Lakeflow ジョブ
Lakeflow Jobsは、 Databricks向けのワークフロー自動化であり、データ処理ワークロードのオーケストレーションを提供して、より大きなワークフローの一部として複数のタスクを調整および実行できるようにします。 頻繁で反復可能なタスクの実行を最適化してスケジュールし、複雑なワークフローを管理できます。
ジョブとは?
Databricks では、ジョブを使用して、ワークフロー内の Databricks 上のタスクをスケジュールおよび調整します。一般的なデータ処理ワークフローには、ETL ワークフロー、ノートブックの実行、機械学習 (ML) ワークフロー、dbt などの外部システムとの統合などがあります。
ジョブは 1 つ以上のタスクで構成され、ビジュアル オーサリング UI を使用した分岐 (if / else ステートメント) やループ (for each ステートメント) などのカスタム制御フロー ロジックをサポートします。 タスクは、ETL ワークフローでデータを読み込んだり変換したり、機械学習パイプラインの一部として制御された反復可能な方法で ML モデルを構築、トレーニング、デプロイしたりできます。
例: 日次データ処理および検証ジョブ
次の例は、Databricks のジョブを示しています。
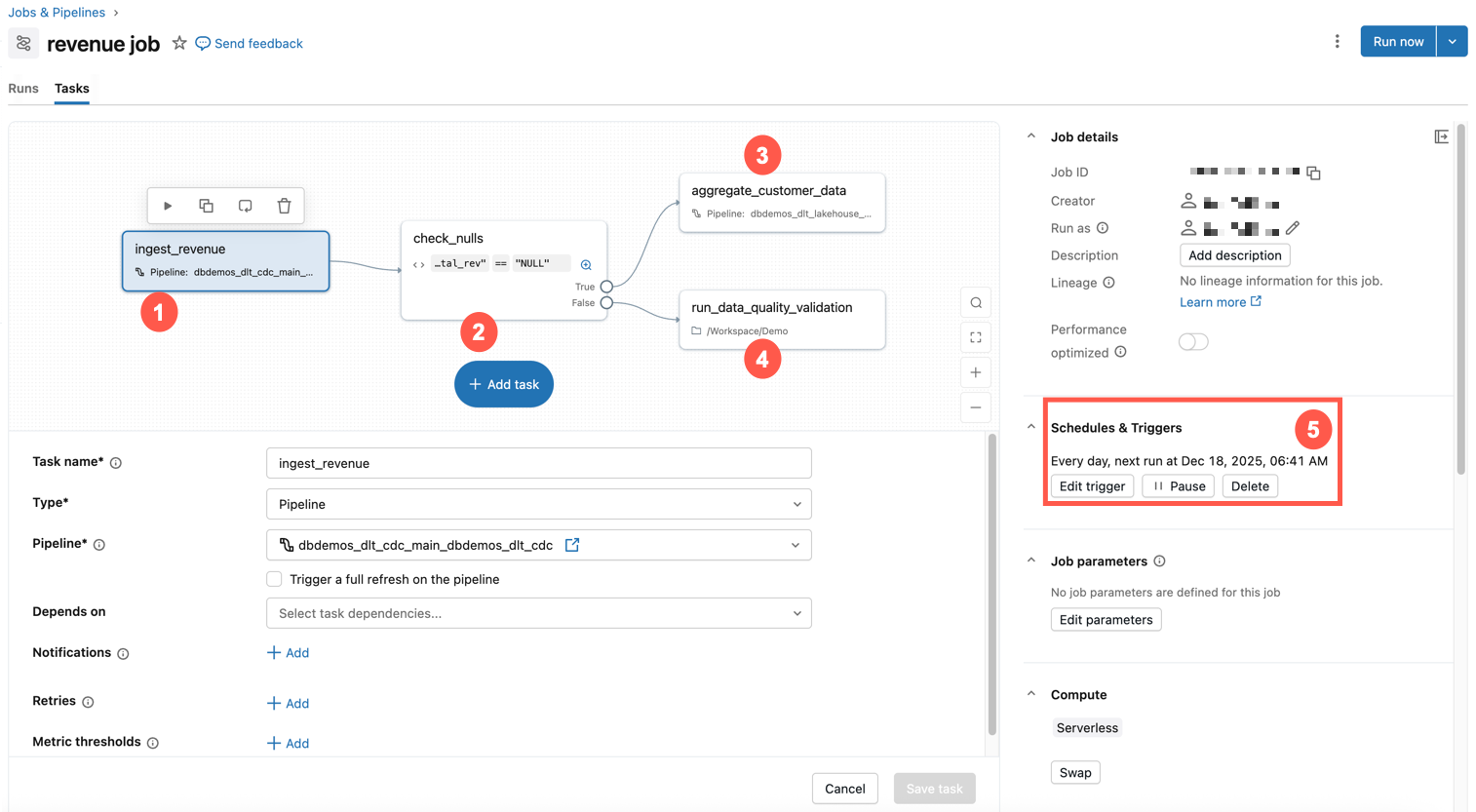
このサンプル・ジョブには、以下の特性があります。
- 最初のタスクでは、収益データを取り込みます。
- 2 番目のタスクは、null の if / else チェックです。
- そうでない場合は、変換タスクが実行されます。
- それ以外の場合は、データ品質検証を使用してノートブック タスクを実行します。
- 毎日同じ時間に実行するようにスケジュールされています。
独自のジョブの作成について簡単に紹介するには、「Lakeflowジョブを使用して最初のワークフローを作成する」を参照してください。
オーケストレーションの概念
DatabricksでLakeflowジョブをオーケストレーションに使用する場合、ジョブ、タスク、トリガーの 3 つの主要な概念があります。
ジョブ - ジョブは、操作の調整、スケジュール設定、および実行のための主要なリソースです。 ジョブの複雑さは、 Databricks ノートブックを実行する 1 つのタスクから、条件付きロジックと依存関係を持つ数百のタスクまでさまざまです。 ジョブ内のタスクは、有向非巡回グラフ (DAG) によって視覚的に表されます。 ジョブには、次のようなプロパティを指定できます。
- トリガー - ジョブをいつ実行するかを定義します。
- パラメーター - ジョブ内のタスクに自動的にプッシュされる実行時のパラメーター。
- 通知 - ジョブが失敗したとき、または時間がかかりすぎたときに送信されるEメールまたはWebhook。
- Git - ジョブ タスクのソース管理設定。
タスク - タスクは、ジョブ内の特定の作業単位です。 各タスクは、次のようなさまざまな操作を実行できます。
- ノートブック タスクは、Databricks ノートブックを実行します。 ノートブックへのパスと、ノートブックに必要なパラメーターを指定します。
- パイプラインタスクはパイプラインを実行します。マテリアライズドビューやストリーミングテーブルなどの既存のLakeflow Pipelinesを指定できます。
- PythonスクリプトタスクはPythonファイルを実行します。ファイルのパスと必要なパラメーターを提供します。
タスクには多くの種類があります。 完全なリストについては、「 タスクの種類」を参照してください。 タスクは、他のタスクに依存したり、条件付きで他のタスクを実行したりできるため、条件付きロジックと依存関係を持つ複雑なワークフローを作成できます。
トリガー - トリガーは、特定の条件やイベントに基づいてジョブの実行を開始する仕組みです。トリガーは、スケジュールされた時刻にジョブを実行するなどの時間ベース、またはクラウドストレージに新しいデータが到着したときにジョブを実行するなどのイベントベースにできます(たとえば、毎日午前 2 時)。
モニタリングとオブザーバビリティ
ジョブは、モニタリングと可観測性のための組み込みサポートを提供します。以下のトピックでは、このサポートの概要を説明します。ジョブのモニタリングとオーケストレーションの詳細については、「LakeFlowジョブのモニタリング」を参照してください。
UI でのジョブ モニタリングと可観測性 - Databricks UI では、ジョブの所有者や最後の実行結果などの詳細を含むジョブを表示したり、ジョブのプロパティでフィルタリングしたりできます。 ジョブの実行履歴を表示し、ジョブ内の各タスクに関する詳細情報を取得できます。
ジョブ 実行のステータスとメトリクス - Databricks は、ジョブの実行の成功と、ジョブ実行内の各タスクのログとメトリクスを報告し、問題を診断してパフォーマンスを把握します。
通知とアラート - Eメール、Slack、カスタムWebhook、その他多くのオプションを使用して、ジョブイベントの通知を設定できます。
システムテーブルを介したカスタムクエリ - Databricks には、アカウント全体のジョブ実行とタスクを記録するシステムテーブルが用意されています。 これらのテーブルを使用して、ジョブのパフォーマンスとコストをクエリおよび分析できます。 ダッシュボードを作成してジョブのメトリクスと傾向を視覚化し、ワークフローの正常性とパフォーマンスを監視できます。
制限
次の制限があります。
- ワークスペースの並列実行タスク数は 2000 に制限されています。 すぐに開始できない実行を要求すると、
429 Too Many Requests応答が返されます。 - ワークスペースが 1 時間に作成できるジョブの数は 10000 に制限されています(「実行の送信」を含む)。この制限は、REST API およびノートブックワークフローによって作成されたジョブにも影響します。
- ワークスペースには、最大 12000 個の保存されたジョブを含めることができます。
- ジョブには、最大 1000 個のタスクを含めることができます。
- タスクがその問題に動的な値を使用する場合、ジョブの問題は 10,000 文字に制限されます。
ワークフローをプログラムで管理する
Databricks には、次のようなツールと API があり、プログラムによってワークフローをスケジュールおよび調整できます。
ツールと API を使用してジョブを作成および管理する例については、「 ジョブの作成と管理の自動化」を参照してください。 使用可能なすべての開発者ツールのドキュメントについては、「 ローカル開発ツール」を参照してください。
外部ツールは、 Databricks ツールと API を使用して、プログラムによってワークフローをスケジュールします。 たとえば、 Apache Airflow などのツールを使用してジョブをスケジュールすることもできます。Apache Airflowを使用したLakeflowジョブのオーケストレーション を参照してください。