sem servidor compute para Notebook
Este artigo explica como usar o site serverless compute para Notebook. Para obter informações sobre como usar serverless compute para Job, consulte executar seus LakeFlow Jobs com serverless compute para fluxo de trabalho.
Para obter informações sobre preços sobre o uso compute serverless no Notebook, consulte PreçosDatabricks.
Requisitos
- Seu workspace deve estar habilitado para o Unity Catalog.
- Seu workspace deve estar em uma região compatível com o serverless compute. Consulte Databricks clouds e regiões.
Anexe um notebook ao site serverless compute
Se o seu workspace estiver habilitado para compute interativo serverless, todos os usuários no workspace terão acesso ao compute serverless para notebooks. Nenhuma permissão adicional é necessária.
Para conectar-se ao compute serverless, clique no menu suspenso Conectar no notebook e selecione Serverless . Para novos notebooks, o compute anexado automaticamente será definido como serverless após a execução do código, caso nenhum outro recurso tenha sido selecionado.
view query percepções
serverless compute para Notebook e Job usa percepções de consulta para avaliar o desempenho da execução do Spark. Depois de executar uma célula em um Notebook, o senhor pode view percepções relacionadas às consultas SQL e Python clicando no link See desempenho .
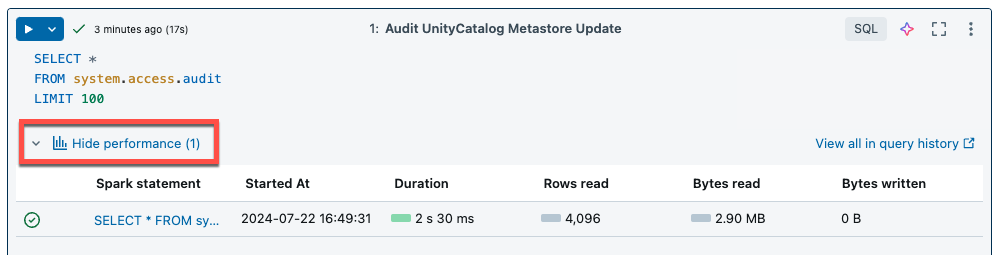
O senhor pode clicar em qualquer um dos extratos Spark para view as métricas de consulta. A partir daí, você pode clicar em Ver perfil de consulta para ver uma visualização da execução da consulta. Para obter mais informações sobre perfis de consulta, consulte Perfil de consulta.
Para view percepções de desempenho para sua execução de trabalho, consulte visualizar percepções de consulta de execução de trabalho.
Histórico de consultas
Todas as consultas executadas no site serverless compute também serão registradas na página de histórico de consultas do site workspace. Para obter informações sobre a história da consulta, consulte História da consulta.
Limitações de entendimento da consulta
- O perfil da consulta só está disponível após o término da execução da consulta.
- As métricas são atualizadas ao vivo, embora o perfil da consulta não seja mostrado durante a execução.
- Apenas os seguintes status de consulta são cobertos: EM EXECUÇÃO, CANCELADO, FALHOU, FINALIZADO.
- Consultas em execução não podem ser canceladas a partir da página de histórico de consultas. Elas podem ser canceladas em notebooks ou jobs.
- Métricas detalhadas não estão disponíveis.
- Download do Perfil de Consulta não está disponível.
- Acesso ao Spark UI não está disponível.
- O texto da declaração contém apenas a última linha executada. No entanto, pode haver várias linhas anteriores a esta linha que foram executadas como parte da mesma declaração.
proteção contra gastos excessivos sem servidor
Para controlar as consultas de longa duração, o serverless Notebook tem um tempo limite de execução default de 2,5 horas. O senhor pode definir manualmente a duração do tempo limite configurando spark.databricks.execution.timeout no Notebook. Consulte Configurar as propriedades do Spark para serverless Notebook e Job.