Tamanho do arquivo de dados de controle
As recomendações deste artigo não se aplicam às tabelas gerenciadas Unity Catalog . Databricks recomenda o uso Unity Catalog para gerenciar tabelas com configurações default para todas as novas tabelas.
No Databricks Runtime 13.3 e acima, Databricks recomenda o uso de clustering para disposição de tabelas. Consulte Usar clustering líquido para tabelas.
Databricks recomenda o uso de otimização preditiva para executar automaticamente OPTIMIZE e VACUUM para tabelas. Consulte Otimização preditiva para Unity Catalog gerenciar tabelas.
Em Databricks Runtime 10.4 LTS e acima, a compactação automática e as gravações otimizadas estão sempre ativadas para as operações MERGE, UPDATE e DELETE. Você não pode desativar essa funcionalidade.
Existem opções para configurar manual ou automaticamente o tamanho do arquivo de destino para gravações e para operações OPTIMIZE . Databricks ajusta automaticamente muitas dessas configurações e habilita recursos que melhoram automaticamente o desempenho da tabela, buscando dimensionar os arquivos corretamente.
Para Unity Catalog gerenciar tabelas, Databricks ajusta a maioria dessas configurações automaticamente se o senhor estiver usando um SQL warehouse ou Databricks Runtime 11.3 LTS ou acima.
Se estiver fazendo upgrade de uma carga de trabalho do Databricks Runtime 10.4 LTS ou abaixo, consulte Upgrade para compactação automática em segundo plano.
Quando executar OPTIMIZE
A compactação automática e as gravações otimizadas reduzem os problemas de arquivos pequenos, mas não substituem completamente o OPTIMIZE. Especialmente para tabelas maiores que 1 TB, Databricks recomenda executar OPTIMIZE em um programar para consolidar ainda mais os arquivos. Databricks não executa automaticamente ZORDER em tabelas, portanto você deve executar OPTIMIZE com ZORDER para habilitar o salto de dados aprimorado. Consulte Ignorando dados.
O que é otimização automática no Databricks?
O termo auto optimize às vezes é usado para descrever a funcionalidade controlada pelas configurações autoOptimize.autoCompact e autoOptimize.optimizeWrite. Este termo foi descontinuado em favor da descrição de cada cenário individualmente. Consulte Compactação automática e Gravações otimizadas.
Compactação automática
A compactação automática combina arquivos pequenos dentro de partições de tabela para reduzir automaticamente problemas com arquivos pequenos. A compactação automática ocorre após uma gravação bem-sucedida em uma tabela e é executada de forma síncrona no cluster que realizou a gravação. A compactação automática compacta apenas os arquivos que não foram compactados anteriormente.
Controle o tamanho do arquivo de saída definindo a configuração do Spark spark.databricks.delta.autoCompact.maxFileSize para Delta ou spark.databricks.iceberg.autoCompact.maxFileSize para Iceberg. A Databricks recomenda o uso do ajuste automático com base na carga de trabalho ou no tamanho da tabela. Consulte Tamanho do arquivo Autotune com base na carga de trabalho e Tamanho do arquivo Autotune com base no tamanho da tabela.
A compactação automática só é acionada para partições ou tabelas que possuam pelo menos um determinado número de arquivos pequenos. Opcionalmente, altere o número mínimo de arquivos necessários para acionar a compactação automática definindo spark.databricks.delta.autoCompact.minNumFiles para Delta ou spark.databricks.iceberg.autoCompact.minNumFiles para Iceberg.
Ative a compactação automática no nível da tabela ou da sessão usando as seguintes configurações:
- Propriedade da tabela:
autoOptimize.autoCompact - Configuração do SparkSession:
spark.databricks.delta.autoCompact.enabled(Delta) ouspark.databricks.iceberg.autoCompact.enabled(Iceberg)
Estas configurações aceitam as seguintes opções:
Opções | Comportamento |
|---|---|
| Ajusta o tamanho do arquivo de destino, respeitando outras funcionalidades de ajuste automático. Requer Databricks Runtime 10.4 LTS ou acima. |
| Alias para |
| Use 128 MB como o tamanho do arquivo de destino. Sem dimensionamento dinâmico. |
| Desativa a compactação automática. Pode ser configurado no nível da sessão para substituir a compactação automática de todas as tabelas modificadas na carga de trabalho. |
Em Databricks Runtime 9.1 LTS, quando outros escritores executam operações como DELETE, MERGE, UPDATE ou OPTIMIZE simultaneamente, a compactação automática pode fazer com que esses outros trabalhos falhem com um conflito de transações. Isso não é um problema em Databricks Runtime 10.4 LTS e acima.
Gravações otimizadas
As gravações otimizadas melhoram o tamanho do arquivo à medida que os dados são gravados e beneficiam as leituras subsequentes na tabela.
As gravações otimizadas são mais eficazes para tabelas particionadas, pois reduzem o número de pequenos arquivos gravados em cada partição. A gravação de menos arquivos grandes é mais eficiente do que gravar muitos arquivos pequenos, mas ainda pode haver um aumento na latência de gravação devido ao rearranjo dos dados antes da gravação.
A imagem a seguir mostra como as gravações otimizadas funcionam:
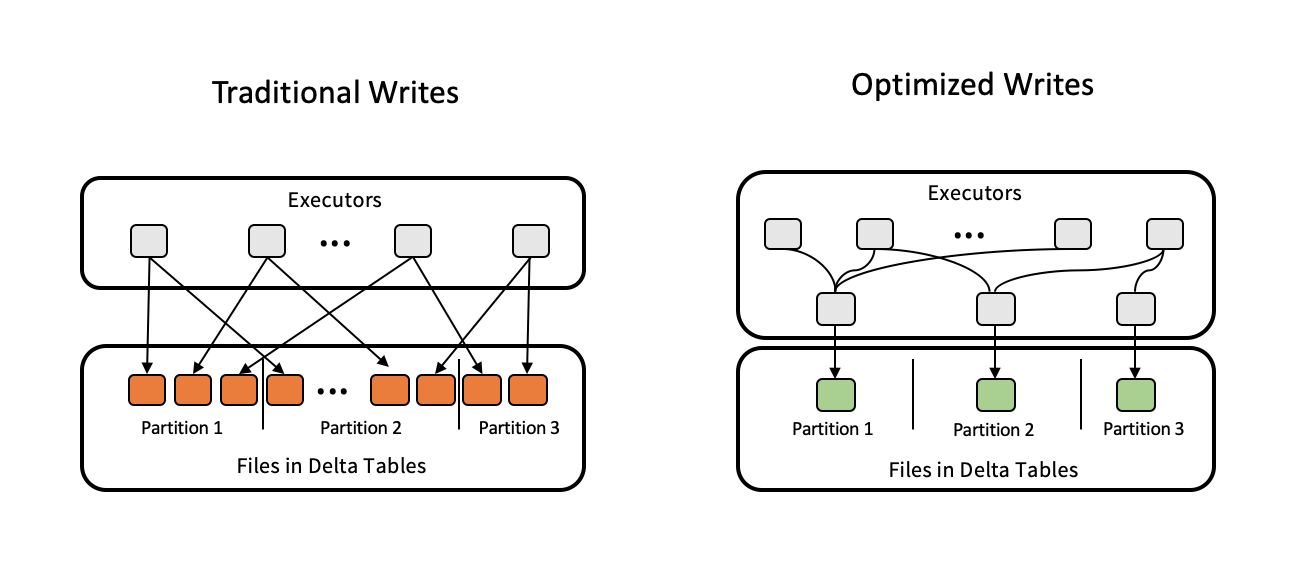
O senhor pode ter um código que executa coalesce(n) ou repartition(n) logo antes de gravar os dados para controlar o número de arquivos gravados. As gravações otimizadas eliminam a necessidade de usar esse padrão.
As gravações otimizadas são habilitadas por padrão para as seguintes operações no Databricks Runtime 9.1 LTS e versões superiores:
MERGEUPDATEcom subconsultasDELETEcom subconsultas
As gravações otimizadas também estão habilitadas para instruções CTAS e operações INSERT ao usar SQL Warehouse. No Databricks Runtime 13.3 LTS e versões superiores, todas as tabelas registradas no Unity Catalog têm gravações otimizadas habilitadas para instruções CTAS e operações INSERT para tabelas particionadas.
As gravações otimizadas podem ser habilitadas no nível da tabela ou da sessão usando as seguintes configurações:
- Propriedade da tabela:
autoOptimize.optimizeWrite - Configuração do SparkSession:
spark.databricks.delta.optimizeWrite.enabled(Delta) ouspark.databricks.iceberg.optimizeWrite.enabled(Iceberg)
Estas configurações aceitam as seguintes opções:
Opções | Comportamento |
|---|---|
| Use 128 MB como o tamanho do arquivo de destino. |
| Desativa as gravações otimizadas. Pode ser configurado no nível da sessão para substituir a compactação automática de todas as tabelas modificadas na carga de trabalho. |
Definir um tamanho de arquivo de destino
Se você quiser ajustar o tamanho dos arquivos em sua tabela, defina a propriedade da tabela targetFileSize para o tamanho desejado. Se essa propriedade estiver definida, todas as operações de otimização de dados farão o possível para gerar arquivos do tamanho especificado. Exemplos disso incluem otimização ou Z-order, compactação automática e gravações otimizadas.
Ao usar tabelas gerenciadas do Unity Catalog e SQL warehouses ou Databricks Runtime 11.3 LTS e versões superiores, somente OPTIMIZE os comandos respeitam a configuração. targetFileSize
Propriedade | Descrição |
|---|---|
| Tipo : Tamanho em bytes ou unidades superiores. Descrição : O tamanho do arquivo alvo. Por exemplo, Valor padrão : Nenhum |
Para tabelas existentes, você pode definir e remover propriedades usando o comando SQL ALTER TABLE SET TBL PROPERTIES. Você também pode definir essas propriedades automaticamente ao criar novas tabelas usando as configurações de sessão do Spark. Consulte a referência de propriedades da tabela para obter detalhes.
Ajuste automático do tamanho do arquivo com base na carga de trabalho
Databricks recomenda definir a propriedade da tabela tuneFileSizesForRewrites como true para todas as tabelas que são direcionadas por muitos MERGE ou operações DML, independentemente do Databricks Runtime, Unity Catalog ou outras otimizações. Quando configurado como true, o tamanho do arquivo de destino para a tabela é configurado para um limite muito menor, o que acelera as operações de gravação intensiva.
Se não for explicitamente definido, o Databricks detecta automaticamente se 9 das últimas 10 operações anteriores em uma tabela foram operações MERGE e define esta propriedade da tabela como true. Você deve definir explicitamente esta propriedade como false para evitar este comportamento.
Propriedade | Descrição |
|---|---|
| Tipo : Descrição : Indica se é necessário ajustar o tamanho dos arquivos para otimizar a disponibilidade de dados. Valor padrão : Nenhum |
Para tabelas existentes, você pode definir e remover propriedades usando o comando SQL ALTER TABLE SET TBL PROPERTIES. Você também pode definir essas propriedades automaticamente ao criar novas tabelas usando as configurações de sessão do Spark. Consulte a referência de propriedades da tabela para obter detalhes.
Ajuste automático do tamanho do arquivo com base no tamanho da tabela
Para minimizar a necessidade de ajustes manuais, o Databricks ajusta automaticamente o tamanho dos arquivos das tabelas com base no tamanho da tabela. O Databricks usará tamanhos de arquivo menores para tabelas menores e tamanhos de arquivo maiores para tabelas maiores, para que o número de arquivos na tabela não cresça demais. O Databricks não ajusta automaticamente tabelas que você tenha ajustado com um tamanho alvo específico ou com base em uma carga de trabalho com reescritas frequentes.
O tamanho do arquivo alvo é baseado no tamanho atual da tabela. Para tabelas com menos de 2,56 TB, o tamanho de arquivo alvo ajustado automaticamente é de 256 MB. Para tabelas com tamanho entre 2,56 TB e 10 TB, o tamanho alvo crescerá linearmente de 256 MB para 1 GB. Para tabelas maiores que 10 TB, o tamanho de arquivo alvo é de 1 GB.
Quando o tamanho do arquivo de destino em uma tabela aumenta, os arquivos existentes não são otimizados novamente em arquivos maiores pelo comando OPTIMIZE. Uma tabela grande pode, portanto, sempre ter alguns arquivos menores que o tamanho de destino. Se também for necessário otimizar esses arquivos menores em arquivos maiores, você pode configurar um tamanho de arquivo de destino fixo para a tabela usando a propriedade targetFileSize.
Quando uma tabela é gravada de forma incremental, os tamanhos e contagens de arquivos de destino estarão próximos aos seguintes números, com base no tamanho da tabela. As contagens de arquivos nesta tabela são apenas um exemplo. Os resultados reais serão diferentes dependendo de muitos fatores.
Tamanho da tabela | Tamanho do arquivo de destino | Número aproximado de arquivos na tabela |
|---|---|---|
10 GB | 256 MB | 40 |
1 TB | 256 MB | 4096 |
2,56 TB | 256 MB | 10240 |
3 TB | 307 MB | 12108 |
5 TB | 512 MB | 17339 |
7 TB | 716 MB | 20784 |
10 TB | 1 GB | 24437 |
20 TB | 1 GB | 34437 |
50 TB | 1 GB | 64437 |
100 TB | 1 GB | 114437 |
Limitar linhas escritas em um arquivo de dados
Ocasionalmente, tabelas com dados restritos podem apresentar um erro quando o número de linhas em um determinado arquivo de dados excede os limites de suporte do formato Parquet. Para evitar esse erro, você pode usar a configuração de sessão SQL spark.sql.files.maxRecordsPerFile para especificar o número máximo de registros a serem gravados em um único arquivo para uma tabela. Especificar um valor zero ou um valor negativo não representa limite.
No Databricks Runtime 11.3 LTS e versões superiores, você também pode usar a opção DataFrameWriter maxRecordsPerFile ao usar as APIs DataFrame para gravar em uma tabela. Quando maxRecordsPerFile é especificado, o valor da configuração da sessão SQL spark.sql.files.maxRecordsPerFile é ignorado.
O Databricks não recomenda o uso dessa opção, a menos que seja necessário evitar o erro mencionado acima. Essa configuração ainda pode ser necessária para algumas tabelas gerenciadas pelo Unity Catalog com dados muito restritos.
Atualize para a compactação automática em segundo plano
A compactação automática em segundo plano está disponível para Unity Catalog gerenciar tabelas em Databricks Runtime 11.3 LTS e acima. Ao migrar uma carga de trabalho ou tabela legada, faça o seguinte:
- Remova a configuração Spark
spark.databricks.delta.autoCompact.enabled(Delta) ouspark.databricks.iceberg.autoCompact.enabled(Iceberg) das configurações cluster ou Notebook. - Para cada tabela, execute
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact)(Delta) ouALTER TABLE <table_name> UNSET TBLPROPERTIES (iceberg.autoOptimize.autoCompact)(Iceberg) para remover quaisquer configurações de compactação automática legadas.
Depois de remover essas configurações herdadas, o senhor deverá ver a compactação automática em segundo plano acionada automaticamente para todas as tabelas gerenciáveis do Unity Catalog.