ディザスタリカバリ
明確なディザスタリカバリ パターンは、 Databricks. ハリケーンや地震などの地域災害によるものであれ、別のソースによるものであれ、地域全体のクラウドサービスプロバイダーの停止というまれなケースでも、データチームが Databricks プラットフォームを使用できることが重要です。
Databricks は、多くの場合、アップストリーム データ取り込み サービス (バッチ/ストリーミング)、 Amazon S3などのクラウドネイティブ ストレージ、ビジネスインテリジェンス アプリなどのダウンストリーム ツールとサービス、オーケストレーション ツールなど、多くのサービスを含む全体的なデータ エコシステムの中核部分です。 ユースケースの中には、リージョン内のサービス全体の停止に特に敏感なものがあります。
この記事では、 Databricks プラットフォーム用の地域間ディザスタリカバリ ソリューションを成功させるための概念とベスト プラクティスについて説明します。
リージョン内の高可用性の保証
このトピックの残りの部分では、リージョン間ディザスタリカバリの実装に焦点を当てていますが、 Databricks on AWS が 1 つのリージョン内で提供する高可用性の保証を理解することが重要です。 リージョン内の高可用性保証は、次のコンポーネントを対象としています。
Databricks コントロールプレーンの可用性
Databricks コントロール プレーンはゾーン障害に対する回復性があり、ゾーン障害から約 15 分以内に自動的に回復する必要があります。これは、定期的なゾーン故障テストで検証されます。
すべてのステートレス コントロール プレーン サービスは、個々の VM だけでなく、ゾーン全体のすべての VM の損失を自動的に処理できます。ワークスペース データは、リージョン内のゾーン間でレプリケートされたデータベースに格納されます。Databricks Runtime イメージの提供に使用されるストレージ アカウントもリージョン内で冗長であり、すべてのリージョンには、プライマリがダウンしたときに使用されるセカンダリ ストレージ アカウントがあります。
ゾーン障害の耐障害性は、1 つのリージョンでダウンしているゾーンを最大で 1 つだけサポートします。
コンピュート飛行機の可用性
ワークスペースの可用性は、コントロールプレーンの可用性によって異なります(前述のとおり)。DBFSルートのストレージ アカウントが 1 ゾーン バリアントで構成されていない場合DBFSルート 上のデータは影響を受けません。AWS S3 データは、デフォルトではリージョン化されており、ゾーン間でデータの冗長性が確保されています。
クラスタリング用のノードはすべて、 AWS コンピュートプロバイダーからの 1 つのアベイラビリティーゾーン (AZ) に割り当てられます。 ノードが失われた場合、クラスタリングマネージャーは、同じ AZ 内の AWS コンピュートプロバイダーに交換ノードをリクエストします。 唯一の例外は、ドライバー ノードが失われた場合です。この場合、クラスタリング マネージャーはジョブとクラスタリングを再開します。 クラスタリングを含む AZ がゾーン障害の影響を受けている場合、クラスタリングマネージャーは別の AZ でジョブとクラスタリングを再起動します。
ディザスタリカバリ overview
ディザスタリカバリには、自然災害または人為的災害後に重要なテクノロジーインフラストラクチャとシステムの回復または継続を可能にする一連のポリシー、ツール、および手順が含まれます。 AWS のような大規模なクラウド サービスは、多くの顧客にサービスを提供し、1 つの障害に対する組み込みガードを備えています。たとえば、リージョンは、1 つの電力損失によってリージョンがシャットダウンされないことを保証するために、異なる電源ソースに接続された建物のグループです。 ただし、クラウドリージョンの障害が発生する可能性があり、中断の程度と組織への影響は異なる可能性があります。
ディザスタリカバリ計画を実装する前に、 ディザスタリカバリ (DR)と 高可用性 (HA)の違いを理解することが重要です。
高可用性は、システムの回復性特性です。 高可用性により、通常は一貫した稼働時間または稼働時間の割合で定義される最小レベルの運用パフォーマンスが保証されます。 高可用性は、プライマリ システムの機能として設計することにより、(プライマリ システムと同じリージョンに) 実装されます。 たとえば、AWSのようなクラウドサービスには、Amazon S3などの高可用性サービスがあります。 高可用性を実現するためには、 Databricks 顧客による大幅な明示的な準備は必要ありません。
これに対し、 ディザスタリカバリ 計画では、重要なシステムの大規模な地域的な停止を処理するために、特定の組織で機能する決定とソリューションが必要です。 この記事では、ディザスタリカバリの一般的な用語、一般的なソリューション、および Databricksを使用したディザスタリカバリプランのベストプラクティスについて説明します。
用語
地域の用語
この記事では、地域について次の定義を使用します。
-
プライマリ リージョン : ユーザーが一般的な日常的な対話型で自動化されたデータ分析ワークロードを実行する地理的リージョン。
-
セカンダリ リージョン : プライマリ リージョンの停止中に IT チームがデータ分析ワークロードを一時的に移動する地理的リージョン。
-
geo 冗長ストレージ : AWS は、非同期ストレージレプリケーションプロセスを使用して、永続化されたバケットの リージョン間で geo 冗長ストレージ を備えています。
ディザスタリカバリ プロセスの場合、Databricks では、ルート バケットなどのリージョン間のデータの複製に geo 冗長 ストレージに依存しないことをお勧めします S3。一般に、 Delta テーブルにはディープクローンを使用し、他のデータ形式には可能であればデータを Delta 形式に変換してディープクローンを使用します。
デプロイ状態の用語
この記事では、デプロイの状態について次の定義を使用します。
-
アクティブなデプロイ : ユーザーは、Databricks ワークスペースのアクティブなデプロイに接続し、ワークロードを実行できます。ジョブは、Databricks スケジューラまたはその他のメカニズムを使用して定期的にスケジュールされます。このデプロイメントでは、データ・ストリームも実行できます。一部のドキュメントでは、アクティブなデプロイメントを ホットデプロイメント と呼んでいる場合があります。
-
パッシブ展開 : パッシブ展開ではプロセスは実行されません。IT チームは、コード、構成、およびその他の Databricks オブジェクトをパッシブ展開に展開するための自動化された手順を設定できます。現在アクティブなデプロイメントがダウンしている場合に のみ、 デプロイメントはアクティブになります。一部のドキュメントでは、パッシブ展開を コールド展開 と呼ぶ場合があります。
プロジェクトには、必要に応じて、異なるリージョンに複数のパッシブ デプロイを含めて、リージョンの停止を解決するための追加のオプションを提供できます。
通常、チームは一度に 1 つのアクティブ展開のみを持ち、 アクティブ/パッシブ ディザスタリカバリ戦略と呼ばれます。 あまり一般的ではないディザスタリカバリ ソリューション戦略は 、アクティブ/アクティブと呼ばれ、2 つのアクティブ展開が同時に存在します。
ディザスタリカバリ 業界用語
チームのために理解し、定義する必要がある 2 つの重要な業界用語があります。
-
目標復旧時点 : 目標復旧時点 (RPO) は、重大なインシデントによって IT サービスからデータ (トランザクション) が失われる可能性がある最大目標期間です。Databricks のデプロイには、主要な顧客データは保存されません。これは、Amazon S3 や制御下にある他のデータソースなど、別のシステムに保存されます。Databricks コントロール プレーンには、ジョブやノートブックなど、一部のオブジェクトが一部または全部格納されます。Databricks の場合、RPO は、ジョブやノートブックの変更などのオブジェクトが失われる可能性のある最大目標期間として定義されます。さらに、Amazon S3 または管理下にある他のデータソースで、自分の顧客データの RPO を定義する責任があります。
-
目標復旧時間 : 目標復旧時間 (RTO) は、災害後にビジネス プロセスを復旧する必要がある目標期間とサービス レベルです。
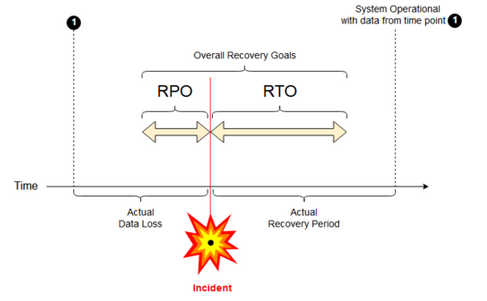
ディザスタリカバリとデータ破損
ディザスタリカバリ ソリューションは、データの破損を軽減し ません 。 プライマリ リージョンの破損したデータは、プライマリ リージョンからセカンダリ リージョンにレプリケートされ、両方のリージョンで破損します。 この種の障害を軽減する方法は他にもあり、たとえばタイムトラベルDelta。
一般的なリカバリワークフロー
Databricksディザスタリカバリシナリオは、通常、次のように展開されます。
-
プライマリリージョンで使用している重要なサービスで障害が発生しました。 これは、 Databricks デプロイに影響を与えるデータソース サービスまたはネットワークである可能性があります。
-
クラウドプロバイダーと状況を調査します。
-
プライマリ リージョンで問題が修復されるのを会社が待てないと結論付けた場合は、セカンダリ リージョンにフェールオーバーすることを決定する可能性があります。
-
同じ問題がセカンダリ リージョンにも影響しないことを確認します。
-
セカンダリ リージョンにフェールオーバーします。
- ワークスペース内のすべてのアクティビティを停止します。ユーザーはワークロードを停止します。ユーザーまたは管理者は、可能であれば最近の変更のバックアップを作成するように指示されます。ジョブは、停止のためにまだ失敗していない場合、シャットダウンされます。
- セカンダリ リージョンで復旧手順を開始します。復旧手順では、ルーティングが更新され、接続とネットワーク トラフィックの名前がセカンダリ リージョンに変更されます。
- テスト後、セカンダリ リージョンが動作可能であることを宣言します。 本番運用ワークロードを再開できるようになりました。 ユーザーは、現在アクティブなデプロイメントにログインできます。 スケジュールされたジョブまたは遅延したジョブを再トリガーできます。
Databricks のコンテキストでの詳細な手順については、「 テスト フェールオーバー」を参照してください。
-
ある時点で、プライマリ リージョンの問題が軽減され、この事実を確認します。
-
プライマリ リージョンに復元 (フェールバック) します。
- セカンダリ リージョンのすべての作業を停止します。
- プライマリリージョンでリカバリ手順を開始します。 復旧手順では、接続とネットワーク トラフィックのルーティングと名前の変更がプライマリ リージョンに処理されます。
- 必要に応じて、データをプライマリ リージョンにレプリケートします。複雑さを軽減するには、レプリケートする必要があるデータの量を最小限に抑えます。たとえば、一部のジョブをセカンダリデプロイで実行したときに読み取り専用になる場合、そのデータをプライマリリージョンのプライマリデプロイにレプリケートし直す必要がない場合があります。ただし、本番運用 ジョブが 1 つあり、そのジョブを実行する必要があり、プライマリ リージョンへのデータ レプリケーションが必要になる場合があります。
- プライマリ リージョンでデプロイをテストします。
- プライマリ リージョンが運用可能であり、それがアクティブなデプロイであることを宣言します。 本番運用ワークロードを再開します。
プライマリ リージョンへの復元の詳細については、「 テスト復元 (フェールバック)」を参照してください。
これらの手順では、データが失われる可能性があります。 組織は、許容されるデータ損失の量と、この損失を軽減するために何ができるかを定義する必要があります。
ステップ 1: ビジネス ニーズを理解する
最初のステップは、ビジネスニーズを定義して理解することです。 どのデータサービスが重要で、予想される RPOとRTOはどれくらいかを定義します。
各システムの実際の許容範囲を調査します。ディザスタリカバリ、フェイルオーバー、およびフェイルバックは、コストがかかり、その他のリスクを伴う可能性があることに注意してください。 その他のリスクには、データの破損、データの重複 (間違った保存場所に書き込んだ場合)、ユーザーが間違った場所にログインして変更を加えることなどがあります。
ビジネスに影響を与えるすべての Databricks 統合ポイントをマッピングします。
- ディザスタリカバリ ソリューションは、対話型プロセス、自動化プロセス、またはその両方に対応する必要がありますか?
- どのデータサービスを使用していますか? 一部はオンプレミスである可能性があります。
- 入力データはどのようにしてクラウドにたどり着くのですか?
- このデータは誰が消費しますか? どのプロセスがダウンストリームでそれを消費しますか?
- ディザスタリカバリの変更に注意する必要があるサードパーティの統合はありますか?
ディザスタリカバリ計画をサポートできるツールまたはコミュニケーション戦略を決定します。
- ネットワーク構成を迅速に変更するために、どのようなツールを使用しますか?
- 構成を事前に定義し、モジュール化して、自然で保守可能な方法でディザスタリカバリソリューションに対応できますか?
- ディザスタリカバリのフェイルオーバーとフェイルバックの変更について、社内のチームとサードパーティ(インテグレーション、ダウンストリームの消費者)に通知するコミュニケーションツールとチャンネルはどれですか? 彼らの承認をどのように確認しますか?
- どのようなツールや特別なサポートが必要ですか?
- 完全な復旧が完了するまで、どのサービスがシャットダウンされますか?
ステップ 2: ビジネス ニーズを満たすプロセスを選択する
ソリューションは、コントロールプレーン、コンピュートプレーン、およびデータソースに正しいデータをレプリケートする必要があります。 ディザスタリカバリの冗長ワークスペースは、異なるリージョンの異なるコントロールプレーンにマップする必要があります。 そのデータは、 同期ツールまたは CI/CD ワークフローのいずれかのスクリプトベースのソリューションを使用して、定期的に同期を維持する必要があります。コンピュート プレーン ネットワーク自体 (ワーカーなど) からデータを同期 Databricks Runtime 必要はありません。
顧客管理VPC 機能 (すべてのサブスクリプションと展開の種類で使用できるわけではありません) を使用する場合は、Terraformなどのテンプレートベースのツールを使用して、これらのネットワークを両方のリージョンに一貫して展開できます。
さらに、データソースが必要に応じてリージョン間でレプリケートされるようにする必要があります。
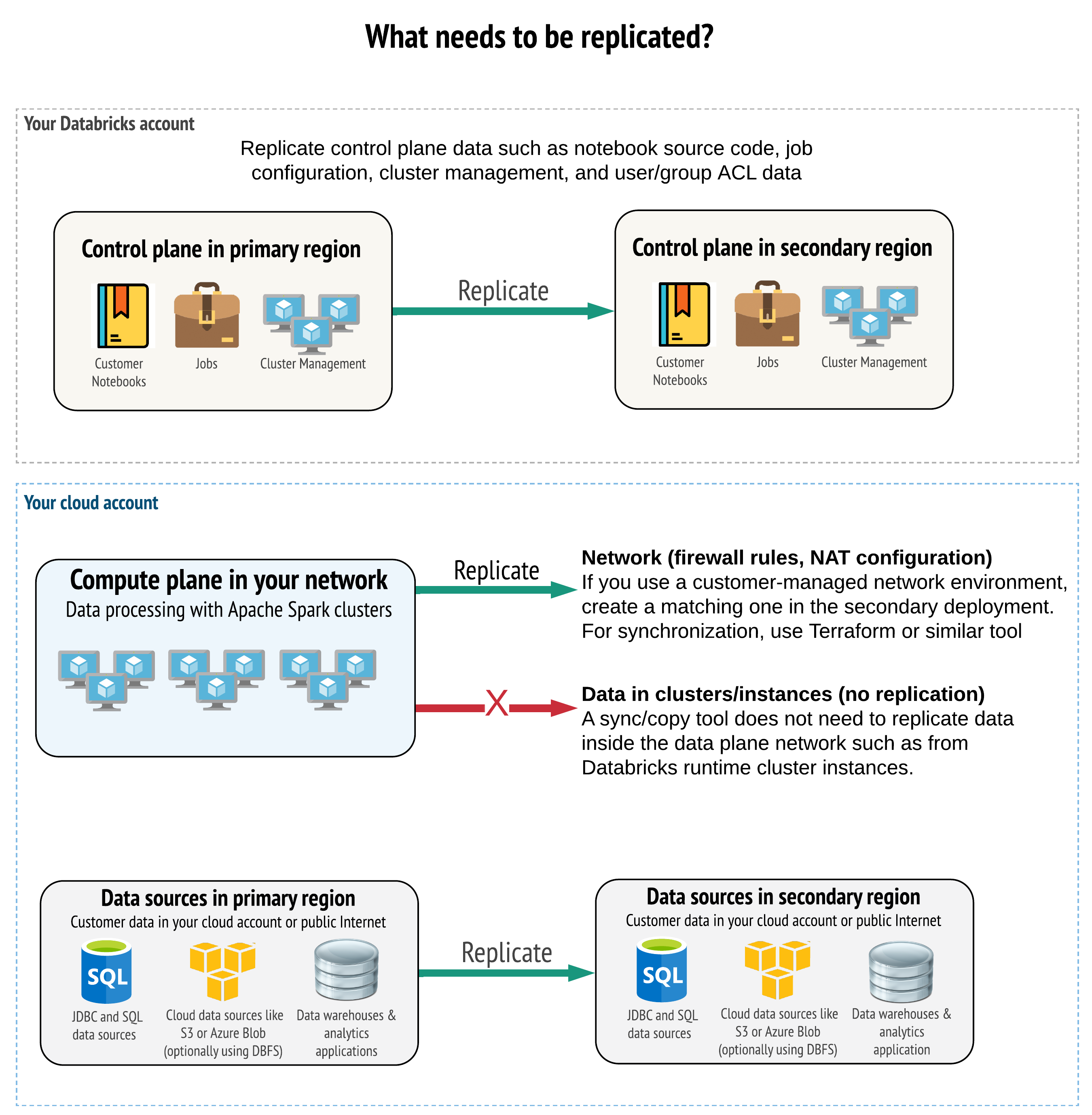
一般的なベストプラクティス
ディザスタリカバリ計画を成功させるための一般的なベストプラクティスには、次のようなものがあります。
-
ビジネスにとって重要で、ディザスタリカバリで実行する必要があるプロセスを理解します。
-
どのサービスが関係しているか、どのデータが処理されているか、データフローは何か、どこに保存されているかを明確に特定します。
-
サービスとデータを可能な限り分離します。 たとえば、ディザスタリカバリ用のデータ用の特別なクラウドストレージコンテナを作成したり、ディザスタ時に必要なDatabricksオブジェクトを別のワークスペースに移動したりします。
-
Databricks コントロール プレーンに格納されていない他のオブジェクトのプライマリ デプロイとセカンダリ デプロイ間の整合性を維持するのは、お客様の責任です。
ベストプラクティスは、ワークスペースのルートアクセスに使用されるルート Amazon S3 バケットにデータを保存しないこと DBFS。 DBFSルート ストレージは、本番運用 顧客データではサポートされていません。 また、ライブラリ、設定ファイル、initスクリプトをこの場所に保存しないこともDatabricks推奨しています。
- データソースの場合、可能な場合は、レプリケーションと冗長性のためのネイティブ AWS ツールを使用して、データをディザスタリカバリリージョンにレプリケートすることをお勧めします。
リカバリソリューション戦略の選択
一般的なディザスタリカバリ ソリューションには、2 つ (または場合によってはそれ以上) のワークスペースが含まれます。 いくつかの戦略から選択できます。中断の潜在的な長さ (数時間または場合によっては 1 日)、ワークスペースが完全に動作していることを確認するための作業、およびプライマリ リージョンに復元 (フェールバック) する作業を考慮してください。
アクティブ/パッシブソリューション戦略
アクティブ/パッシブ ソリューションは最も一般的で簡単なソリューションであり、この記事の焦点はこのタイプのソリューションです。 アクティブ/パッシブ ソリューションは、アクティブ デプロイからパッシブ デプロイにデータとオブジェクトの変更を同期します。 必要に応じて、異なるリージョンに複数のパッシブ デプロイを使用することもできますが、この記事では 1 つのパッシブ デプロイ アプローチに焦点を当てます。 ディザスタリカバリイベント中は、セカンダリリージョンのパッシブデプロイがアクティブデプロイになります。
この戦略には、主に 2 つのバリエーションがあります。
- 統合 (エンタープライズ単位) ソリューション: 組織全体をサポートするアクティブ展開とパッシブ展開の 1 つのセット。
- 部門またはプロジェクト別のソリューション: 各部門またはプロジェクト ドメインは、個別のディザスタリカバリ ソリューションを維持します。 一部の組織では、ディザスタリカバリの詳細を部門間で分離し、各チームの固有のニーズに基づいて、各チームに異なるプライマリ リージョンとセカンダリ リージョンを使用したいと考えています。
読み取り専用のユースケースにパッシブデプロイメントを使用するなど、他のバリアントもあります。ユーザー クエリなど、読み取り専用のワークロードがある場合、データやノートブックやジョブなどの Databricks オブジェクトを変更しない限り、いつでもパッシブ ソリューションで実行できます。
アクティブ/アクティブソリューション戦略
アクティブ/アクティブ ソリューションでは、両方のリージョンのすべてのデータ プロセスを常に並行して実行します。 運用チームは、ジョブなどのデータ処理が 両方のリージョンで正常に完了した場合にのみ 完了としてマークされるようにする必要があります。 本番運用ではオブジェクトを変更することはできず、開発/ステージングから本番運用への厳格な CI/CD プロモーションに従う必要があります。
アクティブ/アクティブ ソリューションは最も複雑な戦略であり、ジョブは両方の地域で実行されるため、追加の財務コストが発生します。
アクティブ/パッシブ戦略と同様に、これを統一された組織ソリューションとして、または部門ごとに実装できます。
ワークフローによっては、すべてのワークスペースに対してセカンダリシステムに同等のワークスペースが必要ない場合があります。 たとえば、開発ワークスペースやステージング ワークスペースには重複が必要ないかもしれません。 適切に設計された開発パイプラインを使用すると、必要に応じてこれらのワークスペースを簡単に再構築できる場合があります。
ツーリングをお選びください
プライマリリージョンとセカンダリリージョンのワークスペース間でデータを可能な限り類似させるためのツールには、主に 2 つの方法があります。
- プライマリからセカンダリにコピーする同期クライアント : 同期クライアントは、本番運用データとアセットをプライマリ リージョンからセカンダリ リージョンにプッシュします。 通常、これはスケジュールに基づいて実行されます。
- 並列デプロイ用のCI/CDツール : 本番運用のコードとアセットの場合は、本番運用システムへの変更を両方のリージョンに同時にプッシュするCI/CDツールを使用します。たとえば、コードとアセットをステージング/開発から本番運用にプッシュする場合、 CI/CD システムにより、両方のリージョンで同時に利用できるようになります。 中心的な考え方は、 Databricks ワークスペース内のすべてのアーティファクトを Infrastructure-as-Codeとして扱うことです。 ほとんどのアーティファクトはプライマリ ワークスペースとセカンダリ ワークスペースの両方に同時デプロイできますが、一部のアーティファクトはディザスタリカバリ イベントの後にのみデプロイする必要があります。 ツールについては 、オートメーション スクリプト、サンプル、プロトタイプを参照してください。
次の図は、これら 2 つのアプローチを対比したものです。
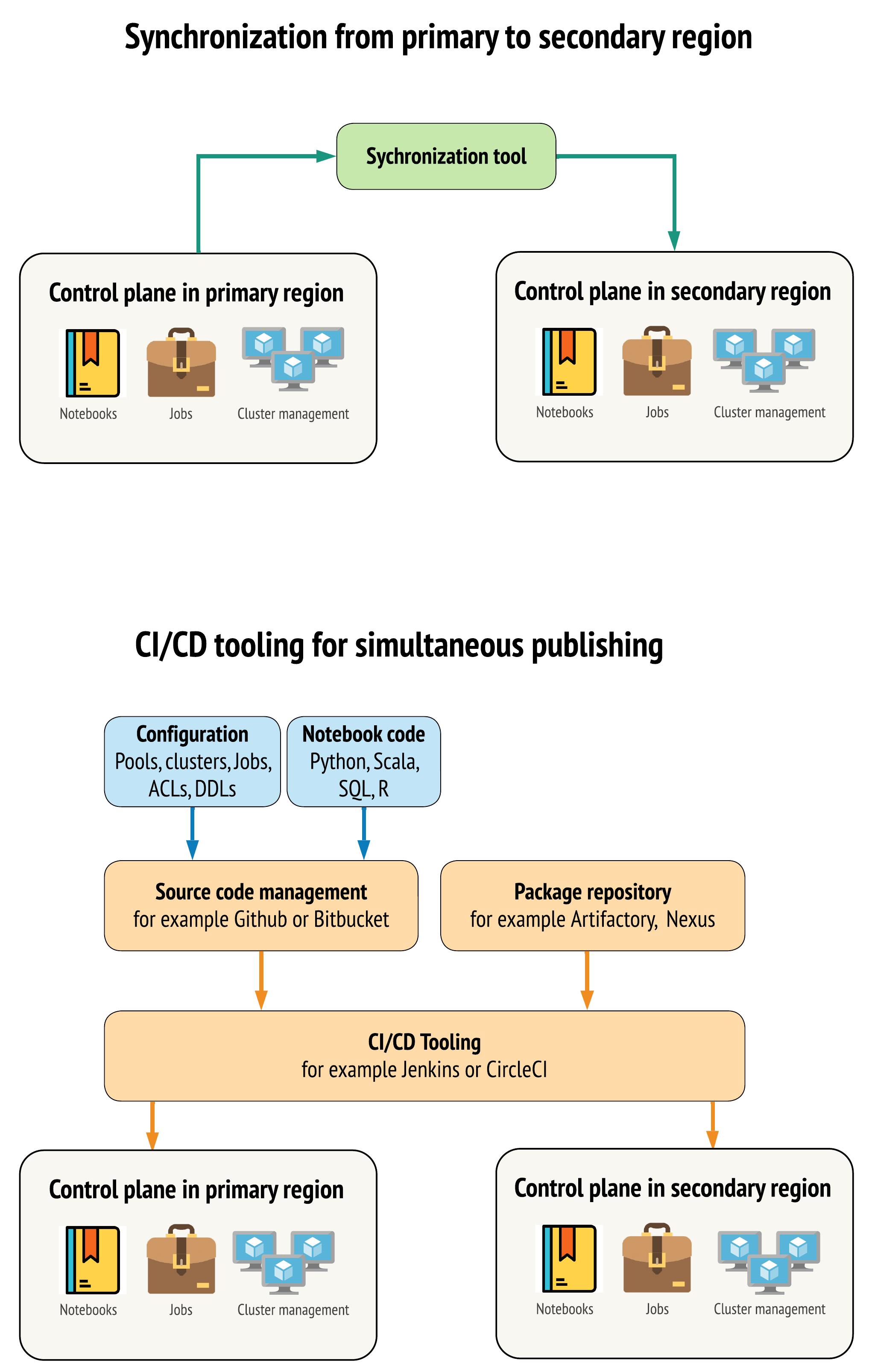
ニーズに応じて、アプローチを組み合わせることができます。たとえば、ノートブックのソース コードには CI/CD を使用しますが、プールやアクセス制御などの構成には同期を使用します。
次の表では、各ツール オプションでさまざまな種類のデータを処理する方法について説明します。
説明 | CI/CDツールでの処理方法 | 同期ツールでの扱い方 |
|---|---|---|
ソース code: ノートブック ソース exports と ソース code for packaged ライブラリ | プライマリとセカンダリの両方に共同デプロイします。 | ソース コードをプライマリからセカンダリに同期します。 |
ユーザーとグループ | メタデータを Git で config として管理します。 または、両方のワークスペースに同じ ID プロバイダー (IdP) を使用します。 ユーザーとグループのデータをプライマリとセカンダリのデプロイに共同デプロイします。 | 両方のリージョンで SCIM またはその他の自動化を使用します。手動で作成することはお勧め しません が、使用する場合は両方に対して同時に行う必要があります。手動セットアップを使用する場合は、スケジュールされた自動プロセスを作成して、2 つのデプロイメント間でユーザーとグループのリストを比較します。 |
プールの構成 | Git のテンプレートにすることができます。 プライマリとセカンダリに共同デプロイします。 ただし、セカンダリの | 任意の |
ジョブ構成 | Git のテンプレートにすることができます。プライマリ・デプロイメントの場合は、ジョブ定義をそのままデプロイします。セカンダリ デプロイの場合は、ジョブをデプロイし、コンカレンシーを 0 に設定します。これにより、このデプロイメントのジョブが無効になり、余分な実行が防止されます。コンカレンシー値は、セカンダリ デプロイがアクティブになった後に変更します。 | 何らかの理由で既存の |
アクセスコントロールリスト (ACL) | Git のテンプレートにすることができます。 ノートブック、フォルダー、クラスターのプライマリデプロイとセカンダリデプロイに共同デプロイします。 ただし、ジョブのデータはディザスタリカバリイベントまで保持します。 | Permissions APIでは、クラスター、ジョブ、プール、ノートブック、およびフォルダーのアクセス制御を設定できます。同期クライアントは、セカンダリ ワークスペース内の各オブジェクトの対応するオブジェクト ID にマップする必要があります。 Databricks では、アクセス制御をレプリケート する前に 、プライマリ ワークスペースからセカンダリ ワークスペースへのオブジェクト ID のマップを作成し、それらのオブジェクトを同期することをお勧めします。 |
ライブラリ | ソース コード テンプレートとクラスター/ジョブ テンプレートに含めます。 | 一元化されたリポジトリ、DBFS、またはクラウドストレージ(マウント可能)からカスタムライブラリを同期します。 |
必要に応じて、ソース コードに含めます。 | 同期を簡単にするには、initスクリプトをプライマリワークスペースの共通フォルダに保存するか、可能であれば小さなフォルダセットに保存します。 | |
マウントポイント | ノートブックベースのジョブまたは コマンド APIのみで作成された場合は、ソース コードに含める . | ジョブを使用します。 ワークスペースが異なるリージョンにあるため、ストレージ エンドポイントは変更される可能性があることに注意してください。 これは、データディザスタリカバリ戦略にも大きく依存します。 |
テーブルのメタデータ | ノートブックベースのジョブまたはコマンド API.これは、内部 Databricks メタストアまたは外部構成メタストアの両方に適用されます。 | Spark Catalog API を使用するか、ノートブックまたはスクリプトを使用して Show Create Table を使用して、メタストア間のメタデータ定義を比較します。基になるストレージのテーブルはリージョンベースにすることができ、メタストア インスタンス間で異なることに注意してください。 |
シークレット | コマンド コードAPI のみを使用して作成された場合は、ソース コードに含める.一部のシークレット コンテンツは、プライマリ コンテンツとセカンダリ コンテンツの間で変更する必要があることに注意してください。 | シークレットは、API を介して両方のワークスペースで作成されます。 一部のシークレット コンテンツは、プライマリ コンテンツとセカンダリ コンテンツの間で変更する必要があることに注意してください。 |
クラスター構成 | Git のテンプレートにすることができます。 プライマリ デプロイとセカンダリ デプロイに共同デプロイしますが、セカンダリ デプロイのデプロイは、ディザスタリカバリ イベントが発生するまで終了する必要があります。 | クラスターは、 API または CLIを使用してセカンダリ ワークスペースに同期された後に作成されます。 これらは、自動終了の設定に応じて、必要に応じて明示的に終了できます。 |
ノートブック、ジョブ、フォルダーのアクセス許可 | Git のテンプレートにすることができます。 プライマリ展開とセカンダリ展開に共同展開します。 | Permissions API を使用してレプリケートします。 |
リージョンと複数のセカンダリ ワークスペースを選択する
ディザスタリカバリトリガーを完全に制御する必要があります。これは、いつでも、または何らかの理由でトリガーすることができます。ディザスタリカバリの安定化については、お客様が責任を持って行っていただくことで、フェイルバック(通常の本番運用)モードでの運用を再開することができます。 通常、これは、本番運用とディザスタリカバリのニーズに対応するために複数の Databricks ワークスペースを作成し、セカンダリフェイルオーバーリージョンを選択する必要があります。
AWS では、選択したセカンダリリージョンを完全に制御できます。 EC2 など、すべてのリソースと製品がそこで使用可能であることを確認します。 一部の Databricks サービスは、 一部のリージョンでのみ使用できます。
ステップ 3: ワークスペースを準備し、1 回限りのコピーを行う
ワークスペースがすでに本番運用にある場合は、通常、 1 回限りのコピー 操作を実行して、パッシブデプロイとアクティブデプロイを同期します。 この 1 回限りのコピーでは、次の処理が行われます。
- データ レプリケーション : クラウド レプリケーション ソリューションまたは Delta ディープクローン操作を使用してレプリケートします。
- トークンの生成 : トークンの生成を使用して、レプリケーションと将来のワークロードを自動化します。
- ワークスペース レプリケーション : 「ステップ 4: データ ソースを準備する」で説明されている方法を使用してワークスペースレプリケーションを使用します。 ワークスペース構成、データ、AI/ML アセットのエクスポートに関する包括的なガイダンスについては、 「ワークスペース データのエクスポート」を参照してください。
- ワークスペースの検証 : - ワークスペースとプロセスが正常に実行され、期待される結果を提供できることをテストして確認します。
その後のコピーおよび同期アクションは、最初の 1 回限りのコピー操作の後の方が高速です。ツールからのログ記録には、いつ、何が変更されたかも記録されます。
ステップ 4: データソースを準備する
Databricks 、バッチ処理またはデータストリームを使用して、さまざまなデータソースを処理できます。
データソースからのバッチ処理
データがバッチで処理される場合、通常、データは簡単にレプリケートしたり、別のリージョンに配信したりできるデータソースに存在します。
たとえば、データは定期的にクラウド ストレージの場所にアップロードされる場合があります。セカンダリリージョンのディザスタリカバリモードでは、ファイルがセカンダリリージョンストレージにアップロードされることを確認する必要があります。ワークロードは、セカンダリ リージョン ストレージから読み取り、セカンダリ リージョン ストレージに書き込む必要があります。
データストリーム
データストリームの処理は、より大きな課題です。ストリーミング データは、さまざまなソースから取り込み、処理して、ストリーミング ソリューションに送信できます。
- Kafka などのメッセージキュー
- Database チェンジデータキャプチャ ストリーム
- ファイルベースの連続処理
- ファイルベースのスケジュール処理 (トリガー ワンスとも呼ばれます)
いずれの場合も、ディザスタリカバリモードを処理し、セカンダリリージョンでセカンダリデプロイを使用するようにデータソースを設定する必要があります。
ストリームライターは、処理されたデータに関する情報を含むチェックポイントを格納します。 このチェックポイントには、ストリームを正常に再起動するために新しい場所に変更する必要があるデータの場所 (通常はクラウド ストレージ) を含めることができます。 たとえば、チェックポイントの下の source サブフォルダには、ファイルベースのクラウド フォルダが格納されている場合があります。
このチェックポイントは、適切なタイミングでレプリケートする必要があります。 チェックポイント間隔を新しいクラウドレプリケーションソリューションと同期することを検討してください。
チェックポイントの更新はライターの機能であるため、データ ストリームの取り込みまたは別のストリーミング ソースでの処理と格納に適用されます。
ストリーミング ワークロードの場合は、チェックポイントが顧客管理ストレージで構成され、最後の障害の時点からワークロードを再開するためにセカンダリ リージョンにレプリケートできることを確認します。 また、セカンダリ ストリーミング プロセスをプライマリ プロセスと並行して実行することもできます。
手順 5: ソリューションを実装してテストする
ディザスタリカバリのセットアップを定期的にテストして、正しく機能することを確認します。 ディザスタリカバリ ソリューションを必要なときに使用できない場合、ディザスタリカバリ ソリューションを維持しても意味がありません。 一部の企業は、数か月ごとに地域を切り替えます。定期的なスケジュールでリージョンを切り替えることで、前提条件とプロセスがテストされ、それらが復旧ニーズを満たしていることを確認できます。これにより、組織は緊急時のポリシーと手順に精通していることも保証されます。
ディザスタリカバリ ソリューションを実際の条件で定期的にテストしてください。
オブジェクトまたはテンプレートが欠落しているにもかかわらず、プライマリ ワークスペースに保存されている情報に依存する必要がある場合は、プランを変更してこれらの障害を取り除くか、この情報をセカンダリ システムにレプリケートするか、他の方法で使用できるようにします。
プロセスおよび一般的な構成に必要な組織的な変更をテストします。ディザスタリカバリ計画はデプロイメントパイプラインに影響を与えるため、チームが何を同期させる必要があるかを把握していることが重要です。ディザスタリカバリ ワークスペースを設定したら、インフラストラクチャ (手動またはコード)、ジョブ、ノートブック、ライブラリ、およびその他のワークスペースオブジェクトがセカンダリリージョンで使用できることを確認する必要があります。
標準の作業プロセスと構成パイプラインを拡張して、すべてのワークスペースに変更をデプロイする方法について、チームと話し合います。 すべてのワークスペースでユーザー ID を管理します。 新しいワークスペースのジョブ自動化やモニタリングなどのツールを構成することを忘れないでください。
構成ツールの変更を計画し、テストします。
- インジェスト: データソースがどこにあり、そのソースがどこでデータを取得しているかを理解します。 可能な場合は、ソースをパラメータ化し、セカンダリデプロイとセカンダリリージョンを操作するための個別の設定テンプレートがあることを確認します。 フェイルオーバーの計画を準備し、すべての前提条件をテストします。
- 実行の変更: ジョブやその他のアクションをトリガーするスケジューラがある場合は、セカンダリ デプロイまたはそのデータソースと連携する別のスケジューラを構成する必要がある場合があります。 フェイルオーバーの計画を準備し、すべての前提条件をテストします。
- 対話型接続: REST API、 CLI ツール、または JDBC/ODBCなどの他のサービスの使用について、構成、認証、ネットワーク接続がリージョンの中断によってどのように影響を受けるかを検討します。 フェイルオーバーの計画を準備し、すべての前提条件をテストします。
- 自動化の変更: すべての自動化ツールについて、フェールオーバーの計画を準備し、すべての前提条件をテストします。
- 出力: 出力データまたはログを生成するツールについては、フェールオーバーの計画を準備し、すべての前提条件をテストします。
テスト フェールオーバー
ディザスタリカバリは、さまざまなシナリオでトリガーできます。 これは、予期しない中断によってトリガーされる可能性があります。 クラウドネットワーク、クラウドストレージ、または別のコアサービスなど、一部のコア機能がダウンしている可能性があります。 システムを正常にシャットダウンするためのアクセス権がないため、回復を試みる必要があります。 ただし、このプロセスは、シャットダウンや計画的な停止、あるいは 2 つのリージョン間でアクティブなデプロイが定期的に切り替えられることによってトリガーされる可能性があります。
フェイルオーバーをテストするときは、システムに接続し、シャットダウン・プロセスを実行します。 すべてのジョブが完了し、クラスターが終了していることを確認します。
同期クライアント (または CI/CD ツール) は、関連する Databricks オブジェクトとリソースをセカンダリ ワークスペースにレプリケートできます。 セカンダリワークスペースをアクティブ化するには、プロセスに以下の一部またはすべてが含まれる場合があります。
-
テストを実行して、プラットフォームが最新の状態であることを確認します。
-
プライマリ リージョンでプールとクラスターを無効にして、障害が発生したサービスがオンラインに戻った場合にプライマリ リージョンが新しいデータの処理を開始しないようにします。
-
回復プロセス:
- 最後に同期されたデータの日付を確認します。ディザスタリカバリ業界用語 を参照してください。 このステップの詳細は、データの同期方法と固有のビジネス ニーズによって異なります。
- データソースを安定させ、すべてのデータソースが使用可能であることを確認します。AWS RDS などのすべての外部データソースと、Delta Lake、Parquet、またはその他のファイルを含めます。
- ストリーミングの復旧ポイントを見つけます。そこから再開するようにプロセスを設定し、潜在的な重複を特定して排除する準備ができているプロセスを用意します (Delta Lake を使用すると、これが容易になります)。
- データフロープロセスを完了し、ユーザーに通知します。
-
関連するプールを開始します (または、
min_idle_instancesを関連する数に増やします)。 -
関連するクラスターを開始します (終了していない場合)。
-
ジョブの並列実行を変更し、該当するジョブを実行します。 これらは、1 回限りの実行または定期的な実行です。
-
DatabricksワークスペースのURLまたはドメイン名を使用する外部ツールの場合は、新しいコントロールプレーンの構成をアカウントに更新します。たとえば、 REST API 接続と JDBC/ODBC 接続のURLを更新します。 コントロール プレーンが変更されると、Databricks Web アプリケーションの顧客向け URL が変更されるため、組織のユーザーに新しい URL を通知してください。
テスト復元 (フェールバック)
フェールバックは制御が簡単で、メンテナンス ウィンドウで実行できます。 このプランには、次の一部またはすべてを含めることができます。
- プライマリ リージョンが復元されたことを確認します。
- セカンダリ リージョンでプールとクラスターを無効にして、新しいデータの処理が開始されないようにします。
- セカンダリ ワークスペース内の新しいアセットまたは変更されたアセットをプライマリ デプロイに同期します。 フェイルオーバー・スクリプトの設計によっては、同じスクリプトを実行して、セカンダリ (ディザスタリカバリ) リージョンからプライマリ (本番運用) リージョンにオブジェクトを同期できる場合があります。
- 新しいデータ更新をプライマリ展開に同期します。 ログとDeltaテーブルの監査証跡を使用して、データが失われないことを保証できます。
- ディザスタリカバリリージョン内のすべてのワークロードをシャットダウンします。
- ジョブとユーザーの URL をプライマリ リージョンに変更します。
- テストを実行して、プラットフォームが最新の状態であることを確認します。
- 関連するプールを開始します (または、
min_idle_instancesを関連する数に増やします)。 - 関連するクラスターを開始します (終了していない場合)。
- ジョブの並列実行を変更し、該当するジョブを実行します。 これらは、1 回限りの実行または定期的な実行です。
- 必要に応じて、将来のディザスタリカバリのためにセカンダリリージョンを再度設定します。
自動化スクリプト、サンプル、プロトタイプ
ディザスタリカバリプロジェクトで考慮すべき自動化スクリプト:
- Databricks では、 Databricks Terraform プロバイダー を使用して、独自の同期プロセスを開発することをお勧めします。
- サンプルの自動化とプロトタイプスクリプトについては、Databricks Workspace移行ツールも参照してください。
- Databricks Sync (DBSync) プロジェクトは、Databricks ワークスペースをバックアップ、復元、同期するオブジェクト同期ツールです。