LakeFlow Empregos
LakeFlow Jobs é a automação de fluxo de trabalho para Databricks, fornecendo orquestração para cargas de trabalho de processamento de dados para que o senhor possa coordenar e executar várias tarefas como parte de um fluxo de trabalho maior. O senhor pode otimizar e programar a execução de tarefas frequentes e repetitivas e gerenciar fluxos de trabalho complexos.
Este artigo apresenta conceitos e opções relacionados ao gerenciamento de cargas de trabalho de produção usando LakeFlow Jobs.
O que são empregos?
Em Databricks, um Job é usado para programar e orquestrar tarefas em Databricks em um fluxo de trabalho. O fluxo de trabalho comum de processamento de dados inclui ETL fluxo de trabalho, execução de Notebook e fluxo de trabalho de aprendizado de máquina (ML), bem como a integração com sistemas externos como dbt.
Os trabalhos consistem em uma ou mais tarefas e suportam a lógica de fluxo de controle personalizado, como ramificação (instruções if / else) ou looping (para cada instrução), usando uma UI de criação visual. A tarefa pode carregar ou transformar dados em um fluxo de trabalho ETL ou criar, treinar e implantar modelos ML de forma controlada e repetível como parte de seu pipeline de aprendizado de máquina.
Exemplo: Processamento diário de dados e trabalho de validação
O exemplo abaixo mostra um trabalho em Databricks.
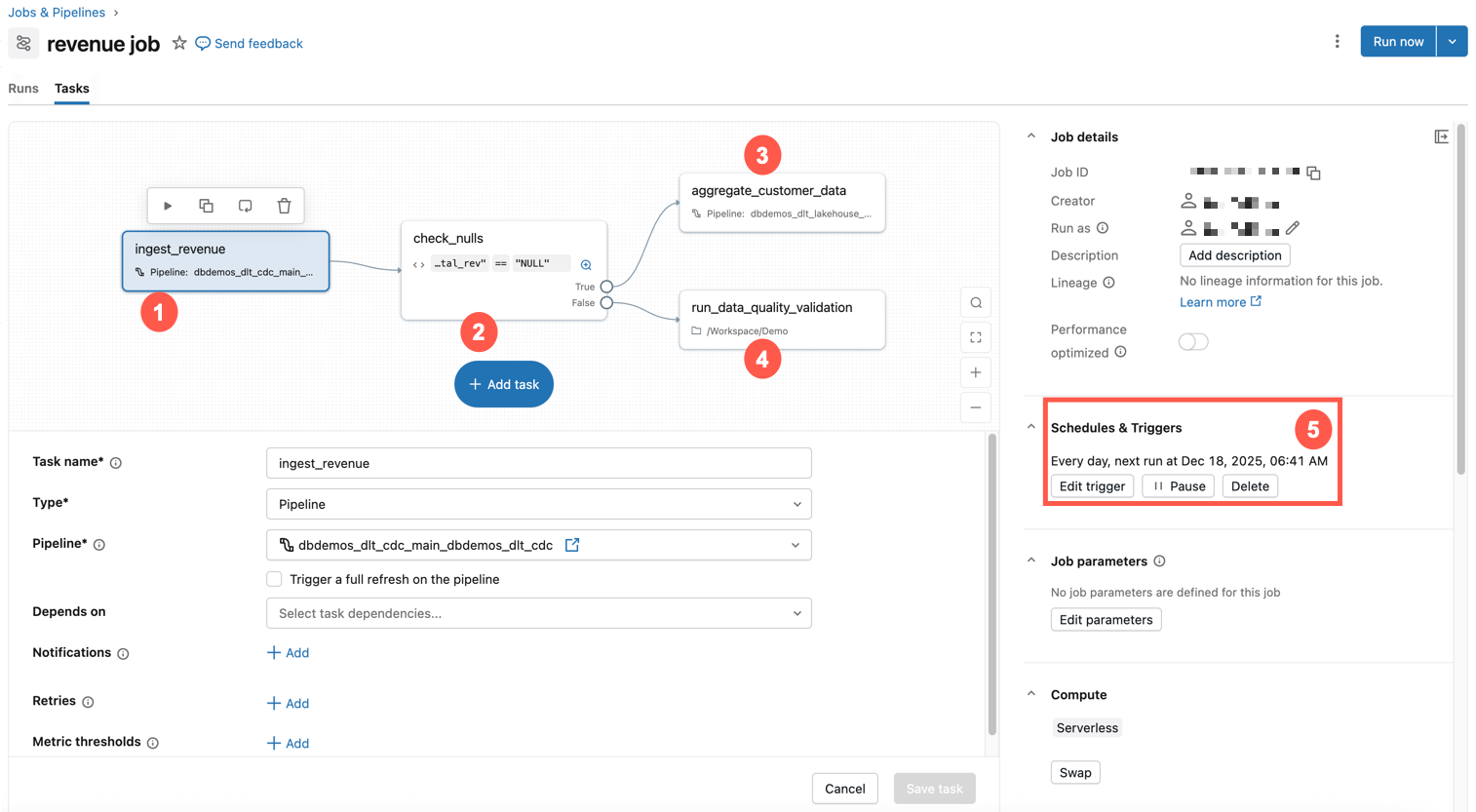
Esse exemplo de trabalho tem as seguintes características:
- A primeira tarefa ingere dados de receita.
- A segunda tarefa é uma verificação if / else para nulos.
- Se não, então a transformação tarefa é execução.
- Caso contrário, ele executa uma tarefa do Notebook com uma validação da qualidade dos dados.
- Está programado para ser executado no mesmo horário todos os dias.
Para obter uma rápida introdução à criação de seu próprio Job, consulte Criar seu primeiro fluxo de trabalho com LakeFlow Jobs.
Casos de uso comuns
Desde os princípios fundamentais da engenharia de dados até o aprendizado de máquina avançado e a integração perfeita de ferramentas, esses casos de uso comuns mostram a amplitude dos recursos que impulsionam a análise moderna, a automação do fluxo de trabalho e a escalabilidade da infraestrutura.
Conceitos de orquestração
Há três conceitos principais ao usar LakeFlow Jobs para orquestração em Databricks: Job, tarefa e gatilhos.
Job - Um Job é o principal recurso para coordenar, programar e executar suas operações. Os trabalhos podem variar em complexidade, desde uma única tarefa executando um Databricks Notebook até centenas de tarefas com lógica condicional e dependências. A tarefa em um trabalho é representada visualmente por um gráfico acíclico direcionado (DAG). O senhor pode especificar propriedades para o Job, incluindo:
- Trigger - define quando o trabalho deve ser executado.
- Parâmetros - parâmetros de tempo de execução que são automaticamente enviados para a tarefa dentro do Job.
- Notificações - e-mail ou webhooks a serem enviados quando um trabalho falhar ou demorar muito.
- Git - configurações de controle de origem para a tarefa Job.
Tarefa - Uma tarefa é uma unidade específica de trabalho em um Job. Cada tarefa pode executar uma variedade de operações, incluindo:
- A tarefa Notebook executa a Databricks Notebook. O senhor especifica o caminho para o Notebook e os parâmetros que ele requer.
- Uma tarefa pipeline execução de um pipeline. Você pode especificar um pipeline declarativo LakeFlow Spark existente, como uma view materializada ou uma tabela de transmissão.
- A Python script tarefa executar a Python file. Você fornece o caminho para o arquivo e todos os parâmetros necessários.
Há muitos tipos de tarefa. Para obter uma lista completa, consulte Tipos de tarefa. A tarefa pode ter dependências de outras tarefas e executar condicionalmente outras tarefas, permitindo que o senhor crie fluxos de trabalho complexos com lógica condicional e dependências.
Gatilho - Um gatilho é um mecanismo que inicia a execução de um trabalho com base em condições ou eventos específicos. Um acionador pode ser baseado em tempo, como a execução de um trabalho em um horário programado (por exemplo, todos os dias às 2h), ou baseado em eventos, como a execução de um trabalho quando novos dados chegam ao armazenamento em nuvem.
monitoramento e observabilidade
Os trabalhos oferecem suporte integrado para monitoramento e observabilidade. Os tópicos a seguir oferecem uma visão geral desse suporte. Para obter mais detalhes sobre o monitoramento do trabalho e a orquestração, consulte monitoramento e observabilidade para LakeFlow Jobs.
Job Monitoramento e observabilidade na interface do usuário - Na interface do usuário Databricks, o senhor pode acessar view Job, incluindo detalhes como o proprietário do Job e o resultado da última execução, e filtrar por propriedades do Job. O senhor pode acessar view a história da execução do trabalho e obter informações detalhadas sobre cada tarefa do trabalho.
Job status de execução e métricas - Databricks informa o sucesso da execução do trabalho e logs e métricas para cada tarefa dentro de uma execução de trabalho para diagnosticar problemas e entender o desempenho.
Notificações e alertas - O senhor pode configurar notificações para eventos de trabalho via email, Slack, webhooks personalizados e uma série de outras opções.
Consultas personalizadas por meio de tabelas do sistema - O site Databricks fornece tabelas do sistema que registram a execução de trabalhos e tarefas no site account. O senhor pode usar essas tabelas para consultar e analisar o desempenho e os custos do trabalho. O senhor pode criar painéis para visualizar as métricas e tendências do trabalho, para ajudar a monitorar a saúde e o desempenho do seu fluxo de trabalho.
Limitações
Aplicam-se as seguintes limitações:
- A workspace é limitada a 2000 concorrente tarefa execução. Uma resposta
429 Too Many Requestsé retornada quando o senhor solicita uma execução que não pode começar imediatamente. - O número de jobs que um workspace pode criar em uma hora é limitado a 10000 (inclui "envio de execuções"). Esse limite também afeta os jobs criados pela API REST e pelos fluxos de trabalho do notebook.
- O site workspace pode conter até 12.000 trabalhos salvos.
- Um trabalho pode conter até 1.000 tarefas.
Posso gerenciar fluxo de trabalho de forma programática?
Databricks possui ferramentas e o site APIs que permitem programar e orquestrar seu fluxo de trabalho de forma programática, incluindo o seguinte:
- CLI do Databricks
- Databricks Asset Bundles
- Extensão do Databricks para Visual Studio Code
- SDKs da Databricks
- API REST de empregos
Para obter exemplos de uso de ferramentas e do site APIs para criar e gerenciar trabalhos, consulte Automatizar a criação e o gerenciamento de trabalhos. Para obter a documentação sobre todas as ferramentas de desenvolvimento disponíveis, consulte Ferramentas de desenvolvimento local.
As ferramentas externas usam as ferramentas Databricks e APIs para programar o fluxo de trabalho. Por exemplo, o senhor também pode programar seu trabalho usando ferramentas como Apache Airflow. Veja Orchestrate LakeFlow Empregos com Apache Airflow .