT dentro de um view e EXECUTE IMMEDIATE agora retornam resultados corretos
As consultas de definições temporárias e persistentes do site view com colunas de nível superior UNION/EXCEPT/INTERSECT e sem aliases anteriormente retornavam resultados incorretos porque as palavras-chave UNION/EXCEPT/INTERSECTeram consideradas aliases. Agora, essas consultas executarão corretamente todo o conjunto de operações.
EXECUTE IMMEDIATE ... INTO com um nível superior UNION/EXCEPT/INTERSECT e colunas sem aliases também escreveu um resultado incorreto de um conjunto de operações na variável especificada devido ao fato de o analisador interpretar essas palavras-chave como aliases. Da mesma forma, as consultas SQL com texto residual inválido também foram permitidas. As operações de configuração nesses casos agora gravam um resultado correto na variável especificada ou falham no caso de texto SQL inválido.
Novas funções listagg e string_agg
Agora você pode usar as funções listagg ou string_agg para agregar valores STRING e BINARY em um grupo. Consulte string_agg para obter mais detalhes.
Correção para agrupamento em literais inteiros com aliases quebrados para determinadas operações
O agrupamento de expressões em um literal de número inteiro com alias era anteriormente interrompido para determinadas operações, como MERGE INTO. Por exemplo, essa expressão retornaria GROUP_BY_POS_OUT_OF_RANGE porque o valor (val) seria substituído por 202001:
merge into t
using
(select 202001 as val, count(current_date) as total_count group by val) on 1=1
when not matched then insert (id, name) values (val, total_count)
Isso foi corrigido. Para atenuar o problema em suas consultas existentes, verifique se as constantes que você está usando não são iguais à posição da coluna que deve estar nas expressões de agrupamento.
Ativar o sinalizador para não permitir a desativação da materialização da fonte para as operações do site MERGE
Anteriormente, os usuários podiam desativar a materialização da fonte em MERGE definindo merge.materializeSource como none. Com o novo sinalizador ativado, isso será proibido e causará um erro. A Databricks planeja ativar o sinalizador apenas para clientes que não usaram esse sinalizador de configuração antes, portanto, nenhum cliente deve notar qualquer alteração no comportamento.
Abril de 2025
Databricks SQL version 2025.15 is now available
April 10, 2025
Databricks SQL version 2025.15 is now available in the Preview channel. Review the following section to learn about new features, behavioral changes, and bug fixes.
Edite várias colunas usando ALTER TABLE
Agora você pode alterar várias colunas em uma única instrução ALTER TABLE. Consulte ALTER TABLE ... COLUMN.
Delta o downgrade do protocolo da tabela é GA com proteção de ponto de verificação
DROP FEATURE está geralmente disponível para remover o recurso da tabela Delta Lake e fazer o downgrade do protocolo da tabela. Em default, o DROP FEATURE agora cria pontos de verificação protegidos para uma experiência de downgrade mais otimizada e simplificada que não exige tempo de espera ou truncamento de histórico. Consulte Drop a Delta Lake table recurso e downgrade table protocol.
Escreva scripts SQL procedimentais com base no ANSI SQL/PSM (Public Preview)
Agora, o senhor pode usar recursos de script baseados em ANSI SQL/PSM para escrever lógica processual com SQL, incluindo instruções condicionais, loops, variáveis locais e tratamento de exceções. Consulte Script SQL.
Tabela e view level default collation
Agora o senhor pode especificar um agrupamento default para tabelas e visualizações. Isso simplifica a criação de tabelas e exibições em que todas ou a maioria das colunas compartilham o mesmo agrupamento. Veja Collation.
Novas funções H3
As seguintes funções H3 foram adicionadas:
Legacy dashboards support has ended
April 10, 2025
Official support for legacy dashboards has ended. You can no longer create or clone legacy dashboards using the UI or API. Databricks continues to address critical security issues and service outages, but recommends using AI/BI dashboards for all new development. To learn more about AI/BI dashboards, see Dashboards. For help migrating, see Clone a legacy dashboard to an AI/BI dashboard and Use dashboard APIs to create and manage dashboards.
Custom autoformatting options for SQL queries
April 3, 2025
Customize autoformatting options for all of your SQL queries. See Custom format SQL statements.
Boxplot visualizations issue fixed
April 3, 2025
Fixed an issue where Databricks SQL boxplot visualizations with only a categorical x-axis did not display categories and bars correctly. Visualizations now render as expected.
CAN VIEW permission for SQL warehouses is in Public Preview
April 3, 2025
CAN VIEW permission is now in Public Preview. This permission allows users to monitor SQL warehouses, including the associated query history and query profiles. Users with CAN VIEW permission cannot run queries on the SQL warehouse without being granted additional permissions. See SQL warehouse ACLs.
Março de 2025
User interface updates
March 27, 2025
- Query profiles updated for improved usability: Query profiles have been updated to improve usability and help you quickly access key insights. See Query profile.
User interface updates
March 20, 2025
- Transfer SQL warehouse ownership to service principal: You can now use the UI to transfer warehouse ownership to a service principal.
User interface updates
March 6, 2025
- Dual-axis charts now support zoom: You can now click and drag to zoom in on dual-axis charts.
- Pin table columns: You can now pin table columns to the left side of the table display. Columns stay in view as you scroll right on the table. See Column settings.
- Fixed an issue with combo charts: Resolved misalignment between x-axis labels and bars when using a temporal field on the x-axis.
Fevereiro de 2025
Databricks SQL version 2025.10 is now available
February 21, 2025
Databricks SQL version 2025.10 is now available in the Preview channel. Review the following section to learn about new features, behavioral changes, and bug fixes.
Em Delta Sharing, a tabela história é ativada pelo default
Os compartilhamentos criados usando o comando SQL ALTER SHARE <share> ADD TABLE <table> agora têm o histórico de compartilhamento (WITH HISTORY) ativado por default. Consulte ALTER SHARE.
As instruções SQL de credenciais retornam um erro quando há uma incompatibilidade de tipo de credencial
Com esta versão, se o tipo de credencial especificado em uma declaração de gerenciamento de credenciais SQL não corresponder ao tipo do argumento da credencial, será retornado um erro e a declaração não será executada. Por exemplo, para a instrução DROP STORAGE CREDENTIAL 'credential-name', se credential-name não for uma credencial de armazenamento, a instrução falhará com um erro.
Essa alteração é feita para ajudar a evitar erros do usuário. Anteriormente, essas declarações eram executadas com êxito, mesmo que fosse passada uma credencial que não correspondesse ao tipo de credencial especificado. Por exemplo, a declaração a seguir eliminaria storage-credential: DROP SERVICE CREDENTIAL storage-credential com sucesso.
Essa alteração afeta as seguintes declarações:
- DROP CREDENTIAL
- ALTER CREDENTIAL
- DESCRIBE CREDENTIAL
- CONCEDER... EM... CREDENCIAL
- REVOGAR... EM... CREDENCIAL
- SHOW GRANTS EM...CREDENCIAL
Use o timestampdiff & timestampadd nas expressões de coluna geradas
As expressões de coluna geradas pelo Delta Lake agora suportam as funções timestampdiff e timestampadd.
Suporte à sintaxe do pipeline SQL
Agora o senhor pode compor o pipelineSQL. Um pipeline SQL estrutura uma consulta padrão, como SELECT c2 FROM T WHERE c1 = 5, em uma sequência passo a passo, conforme mostrado no exemplo a seguir:
FROM T
|> SELECT c2
|> WHERE c1 = 5
Para saber mais sobre a sintaxe compatível com o pipeline SQL, consulte Sintaxe do pipelineSQL.
Para obter informações sobre essa extensão entre indústrias, consulte SQL Has Problems. We Can Fix Them: Pipe Syntax In SQL (por Google Research).
Faça uma solicitação HTTP usando a função http_request
Agora você pode criar conexões HTTP e, por meio delas, fazer solicitações HTTP usando a função http_request.
A atualização para DESCRIBE TABLE retorna metadados como JSON estruturado
Agora o senhor pode usar o comando DESCRIBE TABLE AS JSON para retornar os metadados da tabela como um documento JSON. O resultado do JSON é mais estruturado do que o relatório default legível por humanos e pode ser usado para interpretar o esquema de uma tabela de forma programática. Para saber mais, consulte DESCRIBE TABLE AS JSON.
Agrupamentos insensíveis em branco à direita
Foi adicionado suporte para agrupamentos insensíveis em branco à direita. Por exemplo, esses agrupamentos tratam 'Hello' e 'Hello ' como iguais. Para saber mais, consulte Agrupamento RTRIM.
Processamento incremental aprimorado de clones
Esta versão inclui uma correção para um caso extremo em que um CLONE incremental pode copiar novamente arquivos já copiados de uma tabela de origem para uma tabela de destino. Consulte Clonar uma tabela em Databricks.
User interface updates
February 13, 2025
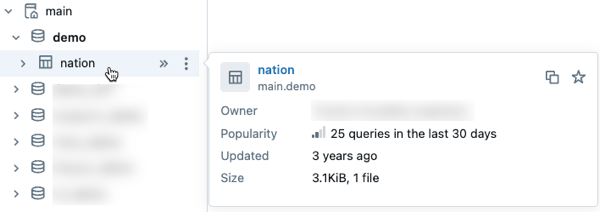
- Preview Unity Catalog metadata in data discovery: Preview metadata for Unity Catalog assets by hovering over an asset in the schema browser. This capability is available in Catalog Explorer and other interfaces where you use the schema browser, such as AI/BI dashboards and the SQL editor.
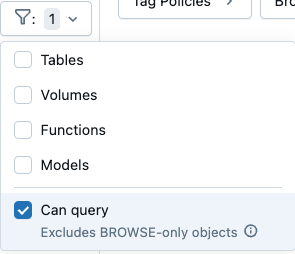
- Filter to find data assets you can query: Filter settings in Catalog Explorer's schema browser now includes a Can query checkbox. Selecting this option excludes objects that you can view but not query.
Janeiro de 2025
User interface updates
January 30, 2025
-
Completed query count chart for SQL warehouses (Public Preview): A new Completed query count chart is now available on the SQL warehouse monitoring UI. This chart shows the number of queries finished in a time window, including canceled and failed queries. The chart can be used with the other charts and the Query History table to assess and troubleshoot the performance of the warehouse. The query is allocated in the time window it is completed. Counts are averaged per minute. For more information, see Monitor a SQL warehouse.
-
Expanded data display in SQL editor charts: Visualizations created in the SQL editor now support up to 15,000 rows of data.
Databricks SQL version 2024.50 is now available
January 23, 2025
Databricks SQL version 2024.50 is now available in the Preview channel. Review the following section to learn about new features, behavioral changes, and bug fixes.
O tipo de dados VARIANT não pode mais ser usado com operações que exigem comparações
Você não pode usar as cláusulas ou operadores a seguir em consultas que incluem um tipo de dados VARIANT:
DISTINCTINTERSECTEXCEPTUNIONDISTRIBUTE BY
Essas operações realizam comparações, e as comparações que usam o tipo de dados VARIANT produzem resultados indefinidos e não são compatíveis com o Databricks. Se o senhor usar o tipo VARIANT em suas cargas de trabalho ou tabelas da Databricks, a Databricks recomenda as seguintes alterações:
- Atualize consultas ou expressões para converter explicitamente valores
VARIANTem tipos de dados que não sejamVARIANT. - Se o senhor tiver campos que devam ser usados com qualquer uma das operações acima, extraia esses campos do tipo de dados
VARIANTe armazene-os usando tipos de dados nãoVARIANT.
Para saber mais, consulte Consultar dados de variantes.
Suporte para parametrizar a cláusula USE CATALOG with IDENTIFIER
A cláusula IDENTIFIER é compatível com o comando USE CATALOG. Com esse suporte, o senhor pode parametrizar o catálogo atual com base em uma variável de cadeia de caracteres ou marcador de parâmetro.
COMMENT ON COLUMN suporte para tabelas e visualizações
A declaração COMMENT ON suporta a alteração de comentários para view e colunas de tabela.
Novas funções SQL
As seguintes novas funções integradas do SQL estão disponíveis:
- dayname (expr) retorna a sigla em inglês de três letras para o dia da semana para a data especificada.
- uniform (expr1, expr2 [, seed]) retorna um valor aleatório com valores independentes e distribuídos de forma idêntica dentro do intervalo de números especificado.
- randstr(length) retorna uma cadeia aleatória de
lengthcaracteres alfanuméricos.
Invocação de parâmetros nomeados para mais funções
As funções a seguir oferecem suporte à invocação de parâmetros nomeados:
Os tipos aninhados agora aceitam adequadamente as restrições NULL
Esta versão corrige um bug que afeta algumas colunas geradas pelo Delta de tipos aninhados, por exemplo, STRUCT. Às vezes, essas colunas rejeitavam incorretamente expressões com base nas restrições NULL ou NOT NULL dos campos aninhados. Isso foi corrigido.
SQL editor user interface updates
January 15, 2025
The new SQL editor (Public Preview) includes the following user interface improvements:
- Enhanced download experience: Query outputs are automatically named after the query when downloaded.
- Keyboard shortcuts for font sizing: Use
Alt +andAlt -(Windows/Linux) orOpt +andOpt -(macOS) to quickly adjust font size in the SQL editor. - User mentions in comments: Tag specific users with
@in comments to send them email notifications. - Faster tab navigation: Tab switching is now up to 80% faster for loaded tabs and 62% faster for unloaded tabs.
- Streamlined warehouse selection: SQL Warehouse size information is displayed directly in the compute selector for easier selection.
- Parameter editing shortcuts: Use
Ctrl + Enter(Windows/Linux) orCmd + Enter(macOS) to execute queries while editing parameter values. - Enhanced version control: Query results are preserved in version history for better collaboration.
Chart visualization updates
January 15, 2025
The new chart system with improved performance, enhanced color schemes, and faster interactivity is now generally available. See Visualizations in Databricks notebooks and SQL editor and Notebook and SQL editor visualization types.