execução MLflow Projetos em Databricks
O MLflow Projects não é mais suportado.
Essa documentação foi descontinuada e pode não estar atualizada. O produto, serviço ou tecnologia mencionados neste conteúdo não são mais suportados.
Um projeto MLflow é um formato para empacotar o código de ciência de dados de forma reutilizável e reproduzível. O componente MLflow Projects inclui as ferramentas API e comando-line para executar projetos, que também se integram ao componente de acompanhamento para registrar automaticamente os parâmetros e o git commit do seu código-fonte para fins de reprodutibilidade.
Este artigo descreve o formato de um projeto MLflow e como executar um projeto MLflow remotamente em Databricks clustering usando o MLflow CLI, o que facilita o escalonamento vertical do código de ciência de dados.
A execução do projeto MLflow não é compatível com o Databricks Free Edition.
Formato do projeto MLflow
Qualquer diretório local ou repositório Git pode ser tratado como um projeto MLflow. As convenções a seguir definem um projeto:
- O nome do projeto é o nome do diretório.
- O ambiente de software é especificado em
python_env.yaml, se houver. Se nenhum arquivopython_env.yamlestiver presente, o MLflow usará um ambiente virtualenv contendo apenas Python (especificamente, o Python mais recente disponível para o virtualenv) ao executar o projeto. - Qualquer arquivo
.pyou.shno projeto pode ser um ponto de entrada, sem parâmetros declarados explicitamente. Quando o senhor executa um comando desse tipo com um conjunto de parâmetros, o site MLflow passa cada parâmetro na linha do comando usando a sintaxe--key <value>.
Você especifica mais opções adicionando um arquivo MLProject, que é um arquivo de texto na sintaxe YAML. Um exemplo de arquivo MLProject tem a seguinte aparência:
name: My Project
python_env: python_env.yaml
entry_points:
main:
parameters:
data_file: path
regularization: { type: float, default: 0.1 }
command: 'python train.py -r {regularization} {data_file}'
validate:
parameters:
data_file: path
command: 'python validate.py {data_file}'
Para Databricks Runtime 13.0 ML e acima, os projetos MLflow não podem ser executados com êxito em um cluster do tipo de trabalho Databricks. Para migrar os projetos MLflow existentes para Databricks Runtime 13.0 ML e acima, consulte MLflow Databricks Spark Formato de projeto de trabalho.
MLflow Databricks Formato do projeto de trabalho Spark
MLflow Databricks Spark O projeto de trabalho é um tipo de projeto MLflow introduzido em MLflow 2.14. Esse tipo de projeto é compatível com a execução de MLflow Projects em um clustering de Spark Jobs e só pode ser executado usando o backend databricks.
Databricks Spark Os projetos de trabalho devem definir databricks_spark_job.python_file ou entry_points. Não especificar nenhuma delas ou especificar as duas configurações gera uma exceção.
Veja a seguir um exemplo de um arquivo MLproject que usa a configuração databricks_spark_job.python_file. Essa configuração envolve o uso de um caminho codificado para o arquivo de execução do Python e seus argumentos.
name: My Databricks Spark job project 1
databricks_spark_job:
python_file: 'train.py' # the file which is the entry point file to execute
parameters: ['param1', 'param2'] # a list of parameter strings
python_libraries: # dependencies required by this project
- mlflow==2.4.1 # MLflow dependency is required
- scikit-learn
Veja a seguir um exemplo de um arquivo MLproject que usa a configuração entry_points:
name: My Databricks Spark job project 2
databricks_spark_job:
python_libraries: # dependencies to be installed as databricks cluster libraries
- mlflow==2.4.1
- scikit-learn
entry_points:
main:
parameters:
model_name: { type: string, default: model }
script_name: { type: string, default: train.py }
command: 'python {script_name} {model_name}'
A configuração entry_points permite que o senhor passe parâmetros que estão usando parâmetros de linha de comando, como:
mlflow run . -b databricks --backend-config cluster-spec.json \
-P script_name=train.py -P model_name=model123 \
--experiment-id <experiment-id>
As seguintes limitações se aplicam aos projetos do Databricks Spark Job:
- Esse tipo de projeto não suporta a especificação das seguintes seções no arquivo
MLproject:docker_env,python_envouconda_env. - As dependências do seu projeto devem ser especificadas no campo
python_librariesda seçãodatabricks_spark_job. As versões do Python não podem ser personalizadas com esse tipo de projeto. - O ambiente de execução deve usar o ambiente principal de tempo de execução do driver Spark para execução em clustering de trabalho que usa Databricks Runtime 13.0 ou superior.
- Da mesma forma, todas as dependências do Python definidas como necessárias para o projeto devem ser instaladas como dependências de clustering do Databricks. Esse comportamento é diferente dos comportamentos anteriores de execução de projetos em que a biblioteca precisava ser instalada em um ambiente separado.
execução e MLflow projeto
Para executar um projeto MLflow em um cluster Databricks no default workspace, use o comando:
mlflow run <uri> -b databricks --backend-config <json-new-cluster-spec>
em que <uri> é um URI de repositório Git ou uma pasta que contém um projeto MLflow e <json-new-cluster-spec> é um documento JSON que contém uma estrutura new_cluster. O URI do Git deve ter o formato: https://github.com/<repo>#<project-folder>.
Um exemplo de especificação de clustering é:
{
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "i3.xlarge"
}
Se o senhor precisar instalar o biblioteca no site worker, use o formato "clustering specification" (especificação de agrupamento). Observe que os arquivos Python wheel devem ser carregados em DBFS e especificados como dependências pypi. Por exemplo:
{
"new_cluster": {
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "i3.xlarge"
},
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
},
{
"pypi": {
"package": "/dbfs/path_to_my_lib.whl"
}
}
]
}
.egge.jarnão são compatíveis com os projetos MLflow.- Não há suporte para a execução de projetos MLflow com ambientes Docker.
- O senhor deve usar uma nova especificação de clustering ao executar um projeto MLflow em Databricks. Não há suporte para a execução de projetos em relação ao clustering existente.
Usando o SparkR
Para usar o SparkR em uma execução de projeto do MLflow, o código do projeto deve primeiro instalar e importar o SparkR da seguinte forma:
if (file.exists("/databricks/spark/R/pkg")) {
install.packages("/databricks/spark/R/pkg", repos = NULL)
} else {
install.packages("SparkR")
}
library(SparkR)
Seu projeto pode então inicializar uma sessão do SparkR e usar o SparkR normalmente:
sparkR.session()
...
Exemplo
Este exemplo mostra como criar um experimento, executar o projeto MLflow tutorial em um clustering Databricks, view a saída da execução do trabalho e view a execução no experimento.
Requisitos
- Instale o MLflow usando
pip install mlflow. - Instalar e configurar a CLI da Databricks. O mecanismo de autenticação Databricks CLI é necessário para executar o trabalho em um cluster Databricks.
Etapa 1: criar um experimento
-
No site workspace, selecione Create > MLflow Experiment .
-
No campo Nome, digite
Tutorial. -
Clique em Criar . Anote o ID do experimento. Neste exemplo, é
14622565.
Etapa 2: execução do projeto MLflow tutorial
As passos a seguir configuram a variável de ambiente MLFLOW_TRACKING_URI e executam o projeto, registrando os parâmetros de treinamento, as métricas e o modelo treinado para o experimento observado na passo anterior:
-
Ajuste a
MLFLOW_TRACKING_URIvariável de ambiente para Databricks workspace.Bashexport MLFLOW_TRACKING_URI=databricks -
execução do projeto MLflow tutorial , treinamento a wine model. Substitua
<experiment-id>pela ID do experimento que você anotou na etapa anterior.Bashmlflow run https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine -b databricks --backend-config cluster-spec.json --experiment-id <experiment-id>Console=== Fetching project from https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine into /var/folders/kc/l20y4txd5w3_xrdhw6cnz1080000gp/T/tmpbct_5g8u ===
=== Uploading project to DBFS path /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz ===
=== Finished uploading project to /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz ===
=== Running entry point main of project https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine on Databricks ===
=== Launched MLflow run as Databricks job run with ID 8651121. Getting run status page URL... ===
=== Check the run's status at https://<databricks-instance>#job/<job-id>/run/1 === -
Copie o URL
https://<databricks-instance>#job/<job-id>/run/1na última linha da saída da execução do MLflow.
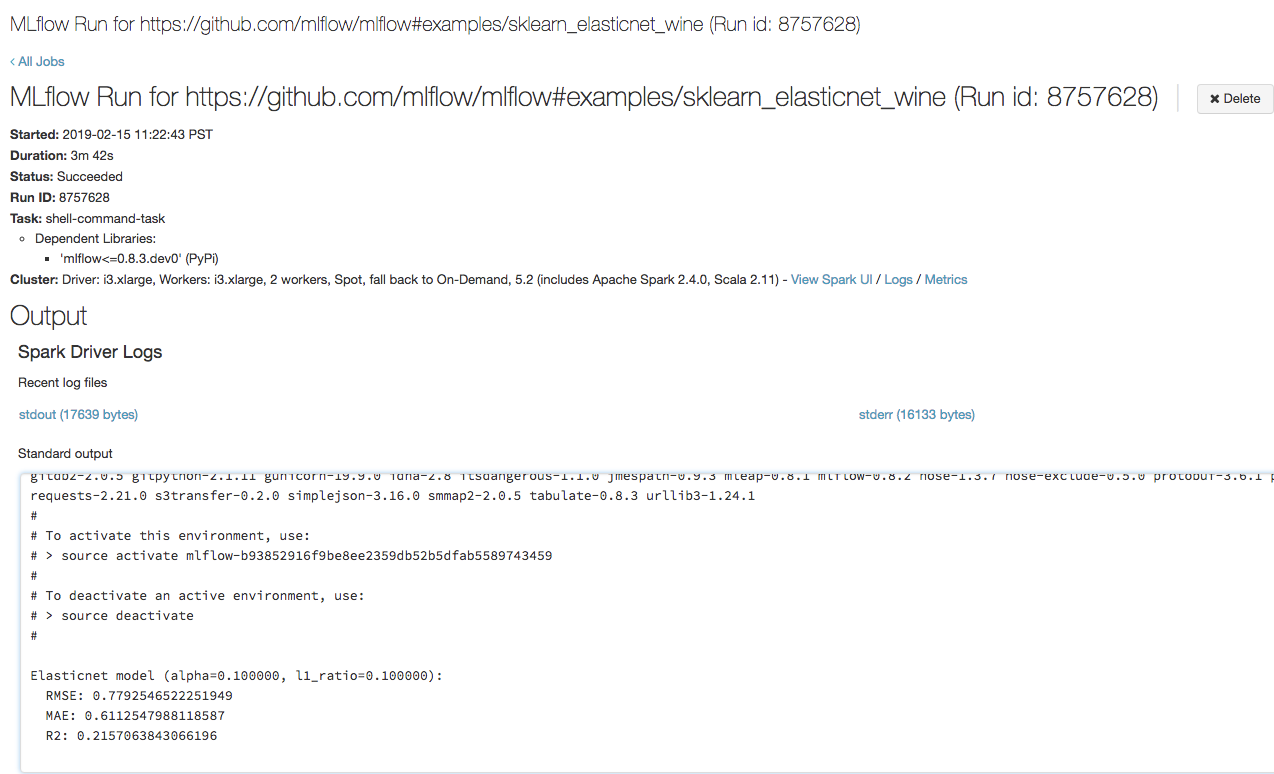
Etapa 3: visualizar o site Databricks Execução do trabalho
-
Abra a URL que você copiou na passo anterior em um navegador para view a saída de execução Job do Databricks:
Etapa 4: visualizar o experimento e MLflow detalhes da execução
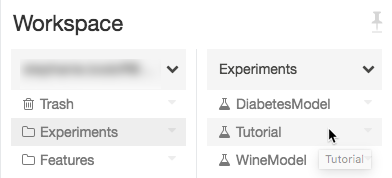
-
Navegue até o experimento em seu site Databricks workspace.
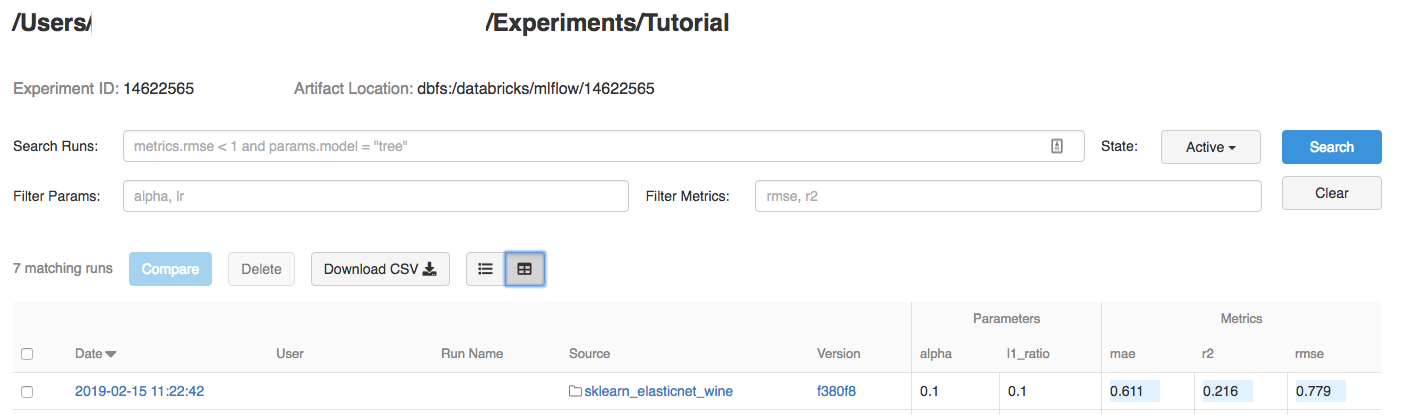
-
Clique no experimento.
-
Para exibir detalhes da execução, clique em um link na coluna Date (Data).
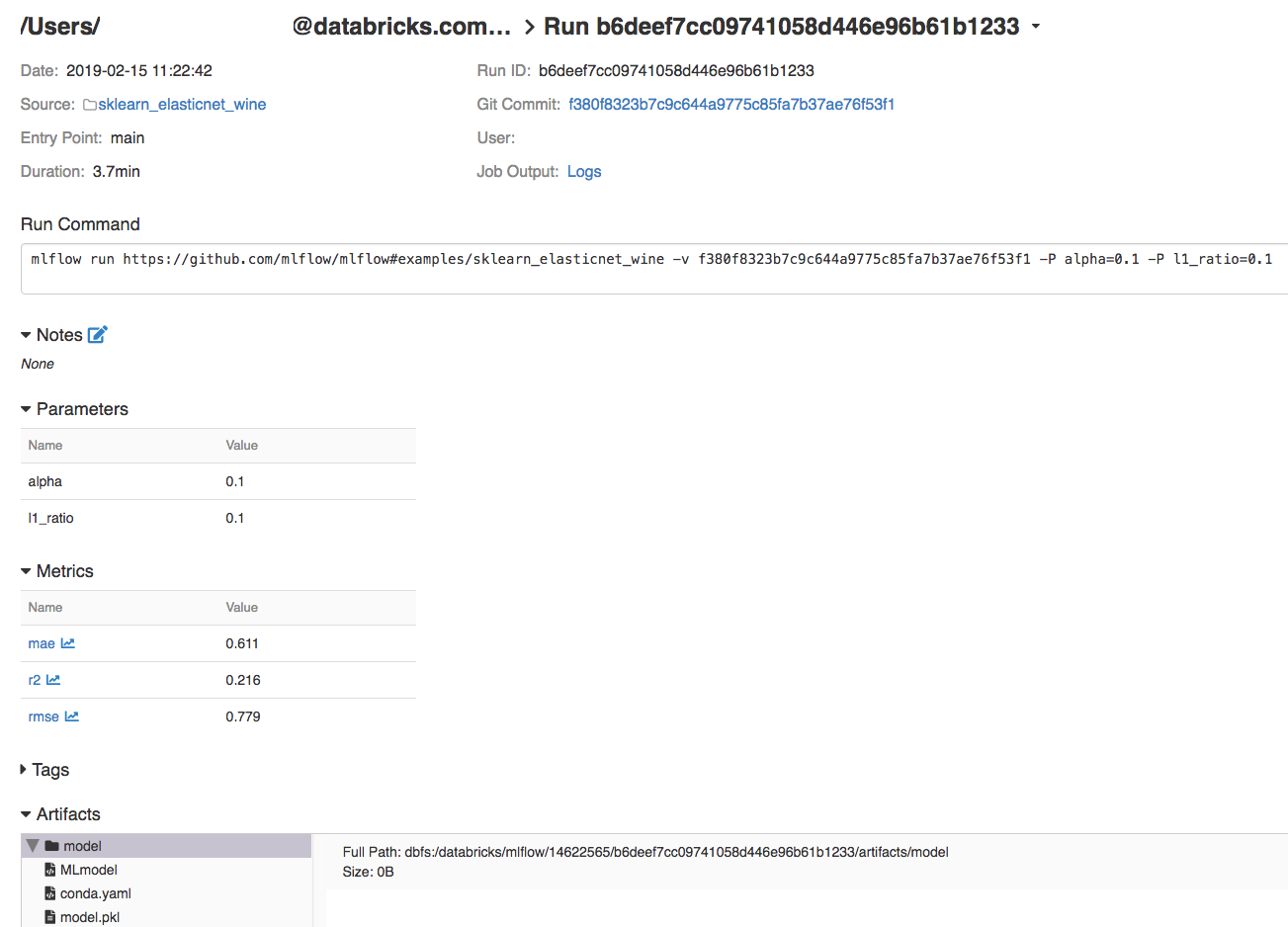
O senhor pode view logs de sua execução clicando no link logs no campo Job Output.
recurso
Para obter alguns exemplos de projetos MLflow, consulte a bibliotecaMLflow App, que contém um repositório de projetos prontos para execução com o objetivo de facilitar a inclusão da funcionalidade ML em seu código.