Databricks での MLOps ワークフロー
この記事では、Databricks プラットフォームで MLOps を使用して、機械学習 (ML) システムのパフォーマンスと長期的な効率を最適化する方法について説明します。 MLOpsアーキテクチャの一般的な推奨事項と、Databricks ML開発から本番運用までのプロセスのモデルとして使用できる プラットフォームを使用した一般化されたワークフローについて説明します。このワークフローの LLMOps アプリケーションの変更については、 LLMOps ワークフローを参照してください。
詳細については、「 The Big Book of MLOps」を参照してください。
MLOpsとは?
MLOps は、コード、データ、モデルを管理するための一連のプロセスと自動化されたステップであり、ML システムのパフォーマンス、安定性、長期的な効率を向上させます。 DevOps、DataOps、ModelOps を組み合わせたものです。
コード、データ、モデルなどのML資産は、アクセス制限が厳しくなく、厳格なテストを受けていない初期の開発段階から、中間テスト段階を経て、厳密に制御された最終的な本番運用段階に進む段階で開発されます。Databricks プラットフォームでは、これらのアセットを 1 つのプラットフォームで管理し、統一されたアクセス制御を行うことができます。 データアプリケーションとMLアプリケーションを同じプラットフォーム上で開発できるため、データの移動に伴うリスクと遅延を軽減できます。
MLOps の一般的な推奨事項
このセクションでは、Databricks での MLOps に関する一般的な推奨事項と、詳細情報へのリンクを示します。
ステージごとに個別の環境を作成する
実行環境は、モデルとデータがコードによって作成または使用される場所です。 各実行環境は、コンピュートインスタンス、そのランタイムとライブラリ、および自動化されたジョブで構成されます。
Databricks では、ML コードとモデル開発のステージごとに個別の環境を作成し、ステージ間の遷移を明確に定義することをお勧めします。 この記事で説明するワークフローは、ステージの共通名を使用して、このプロセスに従います。
他の構成を使用して、組織の特定のニーズを満たすこともできます。
アクセス制御とバージョン管理
アクセス制御とバージョン管理は、あらゆるソフトウェア運用プロセスの主要なコンポーネントです。 Databricks では、次のことを推奨しています。
- バージョン管理には Git を使用します。 パイプラインとコードは、バージョン管理のために Git に格納する必要があります。 ステージ間での ML ロジックの移動は、開発ブランチからステージング ブランチ、リリース ブランチにコードを移動すると解釈できます。 Databricks Git フォルダーを使用して Git プロバイダーと統合し、ノートブックとソース コードを Databricks ワークスペースと同期します。Databricks には、Git 統合とバージョン管理のための追加ツールも用意されています。 ローカル開発ツールを参照してください。
- Delta テーブルを使用してレイクハウス アーキテクチャにデータを格納する。 データは、クラウドアカウントの レイクハウスアーキテクチャ に保存する必要があります。 生データと特徴量テーブルはどちらも、誰が読み取りおよび変更できるかを決定するためのアクセス制御を備えた Delta テーブル として保存する必要があります。
- MLflow を使用してモデル開発を管理します。 MLflow を使用して、モデル開発プロセスを追跡し、コード スナップショット、モデル パラメーター、メトリクス、その他のメタデータを保存できます。
- Unity Catalog のモデルを使用して、モデルのライフサイクルを管理します。 Unity Catalog のモデルを使用して、モデルのバージョン管理、ガバナンス、デプロイの状態を管理します。
モデルではなくコードをデプロイする
ほとんどの場合、Databricks では、ML 開発プロセス中に、 モデル ではなく コード を 1 つの環境から次の環境に昇格することをお勧めします。この方法でプロジェクトアセットを移動すると、ML 開発プロセス内のすべてのコードが同じコードレビューと統合テストプロセスを経るようになります。 また、モデルの本番運用バージョンが本番運用コードでトレーニングされることも保証されます。 オプションとトレードオフの詳細については、「 モデル デプロイ パターン」を参照してください。
推奨される MLOps ワークフロー
次のセクションでは、一般的な MLOps ワークフローについて説明し、開発、ステージング、本番運用の 3 つのステージのそれぞれについて説明します。
このセクションでは、典型的なペルソナとして "データサイエンティスト" と "ML エンジニア" という用語を使用します。 MLOps ワークフローの特定の役割と責任は、チームや組織によって異なります。
開発段階
開発フェーズの焦点は実験です。 データサイエンティスト フィーチャーとモデルを開発し、エクスペリメントを実行してモデルのパフォーマンスを最適化します。 開発プロセスの出力は、特徴計算、モデル トレーニング、推論、およびモニタリングを含めることができる機械学習パイプライン コードです。
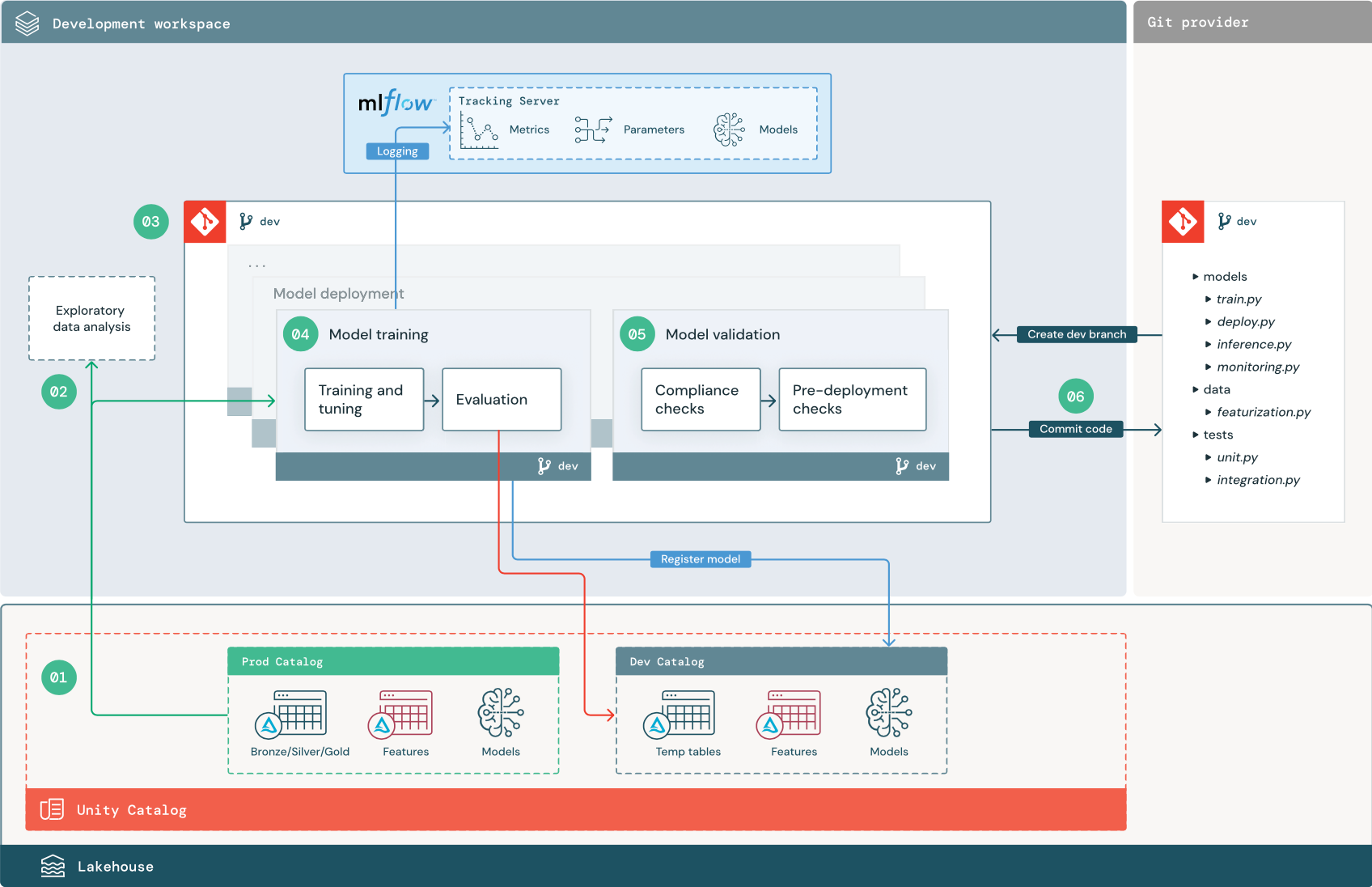
番号が付けられたステップは、図に示されている番号に対応しています。
1. データソース
開発環境は、Unity Catalog の dev カタログで表されます。 データサイエンティスト 、開発ワークスペースに一時データと特徴量テーブルを作成するときに、開発カタログへの読み取り/書き込みアクセス権があります。 開発ステージで作成されたモデルは、開発カタログに登録されます。
理想的には、開発ワークスペースで作業している データサイエンティスト 、製品カタログ内の本番運用データへの読み取り専用アクセス権も持っています。 本番運用データ、推論テーブル、およびメトリクス テーブルへの データサイエンティスト 読み取りアクセスを許可することで、現在の本番運用モデルの予測とパフォーマンスを分析できます。 また、データサイエンティスト実験や分析のために本番運用モデルを読み込めるようにする必要があります。
prod カタログへの読み取り専用アクセス権限を付与できない場合は、本番運用データのスナップショットを開発カタログに書き込んで、 データサイエンティスト プロジェクト・コードを開発および評価できるようにすることができます。
2. 探索的データ解析(EDA)
データサイエンティスト 、ノートブックを使用して、対話型の反復プロセスでデータを探索および分析します。 目標は、入手可能なデータがビジネス上の問題を解決する可能性があるかどうかを評価することです。 この手順では、データ サイエンティストは、モデル トレーニングのデータ準備と特徴量化の手順の特定を開始します。 このアドホック プロセスは、通常、他の実行環境にデプロイされるパイプラインの一部ではありません。
AutoML は、データセットのベースライン モデルを生成することで、このプロセスを高速化します。 AutoML は、一連のトライアルを実行および記録し、各トライアル実行のソースコードを Python ノートブックに提供するため、コードを確認、再現、変更できます。 また、AutoML はデータセットの要約統計を計算し、この情報をノートブックに保存して確認できるようにします。
3. コード
コード リポジトリには、ML プロジェクトのすべてのパイプライン、モジュール、およびその他のプロジェクト ファイルが含まれています。 データサイエンティスト 、プロジェクトリポジトリの開発(「開発」)ブランチに新規または更新されたパイプラインを作成します。 プロジェクトの EDA フェーズと初期フェーズから始めて、 データサイエンティスト リポジトリで作業してコードを共有し、変更を追跡する必要があります。
4. モデルのトレーニング(開発)
データサイエンティスト 、開発カタログまたは製品カタログのテーブルを使用して、開発環境でモデル トレーニング パイプラインを開発します。
このパイプラインには、次の 2 つのタスクが含まれています。
-
トレーニングとチューニング。 トレーニング プロセス 記録済みモデル パラメーター, メトリクス, アーティファクト を MLflow Tracking サーバーに送信します。 ハイパーパラメータのトレーニングとチューニングの後、最終的なモデルアーティファクトはトラッキングサーバーに記録され、モデル、トレーニングされた入力データ、およびモデルの生成に使用されたコード間のリンクが記録されます。
-
評価。 保持されたデータでテストすることにより、モデルの品質を評価します。 これらのテストの結果は、MLflow 追跡サーバーに記録されます。 評価の目的は、新たに開発したモデルが現在の本番運用モデルよりも優れたパフォーマンスを発揮するかどうかを判断することです。 十分な権限があれば、prod カタログに登録されている任意の本番運用モデルを開発ワークスペースに読み込み、新しくトレーニングされたモデルと比較できます。
組織のガバナンス要件にモデルに関する追加情報が含まれている場合は、 MLflow 追跡を使用して保存できます。一般的なアーティファクトは、プレーンテキストの説明と、SHAPによって生成されたプロットなどのモデルの解釈です。特定のガバナンス要件は、データガバナンス責任者またはビジネス利害関係者から提供される場合があります。
モデル トレーニング パイプラインの出力は、開発環境のML MLflowTracking サーバーに格納された モデル アーティファクトです。パイプラインがステージングまたは本番運用ワークスペースで実行される場合、モデル アーティファクトはそのワークスペースの MLflow Tracking サーバーに保存されます。
モデルのトレーニングが完了したら、モデルを Unity Catalogに登録します。 モデル パイプラインが実行された環境に対応するカタログにモデルを登録するように、パイプライン コードを設定します。この例では、Dev カタログです。
推奨アーキテクチャでは、最初のタスクがモデル トレーニング パイプラインで、その後にモデル検証タスクとモデル デプロイ タスクが続くマルチタスク Databricks ワークフローをデプロイします。 モデル トレーニング タスクは、モデル検証タスクで使用できるモデル URI を生成します。 タスク値を使用して、この URI をモデルに渡すことができます。
5. モデルの検証とデプロイ (開発)
開発環境では、モデル トレーニング パイプライン以外にも、モデルの検証 や モデルデプロイメントのパイプラインなどの他のパイプラインが開発されます。
-
モデルの検証。 モデル検証パイプラインは、モデル トレーニング パイプラインからモデル URI を取得し、Unity Catalog からモデルを読み込み、検証チェックを実行します。
検証チェックはコンテキストによって異なります。 これには、形式や必要なメタデータの確認などの基本的なチェックから、事前定義されたコンプライアンス チェックや選択したデータ スライスでのモデルのパフォーマンスの確認など、規制の厳しい業界で必要となる可能性のあるより複雑なチェックが含まれる場合があります。
モデル検証パイプラインの主な機能は、モデルがデプロイ手順に進む必要があるかどうかを判断することです。 モデルがデプロイ前のチェックに合格した場合、Unity Catalog で "Challenger" エイリアスを割り当てることができます。 チェックが失敗した場合、プロセスは終了します。 検証の失敗をユーザーに通知するようにワークフローを構成できます。 「ジョブに通知を追加する」を参照してください。
-
モデルのデプロイメント。 モデル デプロイ パイプラインは、通常、エイリアスの更新を使用して新しくトレーニングされた "Challenger" モデルを "Champion" ステータスに直接昇格させるか、既存の "Champion" モデルと新しい "Challenger" モデルとの比較を容易にします。 このパイプラインでは、モデルサービングエンドポイントなど、必要な推論インフラストラクチャを設定することもできます。 モデル・デプロイメント・パイプラインに関連するステップの詳細については、 本番運用を参照してください。
6. コードをコミットする
トレーニング、検証、デプロイ、およびその他のパイプラインのコードを開発した後、データサイエンティストまたは ML エンジニアは、開発ブランチをソース コントロールに変更します。
ステージング ステージ
このステージでは、 ML パイプライン コードをテストして、本番運用の準備ができていることを確認することに重点を置いています。 このステージでは、モデル トレーニングのコード、機能エンジニアリング パイプライン、推論コードなど、 ML パイプライン コードはすべてテストされます。
ML エンジニアは、このステージで実行される単体テストと統合テストを実装するための CI パイプラインを作成します。 ステージング・プロセスの出力は、 CI/CD システムが本番運用ステージを開始するようにトリガーするリリース・ブランチです。
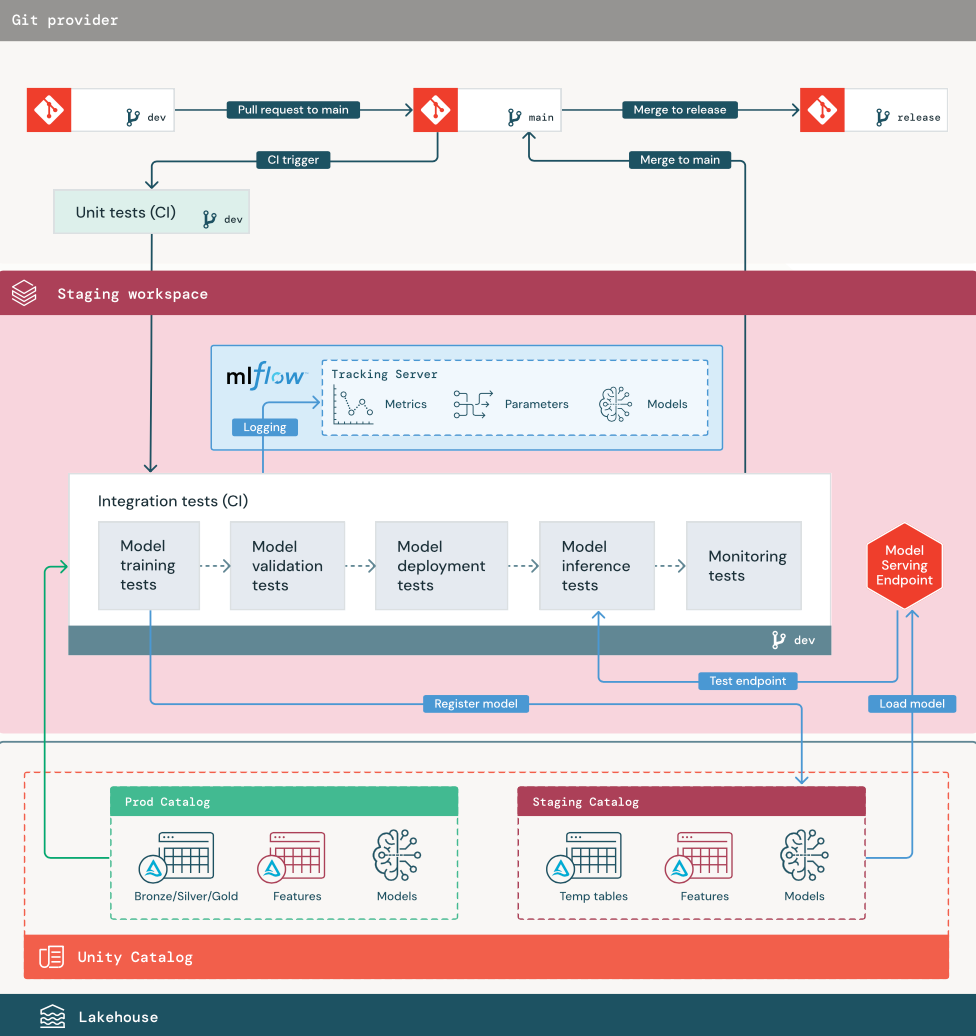
1. データ
ステージング環境では、ML パイプラインをテストし、モデルを Unity Catalog に登録するために、Unity Catalog に独自のカタログが必要です。 このカタログは、図に "ステージング" カタログとして示されています。 このカタログに書き込まれる資産は、通常、一時的なものであり、テストが完了するまでのみ保持されます。 開発環境では、デバッグのためにステージング カタログへのアクセスも必要になる場合があります。
2. コードをマージする
データサイエンティスト 開発カタログまたは本番運用カタログのテーブルを使用して、開発環境で モデル トレーニング パイプラインを開発します。
-
プルリクエスト。 デプロイ プロセスは、ソース管理でプロジェクトのメイン ブランチに対して プルリクエスト が作成されたときに開始されます。
-
単体テスト (CI)。 プルリクエスト は、ソース コードを自動的にビルドし、単体テストをトリガーします。 単体テストが失敗した場合、プルリクエストは拒否されます。
単体テストはソフトウェア開発プロセスの一部であり、コードの開発中に継続的に実行され、コードベースに追加されます。 CI パイプラインの一部として単体テストを実行すると、開発ブランチで行われた変更によって既存の機能が損なわれることはありません。
3. 統合テスト(CI)
その後、CI プロセスは統合テストを実行します。 統合テストでは、すべてのパイプライン (特徴量 エンジニアリング、モデル トレーニング、推論、モニタリングなど) を実行して、それらが正しく連携して機能することを確認します。 ステージング環境は、可能な限り本番運用環境と一致させる必要があります。
リアルタイム推論を使用して ML アプリケーションをデプロイする場合は、ステージング環境でサービングインフラストラクチャを作成してテストする必要があります。 これには、ステージング環境にサービングエンドポイントを作成し、モデルをロードするモデルデプロイメントパイプラインのトリガーが含まれます。
統合テストの実行に必要な時間を短縮するために、一部のステップでは、テストの忠実度と速度またはコストの間でトレードオフが発生する可能性があります。 たとえば、モデルのトレーニングにコストがかかるか時間がかかる場合は、データの小さなサブセットを使用するか、トレーニングの反復回数を減らすことができます。 モデルサービングの場合、本番運用の要件に応じて、統合テストで本格的な負荷テストを行う場合もあれば、小さなバッチジョブや一時的なエンドポイントへの要求をテストするだけの場合もあります。
4. ステージングブランチにマージする
すべてのテストに合格すると、新しいコードはプロジェクトのメインブランチにマージされます。 テストが失敗した場合、CI/CD システムはユーザーに通知し、結果をプル要求に投稿する必要があります。
メインブランチで定期的な統合テストをスケジュールできます。 これは、ブランチが複数のユーザーからの並列プル要求で頻繁に更新される場合に良い考えです。
5. リリースブランチを作成する
CI テストに合格し、開発ブランチがメイン ブランチにマージされた後、 ML エンジニアはリリース ブランチを作成し、これにより CI/CD システムが本番運用ジョブを更新するトリガーとなります。
本番運用ステージ
ML エンジニアは、 ML パイプラインをデプロイして実行する本番運用環境を所有しています。 これらのパイプラインは、モデルのトレーニングをトリガーし、新しいモデルバージョンを検証してデプロイし、ダウンストリームのテーブルやアプリケーションへの予測の公開を行い、プロセス全体を監視してパフォーマンスの低下や不安定性を回避します。
データサイエンティストは通常、本番運用環境では書き込みアクセス権限またはコンピュートアクセス権限を持っていません。 ただし、テスト結果、記録済みモデル アーティファクト、本番運用 パイプライン status、およびモニタリング テーブルをデータサイエンティストが見れるようにすることが重要です。 この可視性により、本番運用の問題を特定して診断し、新しいモデルと現在本番運用中のモデルのパフォーマンスを比較できます。 これらの目的のために データサイエンティストに対して本番運用カタログ内のアセットへの読み取り専用アクセス権限を付与できます。
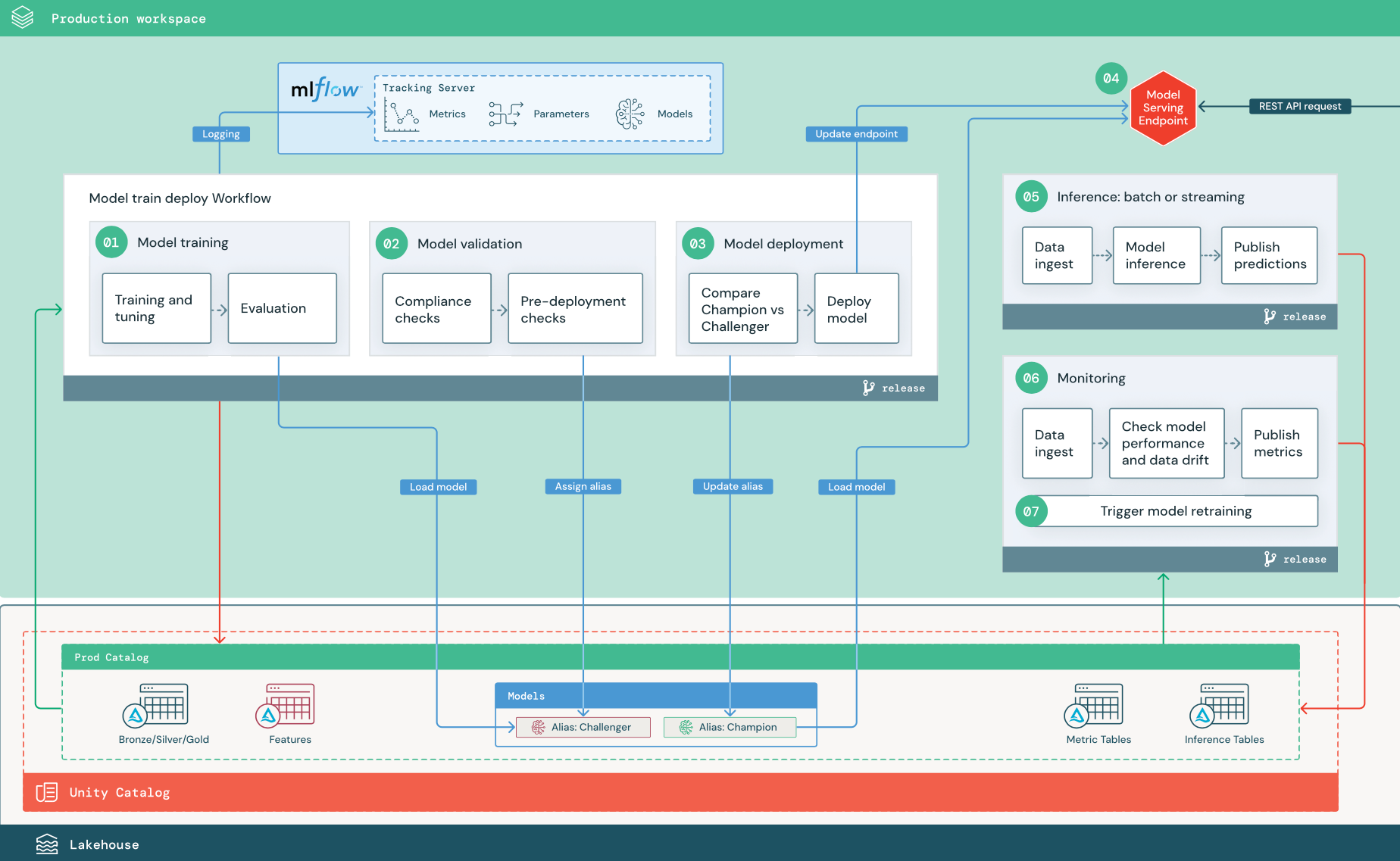
番号が付けられたステップは、図に示されている番号に対応しています。
1. モデルのトレーニング
このパイプラインは、コードの変更または自動再トレーニング ジョブによってトリガーできます。 このステップでは、本番運用カタログのテーブルを次のステップで使用します。
-
トレーニングとチューニング。 トレーニングの過程で、トラッキングサーバー MLflow 本番運用環境にログが記録されます。 これらのログには、モデル メトリクス、パラメーター、タグ、およびモデル自体が含まれます。 特徴量テーブルを使用する場合、モデルはDatabricks Feature Store クライアントを使用してMLflowに記録され、推論時に使用される特徴量テーブル情報と共にモデルがパッケージ化されます。
開発中に、 data scientists 多くのアルゴリズムとハイパーパラメータをテストする場合があります。 本番運用 トレーニング コードでは、パフォーマンスの高いオプションのみを検討するのが一般的です。 この方法でチューニングを制限すると、時間が節約され、自動再トレーニングでのチューニングによる分散を減らすことができます。
データサイエンティストが本番運用カタログへの読み取り専用アクセス権を持っている場合、モデルのハイパーパラメータの最適なセットを決定できる可能性があります。この場合、本番運用にデプロイされたモデル トレーニング パイプラインは、選択したハイパーパラメータのセット (通常は構成ファイルとしてパイプラインに含まれる) を使用して実行できます。
-
評価。 モデルの品質は、ホールドアウトされた本番運用データでテストすることによって評価されます。 これらのテストの結果は、MLflow 追跡サーバーに記録されます。 このステップ は、開発段階でデータサイエンティストが指定した評価メトリクスを使用します。 これらのメトリクスには、カスタムコードが含まれる場合があります。
-
モデルの登録 モデルトレーニングが完了すると、 Unity Catalogの本番運用カタログに指定したモデルのパスに モデルアーティファクトが登録されたモデルバージョンとして保存されます。 モデル トレーニング タスクは、モデル検証タスクで使用できるモデル URI を生成します。 タスク値を使用して、この URI をモデルに渡すことができます。
2. モデルの検証
このパイプラインは、手順 1 のモデル URI を使用し、Unity Catalog からモデルを読み込みます。 その後、一連の検証チェックを実行します。 これらのチェックは、組織やユースケースによって異なり、基本的な形式やメタデータの検証、選択したデータスライスのパフォーマンス評価、タグやドキュメントのコンプライアンスチェックなどの組織要件に対するコンプライアンスなどが含まれます。
モデルがすべての検証チェックに合格した場合は、Unity Catalog でモデルバージョンに "Challenger" エイリアスを割り当てることができます。 モデルがすべての検証チェックに合格しない場合、プロセスは終了し、ユーザーに自動的に通知されます。 タグを使用して、これらの検証チェックの結果に応じて Key-Value 属性を追加できます。 たとえば、タグ "model_validation_status" を作成し、テストの実行時に値を "PENDING" に設定し、パイプラインが完了したら "PASSED" または "FAILED" に更新できます。
モデルは Unity Catalogに登録されているため、開発環境で作業する データサイエンティスト 、本番運用カタログからこのモデルバージョンを読み込んで、モデルが検証に失敗したかどうかを調査できます。 結果にかかわらず、本番運用カタログに登録されたモデルに、モデルバージョンへのアノテーションを付与して結果を記録します。
3. モデルのデプロイ
検証パイプラインと同様に、モデルデプロイパイプラインは組織とユースケースによって異なります。 このセクションでは、新たに検証されたモデルに「Challenger」のエイリアスが割り当てられており、既存の本番運用モデルに「Champion」のエイリアスが割り当てられていることを前提としています。 新しいモデルをデプロイする前の最初のステップは、少なくとも現在の本番運用モデルと同等のパフォーマンスを発揮することを確認することです。
-
「CHALLENGER」と「CHAMPION」のモデルを比較する この比較は、オフラインまたはオンラインで実行できます。 オフライン比較では、保持されたデータ セットに対して両方のモデルが評価され、MLflow 追跡サーバーを使用して結果が追跡されます。 リアルタイム モデルサービングの場合は、A/B テストや新しいモデルの段階的なロールアウトなど、実行時間の長いオンライン比較を実行することができます。 比較で「Challenger」モデルバージョンの方がパフォーマンスが高い場合は、現在の「Champion」エイリアスが置き換えられます。
モデルサービングとデータプロファイリングを使用すると、エンドポイントのリクエストデータとレスポンスデータを含む推論テーブルを自動的に収集および監視できます。
既存の "Champion" モデルがない場合は、"Challenger" モデルをベースラインとしてビジネス ヒューリスティックまたはその他のしきい値と比較できます。
ここで説明するプロセスは完全に自動化されています。 手動の承認手順が必要な場合は、ワークフロー通知またはモデル デプロイ パイプラインからの CI/CD コールバックを使用して設定できます。
-
モデルをデプロイします。 バッチ処理またはストリーミング処理の推論パイプラインは、「Champion」というエイリアスを持つモデルを使用するように設定できます。リアルタイムでの利用ケースでは、モデルをREST APIエンドポイントとしてデプロイするためのインフラストラクチャを構築する必要があります。モデルサービングを使用して、このエンドポイントを作成および管理できます。エンドポイントが既に現在のモデルで使用されている場合は、新しいモデルでエンドポイントを更新できます。モデルサービングは、新しい構成が準備できるまで既存の構成を稼働させ続けることで、ダウンタイムゼロの更新を実行します。
4. モデルサービング
モデルサービングエンドポイントを設定するときは、モデルの名前を Unity Catalog で指定し、提供するバージョンを指定します。 モデル バージョンが Unity Catalog のテーブルの特徴を使用してトレーニングされた場合、モデルには特徴と関数の依存関係が格納されます。 モデルサービングは、この依存関係グラフを自動的に使用して、推論時に適切なオンラインストアから特徴を検索します。 このアプローチは、データの前処理のための関数や、モデルのスコアリング中にオンデマンド特徴量のコンピュートに適用するためにも使用できます。
複数のモデルを持つ 1 つのエンドポイントを作成し、それらのモデル間で分割されるエンドポイント トラフィックを指定して、オンラインでの "Champion" と "Challenger" の比較を行うことができます。
5.推論:バッチまたはストリーミング
推論パイプラインは、本番運用カタログから最新のデータを読み込み、オンデマンド特徴量のコンピュートに関数を実行し、「チャンピオン」モデルを読み込み、データをスコアリングし、予測を返します。 バッチ推論またはストリーミング推論は、一般に、高スループット、高レイテンシのユースケースで最もコスト効率の高いオプションです。 低レイテンシーの予測が必要であるが、予測をオフラインでコンピュートできるシナリオでは、これらのバッチ予測を DynamoDB や Cosmos DB などのオンラインのキーバリューストアに発行できます。
Unity Catalog に登録されているモデルは、そのエイリアスによって参照されます。 推論パイプラインは、"Champion" モデル バージョンを読み込んで適用するように構成されています。 "Champion" バージョンが新しいモデル バージョンに更新された場合、推論パイプラインは次回の実行で新しいバージョンを自動的に使用します。 このようにして、モデルのデプロイ ステップは推論パイプラインから分離されます。
バッチジョブは通常、予測を本番運用カタログのテーブル、フラットファイル、または JDBC 接続を介して公開します。 ストリーミング ジョブは、通常、Unity Catalog テーブルまたは Apache Kafka などのメッセージ キューに予測を発行します。
6. データプロファイリング
データプロファイリングは、データ ドリフトやモデルのパフォーマンスなど、入力データとモデル予測の統計的プロパティを監視します。 これらのメトリクスに基づいてアラートを作成したり、ダッシュボードに公開したりできます。
- データ取り込み。 このパイプラインは、バッチ推論、ストリーミング推論、またはオンライン推論からログを読み取ります。
- 精度とデータのドリフトを確認します。 入力データ、モデルの予測、インフラストラクチャのパフォーマンスに関するパイプライン コンピュート メトリクス。 data scientists開発中にデータとモデル メトリクスを指定し、 MLエンジニアはインフラストラクチャ メトリクスを指定します。 カスタム メトリクスを定義することもできます。
- メトリクスを公開し、アラートを設定します。 このパイプラインは、分析とレポート作成のために、本番運用カタログ内のテーブルに書き込みます。 これらのテーブルは、開発環境から読み取り可能に設定して データサイエンティスト 分析にアクセスできるようにする必要があります。 Databricks SQL を使用して、モデルのパフォーマンスを追跡するモニタリング ダッシュボードを作成したり、メトリクスが指定したしきい値を超えたときに通知を発行するようにモニタリング ジョブまたはダッシュボード ツールを設定したりできます。
- モデルの再トレーニングをトリガーします。 モニタリング メトリクスがパフォーマンスの問題や入力データの変更を示している場合、データサイエンティストは新しいモデル バージョンを開発する必要があるかもしれません。 これが発生したときに SQLに通知するように アラートを設定できます。データサイエンティスト
7. 再トレーニング
このアーキテクチャでは、上記と同じモデル トレーニング パイプラインを使用した自動再トレーニングがサポートされています。 Databricks では、スケジュールされた定期的な再トレーニングから始めて、必要に応じてトリガーによる再トレーニングに移行することをお勧めします。
- スケジュール済み 新しいデータが定期的に利用可能な場合は、スケジュールされたジョブを作成して、利用可能な最新のデータでモデル トレーニング コードを実行できます。スケジュールとトリガーを使用したジョブの自動化を参照してください。
- トリガー。 モニタリング パイプラインがモデルのパフォーマンスの問題を特定してアラートを送信できる場合は、再トレーニングをトリガーすることもできます。 たとえば、受信データの分布が大幅に変化した場合や、モデルのパフォーマンスが低下した場合、自動再トレーニングと再デプロイにより、人間の介入を最小限に抑えてモデルのパフォーマンスを向上させることができます。 これは、メトリクスが異常であるかどうかを確認する SQL アラートによって実現できます(たとえば、しきい値に対するドリフトやモデルの品質をチェックするなど)。 アラートは、Webhook の宛先を使用するように構成でき、後でトレーニング ワークフローをトリガーできます。
再トレーニング パイプラインまたはその他のパイプラインでパフォーマンスの問題が見られる場合、データサイエンティストは、問題に対処するための追加の実験のために開発環境に戻る必要がある場合があります。