R のための Databricks Connect
この記事では sparklyr Databricks Runtime 13.0 以降の Databricks Connect との統合について説明します。 この統合は Databricks によって提供されておらず、Databricks によって直接サポートされていません。
ご不明な点がございましたら、 Posit コミュニティをご覧ください。
問題を報告するには、GitHub の sparklyr リポジトリの [問題] セクションに移動します。
詳細については、sparklyr ドキュメントのDatabricks Connect v2 を参照してください。
Databricks ConnectIDEsRStudioを使用すると、 Desktop、ノートブック サーバー、その他のカスタム アプリケーションなどの一般的なDatabricks を クラスターに接続できます。「Databricks Connect とは」を参照してください。
Spark MLlib は RDD を使用するのに対し、Databricks Connect は DataFrame API のみをサポートしているため、Databricks Connect は Apache Spark MLlib との互換性に制限があります。Sparklyr の Spark MLlib 関数をすべて使用するには、Databricks ノートブックまたは brickster パッケージの db_repl 関数を使用します。
この記事では、 sparklyr と RStudio Desktop を使用して Databricks Connect for R をすぐに使い始める方法について説明します。
- Databricks Connect for Python については、「 Databricks Connect for Python」を参照してください。
- Databricks Connect for Scala については、「 Databricks Connect for Scala」を参照してください。
チュートリアル
次のチュートリアルでは、 でプロジェクトを作成し、RStudio Databricks ConnectDatabricks Runtime13.3LTS 以降の をインストールして構成し、 から ワークスペースのコンピュートで簡単なコードを実行します。DatabricksRStudioこのチュートリアルの補足情報については、Spark Connect の「Databricks Connect」セクションと、sparklyr Web サイトの Databricks Connect v2 を参照してください。
このチュートリアルでは、RStudio Desktop と Python 3.10 を使用します。まだインストールしていない場合は、 R と RStudio Desktop と Python 3.10 をインストールします。
必要条件
このチュートリアルを完了するには、以下の条件を満たす必要があります。
- ターゲットDatabricksワークスペースとクラスターは、Databricks Connectのコンピュート構成の要件を満たしている必要があります。
- クラスター ID が使用可能である必要があります。 クラスター ID を取得するには、ワークスペースでサイドバーの [コンピュート ] をクリックし、クラスターの名前をクリックします。 Web ブラウザーのアドレス バーで、URL の
clustersとconfigurationの間の文字列をコピーします。
ステップ 1: 個人用アクセス トークンを作成する
Databricks Connect for R 認証では、現在、Databricks 個人用アクセス トークンのみがサポートされています。
このチュートリアルでは、Databricks ワークスペースでの認証に Databricks 個人用アクセス トークン認証 を使用します。
Databricks の個人用アクセストークンが既にある場合は、「ステップ 2」に進んでください。Databricks 個人用アクセストークンが既にあるかどうかわからない場合は、ユーザー アカウント内の他の Databricks 個人用アクセストークンに影響を与えることなく、このステップに従うことができます。
個人的なアクセストークンを作成するには、 「ワークスペース ユーザー向けの個人的なアクセストークンを作成する」のステップに従います。
ステップ 2: プロジェクトを作成する
- RStudio Desktop を起動します。
- メインメニューで、 [ファイル] > [新しいプロジェクト] をクリックします。
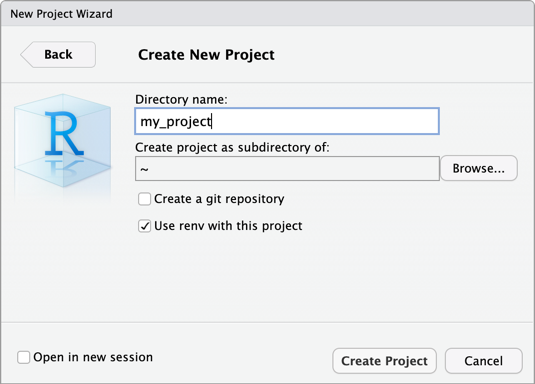
- 新しいディレクトリを選択してください 。
- [新しいプロジェクト ] を選択します。
- [ ディレクトリ名 ] と [ プロジェクトをサブディレクトリとして作成] に、新しいプロジェクト ディレクトリの名前と、この新しいプロジェクト ディレクトリを作成する場所を入力します。
- このプロジェクトで「renvを使う 」を選択してください。
renvパッケージの更新バージョンをインストールするように求められたら、「 はい 」をクリックしてください。 - [プロジェクトの作成 ] をクリックします。
手順 3: Databricks Connect パッケージとその他の依存関係を追加する
-
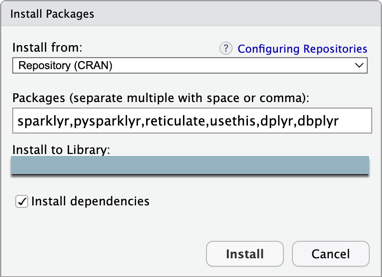
RStudio Desktop のメインメニューで、「 ツール」>「パッケージのインストール」 をクリックします。
-
[ インストール元 ] は [リポジトリ (CRAN)] のままにします。
-
[パッケージ] には、Databricks Connect パッケージとこのチュートリアルの前提条件であるパッケージの次の一覧を入力します。
sparklyr,pysparklyr,reticulate,usethis,dplyr,dbplyr -
[ ライブラリへのインストール ] は R 仮想環境に設定したままにします。
-
「 依存関係をインストール 」が選択されていることを確認してください。
-
[ インストール ] をクリックします。
-
コンソール ビュー ( [表示] > [フォーカスをコンソールに移動 ]) でインストールを続行するように求められたら、「
Y」と入力します。sparklyrパッケージとpysparklyrパッケージ、およびそれらの依存関係は、R 仮想環境にインストールされます。 -
[コンソール ] ウィンドウで、
reticulateを使用して次のコマンドを実行して Python をインストールします。(Databricks Connect for R を使用するには、最初にreticulateと Python をインストールする必要があります。次のコマンドで、3.10Pythonを、Databricks クラスターにインストールされている バージョンのメジャー バージョンとマイナー バージョンに置き換えます。このメジャー バージョンとマイナー バージョンを見つけるには、リリースノートの「システム環境」セクションで、 リリースノートのバージョンと互換性 でクラスターのDatabricks Runtime Databricks Runtimeバージョンを確認してください。reticulate::install_python(version = "3.10") -
[コンソール ] ウィンドウで、次のコマンドを実行して Databricks Connect パッケージをインストールします。次のコマンドで、
13.3Databricks RuntimeをDatabricks クラスターにインストールされている バージョンに置き換えます。このバージョンを見つけるには、 Databricks ワークスペースのクラスターの詳細ページの [構成 ] タブで、[ Databricks Runtime バージョン ] ボックスを確認します。pysparklyr::install_databricks(version = "13.3")クラスターの Databricks Runtime バージョンがわからない場合、または検索したくない場合は、代わりに次のコマンドを実行すると、クラスター
pysparklyrクエリを実行して、使用する正しい Databricks Runtime バージョンが決定されます。pysparklyr::install_databricks(cluster_id = "<cluster-id>")指定したバージョンと同じ Databricks Runtime バージョンの別のクラスターにプロジェクトを後で接続する場合、
pysparklyr同じ Python 環境を使用します。 新しいクラスターの Databricks Runtime バージョンが異なる場合は、新しい Databricks Runtime バージョンまたはクラスター ID を使用してpysparklyr::install_databricksコマンドを再度実行する必要があります。
ステップ 4: ワークスペース URL、アクセス トークン、クラスター ID の環境変数を設定する
Databricks では、Databricks ワークスペース URL、個人用アクセス トークン、クラスター ID などの機密性の高い値や変化する値を R スクリプトにハードコーディングDatabricksDatabricksお勧めしません。代わりに、これらの値をローカル環境変数などに個別に格納します。このチュートリアルでは、RStudio Desktop の組み込みサポートを使用して、環境変数を .Renviron ファイルに格納します。
-
環境変数を格納する
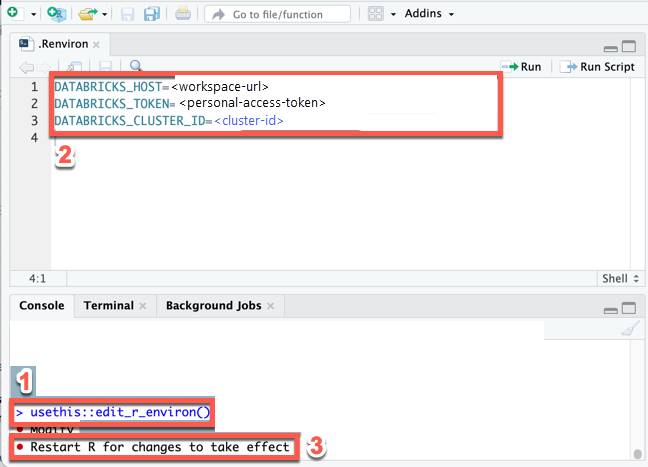
.Renvironファイルを作成し(このファイルがまだ存在しない場合)、このファイルを編集用に開きます。RStudioデスクトップ コンソール で、次のコマンドを実行します。usethis::edit_r_environ() -
表示される
.Renvironファイル( [表示]>[フォーカスをソースに移動 ])に、次の内容を入力します。 このコンテンツでは、次のプレースホルダーを置き換えます。<workspace-url>をワークスペース インスタンスの URL に置き換えます (例:https://dbc-a1b2345c-d6e7.cloud.databricks.com)。<personal-access-token>をステップ 1 の Databricks 個人用アクセストークンに置き換えます。<cluster-id>を、このチュートリアルの要件のクラスター ID に置き換えます。
DATABRICKS_HOST=<workspace-url>
DATABRICKS_TOKEN=<personal-access-token>
DATABRICKS_CLUSTER_ID=<cluster-id> -
.Renvironファイルを保存します。 -
環境変数を R: に読み込みます。メイン メニューで、[セッション] > [R の再起動 ] をクリックします。
ステップ 5: コードを追加する
-
RStudio Desktop のメイン メニューで、[ ファイル] > [新しいファイル] > R スクリプト ] をクリックします。
-
次のコードをファイルに入力し、ファイルを次のように保存します ( [ファイル] > [保存 ])
demo.R:Rlibrary(sparklyr)
library(dplyr)
library(dbplyr)
sc <- sparklyr::spark_connect(
master = Sys.getenv("DATABRICKS_HOST"),
cluster_id = Sys.getenv("DATABRICKS_CLUSTER_ID"),
token = Sys.getenv("DATABRICKS_TOKEN"),
method = "databricks_connect",
envname = "r-reticulate"
)
trips <- dplyr::tbl(
sc,
dbplyr::in_catalog("samples", "nyctaxi", "trips")
)
print(trips, n = 5)
ステップ 6: コードを実行する
-
RStudio デスクトップで、
demo.Rファイルのツールバーで [ソース ] をクリックします。
-
コンソールには 、
tripsテーブルの最初の5行が表示されます。 -
「接続 」ビュー ( 「表示」>「接続の表示 」) では、使用可能なカタログ、スキーマ、表、およびビューを探索できます。
![プロジェクトの [接続] ビュー](/aws/ja/assets/images/connections-view-rstudio-accf8e4c09c5c46a695d63033d4fb515.png)
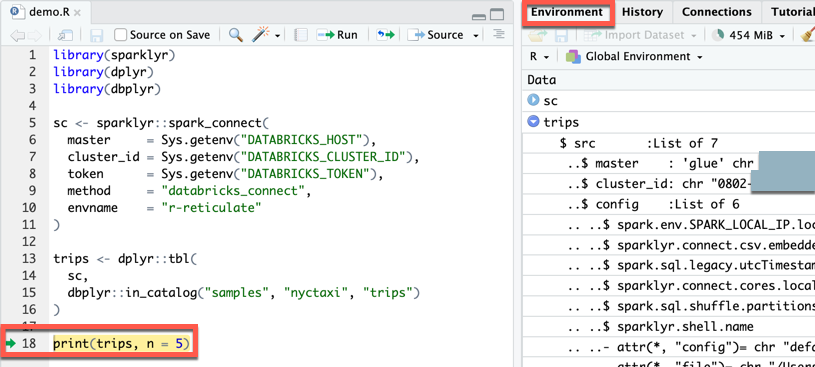
ステップ7: コードをデバッグします
demo.Rファイルで、[print(trips, n = 5)] の横にある余白をクリックしてブレークポイントを設定します。demo.Rファイルのツールバーで、「 ソース 」をクリックします。- コードの実行がブレークポイントで一時停止すると、 環境 ビュー ( 表示>環境の表示 ) で変数を検査できます。
- メイン メニューで、[ デバッグ] > [続行 ] をクリックします。
- コンソールには 、
tripsテーブルの最初の5行が表示されます。