Trabalhar com arquivos no Databricks
Databricks tem várias utilidades e APIs para interagir com arquivos nos seguintes locais:
- Unity Catalog volumes
- arquivos do espaço de trabalho
- Armazenamento de objetos na nuvem
- DBFS montagens e DBFS root
- Armazenamento efêmero anexado ao nó driver do clustering
Este artigo contém exemplos de interação com arquivos nesses locais para as seguintes ferramentas:
- Apache Spark
- Spark SQL e Databricks SQL
- Databricks utilidades do sistema de arquivos (
dbutils.fsou%fs) - CLI do Databricks
- API REST da Databricks
- Bash shell comando (
%sh) - Notebook-A biblioteca com escopo de instalação usa
%pip - Pandas
- OSS Python utilidades de processamento e gerenciamento de arquivos
Algumas operações em Databricks, especialmente aquelas que usam Java ou Scala biblioteca, são executadas como processos JVM, por exemplo:
- Especificar uma dependência de arquivo JAR usando
--jarsnas configurações do Spark - Chamando
catoujava.io.Fileem Scala Notebook - Fonte de dados personalizada, como
spark.read.format("com.mycompany.datasource") - biblioteca que carregam arquivos usando Java's
FileInputStreamouPaths.get()
Essas operações não suportam a leitura ou gravação em volumes Unity Catalog ou arquivos workspace usando caminhos de arquivo padrão, como /Volumes/my-catalog/my-schema/my-volume/my-file.csv. Se o senhor precisar acessar arquivos de volume ou arquivos workspace de dependências JAR ou de uma biblioteca baseada em JVM, copie os arquivos primeiro para o armazenamento local compute usando o comando Python ou %sh, como %sh mv.. Não use %fs e dbutils.fs que usam a JVM. Para acessar arquivos já copiados localmente, use o comando específico do idioma, como Python shutil ou use %sh comando. Se um arquivo precisar estar presente durante o início do clustering, use um init script para mover o arquivo primeiro. Consulte O que são scripts de inicialização?
Preciso fornecer um esquema de URI para acessar os dados?
Os caminhos de acesso aos dados no Databricks seguem um dos seguintes padrões:
-
Os caminhos no estilo URI incluem um esquema de URI. Para soluções de acesso a dados nativas do Databricks, os esquemas de URI são opcionais para a maioria dos casos de uso. Ao acessar diretamente os dados no armazenamento de objetos na nuvem, você deve fornecer o esquema de URI correto para o tipo de armazenamento.
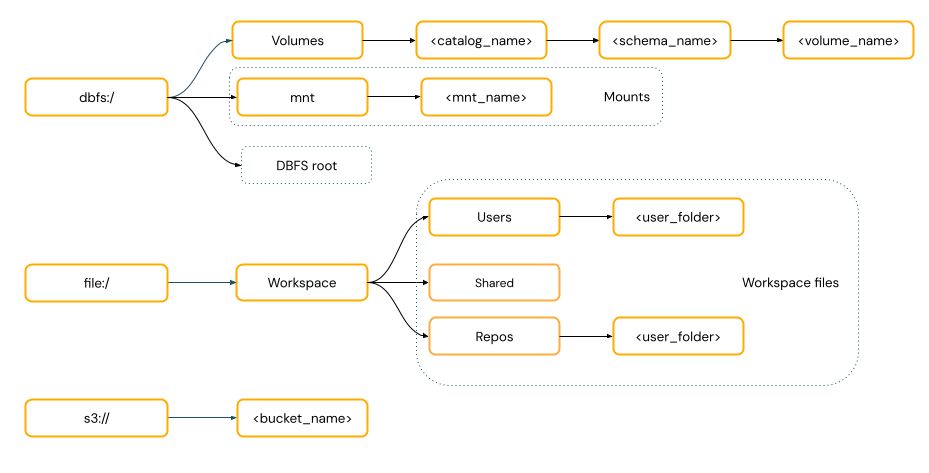
-
Os caminhos no estilo POSIX fornecem acesso aos dados em relação à raiz do driver (
/). Os caminhos no estilo POSIX nunca exigem um esquema. O senhor pode usar volumes do Unity Catalog ou montagens DBFS para fornecer acesso aos dados no estilo POSIX no armazenamento de objetos na nuvem. Muitas estruturas de ML e outros módulos Python OSS exigem o FUSE e só podem usar caminhos no estilo POSIX.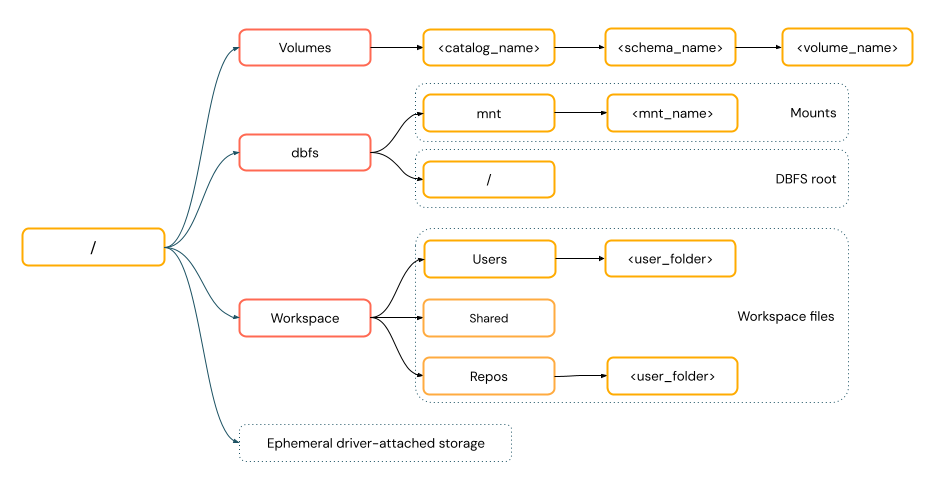
As operações de arquivo que exigem acesso aos dados do FUSE não podem acessar diretamente o armazenamento de objetos na nuvem usando URIs. A Databricks recomenda o uso de volumes do Unity Catalog para configurar o acesso a esses locais para o FUSE.
Em compute configurado com o modo de acesso dedicado (anteriormente, modo de acesso de usuário único) e Databricks Runtime 14.3 e acima, Scala oferece suporte a FUSE para volumes Unity Catalog e arquivos workspace, exceto para subprocessos originados de Scala, como o comando Scala "cat /Volumes/path/to/file".!!.
Trabalhar com arquivos em volumes do Unity Catalog
Databricks recomenda o uso de volumes Unity Catalog para configurar o acesso a arquivos de dados não tabulares armazenados no armazenamento de objetos cloud. Para obter a documentação completa sobre o gerenciamento de arquivos em volumes, incluindo instruções detalhadas e práticas recomendadas, consulte Trabalhar com arquivos em volumes do Unity Catalog.
Os exemplos a seguir mostram operações comuns usando diferentes ferramentas e interfaces:
Ferramenta | Exemplo |
|---|---|
Apache Spark |
|
Spark SQL e Databricks SQL |
|
Databricks utilidades do sistema de arquivos |
|
CLI do Databricks |
|
API REST da Databricks |
|
Bash shell comando |
|
biblioteca instala |
|
Pandas |
|
OSS Python |
|
Para obter informações sobre limitações de volumes e soluções alternativas, consulte Limitações do trabalho com arquivos em volumes.
Trabalhar com arquivos workspace
Os arquivosworkspace Databricks são os arquivos em um workspace, armazenados na accountde armazenamentoworkspace. Você pode usar arquivos workspace para armazenar e acessar arquivos como Notebooks, arquivos de código-fonte, arquivos de dados e outras atividades workspace .
Como os arquivos workspace têm restrições de tamanho, Databricks recomenda armazenar aqui apenas arquivos de dados pequenos, principalmente para desenvolvimento e teste. Para obter recomendações sobre onde armazenar outros tipos de arquivo, consulte Tipos de arquivo.
Ferramenta | Exemplo |
|---|---|
Apache Spark |
|
Spark SQL e Databricks SQL |
|
Databricks utilidades do sistema de arquivos |
|
CLI do Databricks |
|
API REST da Databricks |
|
Bash shell comando |
|
biblioteca instala |
|
Pandas |
|
OSS Python |
|
O esquema file:/ é necessário ao trabalhar com Databricks utilidades, Apache Spark, ou SQL.
Em um espaço de trabalho onde DBFS root e as montagens estão desativadas, você também pode usar dbfs:/Workspace para acessar arquivos workspace com utilitários Databricks . Isso requer Databricks Runtime 13.3 LTS ou superior. Consulte Desativar o acesso à DBFS root no seu workspace Databricks existente.
Para conhecer as limitações do trabalho com arquivos workspace, consulte Limitações.
Para onde vão os arquivos excluídos do workspace?
A exclusão de um arquivo workspace o envia para a lixeira. Você pode recuperar ou excluir permanentemente arquivos da lixeira usando a interface do usuário.
Consulte Excluir um objeto.
Trabalhe com arquivos no armazenamento de objetos na nuvem
A Databricks recomenda o uso de volumes do Unity Catalog para configurar o acesso seguro a arquivos no armazenamento de objetos na nuvem. Você deve configurar as permissões se optar por acessar dados diretamente no armazenamento de objetos na nuvem usando URIs. Consulte gerenciar e volumes externos.
Os exemplos a seguir usam URIs para acessar dados no armazenamento de objetos na nuvem:
Ferramenta | Exemplo |
|---|---|
Apache Spark |
|
Spark SQL e Databricks SQL |
|
Databricks utilidades do sistema de arquivos |
|
CLI do Databricks | Não suportado |
API REST da Databricks | Não suportado |
Bash shell comando | Não suportado |
biblioteca instala |
|
Pandas | Não suportado |
OSS Python | Não suportado |
O armazenamento de objetos na nuvem não oferece suporte a montagens do Amazon S3 com a criptografia do lado do cliente ativada.
Trabalhe com arquivos em DBFS mounts e DBFS root
Tanto DBFS root quanto as montagens DBFS estão obsoletos e não são recomendados pela Databricks. Novas contas são provisionadas sem acesso a esses recursos. Databricks recomenda o uso de volumes Unity Catalog , locais externos ou arquivosworkspace .
Ferramenta | Exemplo |
|---|---|
Apache Spark |
|
Spark SQL e Databricks SQL |
|
Databricks utilidades do sistema de arquivos |
|
CLI do Databricks |
|
API REST da Databricks |
|
Bash shell comando |
|
biblioteca instala |
|
Pandas |
|
OSS Python |
|
O esquema dbfs:/ é necessário ao trabalhar com a CLI do Databricks.
Trabalhe com arquivos no armazenamento temporário anexado ao nó do driver
O armazenamento efêmero anexado ao nó do driver é um armazenamento em bloco com acesso integrado ao caminho baseado em POSIX. Todos os dados armazenados nesse local desaparecem quando um clustering é encerrado ou reiniciado.
Ferramenta | Exemplo |
|---|---|
Apache Spark | Não suportado |
Spark SQL e Databricks SQL | Não suportado |
Databricks utilidades do sistema de arquivos |
|
CLI do Databricks | Não suportado |
API REST da Databricks | Não suportado |
Bash shell comando |
|
biblioteca instala | Não suportado |
Pandas |
|
OSS Python |
|
O esquema file:/ é necessário ao trabalhar com Databricks utilidades.
Mova dados do armazenamento efêmero para volumes
O senhor pode querer acessar downloads de dados ou salvos em armazenamento efêmero usando Apache Spark. Como o armazenamento efêmero é anexado ao driver e o Spark é um mecanismo de processamento distribuído, nem todas as operações podem acessar diretamente os dados aqui. Suponha que o senhor precise mover dados do sistema de arquivos do driver para volumes do Unity Catalog. Nesse caso, o senhor pode copiar arquivos usando o magic comando ou o Databricks utilidades, como nos exemplos a seguir:
dbutils.fs.cp ("file:/<path>", "/Volumes/<catalog>/<schema>/<volume>/<path>")
%sh cp /<path> /Volumes/<catalog>/<schema>/<volume>/<path>
%fs cp file:/<path> /Volumes/<catalog>/<schema>/<volume>/<path>
Recurso adicional
Para obter informações sobre o upload de arquivos locais ou downloads de arquivos da Internet para Databricks, consulte upload files to Databricks.