Spark の DAG で高価な読み取りを特定する
DAGへの行き方
高価なジョブを見ていると仮定すると、まず、読み取りを行っているステージのIDが必要です。ここでは、ステージIDが194であることがわかります。

次に、SQL DAGにアクセスする必要があります。ジョブのページの上部までスクロールし、 関連するSQLクエリ をクリックします。
DAG が表示されます。 そうでない場合は、少しスクロールすると表示されます。

場合によっては、DAG をたどって、データがどこから来ているかを確認できます。 それ以外の場合は、メモしたステージIDを探します。
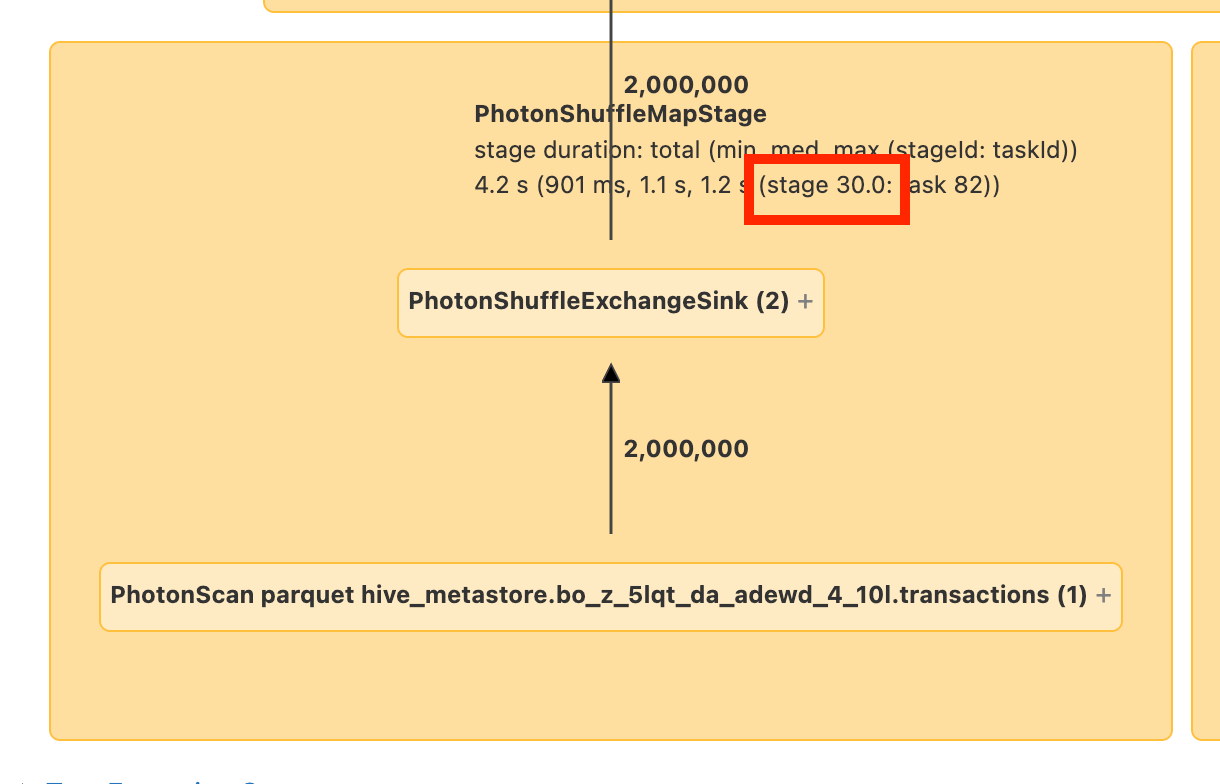
次に、「スキャン」ノードを探す必要があります。この場合、 transactionsという名前のテーブルを読み取っていることは非常に簡単にわかります。

場合によっては、読み取っているデータの場所を取得するために、ノードをクリックまたはロールオーバーする必要があります。