Train recommender models
This article includes two examples of deep-learning-based recommendation models on Databricks. Compared to traditional recommendation models, deep learning models can achieve higher quality results and scale to larger amounts of data. As these models continue to evolve, Databricks provides a framework for effectively training large-scale recommendation models capable of handling hundreds of millions of users.
A general recommendation system can be viewed as a funnel with the stages shown in the diagram.
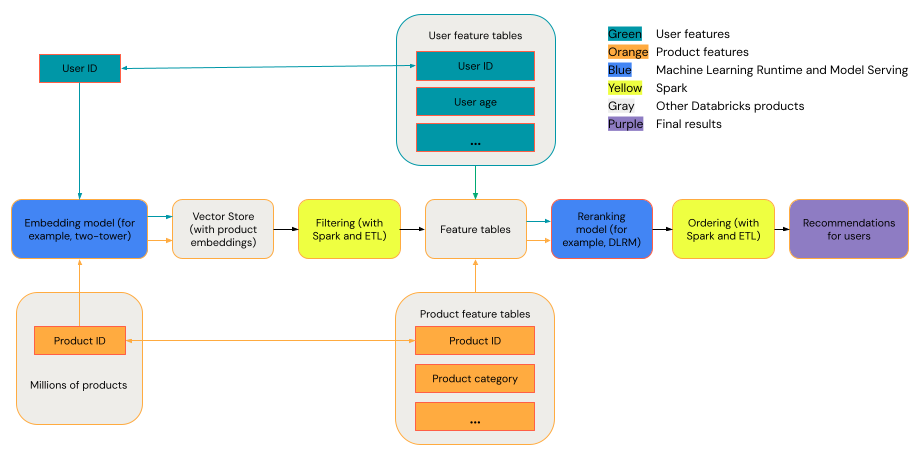
Some models, such as the two-tower model, perform better as retrieval models. These models are smaller and can effectively operate on millions of data points. Other models, such as DLRM or DeepFM, perform better as reranking models. These models can take in more data, are larger, and can provide fine-grained recommendations.
Requirements
Databricks Runtime 14.3 LTS ML
Tools
The examples in this article illustrate the following tools:
- TorchDistributor: TorchDistributor is a framework that allows you to run large scale PyTorch model training on Databricks. It uses Spark for orchestration and can scale to as many GPUs as are available in your cluster.
- Mosaic StreamingDataset: StreamingDataset improves performance and scalability of training on large datasets on Databricks using features like prefetching and interleaving.
- MLflow: MLflow allows you to track parameters, metrics, and model checkpoints.
- TorchRec: Modern recommender systems use embedding lookup tables to handle millions of users and items to generate high-quality recommendations. Larger embedding sizes improve model performance but require substantial GPU memory and multi-GPU setups. TorchRec provides a framework to scale recommendation models and lookup tables across multiple GPUs, making it ideal for large embeddings.
Example: Movie recommendations using a two-tower model architecture
The two-tower model is designed to handle large-scale personalization tasks by processing user and item data separately before combining them. It is capable of efficiently generating hundreds or thousands of decent quality recommendations. The model generally expects three inputs: A user_id feature, a product_id feature, and a binary label defining whether the <user, product> interaction was positive (the user purchased the product) or negative (the user gave the product a one star rating). The outputs of the model are embeddings for both users and items, which are then generally combined (often using a dot product or cosine similarity) to predict user-item interactions.
As the two-tower model provides embeddings for both users and products, you can place these embeddings in a vector index, such as Vector Search, and perform similarity-search-like operations on the users and items. For example, you could place all the items in a vector store, and for each user, query the vector store to find the top hundred items whose embeddings are similar to the user's.
The following example notebook implements the two-tower model training using the “Learning from Sets of Items” dataset to predict the likelihood that a user will rate a certain movie highly. It uses Mosaic StreamingDataset for distributed data loading, TorchDistributor for distributed model training, and MLflow for model tracking and logging.
Two-tower recommender model notebook
This notebook is also available in the Databricks Marketplace: Two-tower model notebook
- Inputs for the two-tower model are most often the categorical features user_id and product_id. The model can be modified to support multiple feature vectors for both users and products.
- Outputs for the two-tower model are usually binary values indicating whether the user will have a positive or negative interaction with the product. The model can be modified for other applications such as regression, multi-class classification, and probabilities for multiple user actions (for example, dismiss or purchase). Complex outputs should be implemented carefully, as competing objectives can degrade the quality of the embeddings generated by the model.
Example: Train a DLRM architecture using a synthetic dataset
DLRM is a state-of-the-art neural network architecture designed specifically for personalization and recommendation systems. It combines categorical and numerical inputs to effectively model user-item interactions and predict user preferences. DLRMs generally expect inputs that include both sparse features (such as user ID, item ID, geographic location, or product category) and dense features (such as user age or item price). The output of a DLRM is typically a prediction of user engagement, such as click-through rates or purchase likelihood.
DLRMs offer a highly customizable framework that can handle large-scale data, making it suitable for complex recommendation tasks across various domains. Because it is a larger model than the two-tower architecture, this model is often used in the reranking stage.
The following example notebook builds a DLRM model to predict binary labels using dense (numerical) features and sparse (categorical) features. It uses a synthetic dataset to train the model, the Mosaic StreamingDataset for distributed data loading, TorchDistributor for distributed model training, and MLflow for model tracking and logging.
DLRM notebook
This notebook is also available in the Databricks Marketplace: DLRM notebook.
Comparison of two-tower and DLRM models
The table shows some guidelines for selecting which recommender model to use.
Model type | Dataset size needed for training | Model size | Supported input types | Supported output types | Use cases |
|---|---|---|---|---|---|
Two-tower | Smaller | Smaller | Usually two features (user_id, product_id) | Mainly binary classification and embeddings generation | Generating hundreds or thousands of possible recommendations |
DLRM | Larger | Larger | Various categorical and dense features (user_id, gender, geographic_location, product_id, product_category, …) | Multi-class classification, regression, others | Fine-grained retrieval (recommending tens of highly relevant items) |
In summary, the two-tower model is best used for generating thousands of good quality recommendations very efficiently. An example might be movie recommendations from a cable provider. The DLRM model is best used for generating very specific recommendations based on more data. An example might be a retailer who wants to present to a customer a smaller number of items that they are highly likely to purchase.