Tutorial: Import and visualize CSV data from a notebook
This tutorial walks you through using a Databricks notebook to import data from a CSV file containing baby name data from health.data.ny.gov into your Unity Catalog volume using Python, Scala, and R. You also learn to modify a column name, visualize the data, and save to a table.
Requirements
To complete the tasks in this article, you must meet the following requirements:
- Your workspace must have Unity Catalog enabled. For information on getting started with Unity Catalog, see Get started with Unity Catalog.
- You must have the
WRITE VOLUMEprivilege on a volume, theUSE SCHEMAprivilege on the parent schema, and theUSE CATALOGprivilege on the parent catalog. - You must have permission to use an existing compute resource or create a new compute resource. See Compute or see your Databricks administrator.
For a completed notebook for this article, see Import and visualize data notebooks.
Step 1: Create a new notebook
To create a notebook in your workspace, click ![]() New in the sidebar, and then click Notebook. A blank notebook opens in the workspace.
New in the sidebar, and then click Notebook. A blank notebook opens in the workspace.
To learn more about creating and managing notebooks, see Manage notebooks.
Step 2: Define variables
In this step, you define variables for use in the example notebook you create in this article.
-
Copy and paste the following code into the new empty notebook cell. Replace
<catalog-name>,<schema-name>, and<volume-name>with the catalog, schema, and volume names for a Unity Catalog volume. Optionally replace thetable_namevalue with a table name of your choice. You will save the baby name data into this table later in this article. -
Press
Shift+Enterto run the cell and create a new blank cell.- Python
- Scala
- R
Pythoncatalog = "<catalog_name>"
schema = "<schema_name>"
volume = "<volume_name>"
download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv"
file_name = "baby_names.csv"
table_name = "baby_names"
path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume
path_table = catalog + "." + schema
print(path_table) # Show the complete path
print(path_volume) # Show the complete pathScalaval catalog = "<catalog_name>"
val schema = "<schema_name>"
val volume = "<volume_name>"
val downloadUrl = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv"
val fileName = "baby_names.csv"
val tableName = "baby_names"
val pathVolume = s"/Volumes/${catalog}/${schema}/${volume}"
val pathTable = s"${catalog}.${schema}"
print(pathVolume) // Show the complete path
print(pathTable) // Show the complete pathRcatalog <- "<catalog_name>"
schema <- "<schema_name>"
volume <- "<volume_name>"
download_url <- "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv"
file_name <- "baby_names.csv"
table_name <- "baby_names"
path_volume <- paste("/Volumes/", catalog, "/", schema, "/", volume, sep = "")
path_table <- paste(catalog, ".", schema, sep = "")
print(path_volume) # Show the complete path
print(path_table) # Show the complete path
Step 3: Import CSV file
In this step, you import a CSV file containing baby name data from health.data.ny.gov into your Unity Catalog volume.
-
Copy and paste the following code into the new empty notebook cell. This code copies the
rows.csvfile from health.data.ny.gov into your Unity Catalog volume using the Databricks dbutuils command. -
Press
Shift+Enterto run the cell and then move to the next cell.- Python
- Scala
- R
Pythondbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")Scaladbutils.fs.cp(downloadUrl, s"${pathVolume}/${fileName}")Rdbutils.fs.cp(download_url, paste(path_volume, "/", file_name, sep = ""))
Step 4: Load CSV data into a DataFrame
In this step, you create a DataFrame named df from the CSV file that you previously loaded into your Unity Catalog volume by using the spark.read.csv method.
-
Copy and paste the following code into the new empty notebook cell. This code loads baby name data into DataFrame
dffrom the CSV file. -
Press
Shift+Enterto run the cell and then move to the next cell.- Python
- Scala
- R
Pythondf = spark.read.csv(f"{path_volume}/{file_name}",
header=True,
inferSchema=True,
sep=",")Scalaval df = spark.read
.option("header", "true")
.option("inferSchema", "true")
.option("delimiter", ",")
.csv(s"${pathVolume}/${fileName}")R# Load the SparkR package that is already preinstalled on the cluster.
library(SparkR)
df <- read.df(paste(path_volume, "/", file_name, sep=""),
source="csv",
header = TRUE,
inferSchema = TRUE,
delimiter = ",")
You can load data from many supported file formats.
Step 5: Visualize data from notebook
In this step, you use the display() method to display the contents of the DataFrame in a table in the notebook, and then visualize the data in a word cloud chart in the notebook.
-
Copy and paste the following code into the new empty notebook cell, and then click Run cell to display the data in a table.
- Python
- Scala
- R
Pythondisplay(df)Scaladisplay(df)Rdisplay(df) -
Review the results in the table.
-
Next to the Table tab, click + and then click Visualization.
-
In the visualization editor, click Visualization Type, and verify that Word cloud is selected.
-
In the Words column, verify that
First Nameis selected. -
In Frequencies limit, click
35.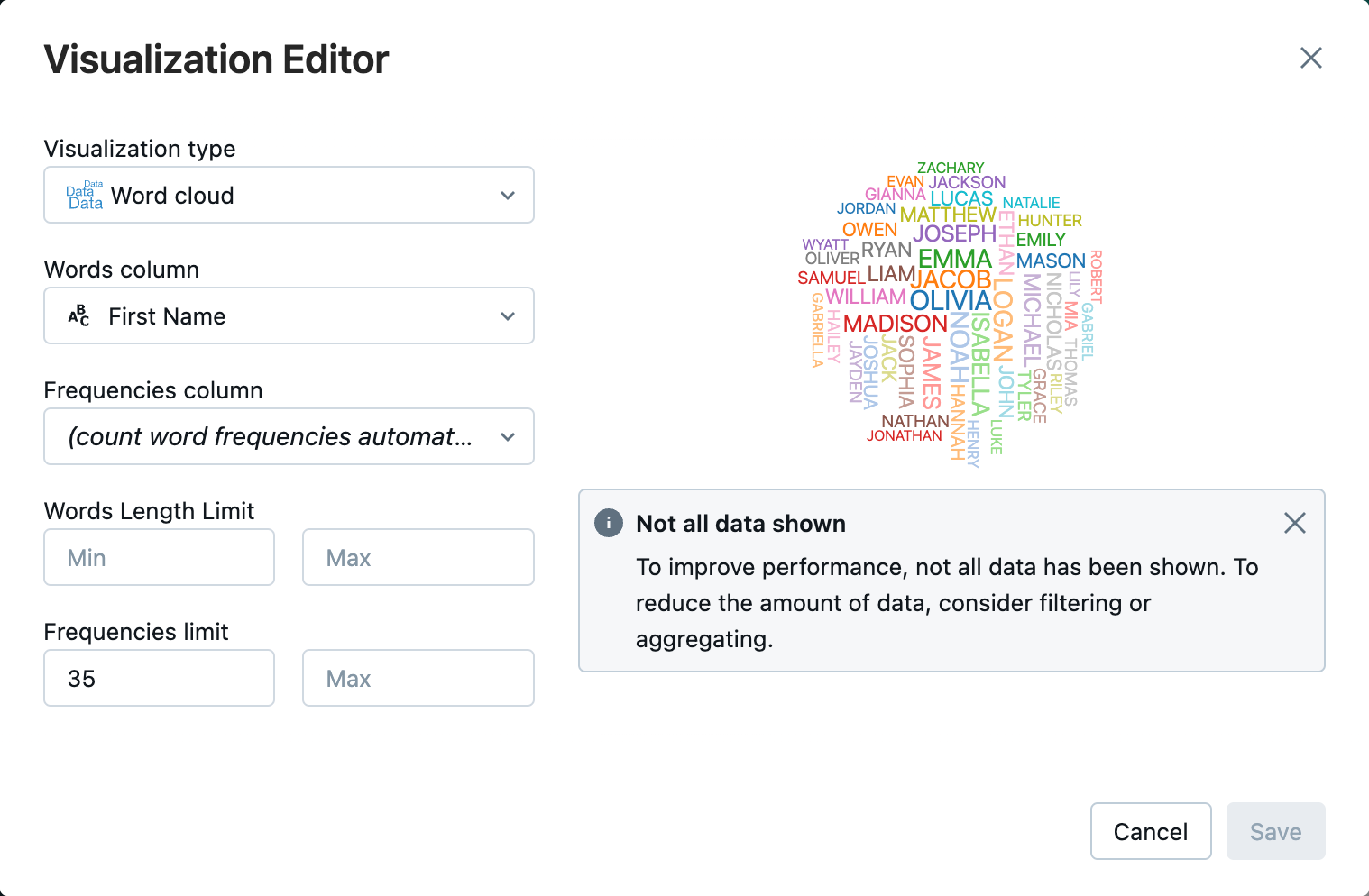
-
Click Save.
Step 6: Save the DataFrame to a table
To save your DataFrame in Unity Catalog, you must have CREATE table privileges on the catalog and schema. For information on permissions in Unity Catalog, see Privileges and securable objects in Unity Catalog and Manage privileges in Unity Catalog.
-
Copy and paste the following code into an empty notebook cell. This code replaces a space in the column name. Special characters, such as spaces are not allowed in column names. This code uses the Apache Spark
withColumnRenamed()method.- Python
- Scala
- R
Pythondf = df.withColumnRenamed("First Name", "First_Name")
df.printSchemaScalaval dfRenamedColumn = df.withColumnRenamed("First Name", "First_Name")
// when modifying a DataFrame in Scala, you must assign it to a new variable
dfRenamedColumn.printSchema()Rdf <- withColumnRenamed(df, "First Name", "First_Name")
printSchema(df) -
Copy and paste the following code into an empty notebook cell. This code saves the contents of the DataFrame to a table in Unity Catalog using the table name variable that you defined at the start of this article.
- Python
- Scala
- R
Pythondf.write.mode("overwrite").saveAsTable(f"{path_table}" + "." + f"{table_name}")ScaladfRenamedColumn.write.mode("overwrite").saveAsTable(s"${pathTable}.${tableName}")RsaveAsTable(df, paste(path_table, ".", table_name), mode = "overwrite") -
To verify that the table was saved, click Catalog in the left sidebar to open the Catalog Explorer UI. Open your catalog and then your schema to verify that the table appears.
-
Click your table to view the table schema on the Overview tab.
-
Click Sample Data to view 100 rows of data from the table.
Import and visualize data notebooks
Use one of the following notebooks to perform the steps in this article. Replace <catalog-name>, <schema-name>, and <volume-name> with the catalog, schema, and volume names for a Unity Catalog volume. Optionally replace the table_name value with a table name of your choice.
- Python
- Scala
- R
Import data from CSV using Python
Import data from CSV using Scala
Import data from CSV using R
Next steps
- To learn about exploratory data analysis (EDA) techniques, see Tutorial: EDA techniques using Databricks notebooks.
- To learn about building an ETL (extract, transform, and load) pipeline, see Tutorial: Build an ETL pipeline with Lakeflow Spark Declarative Pipelines and Tutorial: Build an ETL pipeline with Apache Spark on the Databricks platform