Solução de problemas compute
Este artigo fornece recursos que podem ser usados caso o senhor precise solucionar problemas de comportamento do compute no seu workspace. Os tópicos deste artigo estão relacionados a compute start-up questões.
Para obter outros artigos de solução de problemas, consulte:
- depuração com o Spark UI
- Diagnosticar problemas de custo e desempenho usando o Spark UI
- Tratamento de consultas de grande porte em fluxo de trabalho interativo.
Use o Assistente para depurar erros do ambiente compute
O Databricks Assistant pode ajudar a diagnosticar e sugerir correções para erros de instalação da biblioteca.
Na página da biblioteca do compute, uma ![]() O botão Diagnosticar erro aparece ao lado do nome do pacote com falha e no modal de detalhes que aparece quando você clica no pacote com falha. Clique
O botão Diagnosticar erro aparece ao lado do nome do pacote com falha e no modal de detalhes que aparece quando você clica no pacote com falha. Clique ![]() Diagnostique o erro para usar o Assistente para ajudar na depuração. O Assistente diagnosticará o erro e sugerirá possíveis soluções.
Diagnostique o erro para usar o Assistente para ajudar na depuração. O Assistente diagnosticará o erro e sugerirá possíveis soluções.
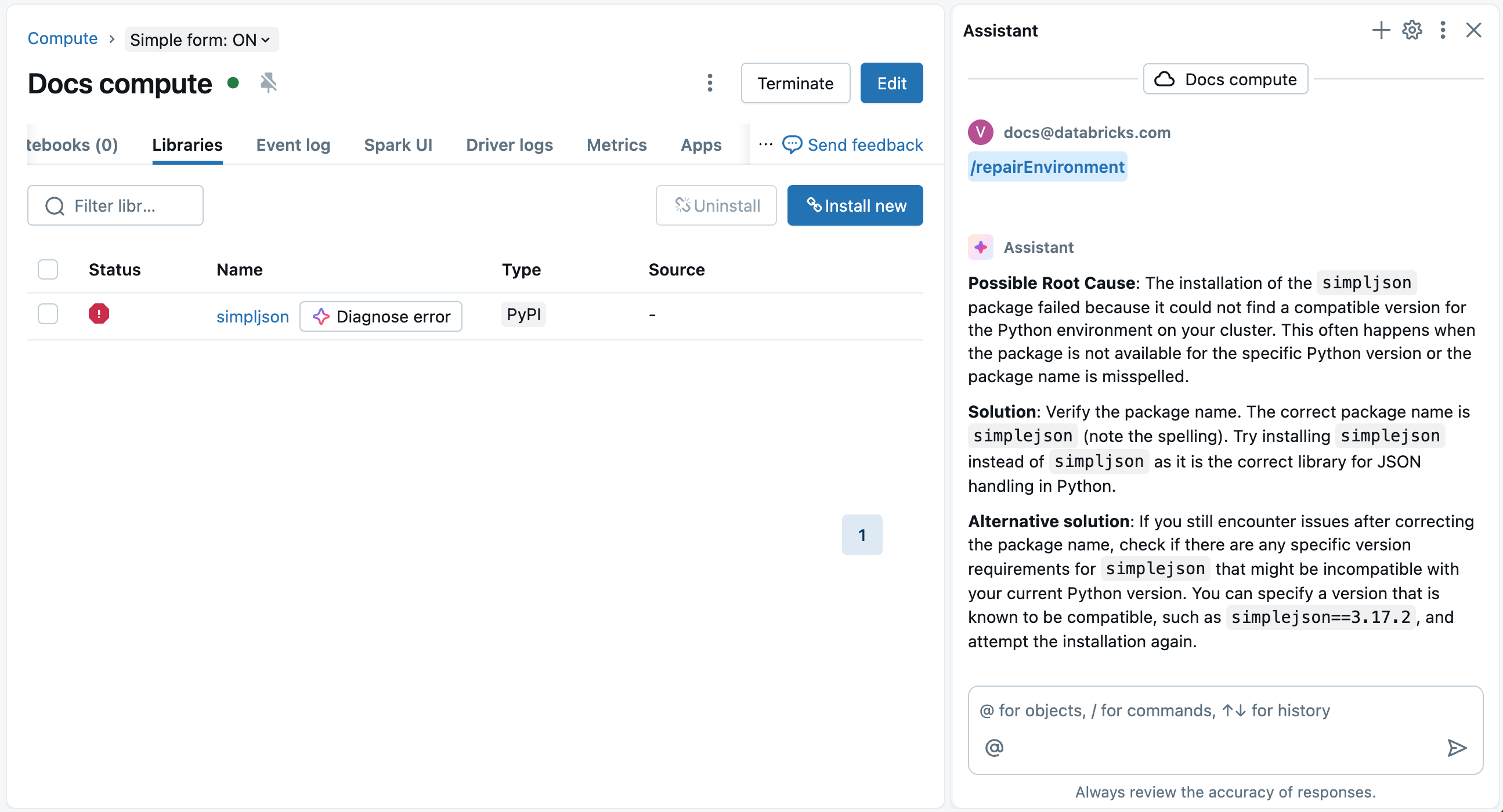
Você também pode usar o Assistente para depurar erros do ambiente compute em um Notebook. Veja Erros do ambiente de depuração.
Um novo compute não responde
Depois do que parece ser uma implementação bem-sucedida do workspace, o senhor pode perceber que o primeiro teste compute não responde. Após aproximadamente 20-30 minutos, verifique o eventocompute log . Você pode ver uma mensagem de erro semelhante a:
The compute plane network is misconfigured. Please verify that the network for your compute plane is configured correctly. Error message: Node daemon ping timeout in 600000 ms ...
Essa mensagem indica que o roteamento ou o firewall estão incorretos. Databricks solicitou instâncias do EC2 para um novo compute, mas encontrou um longo atraso aguardando que a instância do EC2 iniciasse e se conectasse ao plano de controle. O gerenciador compute encerra as instâncias e relata esse erro.
Sua configuração de rede deve permitir que compute as instâncias do nó se conectem com sucesso ao Databricks plano de controle. Para uma técnica de solução de problemas mais rápida do que usar um compute, o senhor pode implantar uma instância do EC2 em uma das sub-redes do workspace e executar as etapas típicas de solução de problemas de rede, como nc, ping, telnet, traceroute, etc. O Relay CNAME para cada região é mencionado nos artigos do customer-gerenciar VPC. Para o armazenamento de artefatos, certifique-se de que haja um caminho de rede bem-sucedido para o S3.
Para domínios de acesso e IPs por região, consulte Endereços IP e domínios para Databricks serviço e ativo. Para o ponto de extremidade regional, consulte (Recomendado) Configurar o ponto de extremidade regional. O exemplo a seguir usa a região do AWS eu-west-1:
# Verify access to the web application
nc -zv ireland.cloud.databricks.com 443
# Verify access to the secure compute connectivity relay
nc -zv tunnel.eu-west-1.cloud.databricks.com 443
# Verify S3 global and regional access
nc -zv s3.amazonaws.com 443
nc -zv s3.eu-west-1.amazonaws.com 443
# Verify STS global and regional access
nc -zv sts.amazonaws.com 443
nc -zv sts.eu-west-1.amazonaws.com 443
# Verify regional Kinesis access
nc -zv kinesis.eu-west-1.amazonaws.com 443
Se tudo isso retornar corretamente, a rede poderá estar configurada corretamente, mas pode haver outro problema se você estiver usando um firewall.O firewall pode ter uma inspeção profunda de pacotes, inspeção de SSL ou qualquer outra coisa que faça com que os comandos do Databricks falhem.Usando uma instância do EC2 na sub-rede do Databricks, tente o seguinte:
curl -X GET -H 'Authorization: Bearer <token>' \
https://<workspace-name>.cloud.databricks.com/api/2.0/clusters/spark-versions
Substitua <token> por seus próprios tokens de acesso pessoal e use o URL correto para seu workspace. Consulte o gerenciamento de tokens API.
Se esta solicitação falhar, experimente a opção -k com sua solicitação para remover a verificação de SSL. Se isso funcionar com a opção -k, então o firewall estará causando um problema com certificados SSL.
Veja os certificados SSL usando o seguinte e substitua o nome do domínio pelo domínio do aplicativo da Web do plano de controle da sua região:
openssl s_client -showcerts -connect oregon.cloud.databricks.com:443
Esse comando mostra o código de retorno e os certificados da Databricks. Se ele retornar um erro, é um sinal de que seu firewall está configurado incorretamente e deve ser corrigido.
Observe que os problemas de SSL não são um problema de camada de rede. A visualização do tráfego no firewall não mostrará esses problemas de SSL. Observar as solicitações de origem e destino funcionará conforme o esperado.
Problemas ao usar seu metastore ou o evento compute log inclui METASTORE_DOWN eventos
Se o seu workspace parece estar funcionando e o senhor pode configurar o compute, mas tem eventos METASTORE_DOWN no seu eventocompute logs , ou se o seu metastore parece não funcionar, confirme se o senhor usa um Web Application Firewall (WAF) como o proxy Squid. os membros da computação devem se conectar a vários serviços que não funcionam em um WAF.
compute começar error: failed to launch Spark container on instance
O senhor poderá ver um erro compute log como, por exemplo, o seguinte:
Cluster start error: failed to launch spark container on instance ...
Exception: Could not add container for ... with address ....
Timed out with exception after 1 attempts
Esse errocompute log provavelmente se deve ao fato de a instância não conseguir usar o STS para entrar no bucket S3 raiz. Isso geralmente acontece quando o senhor está implementando a proteção contra exfiltração, usando o endpoint VPC para bloquear a comunicação ou adicionando um firewall.
Para corrigir, faça uma das seguintes coisas:
- Altere o firewall para permitir a passagem do endpoint STS global (
sts.amazonaws.com), conforme documentado nos documentos de requisitos da VPC. - Use um VPC endpoint para configurar o endpointregional.
Para obter mais informações sobre o erro, chame o comando AWS CLI da decode-authorization-message. Para obter detalhes, consulte o artigo da AWS para decode-authorization-message. O comando tem a seguinte aparência:
aws sts decode-authorization-message --encoded-message
Você poderá ver esse erro se configurar um endpoint VPC (VPCE) com um grupo de segurança diferente para o STS VPCE em relação aos workspaces.Você pode atualizar os grupos de segurança para permitir que os recursos em cada grupo de segurança conversem entre si ou colocar o STS VPCE no mesmo grupo de segurança que as sub-redes do workspace.
Os nós de computação precisam usar o STS para acessar o bucket S3 raiz usando a política S3 do cliente. Um caminho de rede deve estar disponível para o serviço AWS STS a partir dos nós Databricks compute .