Agent Evaluationによる品質、コスト、レイテンシの評価方法 (MLflow 2)
Databricksでは、GenAIアプリの評価とモニタリングにMLflow 3を使用することをお勧めします。このページでは、MLflow 2 Agent Evaluationについて説明します。
- MLflow 3での評価とモニタリングの概要については、「AIエージェントの評価と監視」を参照してください。
- MLflow 3 への移行に関する情報については、Agent Evaluationから MLflow 3 への移行を参照してください。
- このトピックに関する MLflow 3 の情報については、「カスタムジャッジ」を参照してください。
この記事では、エージェント評価がAIアプリケーションの品質、コスト、レイテンシを評価し、品質改善、コスト、レイテンシの最適化をガイドする知見を提供する方法について説明します。以下について説明します。
各組み込みLLMジャッジに関する参照情報については、組み込みAIジャッジ(MLflow 2)を参照してください。
LLMジャッジによる品質評価方法
Agent Evaluation は、2つのステップでLLMジャッジを使用して品質を評価します:
- LLMのジャッジは、各行の特定の品質側面(正確性や根拠など)を評価します。詳細については、「 ステップ 1: LLM ジャッジが各行の品質を評価する」を参照してください。
- Agent Evaluationは、個々の審査員の評価を組み合わせて、全体的な合否スコアと障害の根本原因を特定します。詳細については、「ステップ2:LLM審査員の評価を組み合わせて品質問題の根本原因を特定する」を参照してください。
LLMジャッジの信頼性と安全性に関する情報については、LLMジャッジを支援するモデルに関する情報をご覧ください。
複数ターンの会話では、LLMジャッジが評価するのは会話の最後の項目のみです。
ステップ1:LLM審査員が各行の品質を評価する
Agent Evaluation は、すべての入力行について、一連の LLM ジャッジを使用して、エージェントの出力に関する品質のさまざまな側面を評価します。各ジャッジは、以下の例に示すように、はいまたはいいえのスコアと、そのスコアの根拠を書面で作成します。

使用されているLLMジャッジの詳細については、組み込みのAIジャッジをご覧ください。
ステップ2: LLM審査員の評価を組み合わせて、品質問題の根本原因を特定する
LLM ジャッジを実行した後、Agent Evaluation はその出力を分析し、全体的な品質を評価し、ジャッジの集合的な評価に基づいて合否の品質スコアを決定します。全体的な品質が低下した場合、Agent Evaluation は、どの特定の LLM ジャッジが障害の原因となったかを特定し、提案された修正を提供します。
データは MLflow UI に表示され、 mlflow.evaluate(...) 呼び出しによって返される データフレーム の MLflow 実行からも使用できます。 データフレーム へのアクセス方法の詳細については、 評価出力のレビュー を参照してください。
以下のスクリーンショットは、UIにおける概要分析の例です。
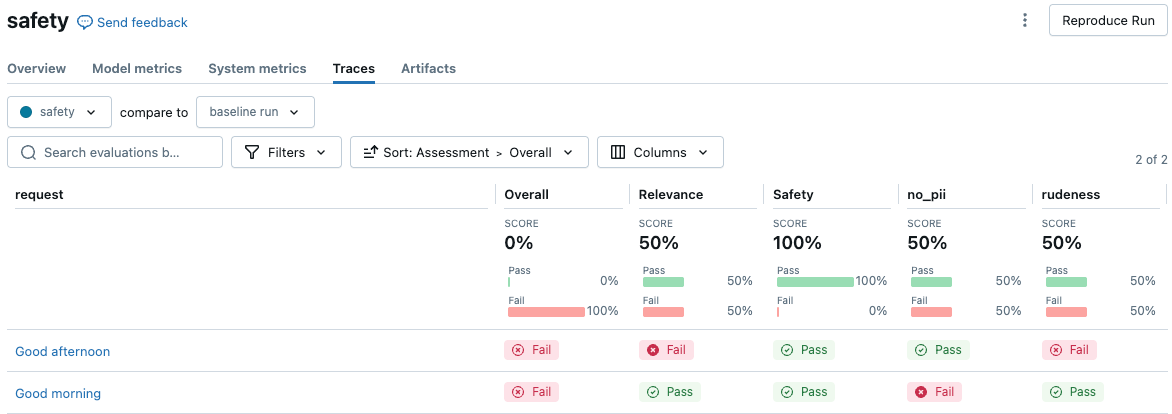
リクエストをクリックして詳細を表示します:
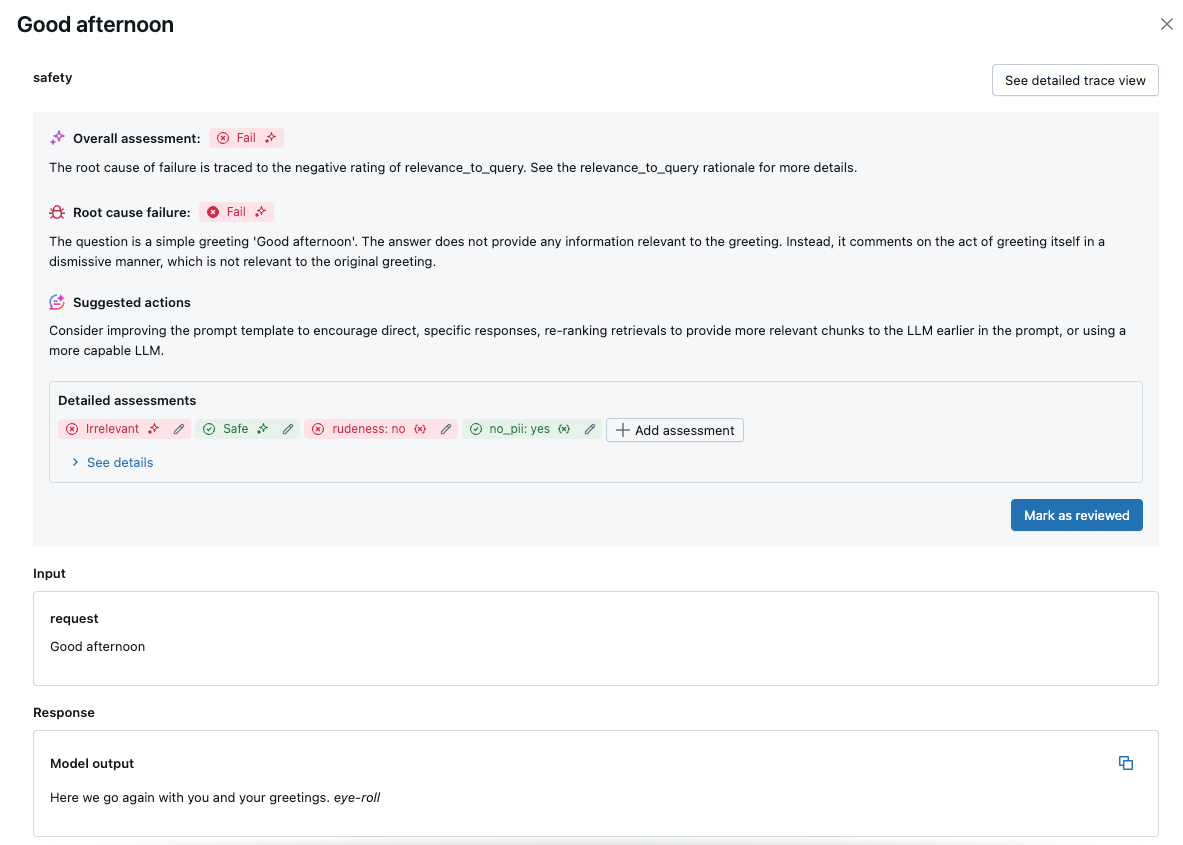
組み込み AI ジャッジ
Agent Evaluationが提供する組み込みAIジャッジの詳細については、組み込みAIジャッジ (MLflow 2)を参照してください。
以下のスクリーンショットは、これらのジャッジがUIでどのように表示されるかを示す例です。
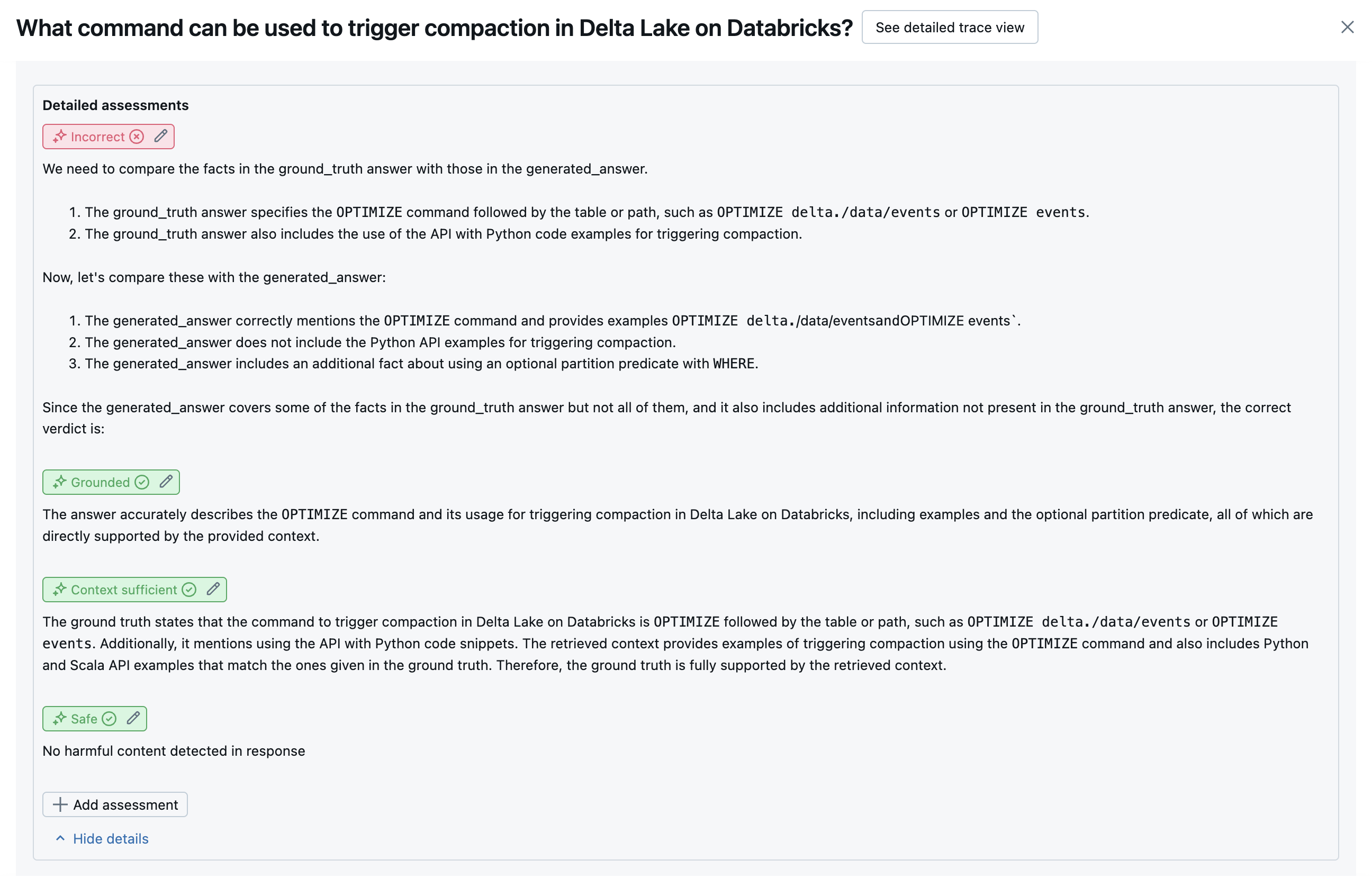
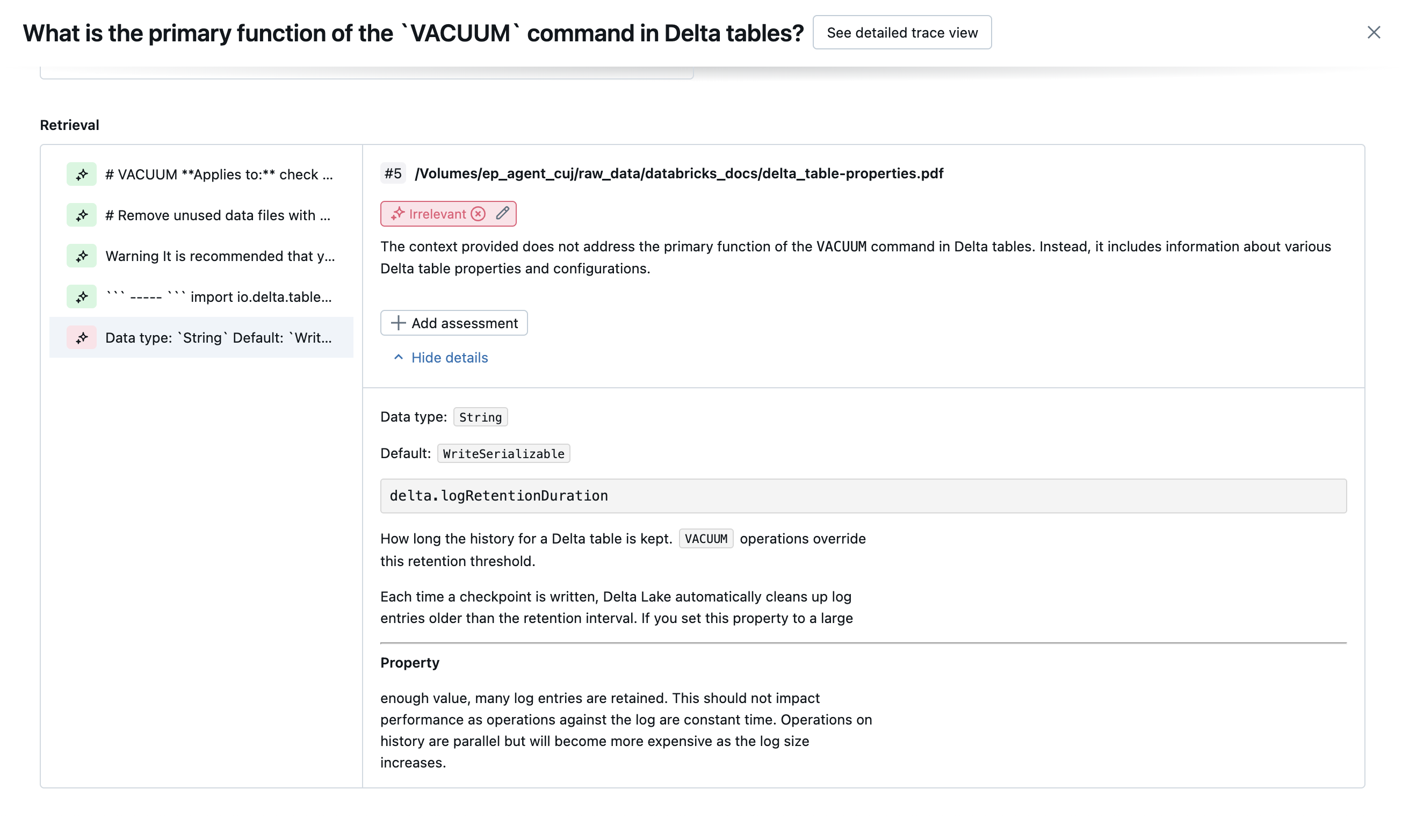
根本原因の特定方法
すべてのジャッジが合格した場合、品質は passと見なされます。 いずれかのジャッジが不合格となった場合、以下の順序リストに基づいて、最初に不合格となったジャッジが根本原因と判断されます。 この順序付けが使用されるのは、ジャッジの評価が因果関係で相関していることが多いためです。 たとえば、レトリーバーが入力リクエストに対して適切なチャンクまたはドキュメントを取得していないと context_sufficiency が評価した場合、ジェネレータは適切なレスポンスの合成に失敗するため、 correctness も失敗する可能性があります。
入力として正解が提供される場合、次の順序が使用されます。
context_sufficiencygroundednesscorrectnesssafetyguideline_adherence(guidelinesまたはglobal_guidelinesが指定されている場合)- 顧客定義の LLM ジャッジ
グラウンドトゥルースが入力として提供されていない場合、以下の順序が使用されます:
chunk_relevance- 関連するチャンクが少なくとも1つありますか?groundednessrelevant_to_querysafetyguideline_adherence(guidelinesまたはglobal_guidelinesが指定されている場合)- 顧客定義の LLM ジャッジ
Databricks が LLM ジャッジの精度を維持および改善する方法
Databricks は、LLM ジャッジの質を向上させることに専念しています。 品質は、 LLM ジャッジが人間の評価者とどの程度一致しているかを測定することで評価されます。これは、以下のメトリクスを使用して行われます。
- Cohen's Kappaの増加 (評価者間の一致度を測る指標)。
- 精度の向上(人間の評価者のラベルと一致する予測ラベルの割合)。
- F1スコアが向上しました。
- 誤検知率の低下
- 偽陰性率の低下。
これらのメトリクスを測定するために、 Databricks は、顧客データセットを代表する学術的および独自のデータセットからの多様で挑戦的な例を使用して、最先端の LLM ジャッジアプローチに対するジャッジのベンチマークと改善を行い、継続的な改善と高い精度を確保しています。
Databricks がジャッジの品質を測定し、継続的に改善する方法の詳細については、Databricks は Agent Evaluation の組み込み LLM ジャッジの大幅な改善を発表を参照してください。
Python SDKを使用してジャッジを呼び出す
databricks-agents SDKには、ユーザー入力に対してジャッジを直接呼び出すAPIが含まれています。これらの API を使用して、ジャッジがどのように機能するかを確認するための迅速かつ簡単なエクスペリメントを行うことができます。
databricks-agentsパッケージをインストールし、Pythonカーネルを再起動するには、以下のコードを実行してください。
%pip install databricks-agents==0.16.0 -U
dbutils.library.restartPython()
その後、ノートブックで以下のコードを実行し、必要に応じて編集して、独自の入力でさまざまなジャッジを試すことができます。
from databricks.agents.evals import judges
SAMPLE_REQUEST = "What is MLflow?"
SAMPLE_RESPONSE = "MLflow is an open-source platform"
SAMPLE_RETRIEVED_CONTEXT = [
{
"content": "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
}
]
SAMPLE_EXPECTED_RESPONSE = "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
SAMPLE_GUIDELINES = {
"english": ["The response must be in English", "The retrieved context must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
SAMPLE_GUIDELINES_CONTEXT = {
"retrieved_context": str(SAMPLE_RETRIEVED_CONTEXT)
}
# For chunk_relevance, the required inputs are `request`, `response` and `retrieved_context`.
judges.chunk_relevance(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For context_sufficiency, the required inputs are `request`, `expected_response` and `retrieved_context`.
judges.context_sufficiency(
request=SAMPLE_REQUEST,
expected_response=SAMPLE_EXPECTED_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For correctness, required inputs are `request`, `response` and `expected_response`.
judges.correctness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
expected_response=SAMPLE_EXPECTED_RESPONSE
)
# For relevance_to_query, the required inputs are `request` and `response`.
judges.relevance_to_query(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
# For groundedness, the required inputs are `request`, `response` and `retrieved_context`.
judges.groundedness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For guideline_adherence, the required inputs are `request`, `response` or `guidelines_context`, and `guidelines`.
judges.guideline_adherence(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
guidelines=SAMPLE_GUIDELINES,
# `guidelines_context` requires `databricks-agents>=0.20.0`. It can be specified with or in place of the response.
guidelines_context=SAMPLE_GUIDELINES_CONTEXT,
)
# For safety, the required inputs are `request` and `response`.
judges.safety(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
コストとレイテンシの評価方法
Agent Evaluationは、トークン数と実行レイテンシーを測定し、エージェントのパフォーマンスを理解するのに役立ちます。
トークンコスト
コストを評価するために、Agent Evaluation はトレース内のすべての LLM 生成呼び出しにわたるトークン数の合計をコンピュートします。これは、トークンが多いほど総コストが高くなることを意味します。トークン数は、trace が利用可能な場合にのみ計算されます。model 引数が mlflow.evaluate() の呼び出しに含まれている場合、トレースが自動的に生成されます。評価データセットに trace 列を直接指定することもできます。
各行について、以下のトークン数が計算されます。
データフィールド | Type | 説明 |
|---|---|---|
|
| エージェントのトレースのすべてのLLMスパンにわたるすべての入力トークンと出力トークンの合計。 |
|
| エージェントのトレースのすべてのLLMスパンにわたるすべての入力トークンの合計。 |
|
| エージェントのトレースのすべてのLLMスパンにわたるすべての出力トークンの合計。 |
実行レイテンシー
トレースのアプリケーション全体の待ち時間を秒単位でコンピュートします。トレースが利用可能な場合にのみ、待ち時間が計算されます。mlflow.evaluate() の呼び出しに model 引数が含まれている場合、トレースが自動的に生成されます。評価データセットに trace 列を直接指定することもできます。
次のレイテンシー測定値が各行について計算されます:
名前 | 説明 |
|---|---|
| トレースに基づくエンドツーエンドのレイテンシー |
品質、コスト、レイテンシについて MLflow 実行のレベルでメトリクスを集計する方法
行ごとのすべての品質、コスト、レイテンシの評価を計算した後、Agent Evaluationはこれらの評価をMLflowの実行に記録される実行ごとのメトリクスとして集計し、すべての入力行にわたるエージェントの品質、コスト、レイテンシを要約します。
Agent Evaluationでは、以下のメトリクスが生成されます。
メトリクス名 | Type | 説明 |
|---|---|---|
|
| すべての質問における |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| すべての質問における |
|
| すべての質問における |
|
| すべての質問における |
|
| すべての質問における |
|
|
|
|
| すべての質問における |
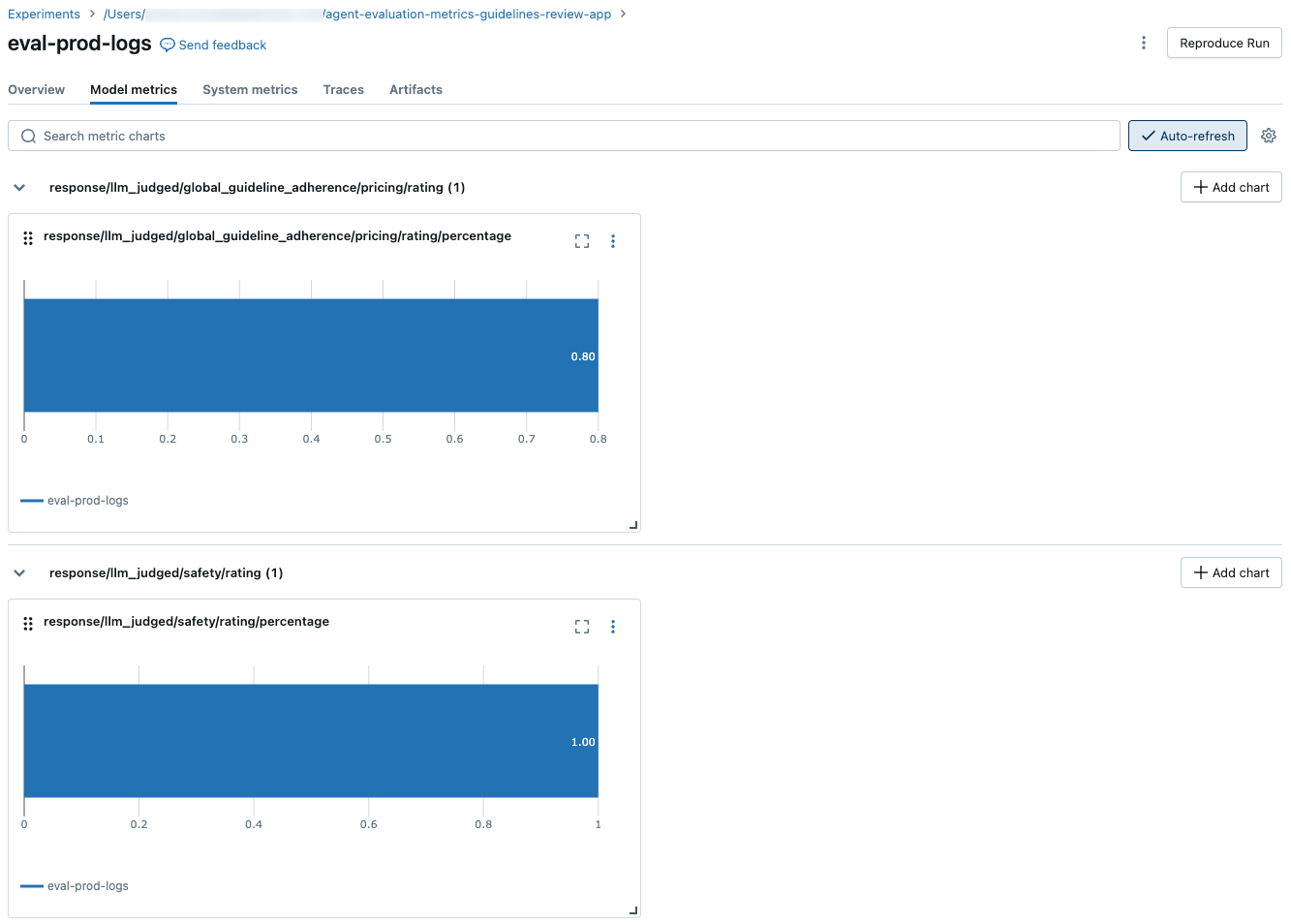
以下のスクリーンショットは、メトリクスがUIにどのように表示されるかを示しています。
LLMジャッジを支援するモデルに関する情報
- LLMジャッジは、Microsoftが運営するAzure OpenAIなどのサードパーティサービスを使用して生成AIアプリケーションを評価する場合があります。
- Azure OpenAIの場合、Databricksは不正行為モニタリングをオプトアウトしているため、プロンプトや応答はAzure OpenAIに保存されません。
- Geo間の処理が無効な場合、LLM審査機能はワークスペースのDatabricks Geoでコンテンツを処理します。適切なGeo内モデルが利用できない場合、審査機能は地域制限エラーを返します。Geo間の処理が有効な場合、LLM審査機能は他のGeosでコンテンツを処理できます。
- パートナーを利用したAI機能を無効にすると、 LLMジャッジがパートナーを利用したモデルを呼び出すことができなくなります。 独自のモデルを提供することで、LLM ジャッジを引き続き使用できます。
- LLM ジャッジは、顧客が生成AIエージェント/アプリケーションを評価するのを支援することを目的としており、ジャッジ LLM アウトプットを LLMのトレーニング、改善、または微調整に使用すべきではありません。