Use dbt transformações em LakeFlow Jobs
O senhor pode executar seus projetos dbt Core como uma tarefa em um Job. Ao executar seu projeto dbt Core como uma tarefa Job, o senhor pode se beneficiar do seguinte recurso LakeFlow Jobs:
- Automatize sua dbt tarefa e programe o fluxo de trabalho que inclui dbt tarefa.
- Monitore suas transformações de dbt e envie notificações sobre o status das transformações.
- Inclua seu projeto dbt em um fluxo de trabalho com outras tarefas. Por exemplo, seu fluxo de trabalho pode ingerir dados com Auto Loader, transformar os dados com dbt e analisar os dados com uma tarefa de Notebook.
- Arquivamento automático dos artefatos da execução do trabalho, incluindo logs, resultados, manifestos e configuração.
Para saber mais sobre o dbt Core, consulte a documentação do dbt.
Desenvolvimento e produção fluxo de trabalho
Databricks recomenda desenvolver seus projetos dbt com base em um depósito Databricks SQL. Usando um Databricks SQL warehouse, o senhor pode testar o SQL gerado pelo dbt e usar o SQL warehouse histórico de consultas para depurar as consultas geradas dbt pelo.
Para executar suas dbt transformações em produção, o site Databricks recomenda o uso da tarefa dbt em um trabalho Databricks. Em default, a tarefa dbt executará o processo dbt Python usando Databricks compute e o dbt gerado SQL contra o SQL warehouse selecionado.
O senhor pode executar transformações em um dbt serverless SQL warehouse ou SQL warehouse pro, Databricks compute, ou qualquer outro dbtdepósito suportado pelo. Este artigo discute as duas primeiras opções com exemplos.
Se o seu workspace estiver habilitado para o Unity Catalog e o serverless Jobs estiver habilitado, em default, a execução do Job no serverless compute.
Desenvolver modelos dbt em um SQL warehouse e executá-los em produção no Databricks compute pode levar a diferenças sutis no desempenho e no suporte à linguagem SQL. Databricks recomenda usar a mesma versão do Databricks Runtime para o compute e o SQL warehouse.
Requisitos
-
Para saber como usar o dbt Core e o pacote
dbt-databrickspara criar e executar projetos dbt em seu ambiente de desenvolvimento, consulte Conectar-se ao dbt Core.A Databricks recomenda o pacote dbt-databricks, não o pacote dbt-spark. O pacote dbt-databricks é uma bifurcação do dbt-spark otimizada para o Databricks.
-
Para usar projetos dbt em um Job Databricks , você precisa configurar as pastas Git Databricks. Não é possível executar um projeto dbt a partir do DBFS.
-
O senhor deve ter o serverless ou o pro SQL warehouse ativado.
-
O senhor deve ter o direito do Databricks SQL.
Crie e execute seu primeiro dbt Job
O exemplo a seguir usa o projeto jaffle_shop, um projeto de exemplo que demonstra os principais conceitos de dbt. Para criar um Job que execute o projeto jaffle shop, execute as seguintes etapas.
-
Em seu site workspace, clique em
 Jobs & pipeline na barra lateral.
Jobs & pipeline na barra lateral. -
Clique em Create e depois em Job .
-
Clique no bloco dbt para configurar a primeira tarefa. Se o bloco dbt não estiver disponível, clique em Adicionar outro tipo de tarefa e pesquise por dbt .
-
Opcionalmente, substitua o nome do trabalho, cujo padrão é
New Job <date-time>pelo seu nome de trabalho. -
Em nome da tarefa , digite um nome para a tarefa.
-
No menu suspenso Source (Fonte ), escolha o provedor Git porque este exemplo usa o projeto jaffle shop localizado em um repositório Git.
-
No diretório do projeto , insira o URL do repositório Git:
https://github.com/dbt-labs/jaffle_shop.git.
-
Nas caixas de texto dbt comando , especifique o dbt comando para execução (deps , seed e execução ). Esses devem ser os default. O senhor deve prefixar cada comando com
dbt. comando são executados na ordem especificada.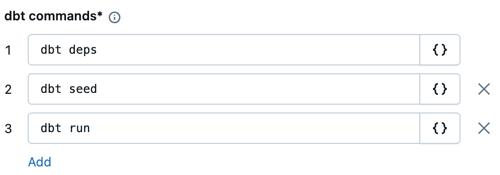
-
Em SQL warehouse , selecione um SQL warehouse para executar o SQL gerado pelo dbt. O menu suspenso SQL warehouse O menu suspenso mostra apenas serverless e pro SQL warehouse.
-
(Opcional) O senhor pode especificar um catálogo e um esquema para a saída da tarefa. Em default, o catálogo e o esquema de
defaultsão usados. -
(Opcional) Se o senhor quiser alterar a configuração do compute que executa dbt Core, clique em dbt CLI compute . Escolha uma opção existente em compute ou clique em Add new Job cluster para criar um novo Job cluster.
-
No menu suspenso Environment and biblioteca , deixe selecionado
dbt-default. -
Clique em Criar tarefa .
-
Para executar o trabalho agora, clique em
 .
.
Veja os resultados de seu dbt Job tarefa
Quando o trabalho for concluído, o senhor poderá testar os resultados executando consultas em SQL a partir de um Notebook ou executando consultas em SQL warehouse. Por exemplo, veja os seguintes exemplos de consultas:
SHOW tables IN <schema>;
SELECT * from <schema>.customers LIMIT 10;
Substitua <schema> pelo nome do esquema configurado na configuração da tarefa.
Exemplo de API
O senhor também pode usar o site Jobs API para criar e gerenciar trabalhos que incluam dbt tarefa. O exemplo a seguir cria um Job com um único dbt tarefa:
{
"name": "jaffle_shop dbt job",
"max_concurrent_runs": 1,
"git_source": {
"git_url": "https://github.com/dbt-labs/jaffle_shop",
"git_provider": "gitHub",
"git_branch": "main"
},
"job_clusters": [
{
"job_cluster_key": "dbt_CLI",
"new_cluster": {
"spark_version": "10.4.x-photon-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 0,
"spark_conf": {
"spark.master": "local[*, 4]",
"spark.databricks.cluster.profile": "singleNode"
},
"custom_tags": {
"ResourceClass": "SingleNode"
}
}
}
],
"tasks": [
{
"task_key": "transform",
"job_cluster_key": "dbt_CLI",
"dbt_task": {
"commands": ["dbt deps", "dbt seed", "dbt run"],
"warehouse_id": "1a234b567c8de912"
},
"libraries": [
{
"pypi": {
"package": "dbt-databricks>=1.0.0,<2.0.0"
}
}
]
}
]
}
(Avançado) execução dbt com um perfil personalizado
Para executar sua tarefa dbt com um SQL warehouse (recomendado) ou compute para todos os fins, use um profiles.yml personalizado definindo o depósito ou Databricks compute para se conectar. Para criar um Job que execute o projeto jaffle shop com um warehouse ou all-purpose compute, execute as seguintes etapas.
Somente um SQL warehouse ou um compute para todos os fins pode ser usado como alvo para uma tarefa dbt. O senhor não pode usar o Job compute como um alvo para dbt.
-
Crie uma bifurcação do repositório jaffle_shop.
-
Clone o repositório bifurcado em seu desktop. Por exemplo, o senhor poderia executar um comando como o seguinte:
Bashgit clone https://github.com/<username>/jaffle_shop.gitSubstitua
<username>pelo seu identificador do GitHub. -
Crie um novo arquivo chamado
profiles.ymlno diretóriojaffle_shopcom o seguinte conteúdo:YAMLjaffle_shop:
target: databricks_job
outputs:
databricks_job:
type: databricks
method: http
schema: '<schema>'
host: '<http-host>'
http_path: '<http-path>'
token: "{{ env_var('DBT_ACCESS_TOKEN') }}"- Substitua
<schema>por um nome de esquema para as tabelas do projeto. - Para executar sua tarefa dbt com um SQL warehouse, substitua
<http-host>pelo valor Server Hostname do Connection Details tab do seu SQL warehouse. Para executar sua dbt tarefa com compute<http-host>o multifuncional, substitua pelo valor Server Hostname das Advanced Options, JDBC/ODBC tab para seu Databricks compute. - Para executar sua tarefa dbt com um SQL warehouse, substitua
<http-path>pelo valor do caminho HTTP do Connection Details tab do seu SQL warehouse. Para executar sua dbt tarefa com compute<http-path>o multifuncional, substitua pelo valor do caminho HTTP das opções avançadas, JDBC/ODBC tab para seu Databricks compute.
Não especifique segredos, como tokens de acesso, no arquivo porque o senhor verificará esse arquivo no controle de origem. Em vez disso, esse arquivo usa a funcionalidade de modelo dbt para inserir credenciais dinamicamente em tempo de execução.
- Substitua
As credenciais geradas são válidas pela duração da execução, até um máximo de 30 dias, e são automaticamente revogadas após a conclusão.
-
Verifique esse arquivo no Git e envie-o para seu repositório bifurcado. Por exemplo, o senhor poderia executar um comando como o seguinte:
Bashgit add profiles.yml
git commit -m "adding profiles.yml for my Databricks job"
git push -
Clique em
Jobs & pipeline na barra lateral da interface do usuário Databricks. -
Selecione dbt Job e clique na tarefa tab.
-
Em Source (Fonte ), clique em Edit (Editar ) e insira os detalhes do repositório do GitHub do jaffle shop bifurcado.
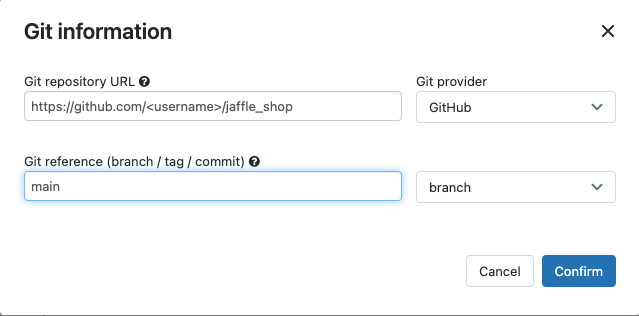
-
Em SQL warehouse selecione None (Manual) .
-
No Diretório de perfis , insira o caminho relativo para o diretório que contém o arquivo
profiles.yml. Deixe o valor do caminho em branco para usar o endereço default da raiz do repositório.
(Avançado) Usar modelos dbt Python em um fluxo de trabalho
O suporte do dbt para modelos Python está na versão beta e requer o dbt 1.3 ou superior.
dbt Agora, o senhor suporta os modelosPython em data warehouse específicos, incluindo Databricks. Com os modelos dbt Python, o senhor pode usar ferramentas do ecossistema Python para implementar transformações que são difíceis de implementar com o SQL. O senhor pode criar um trabalho Databricks para executar uma única tarefa com seu modelo dbt Python ou pode incluir a tarefa dbt como parte de um fluxo de trabalho que inclua várias tarefas.
O senhor não pode executar os modelos Python em uma tarefa dbt usando um SQL warehouse. Para obter mais informações sobre o uso dos modelos dbt Python com Databricks, consulte Armazém de dados específico na documentação dbt.
Erros e solução de problemas
Erro no arquivo de perfil não existe
Mensagem de erro :
dbt looked for a profiles.yml file in /tmp/.../profiles.yml but did not find one.
Causas possíveis :
O arquivo profiles.yml não foi encontrado no $PATH especificado. Certifique-se de que a raiz do seu projeto dbt contenha o arquivo profiles.yml.