Controle de acesso refinado em sistemas dedicados compute
O controle de acesso refinado permite restringir o acesso a visualizações específicas de uso de dados, filtros de linha e máscaras de coluna. Esta página explica como o serverless compute é usado para impor controles de acesso refinados no recurso dedicado compute.
Dedicado compute é multifuncional ou Job compute configurado com o modo de acesso Dedicado (anteriormente, modo de acesso de usuário único). Consulte Modos de acesso.
Requisitos
Para usar o site compute dedicado para consultar um view ou uma tabela com controles de acesso refinados:
- O recurso dedicado compute deve estar em Databricks Runtime 15.4 LTS ou acima.
- O workspace deve estar habilitado para serverless compute .
Se o seu compute recurso dedicado e o workspace atenderem a esses requisitos, a filtragem de dados será executada automaticamente.
Como funciona a filtragem de dados em computededicada
Sempre que uma consulta acessa um objeto de banco de dados com controles de acesso refinados, o recurso dedicado compute passa a consulta para o seu workspace's serverless compute para realizar a filtragem de dados. Os dados filtrados são então transferidos entre o serverless e o compute dedicado usando arquivos temporários no armazenamento em nuvem interno do workspace.
Databricks transfere o uso de dados filtrado do Cloud Fetch, uma funcionalidade que grava conjuntos de resultados temporários no armazenamento interno workspace ( DBFS root do seu workspace). O Databricks coleta automaticamente esses arquivos como lixo, marcando-os para exclusão após 24 horas e excluindo-os permanentemente após mais 24 horas.
Se você habilitar o versionamento de bucketsS3 na DBFS root, Databricks não poderá coletar o lixo de versões antigas de conjuntos de resultados temporários. Isso pode levar a um crescimento exponencial do armazenamento, à medida que versões desatualizadas dos arquivos se acumulam. Consulte as considerações sobre versionamento de buckets S3 para obter recomendações de configuração.
Essa funcionalidade se aplica aos seguintes objetos de banco de dados:
- Visualização dinâmica
- Tabelas com filtros de linha ou máscaras de coluna
- visualização criada sobre tabelas nas quais o usuário não tem o privilégio
SELECT - Visualizações materializadas
- Tabelas de streaming
No diagrama a seguir, um usuário tem o privilégio SELECT em table_1, view_2 e table_w_rls, que tem filtros de linha aplicados. O usuário não tem o privilégio SELECT em table_2, que é referenciado por view_2.
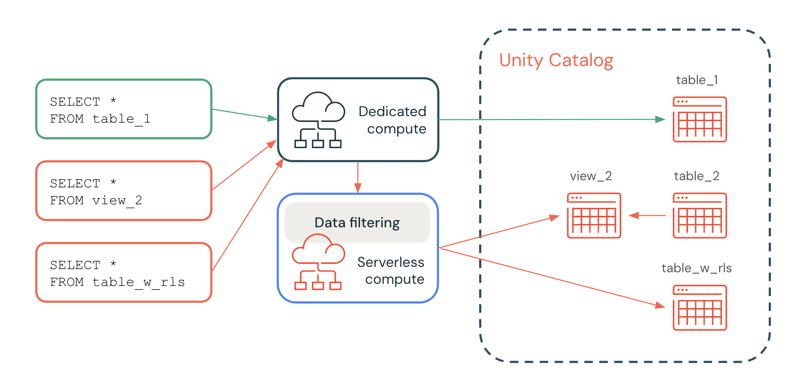
A consulta em table_1 é tratada inteiramente pelo recurso dedicado compute, pois não é necessária nenhuma filtragem. As consultas em view_2 e table_w_rls exigem filtragem de dados para retornar os dados aos quais o usuário tem acesso. Essas consultas são tratadas pelo recurso de filtragem de dados em serverless compute.
Suporte para operações de gravação
Visualização
Esse recurso está em Public Preview.
Em Databricks Runtime 16.3 e acima, o senhor pode gravar em tabelas que tenham filtros de linha ou máscaras de coluna aplicados, usando essas opções:
- O comando MERGE INTO SQL, que o senhor pode usar para obter as funcionalidades
INSERT,UPDATEeDELETE. - O site Delta merge operações.
- A API
DataFrame.write.mode("append").
Para obter a funcionalidade INSERT, UPDATE e DELETE, você pode usar uma tabela intermediária e as cláusulas WHEN MATCHED e WHEN NOT MATCHED da declaração MERGE INTO.
Veja a seguir um exemplo de um UPDATE usando MERGE INTO:
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN MATCHED THEN
UPDATE SET
t.column1 = s.column1,
t.column2 = s.column2;
O exemplo a seguir é de um INSERT usando MERGE INTO:
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN NOT MATCHED THEN
INSERT (id, column1, column2) VALUES (s.id, s.column1, s.column2);
O exemplo a seguir é de um DELETE usando MERGE INTO:
MERGE INTO target_table AS t
USING source_table AS s ON t.id = s.id
WHEN MATCHED AND s.some_column = TRUE THEN DELETE;
Suporte para DDL, SHOW, DESCRIBE e outros comandos
Em Databricks Runtime 17.1 e acima, o senhor pode usar o seguinte comando em combinação com objetos de controle de acesso com granularidade fina em compute dedicado:
- Declarações DDL
- MOSTRAR declarações
- DESCREVA as declarações
- OPTIMIZE
- DESCRIBE HISTORY
- FSCK REPAIR TABLE (Databricks Runtime 17.2 e acima)
Se necessário, esses comandos são executados automaticamente no site serverless compute.
Alguns comandos não são suportados, incluindo VACCUM, RESTORE, e REORG TABLE.
sem servidor compute custos
Os clientes são cobrados pelo recurso serverless compute que realiza operações de filtragem de dados. Para obter informações sobre preços, consulte Platform Tiers and Add-Ons.
Os usuários com acesso podem consultar a tabela system.billing.usage para ver quanto foram cobrados. Por exemplo, a consulta a seguir detalha os custos do compute por usuário:
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
Esta consulta mostra os custos compute para o uso do controle de acesso granular (FGAC), mas não inclui os custos de armazenamento para arquivos de resultados temporários acumulados. Se o versionamento de buckets S3 estiver ativado, as versões de arquivo não atuais não serão contabilizadas nas consultas de faturamento padrão, mas ainda assim gerarão cobranças de armazenamento.
desempenho da consulta de visualização quando a filtragem de dados está ativada
O Spark UI para compute dedicado exibe métricas que podem ser utilizadas para compreender o desempenho das suas consultas. Para cada consulta que você executar no recurso “ compute ”, o SQL/Dataframe tab exibe a representação gráfica da consulta. Se uma consulta estiver envolvida na filtragem de dados, a interface do usuário exibirá um nó do operador RemoteSparkConnectScan na parte inferior do gráfico. Esse nó exibe métricas que podem ser utilizadas para investigar o desempenho da consulta. Consulte a informação em compute na página Spark UI.
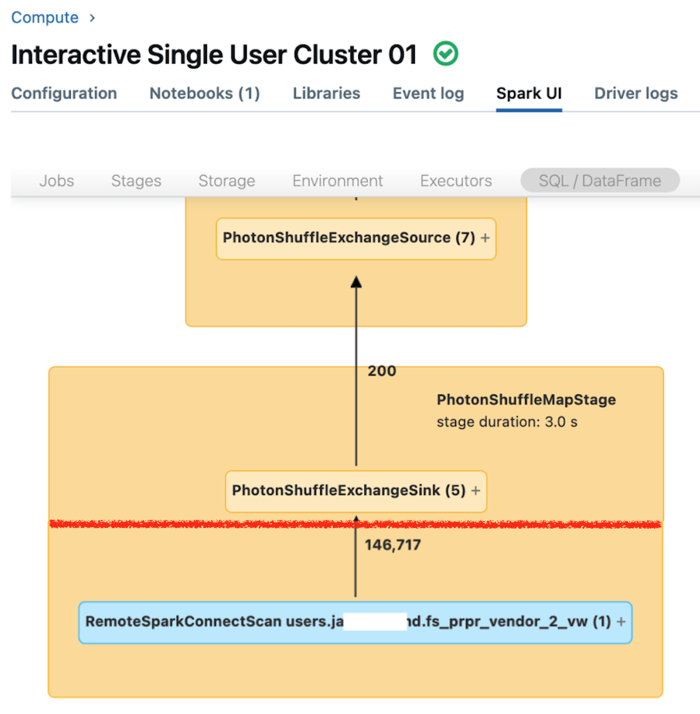
Expanda o nó do operador RemoteSparkConnectScan para ver as métricas que abordam questões como as seguintes:
- Quanto tempo demorou a filtragem de dados? visualizar "tempo total de execução remota".
- Quantas linhas permaneceram após a filtragem de dados? visualizar "saída de linhas".
- Quantos dados (em bytes) foram retornados após a filtragem de dados? visualizar "tamanho da saída das linhas".
- Quantos arquivos de dados foram removidos por partição e não precisaram ser lidos do armazenamento? visualize "Files pruned" (Arquivos removidos) e "Size of files pruned" (Tamanho dos arquivos removidos).
- Quantos arquivos de dados não puderam ser removidos e precisaram ser lidos do armazenamento? visualize "Files read" (Arquivos lidos) e "Size of files read" (Tamanho dos arquivos lidos).
- Dos arquivos que precisavam ser lidos, quantos já estavam no cache? visualize "Cache hits size" e "Cache misses size".
Limitações
-
Somente as leituras de lotes são compatíveis com as tabelas de transmissão. As tabelas com filtros de linha ou máscaras de coluna não são compatíveis com cargas de trabalho de transmissão em compute dedicado.
-
O catálogo default (
spark.sql.catalog.spark_catalog) não pode ser modificado. -
Em Databricks Runtime 16.2 e abaixo, não há suporte para operações de gravação ou refresh em tabelas que tenham filtros de linha ou máscaras de coluna aplicados.
Especificamente, as operações DML, como
INSERT,DELETE,UPDATE,REFRESH TABLEeMERGE, não são compatíveis. Você só pode ler (SELECT) dessas tabelas. -
Em Databricks Runtime 16.3 e acima, operações de tabela de gravação como
INSERT,DELETEeUPDATEnão são compatíveis, mas podem ser feitas usandoMERGE, que é compatível. -
Ao usar
DeltaTable.forName()ouDeltaTable.forPath()em compute dedicada com tabelas habilitadas para FGAC, somente as operaçõesmerge()etoDF()são suportadas. Para outras operações DeltaTable, use o comando SQL correspondente. Por exemplo, em vez dehistory(), useDESCRIBE HISTORYe em vez declone(), useSHALLOW CLONEouDEEP CLONE. -
Em Databricks Runtime 16.2 e abaixo, o self-join é bloqueado por default quando a filtragem de dados é chamada porque essas consultas podem retornar diferentes Snapshot da mesma tabela remota. No entanto, o senhor pode ativar essas consultas definindo
spark.databricks.remoteFiltering.blockSelfJoinscomofalseem compute no qual está executando esse comando.Em Databricks Runtime 16.3 e acima, o Snapshot é sincronizado automaticamente entre o dedicado e serverless compute recurso. Devido a essa sincronização, as consultas autojoin que usam a funcionalidade de filtragem de dados retornam Snapshot idênticos e são ativadas por default. As exceções são a visualização materializada e qualquer visualização, visualização materializada e tabelas de transmissão compartilhadas usando Delta Sharing. Para esses objetos, o self-join é bloqueado por default, mas é possível habilitar essas consultas definindo
spark.databricks.remoteFiltering.blockSelfJoinscomo false em compute no qual o comando está sendo executado.Se o senhor ativar as consultas autojoin para a visualização materializada e qualquer visualização, visualização materializada e tabelas de transmissão, deverá garantir que não haja gravações concorrentes nos objetos que estão sendo unidos.
-
Não há suporte em Docker Image.
-
Não há suporte ao usar o Databricks Container Services.
-
Se o seu workspace foi implantado com um firewall antes de novembro de 2024, o senhor deve abrir as portas 8443 e 8444 para permitir o controle de acesso refinado no compute dedicado. Consulte Grupos de segurança.