perfil de dados
Este artigo descreve o perfil de dados. Este documento apresenta uma visão geral dos componentes e da utilização do perfil de dados.
O perfil de dados fornece estatísticas resumidas para uma tabela, calculando gráficos de perfil ao longo do tempo para que você possa view facilmente as tendências históricas. É útil para o monitoramento aprofundado de todas as métricas key para tabelas selecionadas. Você também pode usá-lo para acompanhar o desempenho do modelo machine learning e do endpoint do modelo de serviço, analisando as tabelas de inferência que contêm as entradas e previsões do modelo. O diagrama mostra o fluxo de dados através ML pipelines no Databricks e como você pode usar o perfilamento para monitorar continuamente a qualidade dos dados e o desempenho do modelo.
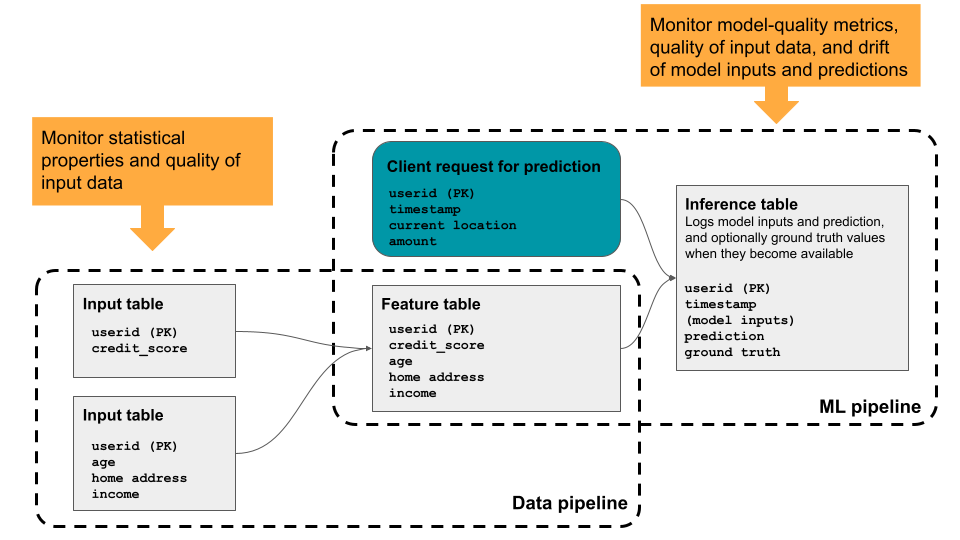
Por que usar perfil de dados?
As métricas quantitativas ajudam você a monitorar e confirmar a qualidade e a consistência dos seus dados ao longo do tempo. Ao detectar alterações na distribuição de dados da sua tabela ou no desempenho do modelo correspondente, as tabelas criadas pelo perfil de dados podem capturar e alertar sobre a alteração, ajudando a identificar a causa.
A análise de perfil de dados ajuda você a responder perguntas como as seguintes:
- Como é a integridade dos dados e como ela muda com o tempo? Por exemplo, qual é a fração de valores nulos ou zero nos dados atuais, e, ela aumentou?
- Como é a distribuição estatística dos dados e como ela muda com o tempo? Por exemplo, qual é o 90º percentil de uma coluna numérica? Ou, qual é a distribuição de valores em uma coluna categórica e como ela difere de ontem?
- Há desvio entre os dados atuais e uma linha de base conhecida ou entre janelas de tempo sucessivas dos dados?
- Como é a distribuição estatística ou desvio de um subconjunto ou fatia dos dados?
- Como as entradas e previsões do modelo de ML estão mudando ao longo do tempo?
- Qual é a tendência do desempenho do modelo com o tempo? A versão do modelo A apresenta um desempenho melhor do que a versão B?
Além disso, o perfil de dados permite controlar a granularidade temporal das observações e configurar métricas personalizadas.
Requisitos
- Seu workspace precisa estar habilitado para Unity Catalog e você precisa ter acesso ao Databricks SQL.
- Para habilitar o perfil de dados, você precisa ter os seguintes privilégios:
USE CATALOGno catálogo eUSE SCHEMAno esquema que contém a tabela.SELECTna tabela.MANAGEno catálogo, esquema ou tabela.
O perfil de dados usa compute serverless para o Job, mas não exige que sua account esteja habilitada para compute serverless . Para informações de acompanhamento sobre despesas, consulte visualizar dados de qualidade de monitoramento de despesas.
Como funciona o perfil de dados
Para criar um perfil de uma tabela, você cria um perfil associado à tabela. Para traçar o perfil do desempenho de um modelo de machine learning, você associa o perfil a uma tabela de inferência que contém as entradas do modelo e as previsões correspondentes.
perfil de dados fornece os seguintes tipos de análise: série temporal, inferência e instantâneo.
Tipo de perfil | Descrição |
|---|---|
Série temporal | Utilize para tabelas que contenham um dataset de séries temporais baseado em uma coluna de registro de data e hora. Análise das métricas de qualidade dos dados computacionais em janelas temporais da série temporal. |
Inferência | Utilize para tabelas que contenham o log de solicitações de um modelo. Cada linha representa uma solicitação, com colunas para o carimbo de data/hora, as entradas do modelo, a previsão correspondente e (opcionalmente) o rótulo de verdade fundamental. A análise de perfil compara o desempenho do modelo e as métricas de qualidade dos dados em janelas temporais do log de solicitações. |
Snapshot | Utilize para todos os outros tipos de tabelas. O perfilamento calcula métricas de qualidade de dados para todos os dados da tabela. A tabela completa é processada a cada refresh. O tamanho máximo de tabela para um perfil de Snapshot é de 4 TB. Para tabelas maiores, utilize perfis de séries temporais. |
Esta seção descreve brevemente as tabelas de entrada utilizadas pelo perfil de dados e as tabelas métricas que ele produz. O diagrama mostra a relação entre as tabelas de entrada, as tabelas de métricas, o perfil e o painel de controle.
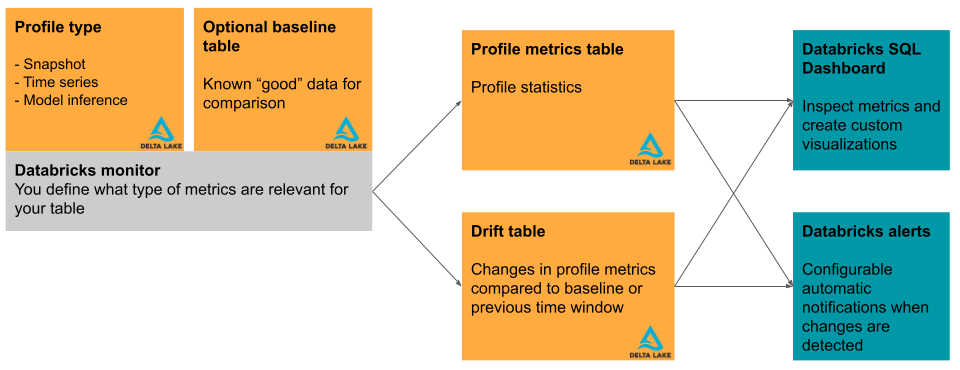
Tabela primária e tabela de base
Além da tabela a ser analisada, chamada de "tabela primária", você pode opcionalmente especificar uma tabela de referência para usar como parâmetro de medição da deriva, ou seja, a variação dos valores ao longo do tempo. Uma tabela de referência é útil quando você tem uma amostra de como espera que seus dados se pareçam. A ideia é que a deriva seja então calculada em relação aos valores e distribuições de dados esperados.
A tabela de referência deve conter um dataset que reflita a qualidade esperada dos dados de entrada, em termos de distribuições estatísticas, distribuições de colunas individuais, valores ausentes e outras características. Deve corresponder ao esquema da tabela perfilada. A exceção é a coluna de data e hora para tabelas usadas com séries temporais ou perfis de inferência. Caso faltem colunas na tabela principal ou na tabela de referência, o perfilamento utiliza heurísticas de melhor esforço para compute as métricas de saída.
Para perfis que utilizam um perfil de Instantâneo, a tabela de linha de base deve conter um Instantâneo dos dados onde a distribuição representa um padrão de qualidade aceitável. Por exemplo, em dados de distribuição de notas, pode-se definir a linha de base como uma turma anterior em que as notas foram distribuídas uniformemente.
Para perfis que utilizam um perfil de série temporal, a tabela de referência deve conter dados que representem janelas de tempo onde as distribuições de dados representem um padrão de qualidade aceitável. Por exemplo, em dados meteorológicos, você pode definir a linha de base para uma semana, mês ou ano em que a temperatura estava próxima das temperaturas normais esperadas.
Para perfis que utilizam um perfil de inferência, uma boa escolha como linha de base são os dados que foram usados para treinar ou validar o modelo que está sendo analisado. Dessa forma, os usuários podem ser alertados quando os dados se desviarem em relação ao que o modelo foi treinado e validado. Esta tabela deve conter as mesmas colunas de recurso que a tabela primária e, adicionalmente, deve ter o mesmo model_id_col que foi especificado para o InferenceLog da tabela primária, para que os dados sejam agregados de forma consistente. Idealmente, o conjunto de teste ou validação usado para avaliar o modelo deve ser utilizado para garantir métricas de qualidade do modelo comparáveis.
Tabelas de métricas e painel de controle
A criação de perfis gera duas tabelas de métricas e um painel de controle. Os valores das métricas são calculados para a tabela inteira, bem como para os intervalos de tempo e subconjuntos de dados (ou "fatias") que você especifica ao criar o perfil. Além disso, para a análise de inferência, as métricas são calculadas para cada ID de modelo. Para obter mais detalhes sobre as tabelas de métricas, consulte Tabelas de métricas de perfil de dados.
- A tabela de métricas de perfil contém estatísticas resumidas. Consulte o esquema da tabela de métricas de perfil.
- A tabela de métricas de deriva contém estatísticas relacionadas à deriva dos dados ao longo do tempo. Caso seja fornecida uma tabela de referência, o desvio também é analisado em relação aos valores de referência. Consulte o esquema da tabela de métricas de deriva.
As tabelas de métricas são tabelas Delta e são armazenadas em um esquema do Unity Catalog que você especifica. Você pode ver essas tabelas utilizando a interface de usuário do Databricks, consultá-las utilizando o Databricks SQL e criar painéis e alertas com base nelas.
Para cada perfil, o Databricks cria automaticamente um painel para ajudar você a visualizar e apresentar os resultados do perfil. O painel de controle é totalmente personalizável. Consulte os painéis de controle.
Limitações
- Somente tabelas Delta são suportadas para criação de perfis, e a tabela deve ser de um dos seguintes tipos: tabelas de gerenciamento, tabelas externas, visualizações, visualizações materializadas ou tabelas de transmissão.
- Os perfis criados sobre visualizações materializadas não suportam processamento incremental.
- Nem todas as regiões são suportadas. Para suporte regional, consulte a coluna perfil de dados na tabela Disponibilidade de recursosAI e machine learning.
- Os perfis criados usando os modos de análise de séries temporais ou inferência compute apenas as médias dos últimos 30 dias. Caso precise ajustar isso, entre em contato com a equipe da sua account Databricks .
- O tamanho máximo de tabela para um perfil de Snapshot é de 4 TB. Para tabelas maiores, utilize perfis de séries temporais.
começar a usar perfil de dados
Consulte os seguintes artigos para começar:
- Crie um perfil usando a interface do usuário do Databricks.
- Crie um perfil de dados usando a API.
- Tabelas de métricas de perfil de dados.
- Painel de perfil de dados.
- Alerta de perfil.
- Use métricas personalizadas com perfil de dados.
- Monitore modelos servidos usando tabelas de inferência habilitadas para AI Gateway.
- Monitore a imparcialidade e o viés dos modelos de classificação.
- Veja o material de referência da APIperfil de dados.
- Exemplo de caderno.