High-level architecture
This article provides a high-level overview of Databricks architecture, including its enterprise architecture, in combination with AWS.
Databricks objects
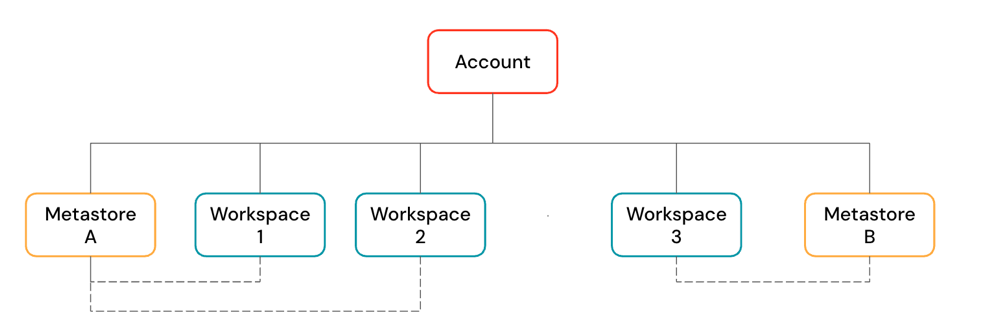
A Databricks account is the top-level construct that you use to manage Databricks across your organization. At the account level, you manage:
- Identity and access: Users, groups, service principals, SCIM provisioning, and SSO configuration.
-
Workspace management: Create, update, and delete workspaces across multiple regions.
-
Unity Catalog metastore management: Create and attach metastore to workspaces.
-
Usage management: Billing, compliance, and policies.
An account can contain multiple workspaces and Unity Catalog metastores.
-
Workspaces are the collaboration environment where users run compute workloads such as ingestion, interactive exploration, scheduled jobs, and ML training.
-
Unity Catalog metastores are the central governance system for data assets such as tables and ML models. You organize data in a metastore under a three-level namespace:
<catalog-name>.<schema-name>.<object-name>
Metastores are attached to workspaces. You can link a single metastore to multiple Databricks workspaces in the same region, giving each workspace the same data view. Data access controls can be managed across all linked workspaces.
Workspace architecture
Databricks operates out of a control plane and a compute plane.
-
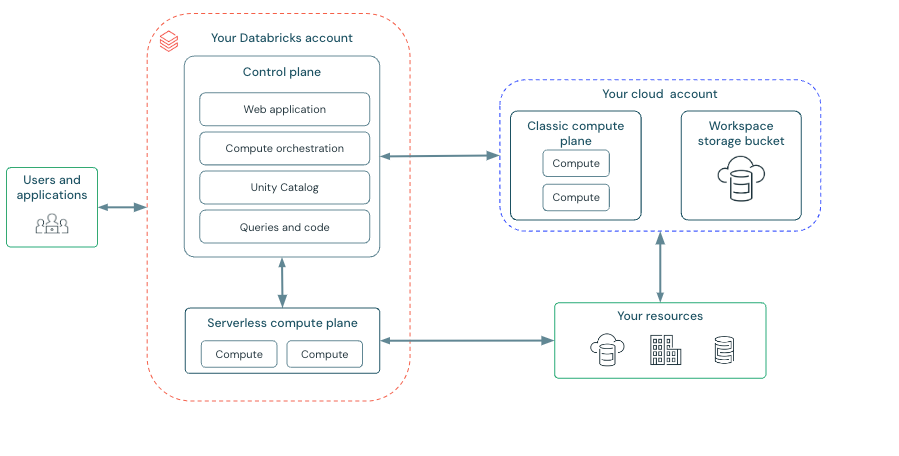
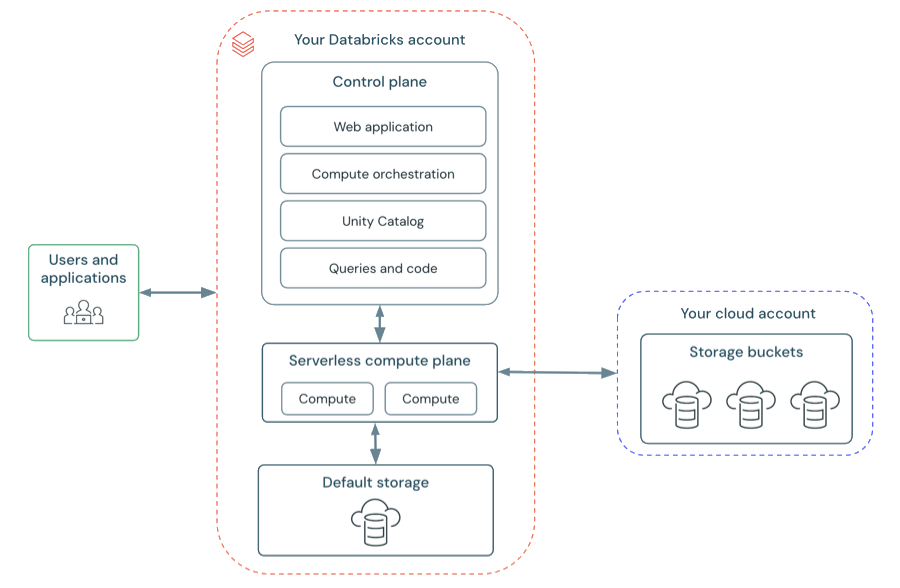
The control plane includes the backend services that Databricks manages in your Databricks account. The control plane is located in the Databricks account, not your cloud account. The web application is in the control plane.
-
The compute plane is where your data is processed. There are two types of compute planes depending on the compute that you are using.
- For serverless compute, the serverless compute resources run in a serverless compute plane in your Databricks account.
- For classic Databricks compute, the compute resources are in your AWS account in what is called the classic compute plane. This refers to the network in your AWS account and its resources.
To learn more about classic compute and serverless compute, see Compute.
Classic workspace architecture
Classic Databricks workspaces have an associated storage bucket known as the workspace storage bucket. The workspace storage bucket is in your AWS account.
The following diagram describes the general Databricks architecture for classic workspaces.
Serverless workspace architecture
Workspace storage in serverless workspaces is stored in the workspace's default storage. You can also connect to your cloud storage account to access your data. The following diagram describes the general architecture for serverless workspaces.
Serverless compute plane
In the serverless compute plane, Databricks compute resources run in a compute layer within your Databricks account. Databricks creates a serverless compute plane in the same AWS region as your workspace's classic compute plane. You select this region when creating a workspace.
To protect customer data within the serverless compute plane, serverless compute runs within a network boundary for the workspace, with various layers of security to isolate different Databricks customer workspaces and additional network controls between clusters of the same customer.
To learn more about networking in the serverless compute plane, Serverless compute plane networking.
Classic compute plane
In the classic compute plane, Databricks compute resources run in your AWS account. New compute resources are created within each workspace's virtual network in the customer's AWS account.
A classic compute plane has natural isolation because it runs in each customer's own AWS account. To learn more about networking in the classic compute plane, see Classic compute plane networking.
For regional support, see Databricks clouds and regions.
Workspace storage
Workspace storage is handled differently depending on your workspace type. For more information about the workspace types, see Create a workspace.
Workspace storage contains two categories of data: workspace file system data and workspace system data. Both are separate from your own data objects (such as Unity Catalog tables and volumes).
Workspace file system data
The workspace file system stores the assets that users create and manage through the Databricks UI. These include:
- Notebooks
- SQL queries and dashboards
- Alerts
- Repos (folders attached to Git repositories)
- Libraries (
.whl,.jar) - Python files, YAML configuration files, and other small files
For more information about workspace files, see What are workspace files?. For a full list of workspace assets, see Introduction to workspace objects.
Workspace system data
Every Databricks workspace also stores system data generated internally by Databricks features. This data is too large to store in memory or databases, or needs to persist beyond the lifetime of a single compute resource. Examples of workspace system data include:
- SQL query results and cached query results
- Job run results
- Notebook revisions
- SQL query plans used for observability
- Cluster logs
For details on how workspace storage is configured for each workspace type, see the sections below.
Serverless workspaces
Serverless workspaces use default storage, which is a fully managed storage location for internal workspace system data and Unity Catalog data assets. Serverless workspaces also support the ability to connect to your cloud storage locations for your own catalogs, tables, and other data assets. See Default storage in Databricks.
Classic workspaces
Do not delete or modify the workspace storage in your cloud account. A Databricks workspace depends on both its control plane databases and its workspace storage for correct operation. If workspace storage is deleted, the workspace cannot be recovered.
In classic workspaces, workspace system data is distinct from What is DBFS?. Although both may reside in the same cloud storage bucket in classic workspaces, they serve different purposes. DBFS root is a user-accessible file system, while workspace system data is used internally by Databricks features.
Classic workspaces require you to provide an S3 bucket and prefix to use as the workspace storage bucket. This S3 bucket will contain:
- Workspace system data: Internal data generated by Databricks features
- Unity Catalog workspace catalog: If your workspace was enabled for Unity Catalog automatically, the workspace storage bucket contains the default workspace catalog. All users in your workspace can create assets in the default schema in this catalog. See Get started with Unity Catalog.
- DBFS (legacy): DBFS root and DBFS mounts are legacy and might be disabled in your workspace. DBFS (Databricks File System) is a distributed file system in Databricks environments accessible under the
dbfs:/namespace. DBFS root and DBFS mounts are both in thedbfs:/namespace. Storing and accessing data using DBFS root or DBFS mounts is a deprecated pattern and not recommended by Databricks. For more information, see What is DBFS?.