「基盤モデル ファインチューニング API を使用してトレーニング実行を作成する」(非推奨)
基盤モデル ファインチューニングは非推奨であり、2026年8月14日に廃止される予定です。既存のファインチューニング実行は引き続き動作し、再トレーニング可能ですが、その日付以降、databricks_genaiパッケージおよび基盤モデル ファインチューニング UI の新規インストールはブロックされます。
Databricksは、基盤モデルのトレーニングとファインチューニングのためのサーバレスかつGPU対応の環境を提供するAI Runtimeへの移行をお勧めします。
プレビュー
この機能は、us-east-1 と us-west-2でパブリック プレビュー段階です。
この記事では、基盤モデル ファインチューニング(現在は Databricks Model Training の一部)APIを使用してトレーニング実行を作成および構成する方法と、API呼び出しで使用されるすべてのパラメーターについて説明します。UIを使用して実行を作成することもできます。手順については、「基盤モデル ファインチューニング UI を使用してトレーニング 実行を作成する(非推奨)」を参照してください。
必要条件
「要件」を参照してください。
トレーニング実行を作成する
トレーニングの実行をプログラムで作成するには、 create() 関数を使用します。この関数は、指定されたデータセットでモデルをトレーニングし、トレーニングされたモデルを推論用に保存します。
必要な入力は、トレーニングするモデル、トレーニングデータセットの場所、モデルを登録する場所です。 また、評価を実行し、実行のハイパーパラメータを変更できるオプションのパラメータもあります。
実行が完了すると、完了した実行と最終チェックポイントが保存され、モデルがクローン化され、そのクローンが推論用のモデルバージョンとしてUnity Catalogに登録されます。
Unity Catalog のクローン作成されたモデル バージョン ではなく 、完了した実行のモデルが MLflow に保存されます。チェックポイントは、継続的なファインチューニング タスクに使用できます。
create() 関数の引数の詳細については、「トレーニング実行の構成」を参照してください。
from databricks.model_training import foundation_model as fm
run = fm.create(
model='meta-llama/Llama-3.2-3B-Instruct',
train_data_path='dbfs:/Volumes/main/mydirectory/ift/train.jsonl', # UC Volume with JSONL formatted data
# Public HF dataset is also supported
# train_data_path='mosaicml/dolly_hhrlhf/train'
register_to='main.mydirectory', # UC catalog and schema to register the model to
)
トレーニング実行を構成する
次の表は、 foundation_model.create() 関数のパラメーターをまとめたものです。
パラメーター | 必須 | タイプ | 説明 |
|---|---|---|---|
| x | str | 使用するモデルの名前。 サポートされているモデルを参照してください。 |
| x | str | トレーニングデータの場所。これは、Unity Catalog内( |
| x | str | 簡単にデプロイできるようにトレーニング後にモデルが登録されるUnity Catalogカタログとスキーマ( |
| str | Sparkデータ処理に使用するクラスターのクラスター ID。これは、トレーニング データが Delta テーブルにあるインストラクション トレーニング タスクに必要です。 クラスター ID を見つける方法については、「 クラスター ID を取得する」を参照してください。 | |
| str | トレーニング 実行出力 (メトリクス と checkpoints) が保存される MLflow エクスペリメントへのパス。 デフォルトをユーザーの個人用ワークスペース内の実行名に設定します (つまり、 | |
| str | 実行するタスクのタイプ。 | |
| str | 評価データのリモートロケーション(存在する場合)。 | |
| リスト[str] | 評価中に応答を生成するためのプロンプト文字列のリスト。デフォルトは | |
| str | トレーニング用のカスタムモデルチェックポイントのリモートロケーション。デフォルトは | |
| str | 実行の合計時間。デフォルトは1エポックまたは | |
| str | モデル トレーニングの学習率。 すべてのモデルは、学習率のウォームアップを使用して AdamW オプティマイザーを使用してトレーニングされます。デフォルトの学習率はモデルによって異なる場合があります。ハイパーパラメータ スイープを実行して、さまざまな学習率とトレーニング期間を試し、最高品質のモデルを取得することをお勧めします。 | |
| str | データサンプルのシーケンスの最大長です。これは、長すぎるデータを切り捨て、効率を上げるために短いシーケンスをまとめてパッケージ化するために使用されます。 デフォルトは、8192 トークンまたは指定されたモデルの最大コンテキスト長のいずれか小さい方です。このパラメーターを使用してコンテキストの長さを構成できますが、各モデルの最大コンテキスト長を超えて構成することはサポートされていません。 各モデルでサポートされるコンテキストの最大長については、「 サポートされるモデル 」を参照してください。 | |
| ブール値 | トレーニングジョブを送信する前に入力パスへのアクセスを検証するかどうか。デフォルトは |
カスタムモデルの重みに基づいて構築する
注: 2025 年 3 月 26 日より前にモデルをトレーニングした場合、それらのモデル チェックポイントから継続的にトレーニングすることはできなくなります。以前に完了したトレーニングの実行は、プロビジョニングされたスループットで問題なく提供できます。
基盤モデル ファインチューニングでは、オプションのパラメーター custom_weights_path を使用してモデルの学習とカスタマイズを行うカスタム重みの追加がサポートされています。
開始するには、 custom_weights_path を以前のファインチューニング API トレーニング 実行のチェックポイント パスに設定します。 チェックポイント パスは、以前のMLflow 実行の アーティファクト タブにあります。チェックポイント・フォルダ名は、特定のスナップショットのバッチとエポックに対応します ( ep29-ba30/など)。
![以前のMLflow実行の[アーティファクト]タブ](/aws/ja/assets/images/checkpoint-path-cff5d33c00e2899b91b47dccd540607c.png)
- 前回の実行から最新のチェックポイントを取得するには、 を
custom_weights_pathをファインチューニング APIによって生成されたチェックポイントに設定します。たとえば、custom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/latest-sharded-rank0.symlink. - 以前のチェックポイントを提供するには、
custom_weights_pathをcustom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/ep#-ba#など、目的のチェックポイントに対応する.distcpファイルを含むフォルダーへのパスに設定します。
次に、custom_weights_pathに渡したチェックポイントの基本モデルと一致するようにmodelパラメーターを更新します。
次の例では、 ift-meta-llama-3-1-70b-instruct-ohugkq を微調整する前の実行 meta-llama/Meta-Llama-3.1-70Bです。 ift-meta-llama-3-1-70b-instruct-ohugkqから最新のチェックポイントを微調整するには、model 変数と custom_weights_path 変数を次のように設定します。
from databricks.model_training import foundation_model as fm
run = fm.create(
model = 'meta-llama/Meta-Llama-3.1-70B'
custom_weights_path = 'dbfs:/databricks/mlflow-tracking/2948323364469837/d4cd1fcac71b4fb4ae42878cb81d8def/artifacts/ift-meta-llama-3-1-70b-instruct-ohugkq/checkpoints/latest-sharded-rank0.symlink'
... ## other parameters for your fine-tuning run
)
ファインチューニング 実行で他のパラメーターを構成する方法については、「 トレーニング 実行の構成 」を参照してください。
クラスター ID を取得する
クラスター ID を取得するには:
-
Databricksワークスペースの左側のナビゲーションバーで、[ コンピュート ]をクリックします。
-
テーブルで、クラスターの名前をクリックします。
-
右上隅にある
 をクリックしてドロップダウンメニューから JSONの表示 を選択します。
をクリックしてドロップダウンメニューから JSONの表示 を選択します。 -
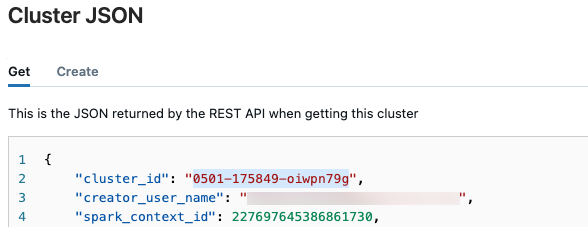
クラスターJSONファイルが表示されます。ファイルの最初の行にあるクラスターIDをコピーします。
実行のステータスを取得する
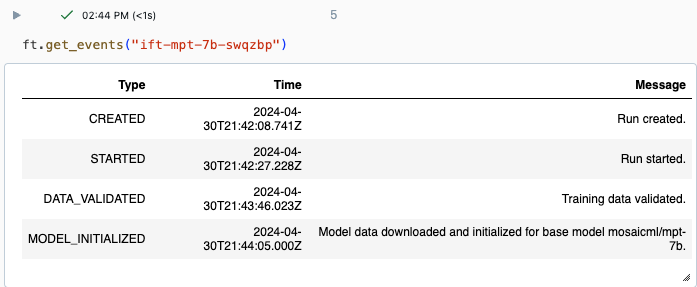
Databricks UIの実験ページまたはAPIコマンドget_events()を使用して、実行の進行状況を追跡できます。詳細については、基盤モデル ファインチューニング実行の参照、管理、分析(非推奨)を参照してください。
get_events()からの出力例:
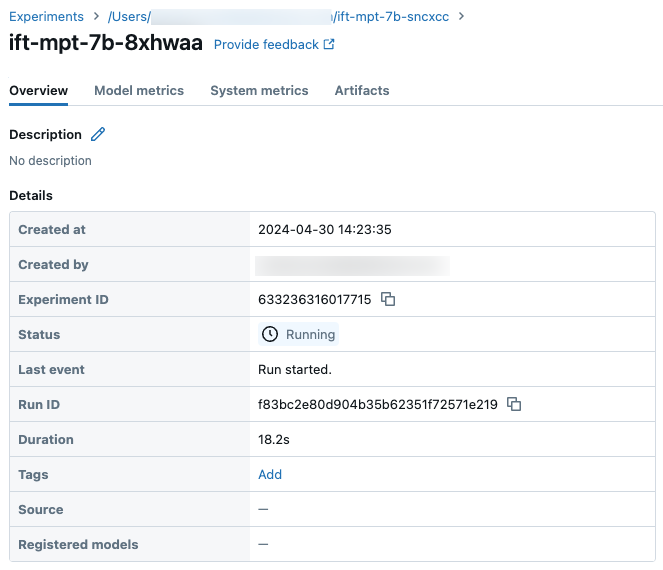
サンプル実行の詳細はエクスペリメントページをご覧ください:
次のステップ
トレーニングの実行が完了したら、MLflowでメトリクスを確認し、推論用にモデルをデプロイできます。「チュートリアル: 基盤モデル ファインチューニング 実行の作成とデプロイ (非推奨)」のステップ5~7を参照してください。
データの準備、微調整トレーニング実行設定、およびデプロイメントを説明する指示を微調整の例については、指示を微調整:エンティティを識別できる名前デモノートブックを参照してください。
ノートブックの例
次のノートブックは、Meta Llama 3.1 405B Instruct モデルを使用して合成データを生成し、そのデータを使用してモデルを微調整する方法の例を示しています。