コンピュート(レガシー)の設定
これらは、従来のクラスター作成 UI の手順であり、履歴の精度を保つためにのみ含まれています。 すべてのお客様は、 更新されたクラスター作成 UI を使用する必要があります。
この記事では、 Databricks クラスターを作成および編集するときに使用できる構成オプションについて説明します。 UI を使用したクラスターの作成と編集に重点を置いています。 その他の方法については、 Databricks CLI、 クラスター ・ API、および Databricks Terraform ・プロバイダーを参照してください。
ニーズに最も適した構成オプションの組み合わせを決定する方法については、 クラスター構成のベスト・プラクティスを参照してください。
クラスターポリシー
クラスターポリシー は、一連のルールに基づいてクラスターを構成する機能を制限します。ポリシー ルールは、クラスターの作成に使用できる属性または属性値を制限します。 クラスターポリシーには、特定のユーザーとグループの使用を制限する ACL があるため、クラスターの作成時に選択できるポリシーが制限されます。
クラスターポリシーを設定するには、 ポリシー ドロップダウンでクラスターポリシーを選択します。
ワークスペースにポリシーが作成されていない場合、 ポリシー ドロップダウンは表示されません。
お持ちの場合:
- クラスター作成権限では、 制限なし ポリシーを選択し、完全に構成可能なクラスターを作成できます。 制限なし ポリシーは、クラスター属性や属性値を制限しません。
- クラスター作成権限とクラスターポリシーへのアクセスの両方で、 制限なし ポリシーとアクセス権を持つポリシーを選択できます。
- クラスターポリシー のみにアクセスするには、アクセスできるポリシーを選択できます。
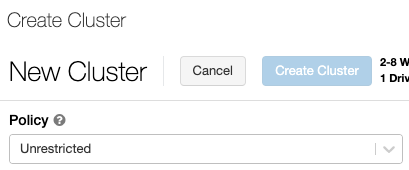
クラスター モード
この記事では、従来のクラスター UI について説明します。 新しいクラスター UI (プレビュー段階) に関する情報については、「 コンピュート構成リファレンス」を参照してください。 これには、クラスター、アクセスタイプ、およびモードに関するいくつかの用語の変更が含まれます。 新しいクラスター タイプと従来のクラスター タイプの比較については、「 クラスター UI の変更」と「クラスター アクセス モード」を参照してください。 プレビュー UI で、次の操作を行います。
- 標準 モード クラスター は、 分離なし共有アクセスモード クラスター と呼ばれるようになりました。
- テーブル ACLを持つハイコンカレンシー は、 共有アクセスモードクラスター と呼ばれるようになりました。
Databricks は、標準、ハイコンカレンシー、シングルノードの 3 つのクラスター モードをサポートしています。 デフォルト クラスター モードは 標準 です。
- ワークスペースが Unity Catalog メタストアに割り当てられている場合、ハイコンカレンシークラスターは使用できません。 代わりに、 アクセスモード を使用して、アクセス制御の整合性を確保し、強力な分離保証を実施します。 アクセスモードも参照してください。
- クラスターの作成後にクラスター モードを変更することはできません。 別のクラスター モードが必要な場合は、新しいクラスターを作成する必要があります。
クラスター構成には、 デフォルト値が クラスター モードに依存する自動終了 設定が含まれています。
- 標準 クラスターと シングルノード クラスターは、デフォルトによって 120 分後に自動的に終了します。
- ハイコンカレンシークラスターはデフォルトでは自動では 停止しません 。
標準 クラスター
標準 モード クラスター (分離無し共有クラスターとも呼ばれます) は、ユーザー間の分離を行わずに、複数のユーザーで共有できます。 テーブル ACL や クレディンシャルパススルー などの追加のセキュリティ設定なしで ハイコンカレンシークラスター モードを使用する場合は、標準 モードのクラスターと同じ設定が使用されます。アカウント 管理者は、これらの種類のクラスターでDatabricksワークスペース管理者の内部資格情報が自動的に生成されるのを防ぐことができます。より安全なオプションについては、 Databricks は ハイコンカレンシークラスターとテーブル ACL などの代替手段を推奨します。
標準 クラスターは、シングル ユーザーのみにお勧めします。 標準 クラスターでは、 Python、 SQL、R、 Scalaで開発されたワークロードを実行できます。
ハイコンカレンシークラスター
ハイコンカレンシークラスターは、マネージド クラウド リソースです。 ハイコンカレンシークラスターの主な利点は、リソースの使用率を最大化し、クエリのレイテンシを最小限に抑えるためのきめ細かな共有を提供することです。
ハイコンカレンシークラスターは、 SQL、 Python、およびRで開発されたワークロードを実行できます。ハイコンカレンシークラスターのパフォーマンスとセキュリティは、ユーザーコードを別々のプロセスで実行することで提供されますが、これは Scalaでは不可能です。
さらに、ハイコンカレンシークラスターのみが テーブルアクセスコントロールをサポートします。
ハイコンカレンシークラスターを作成するには、 クラスター モード を ハイコンカレンシーy に設定します。

Single Node クラスター
シングルノード クラスターには、ワーカーは存在せずSparkジョブはドライバー ノードで実行されます。
これに対し、標準 クラスターでは、Sparkジョブを実行するために、ドライバー ノードに加えて 、少なくとも 1 つの Spark ワーカー ノード必要です。
シングル ノード クラスターを作成するには、 クラスターモード を シングル ノード に設定します。
シングルノード クラスターの操作の詳細については、「 シングルノード コンピュート」を参照してください。
プール
クラスターの開始時間を短縮するために、ドライバーノードとワーカーノードに対して、アイドルインスタンスの事前定義された プール にクラスターをアタッチできます。 クラスターは、プール内のインスタンスを使用して作成されます。 要求されたドライバー ノードまたはワーカー ノードを作成するのに十分なアイドル リソースがプールにない場合、プールはインスタンス プロバイダーから新しいインスタンスを割り当てることによって拡張されます。 アタッチされたクラスターが終了すると、そのインスタンスが使用していたインスタンスはプールに戻され、別のクラスターで再利用できます。
ワーカー・ノードのプールを選択し、ドライバー・ノードには選択しない場合、ドライバー・ノードはワーカー・ノード構成からプールを継承します。
ドライバー ノードのプールを選択しようとしたが、ワーカー ノードの選択を試みなかった場合は、エラーが発生し、クラスターは作成されません。 この要件により、ドライバー ノードがワーカー ノードが作成されるのを待たなければならない状況、またはその逆の状況が回避されます。
Databricksでのプールの操作の詳細については、プール設定リファレンス を参照してください。
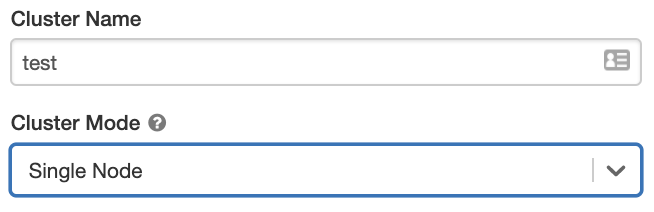
Databricks Runtime
Databricks ランタイムは、 クラスターで実行されるコアコンポーネントのセットです。 すべての Databricks ランタイムには Apache Spark が含まれており、使いやすさ、パフォーマンス、セキュリティを向上させるコンポーネントと更新プログラムが追加されています。 詳細については、Databricks Runtimeリリースノートのバージョンと互換性を参照してください。
Databricks では、クラスターを作成または編集するときに、いくつかのタイプのランタイムとそれらのランタイムタイプのいくつかのバージョンを Databricks Runtimeバージョン ドロップダウンに用意しています。
Photonアクセラレーション
Photonは、Databricks Runtime 9.1LTS 以降 実行中のクラスターに使用できます。
Photonアクセラレーションを有効にするには、[ Photonアクセラレータを使用 ] チェックボックスを選択します。
必要に応じて、[ワーカータイプ]ドロップダウンでインスタンスタイプを指定できます。
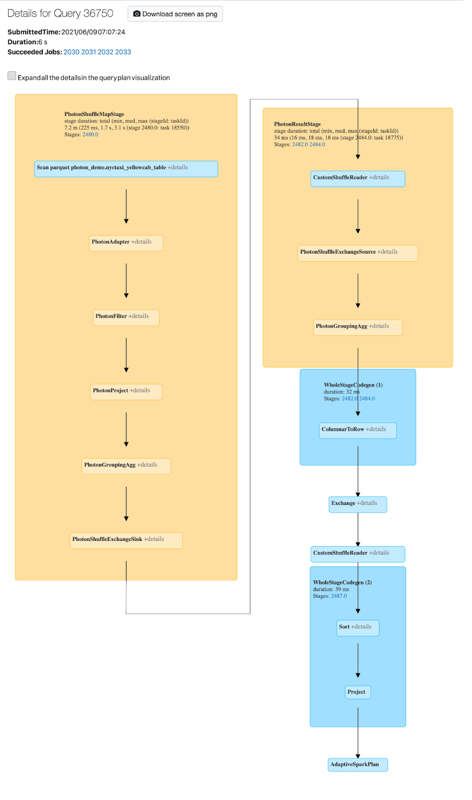
Photonのアクティビティは Spark UIで表示できます。 次のスクリーンショットは、クエリの詳細 DAG を示しています。 DAGにはPhotonの2つの表示があります。 まず、Photon 演算子は "Photon" で始まります (例: PhotonGroupingAgg)。 次に、DAGでは、Photonのオペレーターとステージは桃色で表示され、Photon以外のオペレーターとステージは青色で表示されます。
Dockerイメージ
一部の Databricks Runtime バージョンでは、クラスターの作成時に Dockerイメージを指定できます。 ユースケースの例としては、ライブラリのカスタマイズ、変更されないゴールデンコンテナ環境、Docker CI/CD統合などがあります。
また、Dockerイメージを使用して、GPUデバイスがあるクラスター上にカスタムのディープラーニング環境を作成することもできます。
手順については、「Databricks Container サービスを使用してコンテナをカスタマイズする」および「GPU コンピュート上のDatabricks Container Services」を参照してください。
クラスターノードタイプ
クラスターは、1つのドライバーノードと0個以上のワーカーノードで構成されます。
ドライバーノードとワーカーノードに別々のクラウドプロバイダーインスタンスタイプを選択できますが、デフォルトでは、ドライバーノードはワーカーノードと同じインスタンスタイプを使用します。インスタンスタイプのファミリーが異なれば、メモリ集約型またはコンピュート集約型のワークロードなど、さまざまなユースケースに適合します。
ドライバーノード
ドライバー ノードは、クラスターに接続されているすべてのノートブックの状態情報を保持します。 また、ドライバー ノードは SparkContext を保持し、クラスター上のノートブックまたはライブラリから実行するすべてのコマンドを解釈し、Sparkエグゼキューターと調整する Apache Spark マスターを実行します。
ドライバーノードタイプのデフォルト値は、ワーカーノードタイプと同じです。Sparkワーカーから大量のデータをcollect()により収集してノートブックで分析する場合は、より多くのメモリを備えたより大きなドライバーノードの種類を選択できます。
ドライバーノードは、アタッチされているノートブックのすべての状態情報を保持するため、未使用のノートブックは必ずドライバーノードからデタッチしてください。
ワーカーノード
Databricks ワーカー ノードは、クラスターが適切に機能するために必要な Spark エグゼキューターおよびその他のサービスを実行します。 Spark を使用してワークロードを分散すると、すべての分散処理がワーカー ノードで行われます。 Databricks ワーカー ノードごとに 1 つのエグゼキューターを実行します。したがって、 エグゼキューター と ワーカー という用語は、 Databricks アーキテクチャのコンテキストで同じ意味で使用されます。
Spark ジョブを実行するには、少なくとも 1 つのワーカーノードが必要です。クラスターのワーカーがゼロの場合、ドライバーノードでSpark以外のコマンドは実行できますが、Sparkコマンドは失敗します。
Databricks は、それぞれ 2 つのプライベート IP アドレスを持つワーカー ノードを起動します。ノードのプライマリ プライベート IP アドレスは、Databricks 内部トラフィックをホストするために使用されます。セカンダリ プライベート IP アドレスは、 Spark コンテナーによってクラスター内通信に使用されます。 このモデルを使用すると、 Databricks 同じワークスペース内の複数のクラスターを分離できます。
GPU インスタンスタイプ
ディープラーニングに関連するタスクのように、高いパフォーマンスが求められる計算難易度の高いタスクに対して、 Databricks はグラフィックス プロセッシング ユニット (GPU) で高速化されたクラスターをサポートしています。 詳細については、「 GPU 対応コンピュート」を参照してください。
AWS Graviton インスタンスタイプ
Databricks は、 AWS Graviton プロセッサによるクラスターをサポートしています。 Arm ベースの AWS Graviton インスタンスは、同等の現行世代の x86 ベースのインスタンスよりも優れたコストパフォーマンスを提供するように AWS によって設計されています。 「 AWS Graviton インスタンスタイプ」を参照してください。
クラスターサイズと オートスケール
Databricksクラスターの作成時に、クラスターに一定数のワーカーを指定するか、クラスターのワーカーの最小数と最大数を指定できます。
固定サイズのクラスターを指定すると、Databricksによって、指定された数のワーカーがクラスターに配置されます。ワーカー数の範囲を指定すると、Databricksはジョブの実行に必要なワーカーの適切な数を選択します。これは オートスケーリング と呼ばれます。
オートスケールを使用すると、 Databricks はジョブの特性に応じてワーカーをアカウントに動的に再割り当てします。 パイプラインの特定の部分は、他の部分よりも計算負荷が高い場合があり、Databricks はジョブのこれらのフェーズで追加のワーカーを自動的に追加します (不要になったら削除します)。
オートスケールを使用すると、ワークロードに合わせてクラスターをプロビジョニングする必要がないため、クラスターの使用率を高くすることが容易になります。 これは、要件が時間の経過と共に変化するワークロード (1 日の間にデータセットを探索するなど) に特に当てはまりますが、プロビジョニング要件が不明な 1 回限りの短いワークロードにも適用できます。したがって、オートスケールには2つの利点があります。
- ワークロードは、固定サイズのプロビジョニング不足のクラスターと比較して高速に実行できます。
- クラスターのオートスケーリングでは、静的サイズのクラスターと比較して全体的なコストを削減できます。
クラスターとワークロードの固定サイズに応じて、オートスケーリングでは、これらの利点の一方または両方が同時に実現されます。クラスターのサイズは、クラウドプロバイダーがインスタンスを終了するときに選択されたワーカーの最小数を下回る可能性があります。 この場合、Databricks は、ワーカーの最小数を維持するために、インスタンスの再プロビジョニングを継続的に再試行します。
オートスケールはspark-submitジョブでは使用できません。
オートスケールの動作
- 2つのステップで最小から最大にスケールアップします。
- クラスターがアイドル状態でない場合でも、シャッフル ファイルの状態を調べることでスケールダウンできます。
- 現在のノードの割合に基づいてスケールダウンします。
- ジョブクラスターでは、過去40秒間にクラスターが十分に活用されていない場合にスケールダウンします。
- 汎用クラスターでは、過去150秒間にクラスターが十分に活用されていない場合にスケールダウンします。
spark.databricks.aggressiveWindowDownSSpark 構成プロパティは、クラスターがダウンスケーリングの決定を行う頻度を秒単位で指定します。値を大きくすると、クラスターのスケールダウンが遅くなります。 最大値は600です。
オートスケールの有効化と構成
Databricksでクラスターのサイズを自動的に変更できるようにするには、クラスターのオートスケーリングを有効にし、ワーカーの最小範囲と最大範囲を指定します。
-
オートスケーリングを有効にします。
-
汎用クラスター - [クラスター作成]ページで、[ オートパイロットオプション ]ボックスの[ オートスケールを有効化 ]チェックボックスをオンにします。
-
ジョブ クラスター - [クラスターの構成] ページで、[ オートパイロット オプション ] ボックスの [ オートスケールを有効にする ] チェック ボックスをオンにします。

-
-
ワーカーの最小数と最大数を設定します。

クラスターが実行中の場合、割り当てられたワーカーの数がクラスターの詳細ページに表示されます。割り当てられたワーカーの数をワーカーの設定と比較し、必要に応じて調整を行うことができます。
インスタンス・プールを使用している場合:
- 要求されたクラスター サイズが アイドル インスタンスの最小数以下であることを確認してください プールで。 これより大きい場合、クラスターの開始時間は、プールを使用しないクラスターと同じになります。
- 最大クラスター サイズがプール の最大容量 以下であることを確認します。 大きい場合、クラスター 作成は失敗します。
オートスケールの例
静的クラスターをオートスケーリングクラスターとして再構成すると、Databricksは最小範囲と最大範囲内でクラスターのサイズをただちに変更し、オートスケーリングを開始します。例として、次の表は、5~10ノードをオートスケーリングするようにクラスターを再構成した場合に、特定の初期サイズのクラスターに何が起こるかを示しています。
初期サイズ | 再構成後のサイズ |
|---|---|
6 | 6 |
12 | 10 |
3 | 5 |
ローカルディスクの暗号化
プレビュー
この機能は パブリック プレビュー段階です。
クラスターの実行に使用する一部のインスタンスタイプには、ローカルにアタッチされたディスクがある場合があります。 Databricks は、これらのローカルにアタッチされたディスクにシャッフル データまたはエフェメラル データを格納する場合があります。クラスターのローカル ディスクに一時的に保存されるシャッフル データを含め、すべてのストレージの種類で保存されているすべてのデータが暗号化されるようにするには、ローカル ディスクの暗号化を有効にすることができます。
ローカルボリュームとの間で暗号化されたデータを読み書きするとパフォーマンスに影響を与え、ワークロードの実行が遅くなる可能性があります。
ローカル・ディスク暗号化が有効になっている場合、 Databricks は、各クラスター・ノードに固有の暗号化キーをローカルに生成し、ローカル・ディスクに格納されているすべてのデータを暗号化するために使用されます。 キーのスコープは各クラスター ノードに対してローカルであり、クラスター ノード自体と共に破棄されます。 その有効期間中、キーは暗号化と復号化のためにメモリに存在し、ディスクに暗号化されて保存されます。
ローカル ディスクの暗号化を有効にするには、クラスター の APIを使用する必要があります。クラスターの作成または編集中に、以下を設定します。
{
"enable_local_disk_encryption": true
}
これらの を呼び出す方法の例については、クラスターAPIAPI を参照してください。
次に、ローカル ディスクの暗号化を有効にするクラスター作成呼び出しの例を示します。
{
"cluster_name": "my-cluster",
"spark_version": "7.3.x-scala2.12",
"node_type_id": "r3.xlarge",
"enable_local_disk_encryption": true,
"spark_conf": {
"spark.speculation": true
},
"num_workers": 25
}
セキュリティモード
ワークスペースが Unity Catalog メタストアに割り当てられている場合は、 High Concurrencyクラスターモード ではなくセキュリティモードを使用して、アクセス制御の整合性を確保し、強力な分離保証を適用します。 High Concurrencyクラスター モードは、 Unity Catalogでは使用できません。
詳細オプション で、次のクラスター セキュリティ モードから選択します。
- なし : 分離なし。 ワークスペース-local テーブルアクセスコントロール または資格情報のパススルーは強制されません。 Unity Catalog データにアクセスできません。
- シングルユーザー :1人のユーザー(デフォルト、クラスターを作成したユーザー)のみが使用できます。 他のユーザーはクラスターに接続できません。 シングル・ユーザー ・セキュリティ・モードのクラスターからビューにアクセスすると、ビューはユーザーの権限で実行されます。シングル・ユーザー・クラスターでは、 Python、 Scala、R.initスクリプト、ライブラリ・インストール、および DBFS マウントを使用したワークロードがサポートされます。 自動ジョブでは、シングル ユーザー クラスターを使用する必要があります。
- ユーザーの分離 : 複数のユーザーで共有できます。 SQL ワークロードのみがサポートされています。 ライブラリのインストール、initスクリプト、および DBFS マウントは、クラスター ユーザー間での厳密な分離を強制するために無効になっています。
- Table ACL only (Legacy): ワークスペース-local テーブルアクセスコントロールを強制しますが、 Unity Catalog データにはアクセスできません。
- パススルーのみ (レガシ): ワークスペース ローカルの資格情報パススルーを強制しますが、Unity Catalog データにはアクセスできません。
Unity Catalog ワークロードでサポートされているセキュリティ モードは、 シングル ユーザーと ユーザーの分離 のみです。
詳細については、「 アクセス モード」を参照してください。
AWS の設定
クラスターの AWS インスタンスを設定するときに、アベイラビリティーゾーン、最大スポット料金、EBS ボリュームのタイプとサイズ、およびインスタンスプロファイルを選択できます。 構成を指定するには、
-
クラスター構成ページで、[ 詳細オプション ] トグルをクリックします。
-
ページの下部にある [ インスタンス ] タブをクリックします。
![[インスタンス] タブ](/aws/ja/assets/images/instances-aws-96ce9ee05a7ef2d0ebf6faa7178e04a4.png)
可用性ゾーン
この設定では、クラスターで使用するアベイラビリティーゾーン (AZ) を指定できます。 デフォルトでは、この設定は 自動 (自動 AZ) に設定されており、AZ はワークスペースサブネット内の使用可能な IP に基づいて自動的に選択されます。 自動 AZ は、AWS が容量不足エラーを返した場合、他のアベイラビリティーゾーンで再試行します。
クラスターに特定の AZ を選択することは、主に組織が特定のアベイラビリティーゾーンでリザーブドインスタンスを購入した場合に便利です。 AWSアベイラビリティーゾーンの詳細については、こちらをご覧ください。
スポットインスタンス
スポットインスタンスを使用するかどうかを指定できます。また、スポットインスタンスを起動するときに使用する最大スポット料金を、対応するオンデマンド料金に対するパーセンテージで指定できます。デフォルトでは、最大料金はオンデマンド料金の100%です。「AWSスポット料金」を参照してください。
EBS ボリューム
このセクションでは、ワーカーノードのデフォルト EBS ボリューム設定、シャッフルボリュームの追加方法、および Databricks EBS ボリュームを自動的に割り当てるようにクラスターを設定する方法について説明します。
EBS ボリュームを設定するには、クラスター設定の [インスタンス ] タブをクリックし、[ EBS ボリューム タイプ ] ドロップダウン リストでオプションを選択します。
デフォルトの EBS ボリューム
Databricksは、次のようにすべてのワーカーノードに対してEBSボリュームをプロビジョニングします。
- ホストオペレーティングシステムと Databricks 内部サービスによってのみ使用される 30 GB の暗号化された EBS インスタンスルートボリューム。
- Sparkワーカーが使用する150 GBの暗号化されたEBSコンテナルートボリューム。これは、Sparkサービスとログをホストします。
- (HIPAAのみ)Databricks内部サービスのログを保存する75 GBの暗号化されたEBSワーカーログボリューム。
EBS シャッフルボリュームの追加
シャッフルボリュームを追加するには、「EBS ボリュームタイプ」ドロップダウンリストで 「汎用SSDボリューム 」を選択します。
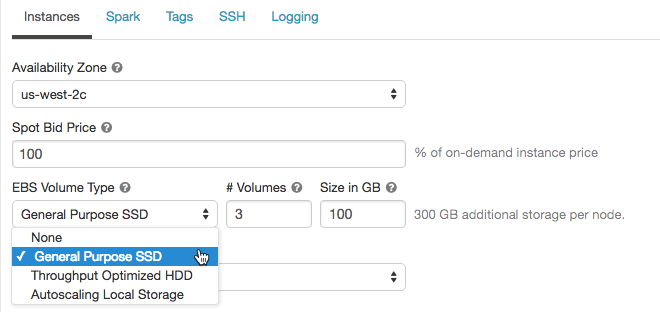
デフォルトでは、Spark シャッフル出力はインスタンスのローカルディスクに送られます。 ローカルディスクがないインスタンスタイプの場合、または Spark シャッフルストレージ容量を増やす場合は、追加の EBS ボリュームを指定できます。これは、大きなシャッフル出力を生成する Spark ジョブを実行するときにディスク容量不足のエラーを防ぐために特に役立ちます。
Databricksは、オンデマンドインスタンスとスポットインスタンスの両方でこれらのEBSボリュームを暗号化します。AWS EBSボリュームの詳細についてお読みください。
オプションで、 Databricks EBS ボリュームを顧客管理のキーで暗号化します
オプションで、クラスター EBS ボリュームを顧客管理のキーで暗号化できます。
暗号化については、顧客管理のキーを参照してください。
AWS EBS の制限
AWS EBS の制限が、すべてのクラスターのすべてのワーカーのランタイム要件を満たすのに十分な高さであることを確認してください。デフォルトの EBS 制限とその変更方法については、「Elastic Block Store (EBS) の制限Amazon」を参照してください。
AWS EBS SSD ボリュームタイプ
AWS EBS SSD ボリュームタイプには、gp2 または gp3 のいずれかを選択できます。 これを行うには、「 SSD ストレージの管理」を参照してください。 Databricks では、gp2 と比較してコストを節約できるため、gp3 に切り替えることをお勧めします。 gp2 と gp3 の技術情報については、「 Amazon EBS ボリュームタイプ」を参照してください。
オートスケール Local Storage
クラスターの作成時に固定数の EBS ボリュームを割り当てない場合は、オートスケール ローカルストレージを使用します。 オートスケール ローカル ストレージを使用すると、 Databricks はクラスターの Spark ワーカーで使用可能な空きディスク容量を監視します。 ワーカーがディスク上で実行を開始したディスクが少なすぎる場合、 Databricks は、ディスク領域から実行する前に、新しい EBS ボリュームをワーカーに自動的にアタッチします。 EBS ボリュームは、インスタンスあたり合計ディスク容量 (インスタンスのローカルストレージを含む) の上限 5 TB までアタッチされます。
オートスケールストレージを設定するには、[オートパイロットオプション] ボックスで ローカル ストレージのオートスケールを有効化 を選択します。

インスタンスにアタッチされた EBS ボリュームは、インスタンスが AWS に返されたときにのみデタッチされます。 つまり、EBS ボリュームは、稼働中のクラスターの一部である限り、インスタンスから切り離されることはありません。 EBS の使用量をスケールダウンするには、 Databricks は、 クラスター サイズとオートスケール または 自動終了で構成されたクラスターでこの機能を使用することをお勧めします。
Databricksは、スループット最適化HDD(st1)を使用してインスタンスのローカルストレージを拡張します。これらのボリュームのデフォルトのAWS容量制限は20TiBです。この制限に達しないようにするには、管理者は使用要件に基づいてこの制限の引き上げをリクエストする必要があります。
Databricksアカウントをバージョン 2.44 より前 (2017 年 4 月 27 日より前) で作成し、オートスケール ローカル ストレージ ( High Concurrency クラスターで確実に有効化) を使用したい場合は、アカウントの作成に使用されるIAMロールまたはキーにボリューム アクセス許可を追加する必要があります。 特に、権限ec2:AttachVolume 、 ec2:CreateVolume 、 ec2:DeleteVolume 、およびec2:DescribeVolumesを追加する必要があります。権限の完全なリストと、既存のIAMロールまたはキーを更新する手順については、 「認証情報設定の作成」を参照してください。
インスタンスプロファイル
AWSキーを使用せずにAWSリソースに安全にアクセスするには、インスタンスプロファイルを使用してDatabricksクラスターを起動できます。インスタンスプロファイルの作成および設定方法については、 チュートリアル: インスタンスプロファイルを使用して S3 アクセスを設定する を参照してください。 インスタンスプロファイルを作成したら、インスタンスプロファイルドロップダウンリストで選択します。
インスタンスプロファイルを使用してクラスターが開始されると、このクラスターへのアタッチ権限を持つユーザーは、このロールによって制御される基盤となるリソースにアクセスできます。 不要なアクセスを防ぐために、 コンピュート権限 を使用して、権限をクラスターに制限できます。
Spark の構成
Sparkジョブを 微調整するために、クラスター構成でカスタム Spark 構成プロパティ を指定できます。
-
クラスター構成ページで、[ 詳細オプション ] トグルをクリックします。
-
[ Spark ] タブをクリックします。
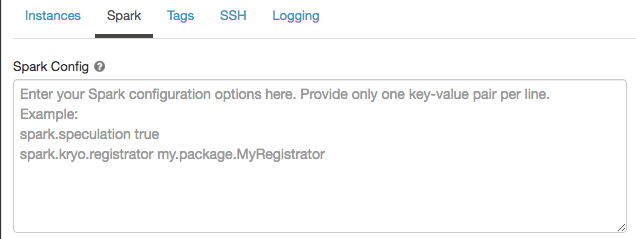
Spark構成 では、1行に1つのキーと値のペアとして設定プロパティを入力します。
クラスターを使用してクラスターを設定する場合は、API Sparkspark_conf新しいクラスターAPI データの作成API または クラスター設定の更新 の フィールドで プロパティを設定します。
Databricks は global initスクリプトの使用を推奨しません。
すべてのクラスターの Spark プロパティを設定するには、 グローバルinitスクリプトを作成します。
dbutils.fs.put("dbfs:/databricks/init/set_spark_params.sh","""
|#!/bin/bash
|
|cat << 'EOF' > /databricks/driver/conf/00-custom-spark-driver-defaults.conf
|[driver] {
| "spark.sql.sources.partitionOverwriteMode" = "DYNAMIC"
|}
|EOF
""".stripMargin, true)
シークレットから Spark 構成プロパティを取得する
Databricks では、パスワードなどの機密情報をプレーンテキストではなく シークレット に格納することをお勧めします。 Spark 構成でシークレットを参照するには、次の構文を使用します。
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
たとえば、passwordというSpark構成プロパティをsecrets/acme_app/passwordに保存されているシークレットの値に設定するには、次のようにします。
spark.password {{secrets/acme-app/password}}
詳細については、シークレットの管理を参照してください。
環境変数
クラスタで実行されている initスクリプト からアクセスできるカスタム環境変数を設定できます。 Databricks には、initスクリプトで使用できる定義済みの 環境変数 も用意されています。 これらの事前定義された環境変数を上書きすることはできません。
-
クラスター構成ページで、[ 詳細オプション ] トグルをクリックします。
-
[ Spark ] タブをクリックします。
-
[ 環境変数 ] フィールドで環境変数を設定します。
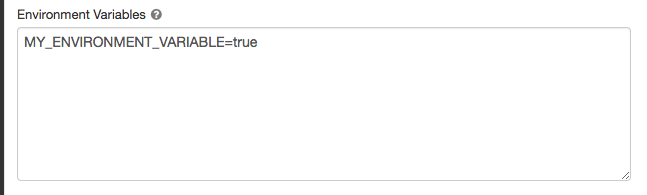
Create new cluter API または Update cluster configuration APIの spark_env_vars フィールドを使用して、環境変数を設定することもできます。
クラスタータグ
クラスタータグを使用すると、組織内のさまざまなグループで使用されるクラウド リソースのコストを簡単に監視できます。 クラスターを作成するときにキーと値のペアとしてタグを指定でき、 Databricks これらのタグを VM やディスク ボリュームなどのクラウド リソースや DBU 使用状況レポートに適用します。
プールから起動されたクラスターの場合、カスタム クラスタータグは DBU 使用状況レポートにのみ適用され、クラウド リソースには反映されません。
プールタグとクラスタータグのタイプが連携する仕組みの詳細については、「 タグを使用して使用状況を属性付けおよび追跡する」を参照してください。
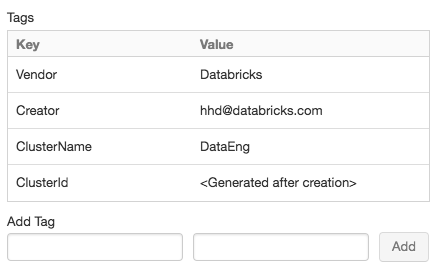
便宜上、 Databricks では、Vendor、Creator、ClusterName、ClusterId の 4 つのデフォルト タグを各クラスターに適用します。
さらに、ジョブ クラスターでは、 Databricks は RunName と JobId の 2 つのデフォルト タグを適用します。
Databricks SQL によって使用されるリソースに対して、Databricks はデフォルトのタグ SqlWarehouseIdも適用します。
キー Name を持つカスタム タグをクラスターに割り当てないでください。 すべてのクラスターには、 Databricksによって値が設定されるタグ Name があります。 キー Name に関連付けられた値を変更すると、クラスターは Databricksで追跡できなくなります。 その結果、クラスターはアイドル状態になった後に終了せず、引き続き使用コストが発生します。
クラスターを作成するときに、カスタムタグを追加できます。 クラスタータグを設定するには:
-
クラスター構成ページで、[ 詳細オプション ] トグルをクリックします。
-
ページの下部にある [ タグ ] タブをクリックします。
-
各カスタムタグにキーと値のペアを追加します。 最大 45 個のカスタムタグを追加できます。
必須タグを適用する
クラスターの作成時に特定のタグが常に入力されるようにするには、特定の IAM ポリシーをアカウントのプライマリ IAMロール(アカウントの設定中に作成されたもの、アクセスが必要な場合は AWS 管理者にお問い合わせください)に適用できます。 IAM ポリシーには、必須のタグキーとオプションの値に対する明示的な Deny ステートメント を含める必要があります。許可された値のいずれかを持つ必要なタグが指定されていない場合、 クラスターの作成は失敗します 。
たとえば、Department タグと Project タグを強制し、前者には指定された値のみを許可し、後者には空でない自由形式の値を設定する場合は、次のような IAM ポリシーを適用できます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "MandateLaunchWithTag1",
"Effect": "Deny",
"Action": ["ec2:RunInstances", "ec2:CreateTags"],
"Resource": "arn:aws:ec2:region:accountId:instance/*",
"Condition": {
"StringNotEqualsIgnoreCase": {
"aws:RequestTag/Department": ["Deptt1", "Deptt2", "Deptt3"]
}
}
},
{
"Sid": "MandateLaunchWithTag2",
"Effect": "Deny",
"Action": ["ec2:RunInstances", "ec2:CreateTags"],
"Resource": "arn:aws:ec2:region:accountId:instance/*",
"Condition": {
"StringNotLike": {
"aws:RequestTag/Project": "?*"
}
}
}
]
}
オンデマンドインスタンスのみ、スポットインスタンスのみ、またはその両方を持つクラスターが存在するシナリオを効果的にカバーするには、各タグに ec2:RunInstances アクションと ec2:CreateTags アクションの両方が必要です。
Databricks では、タグごとに個別のポリシー ステートメントを追加することをお勧めします。 全体的なポリシーが長くなる可能性がありますが、デバッグは簡単です。 ポリシーで使用できる演算子の一覧については、 IAM ポリシー条件演算子のリファレンス を参照してください。
IAM ポリシーによるクラスター作成エラーには、次のencoded error messageが表示されます。
Cloud Provider Launch Failure: A cloud provider error was encountered while setting up the cluster.
このメッセージがエンコードされるのは、認証状況の詳細が、アクションを要求したユーザーには表示されない特権情報を構成する可能性があるためです。 このようなメッセージをデコードする方法については、「DecodeAuthorizationMessage API (または CLI) を参照してください。
クラスターへのSSHアクセス
SSH を使用して、 セキュアなクラスター接続 が有効になっているクラスターにログインすることはできません。
SSH を使用すると、 Apache Spark クラスターにリモートでログインして、高度なトラブルシューティングやカスタムソフトウェアのインストールを行うことができます。
関連する機能については、Databricks Webターミナルの実行 シェル コマンドを参照してください。
このセクションでは、公開鍵を使用してクラスターへのイングレスアクセスを有効にするように AWS アカウントを設定する方法と、クラスターノードへのSSH接続を開く方法について説明します。
セキュリティ グループを構成する
AWS アカウントの Databricks セキュリティグループを更新して、SSH 接続を開始する IP アドレスへのイングレスアクセスを許可する必要があります。 これは、1 つの IP アドレスに設定することも、オフィスの IP 範囲全体を表す範囲を指定することもできます。
-
AWS コンソールで、Databricks セキュリティ グループを見つけます。 次のようなラベルが付けられます
<databricks-instance>-worker-unmanaged。 (例:dbc-fb3asdddd3-worker-unmanaged) -
セキュリティグループを編集し、ワーカーマシンへのポート
2200を許可するインバウンド TCP ルールを追加します。 1 つの IP アドレスまたは範囲を指定できます。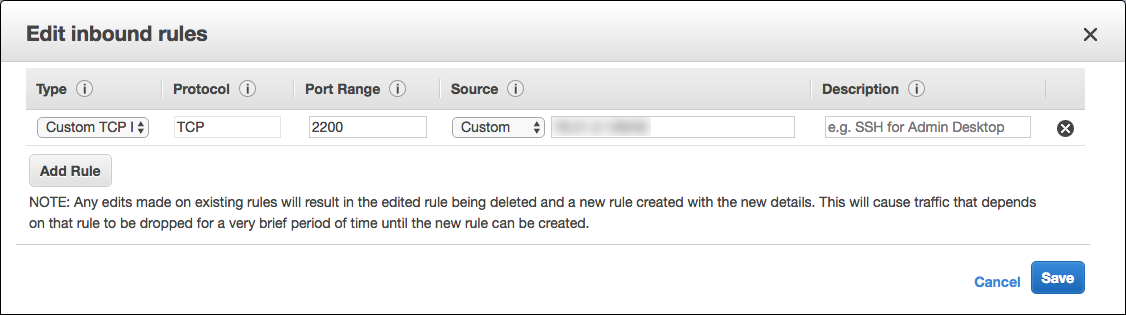
-
お使いのコンピューターとオフィスで、ポートでTCPトラフィックを送信できることを確認してください
2200。
SSHキーペアの生成
SSH キーペアを作成するには、ターミナルセッションで次のコマンドを実行します。
ssh-keygen -t rsa -b 4096 -C "email@example.com"
公開鍵と秘密鍵を保存するディレクトリへのパスを指定する必要があります。 公開鍵は拡張子 .pubで保存されます。
公開鍵を使用して新しいクラスターを構成する
-
公開鍵ファイルの内容全体をコピーします。
-
クラスター構成ページで、[ 詳細オプション ] トグルをクリックします。
-
ページの下部にある [SSH ] タブをクリックします。
-
コピーしたキーを SSH 公開キー フィールドに貼り付けます。
公開キーを使用して既存のクラスターを構成する
クラスターがあり、クラスターの作成時に公開キーを指定しなかった場合は、クラスターに接続されている任意のノートブックから次のコードを実行して公開キーを挿入できます。
val publicKey = " put your public key here "
def addAuthorizedPublicKey(key: String): Unit = {
val fw = new java.io.FileWriter("/home/ubuntu/.ssh/authorized_keys", /* append */ true)
fw.write("\n" + key)
fw.close()
}
val numExecutors = sc.getExecutorMemoryStatus.keys.size
sc.parallelize(0 until numExecutors, numExecutors).foreach { i =>
addAuthorizedPublicKey(publicKey)
}
addAuthorizedPublicKey(publicKey)
Spark ドライバー ノードに SSH で接続します
-
クラスター構成ページで、[ 詳細オプション ] トグルをクリックします。
-
[SSH ] タブをクリックします。ドライバー ノードのホスト名をコピーします。
-
次のコマンドを実行して、ホスト名と秘密鍵のファイルパスを置き換えます。
Bashssh ubuntu@<hostname> -p 2200 -i <private-key-file-path>
Spark ワーカー ノードへの SSH 接続
ワーカーノードに SSH 接続するには、ドライバーノードに SSH 接続するのと同じ方法を使用します。
-
クラスターの詳細ページで、[ Spark クラスター UI - マスター ] タブをクリックします。
-
ワーカー テーブルで、SSH 接続するワーカーをクリックします。 「ホスト名」フィールドをコピーします。

クラスター ログ配信
クラスターを作成するときに、 Spark ドライバーノード、ワーカーノード、およびイベントのログを配信する場所を指定できます。 ログは、選択した宛先に 5 分ごとに配信されます。 クラスターが終了すると、 Databricks は、クラスターが終了するまでに生成されたすべてのログを配信することを保証します。
ログの保存先は、クラスター ID によって異なります。 指定した宛先が
dbfs:/cluster-log-delivery、 0630-191345-leap375 のクラスターログは
dbfs:/cluster-log-delivery/0630-191345-leap375。
ログの配信場所を設定するには、以下の手順に従ってください。
-
クラスター構成ページで、[ 詳細オプション ] トグルをクリックします。
-
[ ロギング ] タブをクリックします。
-
宛先タイプを選択します。
-
クラスター ログ パスを入力します。
S3 バケットの送信先
S3宛先を選択する場合は、バケットにアクセスできるインスタンスプロファイルを使用してクラスターを構成する必要があります。このインスタンスプロファイルには、 PutObject と PutObjectAcl の両方のアクセス許可が必要です。 インスタンスプロファイルの例
あなたの便宜のために含まれています。 インスタンスプロファイルの設定方法については 、「チュートリアル: インスタンスプロファイルを使用した S3 アクセスの設定 」を参照してください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["s3:ListBucket"],
"Resource": ["arn:aws:s3:::<my-s3-bucket>"]
},
{
"Effect": "Allow",
"Action": ["s3:PutObject", "s3:PutObjectAcl", "s3:GetObject", "s3:DeleteObject"],
"Resource": ["arn:aws:s3:::<my-s3-bucket>/*"]
}
]
}
この機能は、REST APIでも使用できます。クラスターAPIを参照してください。
initスクリプト
クラスターノードの初期化(initスクリプト)は、Sparkドライバまたはワーカー が起動する 前の 各クラスターノードの起動中に実行されるシェルスクリプトです。JVMinitスクリプトを使用して、 Databricks ランタイムに含まれていないパッケージとライブラリをインストールしたり、 JVM システムクラスパスを変更したり、 JVMが使用するシステムプロパティと環境変数を設定したり、 Spark 構成パラメーターを変更したりできます。
initスクリプトをクラスターにアタッチするには、 Advanced Options セクションを展開し、 initスクリプト タブをクリックします。
詳細な手順については、 initスクリプトとはを参照してください。