Databricks Connect
Este artigo abrange o Databricks Connect para Databricks Runtime 13.3 LTS e acima.
Databricks Connect é uma biblioteca cliente para o Databricks Runtime que permite que você se conecte ao Databricks compute a partir de IDEs como Visual Studio Code, PyCharm e IntelliJ IDEA, Notebook e qualquer aplicativo personalizado, para permitir novas experiências interativas do usuário com base no seu Databricks Lakehouse.
O Databricks Connect está disponível para os seguintes idiomas:
O que posso fazer com o Databricks Connect?
Usando Databricks Connect, o senhor pode escrever código usando Spark APIs e executá-lo remotamente em Databricks compute em vez de na sessão local Spark.
-
Desenvolva e depure interativamente a partir de qualquer IDE . Databricks Connect permite que os desenvolvedores desenvolvam e depurem seu código no Databricks compute usando a funcionalidade nativa de execução e teste de qualquer IDE. A extensão Databricks Visual Studio Code usa o Databricks Connect para fornecer depuração integrada do código do usuário no Databricks.
-
Crie aplicativos de dados interativos . Assim como um driver JDBC, a biblioteca Databricks Connect pode ser incorporada em qualquer aplicativo para interagir com o Databricks. Databricks Connect fornece toda a expressividade do Python por meio PySpark, eliminando a incompatibilidade de impedância da linguagem de programação SQL e permitindo que você execute todas as transformações de dados com Spark na compute escalável serverless Databricks .
Como funciona?
O Databricks Connect é criado no Spark Connect de código aberto, que tem uma arquitetura cliente-servidor desacoplada para o Apache Spark, permitindo conectividade remota a clusters Spark usando a API DataFrame. O protocolo subjacente usa planos lógicos não resolvidos do Spark e do Apache Arrow sobre gRPC. A API do cliente foi projetada para ser fina, para que possa ser incorporada em qualquer lugar: em servidores de aplicativos, IDEs, Notebook e linguagens de programação.
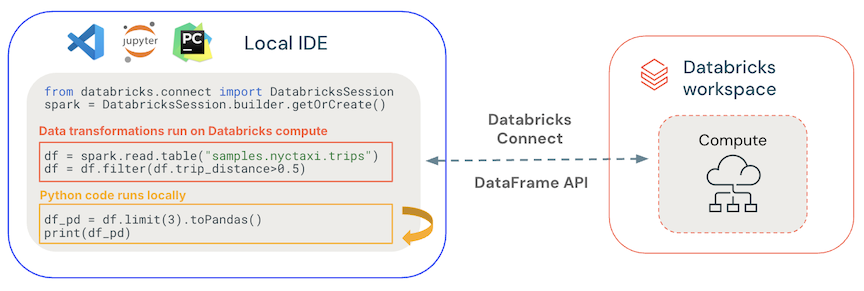
- Execução geral de código localmente : Execução de código Python e Scala no lado do cliente, possibilitando depuração interativa. Todo o código é executado localmente, enquanto todo o código Spark continua sendo executado no cluster remoto.
- As APIs do DataFrame são executadas no Databricks compute . Todas as transformações de dados são convertidas em planos Spark e executadas no compute Databricks por meio da sessão remota Spark . Eles são materializados no seu cliente local quando você usa comandos como
collect(),show(),toPandas(). - Execução de códigoUDF no Databricks compute : UDFs definidos localmente são serializados e transmitidos ao cluster onde são executados. APIs que executam o código do usuário no Databricks incluem: UDFs,
foreach,foreachBatchetransformWithState. - Para gerenciamento de dependências:
- Instale dependências do aplicativo na sua máquina local . Eles são executados localmente e precisam ser instalados como parte do seu projeto, como parte do seu ambiente virtual Python .
- Instale as dependências UDF no Databricks . Consulte Gerenciar dependências UDF.
Como o Databricks Connect e o Spark Connect estão relacionados?
O Spark Connect é um protocolo de código aberto baseado em gRPC dentro do Apache Spark que permite a execução remota de cargas de trabalho do Spark usando a API DataFrame.
Para Databricks Runtime 13.3 LTS e acima, Databricks Connect é uma extensão do Spark Connect com adições e modificações para dar suporte ao trabalho com os modos compute Databricks e Unity Catalog.
Próximas etapas
Veja o tutorial a seguir para começar a desenvolver rapidamente soluções Databricks Connect :
- tutorial compute clássica Databricks Connect para Python
- tutorialDatabricks Connect para compute serverless Python
- tutorialclássico compute Databricks Connect para Scala
- tutorialcompute serverless Databricks Connect para Scala
- tutorialDatabricks Connect para R
Para ver exemplos de aplicativos que usam o Databricks Connect, consulte o repositório de exemplos do GitHub, que inclui os seguintes exemplos: