チュートリアル: ノートブックからのデータのクエリと視覚化
このチュートリアルでは、Databricks ノートブックを使用して、SQL、Python、Scala、R を使用して Unity Catalog に保存されているサンプル データをクエリし、クエリ結果をノートブックで視覚化する方法について説明します。
Genie Code (エージェントモード)に以下の操作を指示してください。
Create a new notebook that queries @samples.nyctaxi.trips and displays a bar chart showing the average fare amount by trip distance, grouped by the pickup zip code.
必要条件
この記事のタスクを完了するには、次の要件を満たす必要があります。
- ワークスペースで Unity Catalog が有効になっている必要があります。Unity Catalogの使用を開始する方法については、「Unity Catalogの使用を開始する」を参照してください。
- 既存のコンピュート リソースを使用するか、新しいコンピュート リソースを作成するには、権限が必要です。 「コンピューティング」を参照するか、 Databricks管理者に問い合わせてください。
ステップ 1: 新しいノートブックを作成する
ワークスペースにノートブックを作成するには、サイドバーの「![]() 新規 」をクリックし、「 ノートブック 」をクリックします。空白のノートブックがワークスペースで開きます。
新規 」をクリックし、「 ノートブック 」をクリックします。空白のノートブックがワークスペースで開きます。
ノートブックの作成と管理の詳細については、Databricks ノートブックの管理を参照してください。
ステップ 2: テーブルのクエリを実行する
選択した言語を使用して、Unity Catalogのsamples.nyctaxi.tripsテーブルをクエリしてください。このテーブルは、samplesカタログに含まれるサンプルデータセットの1つです。
- 次のコードをコピーして、新しい空のノートブック セルに貼り付けます。 このコードは、Unity Catalog の
samples.nyctaxi.tripsテーブルに対してクエリを実行した結果を表示します。
- SQL
- Python
- Scala
- R
SELECT * FROM samples.nyctaxi.trips
display(spark.read.table("samples.nyctaxi.trips"))
display(spark.read.table("samples.nyctaxi.trips"))
library(SparkR)
display(sql("SELECT * FROM samples.nyctaxi.trips"))
-
Shift+Enterを押してセルを実行し、次のセルに移動します。クエリ結果がノートブックに表示されます。
ステップ 3: データを表示する
乗車距離ごとの平均運賃額を、ピックアップの郵便番号でグループ化して表示します。
-
テーブル タブの横にある + をクリックし、 ビジュアライゼーション をクリックします。
ビジュアライゼーションエディタが表示されます。
-
[ビジュアライゼーションのタイプ] ドロップダウンで、 [バー] が選択されていることを確認します。
-
[X] 列 で [
fare_amount] を選択します。 -
[Y] 列 で [
trip_distance] を選択します。 -
集計タイプとして [
Average] を選択します。 -
[グループ化] 列として [
pickup_zip] を選択します。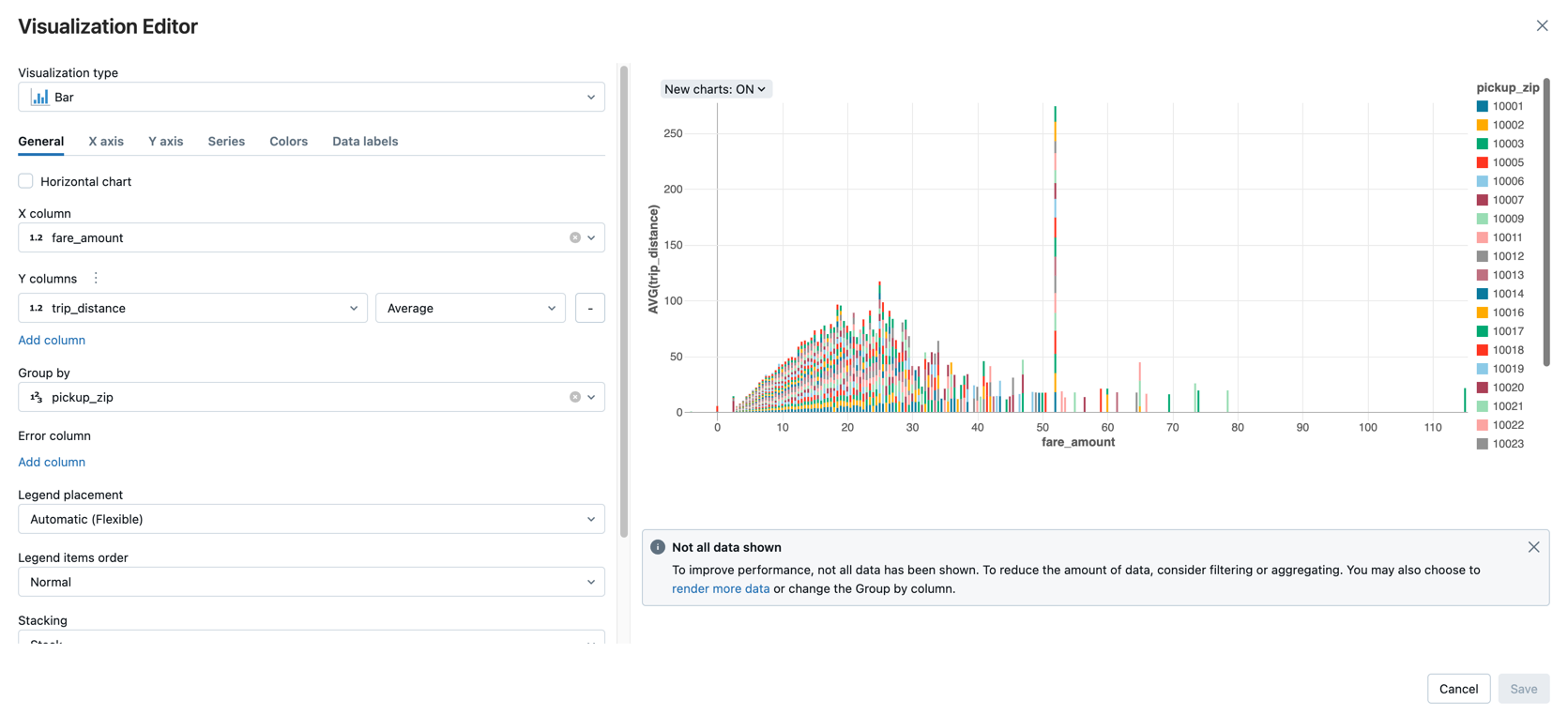
-
[ 保存 ]をクリックします。
次のステップ
- CSV ファイルから Unity Catalog にデータを追加し、データを視覚化する方法については、「 チュートリアル: ノートブックから CSV データをインポートして視覚化する」を参照してください。
- を使用してデータをDatabricks Apache Sparkにロードする方法については、「チュートリアル: を使用してデータをロードおよび変換Apache Sparkデータフレーム する」を参照してください。
- Databricksへのデータの取り込みについて詳しくは、Lakeflowコネクトの標準コネクタを参照してください。
- Databricks を使用したデータのクエリの詳細については、「 データのクエリ」を参照してください。
- 視覚化の詳細については、「 Databricks ノートブックと SQL エディターでの視覚化」を参照してください。
- 探索的データ分析 (EDA) 手法の詳細については、「 チュートリアル: Databricks ノートブックを使用した EDA 手法」を参照してください。