宣言型自動化バンドルとは何ですか?
宣言型自動化バンドル(旧称:Databricksアセットバンドル)は、データおよびAIプロジェクトにおいて、ソース管理、コードレビュー、テスト、継続的インテグレーションおよびデリバリー(CI/CD)などのソフトウェアエンジニアリングのベストプラクティスの導入を促進するためのツールです。バンドルを使用すると、プロジェクトのソース ファイルと一緒にメタデータを含める方法が提供され、ジョブやパイプラインなどのDatabricksリソースをソース ファイルとして記述することが可能になります。 最終的に、バンドルとはプロジェクトの構造、テスト方法、デプロイ方法などを含めた、プロジェクトのエンドツーエンドの定義です。これにより、開発が活発に行われている段階でのプロジェクトにおける共同作業が容易になります。
バンドルプロジェクトのソースファイルとメタデータのコレクションは、単一のバンドルとしてターゲット環境にデプロイされます。バンドルには、次のパーツが含まれています。
- 必要なクラウドインフラストラクチャおよびワークスペースの構成
- ビジネスロジックを含むノートブックやPythonファイルなどのソースファイル
- Lakeflow Jobs、LakeFlow Pipelines、ダッシュボード、Model Serving Endpoint、MLflow エクスペリメント、MLflow 登録モデルなどのDatabricks リソースの定義と設定です。
- ユニットテストと統合テスト
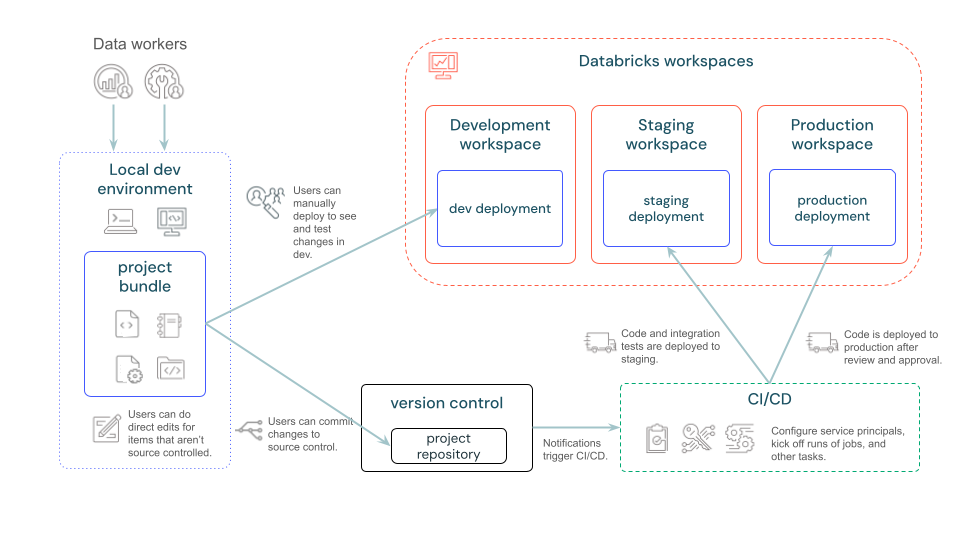
次の図は、バンドルを使用した開発およびCI/CDパイプラインの概要を示します。
ビデオウォークスルー
このビデオでは、宣言型自動化バンドルの操作方法を解説します(5分)。
バンドルはいつ使用すればよいですか?
宣言型自動化バンドルは、 Databricksプロジェクトを管理するためのInfrastructure-as-Code ( IaC )のアプローチです。 複数の貢献者と自動化が不可欠であり、継続的インテグレーションとデプロイメント(CI/CD)が必須となるような複雑なプロジェクトを管理したい場合に、これらを使用してください。バンドルは、ソースコードと並行して作成・管理するYAMLテンプレートとファイルを通じて定義および管理されるため、IaCが適切なアプローチとなるシナリオによく適合します。
バンドルの理想的なシナリオには、以下のものがあります。
- チームベースの環境で、データ、アナリティクス、機械学習の各プロジェクトを構築します。バンドルを使用すると、さまざまなソースファイルを効率的に整理し管理できるようになります。これにより、コラボレーションがスムーズになり、プロセスも合理化されます。
- 機械学習の問題を迅速に反復処理します。本番運用のベストプラクティスを最初から採用している機械学習プロジェクトを使用して、機械学習のパイプラインリソース(トレーニングやバッチ推論のジョブなど)を管理します。
- デフォルトの権限、サービスプリンシパル、CI/CD構成を含むカスタムバンドルテンプレートを作成することで、新しいプロジェクト向けに組織としての基準を設定できます。
- 規制順守:規制順守に細心の注意を払う必要のある業界でも、バンドルを活用することで、コードやインフラストラクチャ作業のバージョン管理がしやすくなります。これは適切なガバナンスに役立つだけでなく、必要なコンプライアンス基準を確実に満たす上でも効果的です。
バンドルはどのように機能しますか?
バンドルメタデータは、Databricksプロジェクトのアーティファクト、リソース、構成を指定するYAMLファイルを使用して定義されます。その後、Databricks CLIでこれらのバンドルYAMLファイルを使用してバンドルを検証、デプロイ、実行することができます。バンドルプロジェクトは、IDE、ターミナル、またはDatabricks内から直接実行することができます。
バンドルは、手動で作成することも、テンプレートに基づいて作成することもできます。Databricks CLI には、単純なユースケース用のデフォルトのテンプレートが用意されていますが、より具体的なジョブや複雑なジョブの場合は、カスタムバンドルテンプレートを作成して、チームのベストプラクティスを実装し、共通の構成の一貫性を保つことができます。
宣言型自動化バンドルを表現するために使用される構成 YAML の詳細については、 「宣言型自動化バンドルの構成」を参照してください。
バンドルを使用するには何をインストールする必要がありますか?
宣言型自動化バンドルは、Databricks CLIの機能の一つです。ローカルでバンドルを作成し、Databricks CLI を使用してバンドルをリモートの Databricks ワークスペースにデプロイし、コマンドラインからそれらのワークスペースでバンドルのワークフローを実行します。
ワークスペースでバンドルを使用するだけの場合は、Databricks CLI をインストールする必要はありません。「ワークスペースでバンドルを共同作業する」を参照してください。
Databricks ワークスペースでバンドルをビルド、デプロイ、実行するには:
-
リモート Databricks ワークスペースでは、ワークスペース ファイルが有効になっている必要があります。 Databricks Runtime バージョン 11.3 LTS 以降を使用している場合、この機能はデフォルトによって有効になります。
-
Databricks CLI バージョン v0.218.0 以降をインストールする必要があります。Databricks CLI をインストールまたは更新するには、「 Databricks CLI のインストールまたは更新」を参照してください。
Databricks では、 新しいバンドル機能を利用するために、最新バージョンの CLI に定期的に更新することをお勧めします。インストールされている Databricks CLI のバージョンを確認するには、次のコマンドを実行します。
shdatabricks --version -
DatabricksワークスペースにアクセスするようにDatabricks CLIを構成しました。 Databricks では、ワークスペースへのアクセスを構成する際に、OAuth ユーザー対マシン (U2M) 認証を使用することを推奨しています。これについては、 「ワークスペースへのアクセスを構成する」で説明しています。その他の認証方法については、「宣言型自動化バンドルの認証」を参照してください。
バンドルの使用を開始するにはどうすればよいですか?
ローカル バンドル開発を開始する最も早い方法は、バンドル プロジェクト テンプレートを使用することです。Databricks CLI のバンドル init コマンドを使用して、最初のバンドル プロジェクトを作成します。このコマンドは、 Databricksが提供するバンドル テンプレートの選択肢を提示し、プロジェクト変数を初期化するための一連の質問を行います。
databricks bundle init
バンドルの作成は、 バンドルのライフサイクルの最初のステップです。次に、 databricks.yml と Resource の構成ファイルでバンドル設定とリソースを定義して、バンドルを開発します。 最後に、バンドル を検証し て デプロイ し、 ワークフローを実行します。
バンドル設定例は、 GitHub のバンドル設定例 と バンドル例リポジトリにあります。
次のステップ
- ノートブックをDatabricksワークスペースにデプロイするバンドルを作成し、その後、ノートブックをDatabricksジョブまたはパイプラインにデプロイする実行を作成します。 「宣言型自動化バンドルを使用したジョブの開発」および「宣言型自動化バンドルを使用したパイプラインの開発」を参照してください。
- MLOpsスタックをデプロイして実行するバンドルを作成します。MLOpsスタック向けの宣言型自動化バンドルを参照してください。
- GitHub の CI/CD (継続的インテグレーション/継続的デプロイ) ワークフローの一部としてバンドル デプロイを開始します。「パイプラインの更新を実行するバンドルを使用した CI/CD ワークフローの実行」を参照してください。
- Python wheelファイルをビルド、デプロイ、および呼び出すバンドルを作成します。 宣言型自動化バンドルを使用してPython wheelファイルを構築する方法については、こちらをご覧ください。
- ワークスペース内のジョブまたはその他のリソースの構成をバンドルで生成し、それをワークスペース内のリソースにバインドして、構成の同期を維持します。「 databricks バンドルの生成 」と「 databricks バンドルのデプロイ バインド」を参照してください。
- ワークスペースにバンドルを作成してデプロイします。「ワークスペースでのバンドルでの共同作業」を参照してください。
- あなたや他のユーザーがバンドルを作成する際に使用できるカスタムテンプレートを作成します。カスタムテンプレートには、デフォルトの権限、サービスプリンシパル、およびカスタムのCI/CD構成が含まれる場合があります。宣言型自動化バンドルのプロジェクトテンプレートを参照してください。
- dbxから宣言型自動化バンドルへ移行します。dbx からバンドルへの移行を参照してください。
- 宣言型自動化バンドル向けにリリースされた最新の主要新機能をご覧ください。宣言型自動化バンドル機能のリリースノートを参照してください。