visualizar a linhagem de dados usando Unity Catalog
Esta página descreve como visualizar a linhagem de dados usando o Catalog Explorer e as tabelas do sistema de linhagem de dados.
Visão geral da linhagem de dados
O Unity Catalog captura a linhagem de dados em tempo de execução em todas as consultas executadas no Databricks. A linhagem é suportada para todos os idiomas e é capturada até o nível da coluna. Os dados de linhagem incluem Notebooks, Jobs e dashboards relacionados à consulta. A linhagem pode ser visualizada no Catalog Explorer em tempo quase real e recuperada programaticamente usando as tabelas do sistema de linhagem.
A linhagem também pode incluir ativos externos e fluxo de trabalho que são executados fora do site Databricks. Esse recurso de metadados de linhagem externa está em Public Preview. Consulte Traga sua própria linhagem de dados.
A linhagem é agregada em todos os espaços de trabalho anexados a um metastore Unity Catalog. Isso significa que a linhagem capturada em um workspace é visível em qualquer outro workspace que compartilhe esse metastore. Especificamente, as tabelas e outros objetos de dados registrados no metastore são visíveis para os usuários que têm pelo menos BROWSE permissões nesses objetos, em todos os espaços de trabalho anexados ao metastore. No entanto, as informações detalhadas sobre objetos de nível workspace, como Notebook e dashboards em outro espaço de trabalho, são ocultadas (consulte Limitações de linhagem e Permissões de linhagem).
Os dados de linhagem exibidos no Explorador de Catálogo ou retornados pela API são retidos indefinidamente. Todos os dados de linhagem coletados após 1º de setembro de 2024 estão disponíveis. Para metastores criados após essa data, o Explorador de Catálogo inclui uma opção "Todo o período" na dropdown de intervalo de tempo da linhagem. Para metastores mais antigos, o dropdown inclui uma opção "Todos disponíveis" que começa a partir de 1º de setembro de 2024. A seleção default é 1 ano . As tabelas do sistema de linhagem (system.access.table_lineage e system.access.column_lineage) retêm uma janela móvel de dados de 1 ano. Consulte a tabela de referência do sistema de linhagem.
A imagem a seguir é um exemplo de gráfico de linhagem. Os nós no gráfico podem representar várias atividades, incluindo tabelas e visualizações, versões de modelos ML , atividades externas e caminhos de arquivos.
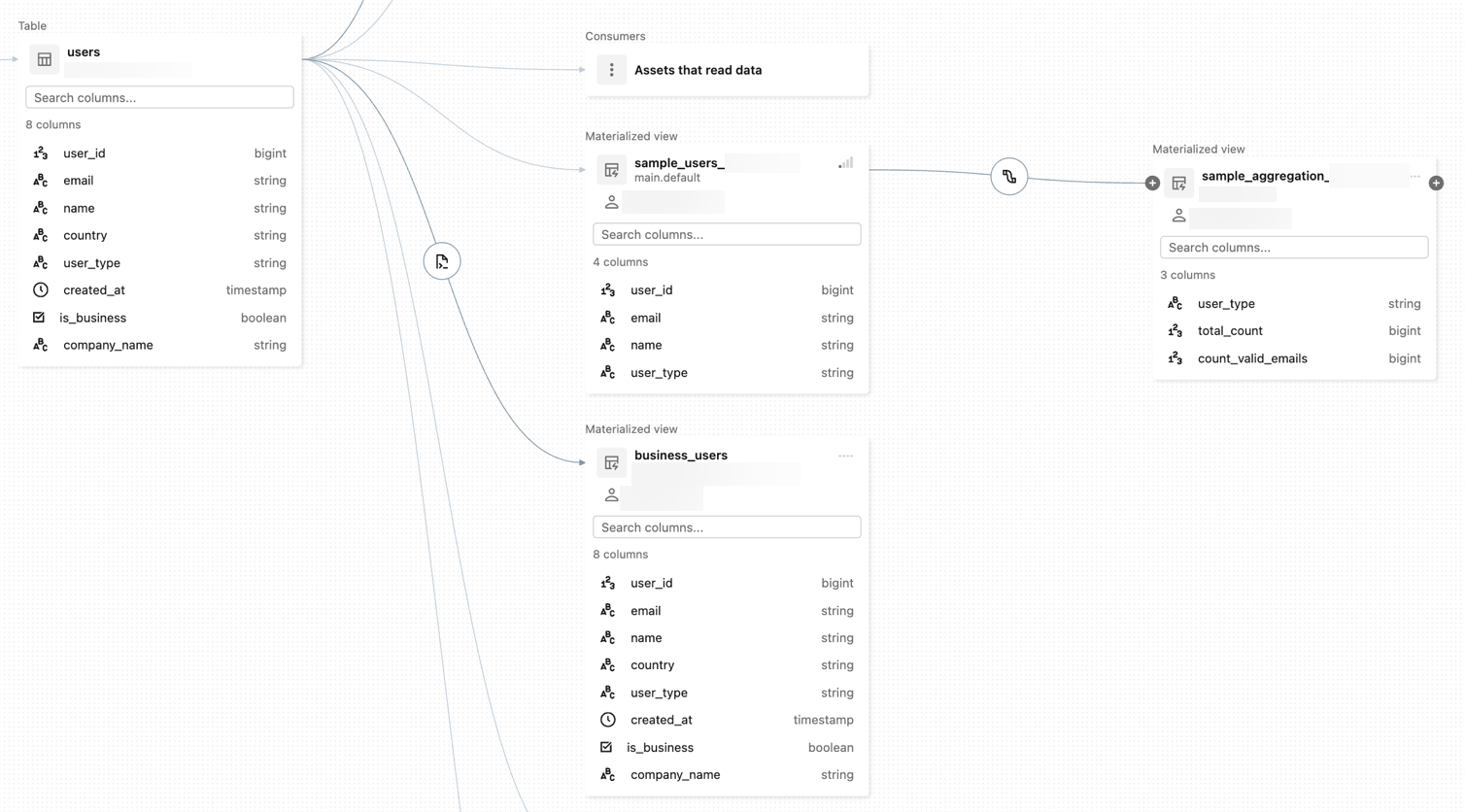
Para uma demonstração de visualização da linhagem de dados, consulte Unity Catalog - linhagem de dados.
Para obter informações sobre o acompanhamento da linhagem de um modelo do aprendizado de máquina, consulte Acompanhar a linhagem de dados de um modelo Unity Catalog em.
Requisitos
Para capturar a linhagem de dados usando o Unity Catalog:
- As tabelas devem ser registradas em um metastore do Unity Catalog.
- Os ativos externos (aqueles não registrados no metastore Unity Catalog ) devem ser adicionados como objetos de metadados externos em Unity Catalog, configurados para ter relacionamentos com outros objetos protegíveis registrados no metastore Unity Catalog. Consulte Traga sua própria linhagem de dados.
- As consultas devem usar o Spark DataFrame (por exemplo, Spark SQL funções que retornam um DataFrame) ou Databricks SQL interfaces como o Notebook ou o editor de consultas SQL.
Para view linhagem de dados:
- Você deve ter pelo menos o privilégio
BROWSEno catálogo pai da tabela ou view. O catálogo principal também deve ser acessível a partir do workspace. Consulte a vinculação workspace-catalog. - Para Notebook, Job ou dashboards, o senhor deve ter permissões nesses objetos, conforme definido pelas configurações de controle de acesso no site workspace. Para obter detalhes, consulte Permissões do Lineage.
- Para um pipeline habilitado para o Unity Catalog, o senhor deve ter permissão CAN VIEW no pipeline.
Requisitos de computação:
- O acompanhamento da transmissão da linhagem entre as tabelas Delta requer Databricks Runtime 11.3 LTS ou acima.
- O acompanhamento da linhagem de colunas para cargas de trabalho de pipeline declarativo LakeFlow Spark requer Databricks Runtime 13.3 LTS ou superior.
Requisitos de rede:
- Você pode precisar atualizar as regras do firewall de saída para permitir a conectividade com o endpoint do Amazon Kinesis no plano de controle do Databricks. Normalmente, isso se aplica se o seu workspace Databricks estiver implantado em sua própria VPC ou se você usar AWS PrivateLink em seu ambiente de rede Databricks . Para obter o endpoint Kinesis para a região do seu workspace , consulte EndereçosKinesis. Consulte também Configurar uma VPCgerenciada pelo cliente e Configurar conectividade privada clássica com Databricks.
visualizar a linhagem de dados usando o Catalog Explorer
Para usar o Catalog Explorer para view a linhagem da tabela:
-
Em seu site Databricks workspace, clique em
 Catalog .
Catalog . -
Pesquise ou procure sua tabela.
-
Selecione a linhagem tab. O painel de linhagem aparece e exibe tabelas relacionadas.
-
Para view um gráfico interativo da linhagem de dados, clique em See Lineage gráfico .
Em default, um nível é exibido no gráfico. Clique no
 ícone em um nó para revelar mais conexões, se estiverem disponíveis.
ícone em um nó para revelar mais conexões, se estiverem disponíveis. -
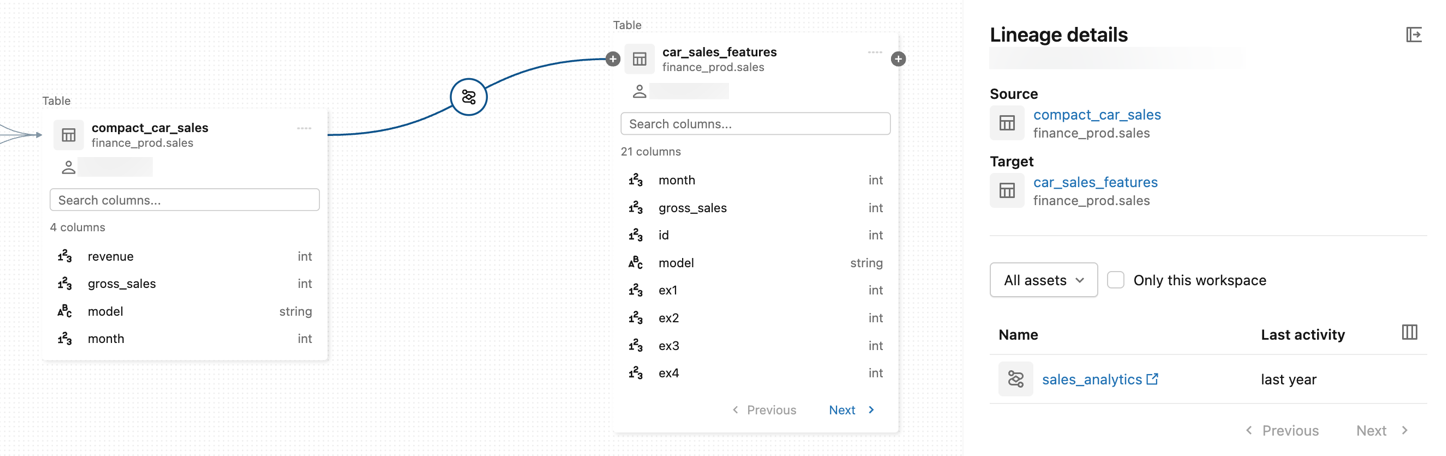
Clique no ícone em uma aresta de conexão no gráfico de linhagem para abrir o painel de detalhes da linhagem .
O painel Detalhes da linhagem mostra informações sobre a conexão, incluindo as tabelas de origem e destino.
-
Para view um ativo associado a uma tabela, selecione o ativo no painel Detalhes da linhagem . Você pode filtrar por Notebook, Job, pipeline e consultas.
-
Para view a linhagem em nível de coluna, clique em uma coluna no gráfico para exibir os links para as colunas relacionadas. Por exemplo, clicar na coluna
revenueneste gráfico de exemplo mostra as colunas anteriores das quais a coluna foi derivada: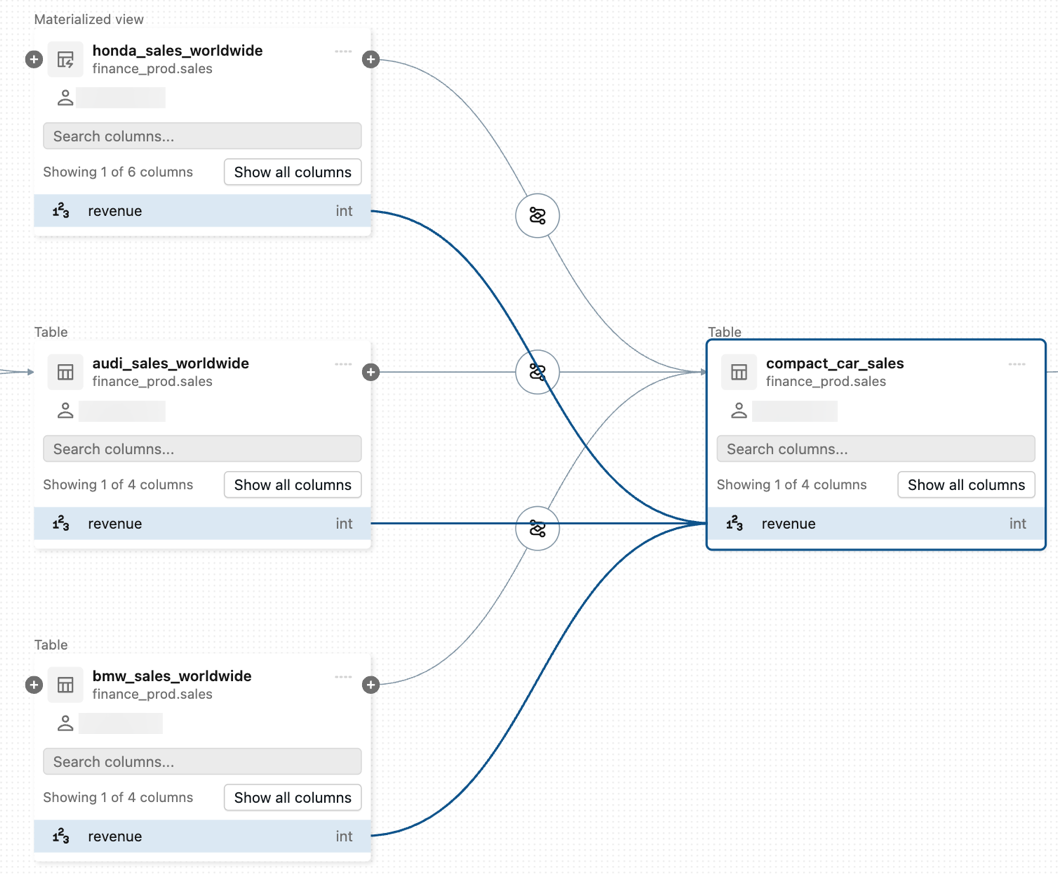
ver tabela
Para view as tendências de uso da tabela e as consultas frequentes, usuários e painéis, acesse a tab "Escolher" da tabela no Explorador de Catálogo. Para obter mais informações, incluindo como os dados são delimitados por workspace, consulte a seção "Exibir consultas frequentes e usuários de uma tabela".
ver Linhagem de trabalho
Para view a linhagem do trabalho, acesse a linhagem de uma tabela tab, selecione Jobs e selecione Downstream . O nome do trabalho aparece em Job Name como um consumidor da tabela.
visualizar a linhagem do painel
Para acessar o site view dashboard lineage, vá para Lineage tab de uma tabela e clique em Dashboards . O painel aparece em Nome do painel como consumidor da tabela.
Obtenha a linhagem da tabela usando o código Genie.
Genie Code fornece informações detalhadas sobre linhagens e percepções da tabela.
Para obter informações de linhagem usando Genie Code:
- Na barra lateral do site workspace, clique em Catalog .
- Navegue ou pesquise o catálogo, clique no nome do catálogo e, em seguida, clique em
 Ícone do código Genie no canto superior direito.
Ícone do código Genie no canto superior direito. - No prompt do Genie Code, digite:
- /getTableLineages para view dependências upstream e downstream.
- /getTableInsights para acessar percepções orientadas por metadados, como atividade do usuário e padrões de consulta.
Essas consultas permitem que o Genie Code responda a perguntas como "mostre-me as linhagens subsequentes" ou "quem consulta esta tabela com mais frequência".
Consulta de linhagem uso de dados tabelas do sistema
Você pode usar as tabelas do sistema de linhagem para consultar dados de linhagem programaticamente. Para obter instruções detalhadas, consulte a Referência de tabelas do sistema e a Referência de tabelas do sistema de linhagem.
Permissões de linhagem
O Lineage gráfico compartilha o mesmo modelo de permissão que o Unity Catalog. As tabelas e outros objetos de dados registrados no metastore do Unity Catalog são visíveis apenas para usuários que tenham pelo menos BROWSE permissões sobre esses objetos. Se um usuário não tiver o privilégio BROWSE ou SELECT em uma tabela, ele não poderá explorar sua linhagem. O Lineage gráfico exibe Unity Catalog objetos em todos os espaços de trabalho anexados ao metastore, desde que o usuário tenha as permissões de objeto adequadas.
Por exemplo, execute o seguinte comando para userA:
GRANT USE SCHEMA on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
Quando o site userA visualizar o gráfico de linhagem da tabela lineage_data.lineagedemo.menu, ele verá a tabela menu. Eles não poderão ver informações sobre tabelas associadas, como a tabela downstream lineage_data.lineagedemo.dinner. A tabela dinner é exibida como um nó masked na exibição para userA, e userA não pode expandir o gráfico para revelar tabelas downstream de tabelas às quais não tem permissão de acesso.
Se o senhor executar o seguinte comando para conceder a permissão BROWSE a userB, esse usuário poderá view o gráfico de linhagem para qualquer tabela no esquema lineage_data:
GRANT BROWSE on lineage_data to `userB@company.com`;
Da mesma forma, os usuários de linhagem devem ter permissões específicas para view workspace objetos como Notebook, Job e dashboards. Além disso, eles só podem ver informações detalhadas sobre os objetos do workspace quando estiverem conectados ao workspace no qual esses objetos foram criados. Informações detalhadas sobre objetos de nível workspaceem outro espaço de trabalho são mascaradas no gráfico de linhagem.
Para obter mais informações sobre como gerenciar o acesso a objetos protegidos em Unity Catalog, consulte gerenciar privilégios em Unity Catalog. Para obter mais informações sobre como gerenciar o acesso a objetos do site workspace, como Notebook, Job e dashboards, consulte Listas de controle de acesso.
Limitações de linhagem
A linhagem de dados tem as seguintes limitações. Essas limitações também se aplicam às tabelas do sistema de linhagem:
- Embora a linhagem seja agregada a todos os espaços de trabalho anexados ao mesmo metastore Unity Catalog, os detalhes dos objetos workspace, como o Notebook e os painéis, são visíveis apenas no workspace em que foram criados.
- Os dados de linhagem coletados antes de 1º de setembro de 2024 não estão disponíveis.
- Os trabalhos que usam a solicitação Jobs API
runs submitou o tipo de tarefaspark submitnão estão disponíveis na exibição de linhagem. A linhagem de nível de tabela e coluna ainda é capturada para esses fluxos de trabalho, mas o link para a execução do trabalho não é capturado. - A linhagem não é preservada para objetos renomeados - isso se aplica a catálogos, esquemas, tabelas, visualizações e colunas.
- Se o senhor usar Spark SQL dataset checkpointing, a linhagem não será capturada.
- Unity Catalog captura a linhagem do pipeline declarativo LakeFlow Spark na maioria dos casos. No entanto, em alguns casos, a cobertura completa da linhagem não pode ser garantida, como quando o pipeline usa tabelas PRIVADAS.
- Resilient Distributed Datasets (RDDs) não são capturados na linhagem.
- A visualização temporária global não é capturada na linhagem.
- As transações geram um registro de linhagem à medida que cada leitura e gravação ocorre. Os eventos de linhagem persistem mesmo se a transação for revertida.
- Tabelas abaixo de
system.information_schemanão são capturadas na linhagem. - O Unity Catalog captura a linhagem até o nível da coluna, tanto quanto possível. No entanto, há alguns casos em que a linhagem em nível de coluna não pode ser capturada. Isso inclui:
-
A linhagem da coluna não pode ser capturada se a origem ou o destino forem referenciados como caminho (Exemplo:
select * from delta."s3://<bucket>/<path>"). A linhagem de coluna é suportada somente quando a origem e o destino são referenciados pelo nome da tabela (Exemplo:select * from <catalog>.<schema>.<table>). -
Uso de funções definidas pelo usuário (UDFs), que podem obscurecer o mapeamento entre a origem e a coluna de destino.
-