AI Searchエンドポイントとインデックスを作成
AI Searchインデックスは、Deltaテーブルに対するリアルタイムの類似性検索を提供し、AI Searchエンドポイントはクエリ用にそれらのインデックスを提供します。この記事では、両方を作成する方法について説明します。AI Search の概要については、Databricks AI Search を参照してください。
UI、Python SDK 、またはREST API を使用して、AI SearchエンドポイントやAI Searchインデックスなどの AI Search コンポーネントを作成および管理できます。
たとえば、AI Search エンドポイントを作成およびクエリする方法を説明するノートブックについては、「AI Search サンプルノートブック」を参照してください。リファレンス情報については、 Python SDK リファレンスを参照してください。
Databricks AI Search(旧 Databricks ベクトル検索)でした。
要件
- Unity Catalog対応ワークスペースであること。
- サーバレス コンピュートが有効になっていること。 手順については、 サーバレス コンピュートへの接続を参照してください。
- 標準エンドポイントの場合、ソース テーブルでチェンジデータフィードが有効になっている必要があります。Databricksでのチェンジデータフィードの使用 を参照してください。
- AI Searchインデックスを作成するには、インデックスを作成するカタログスキーマに対するCREATE TABLE権限が必要です。
- 別のユーザーが所有するインデックスをクエリするには、追加の権限が必要です。「AI Searchインデックスをクエリする方法」を参照してください。
AI Searchエンドポイントを作成および管理するためのアクセス許可は、アクセス制御リストを使用して構成されます。AI 検索エンドポイント ACLを参照してください。
インストール
AI Search SDK を使用するには、ノートブックにインストールする必要があります。パッケージをインストールするには、次のコードを使用します。
%pip install databricks-ai-search
dbutils.library.restartPython()
次に、AISearchClientをインポートするには、次のコマンドを使用してください。
from databricks.ai_search.client import AISearchClient
認証に関する情報については、「データ保護と認証」を参照してください。
AI Searchエンドポイントを作成
Databricks UI、Python SDK、またはAPIを使用して、AI Searchエンドポイントを作成できます。
UIを使用してAI Searchエンドポイントを作成する
UI を使用して AI Search エンドポイントを作成するには、次のステップに従います。
-
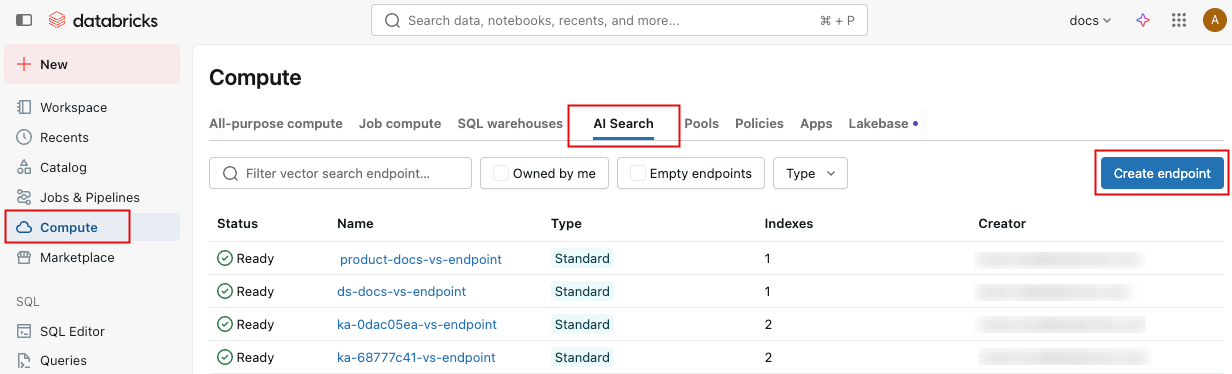
左側のサイドバーで、 コンピュート をクリックします。
-
「**AI Search**」タブをクリックし、「**エンドポイントを作成**」をクリックします。
-
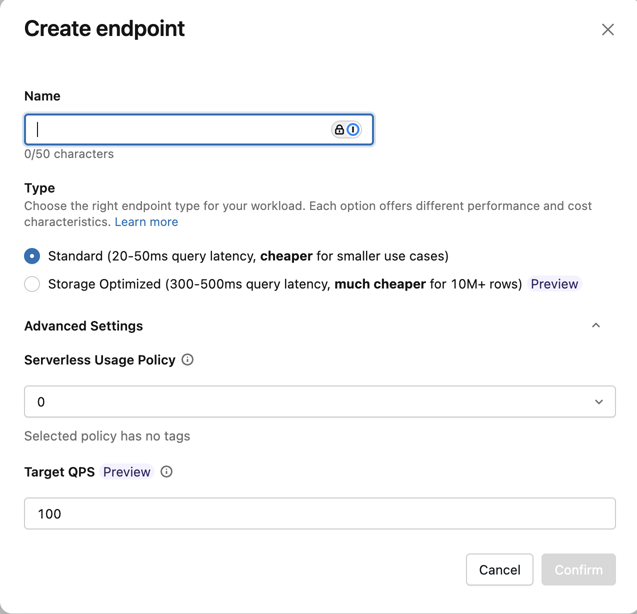
エンドポイントの作成フォーム が開きます。このエンドポイントの名前を入力します。
-
タイプ フィールドで、 標準 または ストレージ最適化 を選択します。エンドポイントのオプションを参照してください。
-
(オプション) 詳細設定 で、使用ポリシーを選択します。AI 検索使用ポリシーをご覧ください。
-
確認 をクリックします。
Python SDKを使用して、AI Searchエンドポイントを作成する
次の例では、 create_endpoint() SDK 関数を使用して AI Search エンドポイントを作成します。
# The following line automatically generates a PAT Token for authentication
client = AISearchClient()
# The following line uses the service principal token for authentication
# client = AISearchClient(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD" # or "STORAGE_OPTIMIZED"
)
REST APIを使用してAI Searchエンドポイントを作成する
REST API リファレンスドキュメント: POST /api/2.0/vector-search/endpointsを参照してください。
宣言型オートメーションバンドルを使用してベクトル検索エンドポイントを作成する
宣言型オートメーションバンドル内でベクトル検索エンドポイントをリソースとして定義し、ジョブ、パイプライン、その他のワークスペースアセットとともにコードとして管理できます。バンドルの概要については、宣言型オートメーションバンドルとはをご覧ください。
バンドルでベクトル検索エンドポイントを定義できるのは、直接デプロイエンジンのみであり、Databricks CLIバージョン1.1.0が必要です。またはそれ以降。
次の例では、標準のベクトル検索エンドポイントを定義します。
resources:
vector_search_endpoints:
my_vector_search_endpoint:
name: my_vector_search_endpoint
endpoint_type: STANDARD
endpoint_type、budget_policy_id、min_qps、およびpermissionsを含むサポートされている全フィールドのリストについては、vector_search_endpointをご覧ください。
ハイスループットのワークロード向けに、ターゲットQPSを設定してエンドポイントを作成します。
ハイスループットのワークロード向けに、ターゲットQPSのエンドポイントを作成できます。この機能は標準エンドポイントでのみ利用できます。
ターゲットQPSを設定するには、target_qpsパラメーターを使用します。「高 QPS でのエンドポイントスループットのスケーリング」を参照してください。
target_qps を設定すると、追加の容量がプロビジョニングされ、これによりEndpointのコストが増加します。実際のクエリートゥラフィックに関係なく、この追加容量に対して課金されます。throughputのスケーリングはベストエフォート型であり、保証されません。
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD",
target_qps=500, # target QPS for high-throughput workloads
)
既存のエンドポイントでターゲットQPSを変更するには、update_endpoint()を使用します。
from databricks.ai_search.client import AISearchClient
client = AISearchClient()
# Set or update target QPS
response = client.update_endpoint(name="vector_search_endpoint_name", target_qps=500)
# Check scaling status
scaling_info = response.get("endpoint", {}).get("scaling_info", {})
print(f"State: {scaling_info.get('state')}") # SCALING_CHANGE_IN_PROGRESS or SCALING_CHANGE_APPLIED
ターゲットQPSを更新した後、新しい構成を適用するためにインデックスを同期してください。
(オプション) 埋め込みモデルを提供するためのエンドポイントを作成して構成する
Databricksで埋め込みをコンピュートすることを選択した場合は、事前構成済みの基盤モデルAPIsエンドポイントを使用するか、選択した埋め込みモデルを提供するためのモデルサービングエンドポイントを作成できます。手順については、トークン単位の従量課金 基盤モデル APIs または 基盤モデルをサービングするエンドポイントの作成を参照してください。たとえば、ノートブックについては、 AI Search サンプル ノートブックを参照してください。
エンべディングエンドポイントを構成する場合、Databricks では、デフォルトの選択である Scale to zero を削除することをお勧めします。 エンドポイントの提供にはウォームアップに数分かかる場合があり、スケールダウンされたエンドポイントを持つインデックスに対する最初のクエリがタイムアウトする可能性があります。
エンベディングエンドポイントがデータセットに対して適切に構成されていない場合、AI Search インデックスの初期化がタイムアウトになる可能性があります。CPU エンドポイントは、小規模なデータセットとテストにのみ使用してください。大規模なデータセットの場合は、最適なパフォーマンスを得るために GPU エンドポイントを使用します。
AI Searchインデックスを作成
UI、Python SDK、またはREST APIを使用して、AI Searchインデックスを作成できます。UI は最もシンプルなアプローチです。
インデックスには2種類あります:
- Delta Sync Index は、ソースのDelta Tableと自動的に同期し、Delta Tableの基になるデータが変更されると、インデックスを自動的かつ段階的に更新します。
- Direct Vector Access Indexは、ベクトルとメタデータの直接読み取りと書き込みをサポートします。 ユーザーはREST APIまたはPython SDKを使用してこのテーブルを更新する必要があります。このタイプのインデックスはUIを使用して作成できません。REST API または SDK を使用する必要があります。
Delta 同期インデックスは以下の検索モードに対応しています。
- ベクトル検索 (ANN またはハイブリッド):埋め込み列が必要です。標準とストレージ最適化エンドポイントの両方をサポートしています。これらのインデックスに対するキーワード検索に
query_type="FULL_TEXT"を使うこともできます。 - 専用フルテキスト検索インデックス (ベータ版):キーワード検索のみを目的とし、埋め込み列なしで作成された Delta Sync インデックス。トリガー同期モードを使用するストレージ最適化エンドポイントでのみ利用可能です。全文検索インデックスの作成を参照してください。
列名 _id は予約されています。ソーステーブルに_idという名前の列がある場合、AI Searchインデックスを作成する前に名前を変更してください。
UIを使用したインデックスの作成
-
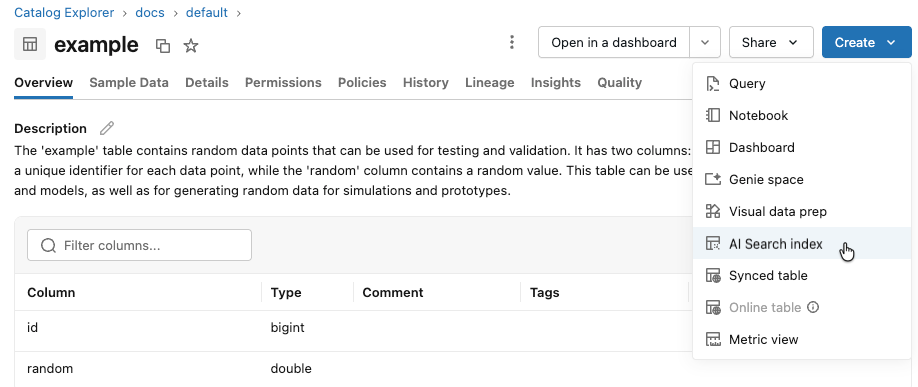
左のサイドバーで[ カタログ ] をクリックして、カタログエクスプローラーUIを開きます。
-
使用する Delta テーブルに移動します。
-
右上の 作成 ボタンをクリックし、ドロップダウンメニューから ベクトル検索インデックス を選択します。
-
ダイアログのセレクターを使用して、インデックスを設定してください。
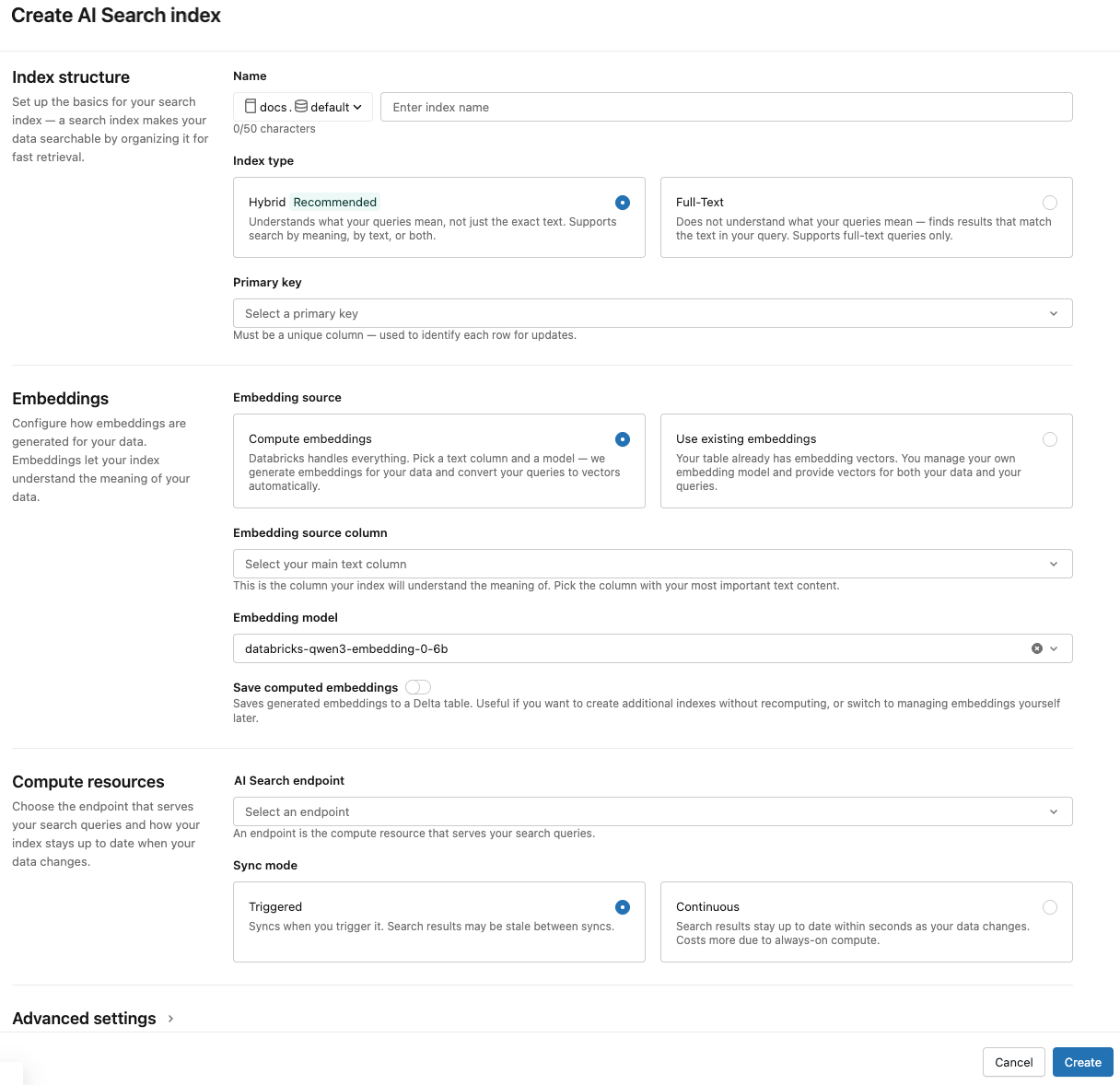
インデックス構造
名前 : Unity Catalog のオンライン テーブルに使用する名前。名前には3階層の名前空間が必要です、
<catalog>.<schema>.<name>。名前にスペース、ピリオド、スラッシュ、または制御文字を含めることはできません。インデックスタイプ :同じインデックスでセマンティック(ベクトル)検索とキーワード検索の両方をサポートするには、 ハイブリッド を選択します。埋め込みなしでキーワード検索のみを行うには、 全文 を選択してください。全文インデックスの要件については、全文検索インデックスの作成 (ベータ) を参照してください。
主キー :主キーとして使用する列。
エンベディング
エンべディングソース :Databricks でDeltaテーブル内のテキスト列のエンべディングをコンピュートするか( エンベディングの計算)、またはDeltaテーブルに事前コンピュートされたエンべディングが含まれるかどうか( 既存のエンべディングを使用 )を示します。
-
コンピュート埋め込み を選択した場合は、埋め込みコンピュートの列を選択します。Databricks が管理する埋め込みモデルがデフォルトで選択されています。別のモデルを使用するには、**高度な設定**を展開し、**埋め込みモデル**ドロップダウンから選択します。テキスト列のみがサポートされています。
-
標準エンドポイントを使用する本番運用アプリケーションの場合、Databricks は、プロビジョニング スループット サービング エンドポイントと共に基盤モデル
databricks-qwen3-embedding-0-6bを使用することをお勧めします。 -
Databricksがホストするモデルでストレージ最適化エンドポイントを使用する本番運用アプリケーションの場合は、埋め込みモデルエンドポイントとしてモデル名を直接使用します (例:
databricks-qwen3-embedding-0-6b)。ストレージ最適化エンドポイントは、取り込み時にai_queryをバッチ推論とともに使用し、埋め込みジョブに高いスループットを提供します。クエリにプロビジョン済みスループット エンドポイントを使用する場合、インデックス作成時にmodel_endpoint_name_for_queryフィールドで指定します。
-
-
「 既存の埋め込みを使用 」を選択した場合は、事前計算された埋め込みと埋め込みディメンションを含む列を選択します。事前計算された埋め込み列の形式は
array[float]である必要があります。ストレージ最適化エンドポイントの場合、埋め込みディメンションは 16 で均等に割り切れる必要があります。
コンピュート エンベディングを保存 : この設定を切り替えて、生成されたエンベディングを Unity Catalog テーブルに保存します。詳細については、「生成されたエンベディングテーブルを保存する」を参照してください。
コンピュートリソース
ベクトル検索エンドポイント : インデックスを保存するためのベクトル検索エンドポイントを選択します。
同期モード : 連続 は、インデックスを数秒の待機時間と同期させます。ただし、継続的な同期ストリーミングパイプラインを実行するためにコンピュートクラスターをプロビジョニングするため、コストが高くなります。
- 標準エンドポイントの場合、 連続 と トリガー の両方が増分更新を実行するため、最後の同期以降に変更されたデータのみが処理されます。
- ストレージ最適化エンドポイントの場合、同期ごとにインデックスが部分的に再構築されます。後続の同期で管理対象インデックスの場合、ソース行が変更されていない限り、生成された埋め込みは再利用され、再計算する必要はありません。ストレージ最適化エンドポイントの制限事項を参照してください。
トリガー モードでは、Python SDK または REST API を使用して同期を開始します。Delta Sync インデックスの更新を参照してください。
ストレージ最適化エンドポイントの場合、 トリガー 同期モードのみがサポートされています。
高度な設定
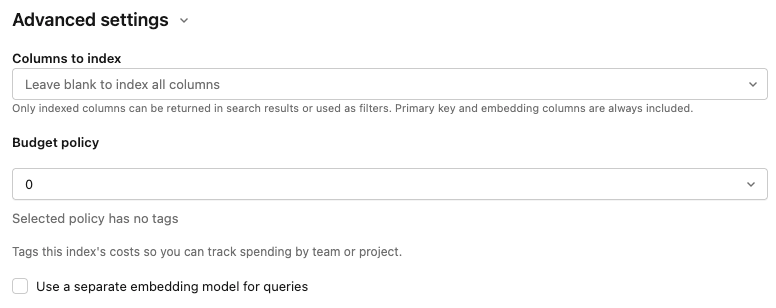
「 高度な設定 」セクションはデフォルトで折りたたまれています。ほとんどのユーザーはデフォルトを受け入れることができます。以下のいずれかをファインチューニングできるように拡張します:
埋め込みモデル : デフォルトの埋め込みモデルを上書きします。デフォルトの Databricks ホスト型モデルは、ほとんどのワークスペースで機能します。別のものが必要な場合、またはデフォルトにアクセスできない場合は、こちらで変更してください。
インデックスを作成する列 :インデックスに含める列を選択してください。このフィールドを空白のままにすると、ソーステーブルのすべての列のインデックスが作成されます。プライマリキーおよび埋め込み列は常に含まれます。検索結果で返すかフィルターとして使用できるのは、インデックス化された列のみです。
使用ポリシー :チームまたはプロジェクトで追跡できるように、インデックスのコストにタグを付けるために使用するポリシーです。AI 検索使用ポリシーをご覧ください。
クエリ用の個別の埋め込みモデル:「埋め込みのコンピュート」を選択した場合、インデックスのクエリに個別のモデルサービングエンドポイントを指定できます。これは、取り込みには高スループットのエンドポイントが必要ですが、クエリには低レイテンシのエンドポイントが必要な場合に役立ちます。「 埋め込みモデル 」フィールドで指定されたモデルは、ここで別のモデルを指定しない限り、常に取り込みに使用され、クエリにも使用されます。
-
-
インデックスの設定が完了したら、[ 作成 ]をクリックします。
Python SDKを使用して、インデックスを作成する
次の例では、Databricksによって計算されるエンべディングを用いたDelta Sync Indexを作成します。詳細については、 Python SDK リファレンスを参照してください。
この例では、オプションのパラメーターmodel_endpoint_name_for_queryも示しています。これは、インデックスのクエリに使用される別の埋め込みモデルサービング エンドポイントを指定します。
client = AISearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2", # This model is used for ingestion, and is also used for querying unless model_endpoint_name_for_query is specified.
model_endpoint_name_for_query="e5-mini-v2" # Optional. If specified, used only for querying the index.
)
次の例では、自己管理型のエンベディングを使用して Delta Sync Index を作成します。
client = AISearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
デフォルトでは、ソーステーブルのすべてのカラムがインデックスと同期されます。同期する列のサブセットを選択するには、columns_to_syncを使用します。プライマリ・キーとエンベディングカラムは、常にインデックスに含まれます。
プライマリキーとエンベディングカラム のみを 同期するには、次のように columns_to_sync で指定する必要があります。
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
追加の列を同期するには、次のように指定します。 プライマリ・キーとエンベディングカラムは、常に同期されるため、含める必要はありません。
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
全文検索インデックスを作成(ベータ)
ベータ版
全文検索インデックスの作成は、**ベクトル検索:全文検索**ベータの一部として、ストレージ最適化されたエンドポイントでのみ利用できます。使用するには、 ベクトル検索: 全文検索 パブリックプレビューを有効にしてください。プレビューを有効にするには、アカウントチームにお問い合わせいただくか、Databricks プレビューの管理を参照してください。
全文検索インデックスは、ベクトル埋め込みを必要とせずに、テキスト列でのキーワードベースの検索を可能にします。これは、意味的な類似性よりも、正確な用語、識別子、またはキーワードを検索したい場合に便利です。
Databricks は同期時に、各テキスト列の主要言語を検出し、言語固有のアナライザーを使用します。対応言語は、英語、中国語、日本語、韓国語、ドイツ語、フランス語、スペイン語、イタリア語、ポルトガル語、ロシア語です。
全文検索インデックスには次の要件があります。
- ストレージ最適化エンドポイントを使用する必要があります。標準エンドポイントはサポートされていません。
- トリガー モードを使用する必要があります。連続同期はサポートされていません。
- パラメーター
embedding_source_column、embedding_vector_column、およびembedding_dimensionはサポートされていません。
次の例では、Python SDK を使用してフルテキスト検索インデックスを作成します。
client = AISearchClient()
index = client.create_delta_sync_index(
endpoint_name="storage_optimized_endpoint",
source_table_name="catalog.schema.source_table",
index_name="catalog.schema.full_text_index",
pipeline_type="TRIGGERED",
primary_key="id",
columns_to_sync=["id", "text", "metadata_column"],
index_subtype="FULL_TEXT"
)
インデックスを作成した後、同期をトリガーしてインデックスにデータを入力してください。
index.sync()
全文インデックスをクエリーするには、query_type="FULL_TEXT"を使用します。詳細については、「AI Search Index をクエリする」を参照してください。
results = index.similarity_search(
query_text="search terms",
columns=["id", "text"],
num_results=10,
query_type="FULL_TEXT"
)
以下の例では、Direct Vector Accessインデックスを作成します。
client = AISearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name=f"{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
REST APIを使用してインデックスを作成する
REST API リファレンスドキュメント: POST /api/2.0/vector-search/indexesを参照してください。
生成されたエンベディングテーブルを保存
Databricks がエンべディングを生成する場合、生成されたエンべディングを Unity Catalog のテーブルに保存できます。 このテーブルは、ベクトル索引と同じスキーマで作成され、ベクトル索引ページからリンクされます。
テーブル名は、AI Searchインデックス名に _writeback_table が付加されたものです。名前は編集できません。
Unity Catalog で、他のテーブルと同様に、テーブルにアクセスしてクエリを実行できます。ただし、手動で更新されることを想定していないため、テーブルを削除したり変更したりしないでください。インデックスが削除された場合、テーブルは自動的に削除されます。
AI Searchインデックスを更新する
Delta Syncインデックスを更新する
Continuous 同期モードで作成されたインデックスは、ソースDeltaテーブルが変更されると自動的に更新されます。 トリガー 同期モードをご利用の場合、UI、Python SDK、またはREST APIを使用して同期を開始できます。
- Databricks UI
- Python SDK
- REST API
-
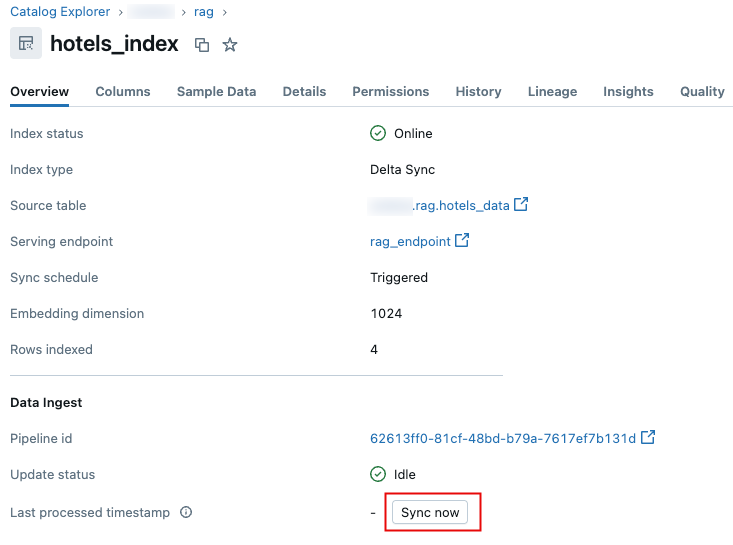
Catalog Explorer で、「AI 検索インデックス」に移動します。
-
概要 タブの データ取り込み セクションで、 今すぐ同期 をクリックします。
 。
。
詳細については、 Python SDK リファレンスを参照してください。
client = AISearchClient()
index = client.get_index(index_name="vector_search_demo.vector_search.en_wiki_index")
index.sync()
REST API リファレンスドキュメント: POST /api/2.0/vector-search/indexes/{index_name}/syncを参照してください。
ダイレクト ベクター アクセス インデックスの更新
Direct Vector Access Index にデータを挿入、更新、削除するには、Python SDK または REST API を使用できます。
- Python SDK
- REST API
詳細については、 Python SDK リファレンスを参照してください。
index.upsert([
{
"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0] * 1024
},
{
"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1] * 1024
}
])
REST API リファレンスドキュメント: POST /api/2.0/vector-search/indexesを参照してください。
本番運用アプリケーションの場合、 Databricks は パーソナルアクセストークン の代わりに サービスプリンシパル を使用することをお勧めします。 パフォーマンスは、クエリごとに最大 100 ミリ秒向上できます。
次のコード例は、サービスプリンシパルを使用してインデックスを更新する方法を示しています。
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into AI Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from AI Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
次のコード例は、パーソナルアクセストークン (PAT) を使用してインデックスを更新する方法を示しています。
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into AI Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from AI Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
ダウンタイムなしでスキーマを変更する方法
ソーステーブルへのスキーマの変更は、インデックスを再構築しない限りサポートされていません。これには、既存の列の変更と新しい列の追加が含まれます。インデックススキーマは作成時に固定されているため、スキーマの変更を反映させるには新しいインデックスを作成する必要があります。
ダウンタイムなしでインデックスを再構築してデプロイするには、以下のステップに従ってください。
- ソーステーブルでスキーマ変更を実行してください。
- 更新されたスキーマを使用して新しいインデックスを作成する。
- 新しいインデックスの準備ができたら、トラフィックを新しいインデックスに切り替えてください。
- 元のインデックスを削除してください。