Databricks AI Search
Databricks AI Search (formerly Databricks Vector Search) is a search solution that is built into the Databricks Data Intelligence Platform and integrated with its governance and productivity tools. It powers retrieval for generative AI applications such as RAG systems, recommender systems, and image and video recognition by finding the embeddings most similar to a query.
Vector search is a type of search optimized for retrieving embeddings. Embeddings are mathematical representations of the semantic content of data, typically text or image data. Embeddings are generated by a large language model and are a key component of many generative AI applications that depend on finding documents or images that are similar to each other.
With Databricks AI Search, you create an AI Search index from a Delta table. The index includes embedded data with metadata. You can then query the index using a REST API to identify the most similar vectors and return the associated documents. You can structure the index to automatically sync when the underlying Delta table is updated.
AI Search supports the following:
- Hybrid keyword-similarity search.
- Full-text keyword search (Beta) on any endpoint, or dedicated full-text indexes (Beta) on storage-optimized endpoints.
- Filtering.
- Reranking.
- Access control lists (ACLs) to manage AI Search endpoints.
- Sync only selected columns.
- Save and sync generated embeddings.
How does AI Search work?
AI Search uses the Hierarchical Navigable Small World (HNSW) algorithm for its approximate nearest neighbor (ANN) searches and the L2 distance metric to measure embedding vector similarity. If you want to use cosine similarity you need to normalize your datapoint embeddings before feeding them into the vector search algorithm. When the data points are normalized, the ranking produced by L2 distance is the same as the ranking produced by cosine similarity.
AI Search also supports hybrid keyword-similarity search, which combines vector-based embedding search with traditional keyword-based search techniques. This approach matches exact words in the query while also using a vector-based similarity search to capture the semantic relationships and context of the query.
By integrating these two techniques, hybrid keyword-similarity search retrieves documents that contain not only the exact keywords but also those that are conceptually similar, providing more comprehensive and relevant search results. This method is particularly useful in RAG applications where source data has unique keywords such as SKUs or identifiers that are not well suited to pure similarity search.
For details about the API, see the Python SDK reference and Query an AI Search index.
Similarity search calculation
The similarity search calculation uses the following formula:

where dist is the Euclidean distance between the query q and the index entry x:

Keyword search algorithm
Relevance scores are calculated using Okapi BM25. All text or string columns are searched, including the source text embedding and metadata columns in text or string format. The tokenization function splits at word boundaries, removes punctuation, and converts all text to lowercase.
How similarity search and keyword search are combined
The similarity search and keyword search results are combined using the Reciprocal Rank Fusion (RRF) function.
RRF first rescores each document from each method using the scores:


rrf_param controls the relative importance of higher-ranked and lower-ranked documents. Based on the literature, rrf_param is set to 60.
Scores are normalized so that the highest possible score is 1 using the following normalization factor:

The final score for each document is calculated as follows:

The documents with the highest final scores are returned.
Options for providing vector embeddings
To create an AI Search index in Databricks, you must first decide how to provide vector embeddings. Databricks supports three options.
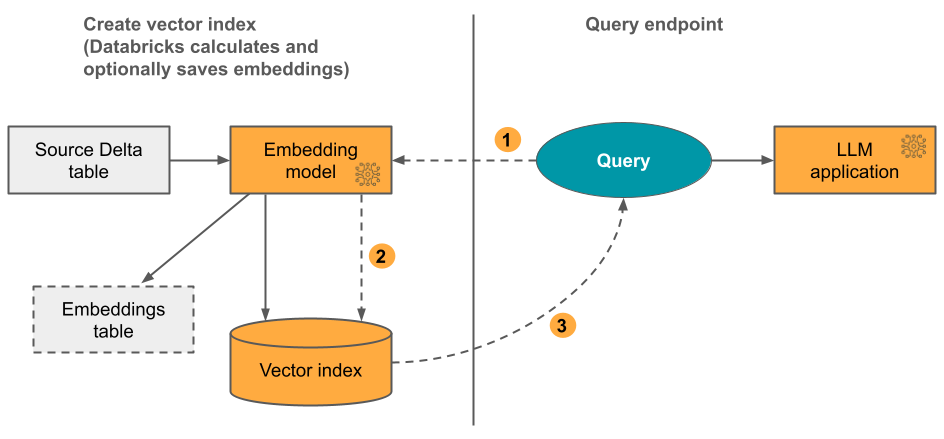
Option 1: Delta Sync Index with embeddings computed by Databricks
With this option, you provide a source Delta table that contains data in text format. Databricks calculates the embeddings, using a model that you specify, and optionally saves the embeddings to a table in Unity Catalog. As the Delta table is updated, the index stays synced with the Delta table.
The following diagram illustrates the process:
- Calculate query embeddings. Query can include metadata filters.
- Perform similarity search to identify most relevant documents.
- Return the most relevant documents and append them to the query.
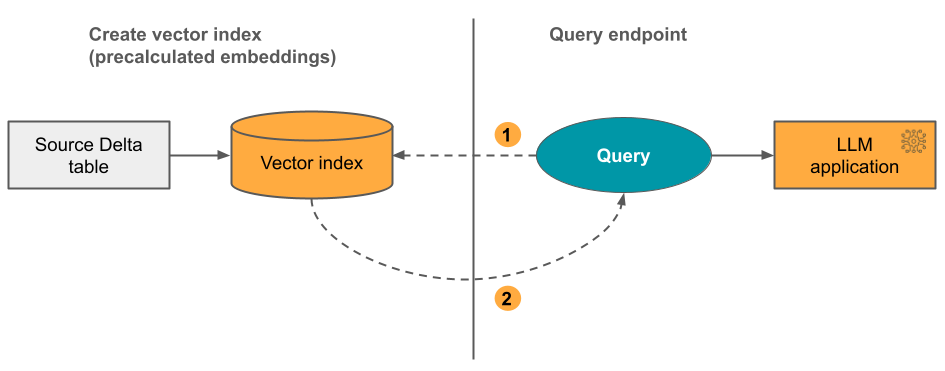
Option 2: Delta Sync Index with self-managed embeddings
With this option, you provide a source Delta table that contains pre-calculated embeddings. As the Delta table is updated, the index stays synced with the Delta table.
It is not possible to convert a self-managed embedding index to a Databricks-managed index. If you later decide to use managed embeddings, you must create a new index and recompute embeddings.
The following diagram illustrates the process:
- Query consists of embeddings and can include metadata filters.
- Perform similarity search to identify most relevant documents. Return the most relevant documents and append them to the query.
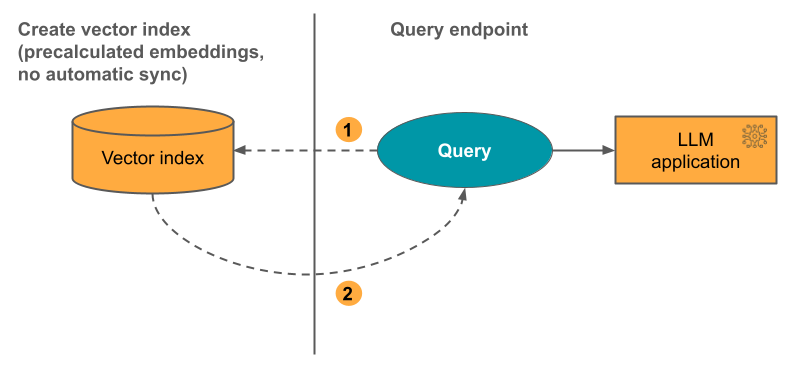
Option 3: Direct Vector Access Index
With this option, you must manually update the index using the REST API when the embeddings table changes.
The following diagram illustrates the process:
Option 4: Full-text search index on storage-optimized endpoints (Beta)
With this option, you create a Delta Sync Index on a storage-optimized endpoint without any embedding columns. The index supports keyword-based full-text search using BM25 scoring, without requiring vector embeddings. This is useful for searching exact terms, identifiers, or keywords in text data.
You can also use query_type="FULL_TEXT" to perform keyword searches on existing AI Search indexes on both standard and storage-optimized endpoints. This option is for creating a dedicated index that contains no embeddings at all.
Dedicated full-text search indexes are only available on storage-optimized endpoints and require triggered sync mode. See Create a full-text search index (Beta) for instructions.
Endpoint options
AI Search provides the following options so you can select the endpoint configuration that meets the needs of your application.
High QPS is available for standard endpoints only.
- Standard endpoints have a capacity of 320 million vectors at dimension 768.
- With standard endpoints, you can use high QPS to support high sustained throughput. See Scale AI Search endpoint throughput with high QPS.
- Storage-optimized endpoints have a larger capacity (over one billion vectors at dimension 768) and provide 10-20x faster indexing. Queries on storage-optimized endpoints have a slightly increased latency of about 250msec. Pricing for this option is optimized for the larger number of vectors. For pricing details, see the AI Search pricing page. For information on managing AI Search costs, see AI Search cost management guide.
You specify the endpoint type when you create the endpoint.
See also Storage-optimized endpoints limitations.
How to set up AI Search
To use AI Search, you must create the following:
-
An AI Search endpoint. This endpoint serves the AI Search index. You can query and update the endpoint using the REST API or the SDK. See Create an AI Search endpoint for instructions.
Endpoints scale up automatically to support the size of the index or the number of concurrent requests. Endpoints scale down automatically when an index is deleted.
-
An AI Search index. The AI Search index is created from a Delta table and is optimized to provide real-time approximate nearest neighbor (ANN) searches. The goal of the search is to identify documents that are similar to the query. AI Search indexes appear in and are governed by Unity Catalog. See Create an AI Search index for instructions.
In addition, if you choose to have Databricks compute the embeddings, you can use a pre-configured Foundation Model APIs endpoint or create a model serving endpoint to serve the embedding model of your choice. See Pay-per-token Foundation Model APIs or Create foundation model serving endpoints for instructions.
To query the model serving endpoint, you use either the REST API or the Python SDK. Your query can define filters based on any column in the Delta table. For details, see Use filters on queries, the API reference, or the Python SDK reference.
Requirements
- Unity Catalog enabled workspace.
- Serverless compute enabled. For instructions, see Connect to serverless compute.
- For standard endpoints, the source table must have Change Data Feed enabled. See Use change data feed on Databricks.
- To create an AI Search index, you must have CREATE TABLE privileges on the catalog schema where the index will be created.
Permission to create and manage AI Search endpoints is configured using access control lists. See AI Search endpoint ACLs.
Data protection and authentication
Databricks implements the following security controls to protect your data:
- Every customer request to AI Search is logically isolated, authenticated, and authorized.
- AI Search encrypts all data at rest (AES-256) and in transit (TLS 1.2+).
AI Search supports two modes of authentication, service principals and personal access tokens (PATs). For production applications, Databricks recommends that you use service principals, which can have a per-query performance up to 100 msec faster relative to personal access tokens.
-
Service principal token. An admin can generate a service principal token and pass it to the SDK or API. See use service principals. For production use cases, Databricks recommends using a service principal token.
Python# Pass in a service principal
vsc = AISearchClient(workspace_url="...",
service_principal_client_id="...",
service_principal_client_secret="..."
) -
Personal access token. You can use a personal access token to authenticate with AI Search. See personal access authentication token. If you use the SDK in a notebook environment, the SDK automatically generates a PAT token for authentication.
Python# Pass in the PAT token
client = AISearchClient(workspace_url="...", personal_access_token="...")
Customer Managed Keys (CMK) are supported on endpoints created on or after May 8, 2024.
Monitor usage and costs
For information about monitoring usage and costs associated with AI Search indexes and endpoints, see AI Search cost management guide.
You can also query usage by usage policy. See AI Search usage policies.
Resource and data size limits
The following table summarizes resource and data size limits for AI Search endpoints and indexes:
Resource | Granularity | Limit |
|---|---|---|
AI Search endpoints | Per workspace | 500 |
Embeddings (Delta Sync index) | Per standard endpoint | ~ 320,000,000 at 768 embedding dimension ~ 160,000,000 at 1536 embedding dimension ~ 80,000,000 at 3072 embedding dimension (scales approximately linearly) |
Embeddings (Direct Vector Access index) | Per standard endpoint | ~ 2,000,000 at 768 embedding dimension |
Embeddings (storage-optimized endpoint) | Per storage-optimized endpoint | ~ 1,000,000,000 at 768 embedding dimension |
Embedding dimension | Per index | 4096 |
Indexes | Per endpoint | 50 |
Columns | Per index | 50 |
Columns | Supported types: Bytes, short, integer, long, float, double, boolean, string, timestamp, date, array | |
Metadata fields | Per index | 50 |
Index name | Per index | 128 characters |
The following limits apply to the creation and update of AI Search indexes:
Resource | Granularity | Limit |
|---|---|---|
Row size for Delta Sync Index | Per index | 100KB |
Embedding source column size for Delta Sync index | Per Index | 32764 bytes |
Bulk upsert request size limit for Direct Vector index | Per Index | 10MB |
Bulk delete request size limit for Direct Vector index | Per Index | 10MB |
The following limits apply to the query API.
Resource | Granularity | Limit |
|---|---|---|
Query text length | Per query | 32764 characters |
Tokens when using hybrid search | Per query | 1024 words or 2-byte characters |
Filter conditions | Per filter clause | 1024 elements |
Maximum number of results returned (approximate nearest neighbor search) | Per query | 10,000 |
Maximum number of results returned (hybrid keyword-similarity search) | Per query | 200 |
Maximum number of results returned (full-text search) | Per query | 200 |
Response size | Per query | 10MB |
Limitations
- The column name
_idis reserved. If your source table has a column named_id, rename it before creating an AI Search index. - Row and column level permissions are not supported. However, you can implement your own application level ACLs using the filter API.
- You cannot clone an index into a different workspace. You can make cross-workspace requests using the Databricks SDK or REST API.
- Index capacity is provisioned based on the source table size at index creation time. Starting with a small source table limits how much the index can grow and can result in capacity-exhausted errors, so size the source table to match your expected data volume before creating the index.
Storage-optimized endpoints limitations
The limitations in this section apply only to storage-optimized endpoints.
- Continuous sync mode is not supported.
- Columns to sync is not supported.
- Embedding dimension must be divisible by 16.
- Incremental update is partially supported. Every sync must rebuild portions of the AI Search index.
- For managed indexes, any embeddings previously computed are reused if the source row has not changed.
- You should anticipate a significant end-to-end reduction in time required for a sync compared to the standard endpoints. Datasets with 1 billion embeddings should complete a sync in under 8 hours. Smaller datasets will take less time to sync.
- FedRAMP compliant workspaces are not supported.
- Customer-managed keys (CMK) are not supported.
- To use a custom embedding model for a managed Delta Sync index, the AI Query for Custom Models and External Models preview must be enabled. See Manage Databricks previews to learn how to enable previews.
- Storage-optimized endpoints support up to 1 billion embeddings of vectors of 768 dimensions. If you have a larger scale use case, reach out to your account team.