Managed connectors in Lakeflow Connect
Managed connectors in Lakeflow Connect are in various release states.
This page provides an overview of managed connectors in Databricks Lakeflow Connect for ingesting data from SaaS applications and databases. The resulting ingestion pipeline is governed by Unity Catalog and is powered by serverless compute and Lakeflow Spark Declarative Pipelines. Managed connectors leverage efficient incremental reads and writes to make data ingestion faster, scalable, and more cost-efficient, while your data remains fresh for downstream consumption.
Connector types
-
- SaaS connectors
- Ingest data from enterprise SaaS applications including Salesforce, HubSpot, Jira, Workday, and more.
-
- Database connectors (CDC)
- Ingest data from relational databases including MySQL, PostgreSQL, and SQL Server using change data capture.
Architecture
Each connector type has a distinct set of components. SaaS connectors use a connection, an ingestion pipeline, and destination tables. Database connectors also include an ingestion gateway and staging storage to support continuous change capture. For details, see SaaS connectors in Lakeflow Connect and Database connectors in Lakeflow Connect.
Orchestration
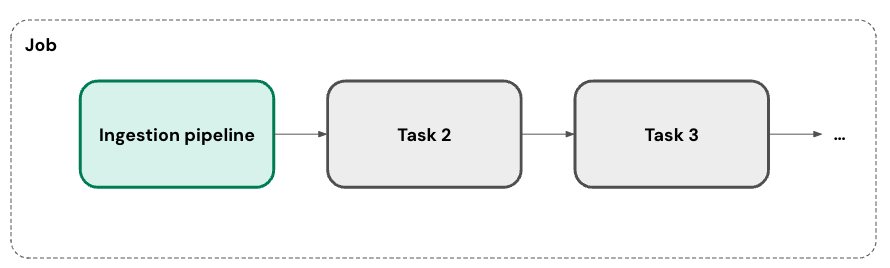
You can run your ingestion pipeline on one or more custom schedules. For each schedule that you add to a pipeline, Lakeflow Connect automatically creates a job for it. The ingestion pipeline is a task within the job. You can optionally add more tasks to the job.
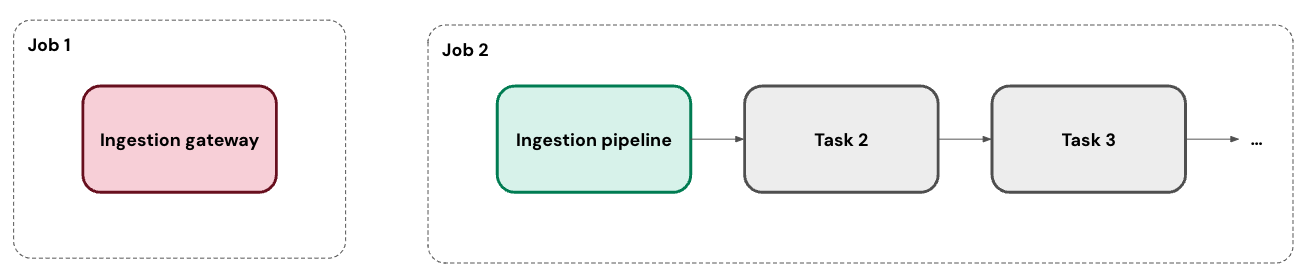
For database connectors, the ingestion gateway runs in its own job as a continuous task.
Incremental ingestion
Lakeflow Connect uses incremental ingestion to improve pipeline efficiency. On the first run of your pipeline, it ingests all of the selected data from the source. In parallel, it tracks changes to the source data. On each subsequent run of the pipeline, it uses that change tracking to ingest only the data that's changed from the prior run, when possible.
The exact approach depends on what's available in your data source. For example, you can use both change tracking and change data capture (CDC) with SQL Server. In contrast, the Salesforce connector selects a cursor column from a set list of options.
Some sources or specific tables don't support incremental ingestion at this time. Databricks plans to expand coverage for incremental support.
Networking
There are several options for connecting to a SaaS application or database.
- Connectors for SaaS applications reach out to the source's APIs. They're also automatically compatible with serverless egress controls.
- Connectors for cloud databases can connect to the source via Private Link. Alternatively, if your workspace has a Virtual Network (VNet) or Virtual Private Cloud (VPC) that's peered with the VNet or VPC hosting your database, then you can deploy the gateway inside of it.
- Connectors for on-premises databases can connect using services like AWS Direct Connect and Azure ExpressRoute.
Deployment
You can deploy ingestion pipelines using Declarative Automation Bundles, which enable best practices like source control, code review, testing, and continuous integration and delivery (CI/CD). Bundles are managed using the Databricks CLI and can be run in different target workspaces, such as development, staging, and production.
Failure recovery
As a fully-managed service, Lakeflow Connect aims to automatically recover from issues when possible. For example, when a connector fails, it automatically retries with exponential backoff.
However, it's possible that an error requires your intervention (for example, when credentials expire). In these cases, the connector tries to avoid missing data by storing the last position of the cursor. It can then pick back up from that position on the next run of the pipeline when possible.
Monitoring
Lakeflow Connect provides robust alerting and monitoring to help you maintain your pipelines. This includes event logs, cluster logs, pipeline health metrics, and data quality metrics. You can also use the system.billing.usage table to track costs and monitor pipeline usage. See Monitor managed ingestion pipeline cost.
For database connectors, you can monitor gateway progress in real time using event logs. See Monitor ingestion gateway progress with event logs.
Dependence on external services
Databricks SaaS, database, and other fully-managed connectors depend on the accessibility, compatibility, and stability of the application, database, or external service they connect to. Databricks does not control these external services and, therefore, has limited (if any) influence over their changes, updates, and maintenance.
If changes, disruptions, or circumstances related to an external service impede or render impractical the operation of a connector, Databricks may discontinue or cease maintaining that connector. Databricks will make reasonable efforts to notify customers of discontinuation or cessation of maintenance, including updates to the applicable documentation.