Regressão com AutoML
Use o AutoML para encontrar automaticamente o melhor algoritmo de regressão e a melhor configuração de hiperparâmetro para prever valores numéricos contínuos.
Configure o experimento de regressão com a interface
O senhor pode configurar um problema de regressão usando a AutoML UI com as seguintes etapas:
-
Na barra lateral, selecione Experimentos .
-
No cartão Regressão , selecione começar treinamento .
A página Configurar experimento AutoML é exibida. Nessa página, o senhor configura o processo AutoML, especificando o dataset, o tipo de problema, a coluna de destino ou rótulo a ser prevista, as métricas a serem usadas para avaliar e pontuar a execução do experimento e as condições de interrupção.
-
No campo computação , selecione um clustering em execução Databricks Runtime ML.
-
Em dataset , selecione Browse .
-
Navegue até a tabela que você deseja usar e clique em Selecionar . O esquema da tabela é exibido.
- Em Databricks Runtime 10.3 ML e acima, o senhor pode especificar quais colunas AutoML deve usar para treinamento. O senhor não pode remover a coluna selecionada como Alvo de previsão ou a coluna de tempo para dividir os dados.
- Em Databricks Runtime 10.4 LTS ML e acima, o senhor pode especificar como os valores nulos são imputados selecionando a opção Impute with dropdown. Em default, AutoML seleciona um método de imputação com base no tipo e no conteúdo da coluna.
Se o senhor especificar um método de imputação que não seja odefault, o AutoML não realizará a detecção do tipo semântico.
-
Clique no campo Prediction target (Alvo de previsão ). Uma lista suspensa aparece listando as colunas mostradas no esquema. Selecione a coluna que você deseja que o modelo preveja.
-
O campo Nome do experimento mostra o nome default. Para alterá-lo, digite o novo nome no campo.
Você também pode:
- Especifique opções de configuração adicionais.
- Use as tabelas de recursos existentes no recurso Store para aumentar a entrada original dataset.
Configurações avançadas
Abra a seção Configuração avançada (opcional) para acessar esses parâmetros.
-
As métricas de avaliação são as principais métricas usadas para pontuar a execução.
-
Em Databricks Runtime 10.4 LTS ML e acima, o senhor pode excluir as estruturas de treinamento da consideração. Em default, AutoML treina modelos usando as estruturas listadas nos algoritmos deAutoML.
-
Você pode editar as condições de parada. As condições de parada padrão são:
- Para prever experimentos, pare após 120 minutos.
- No Databricks Runtime 10.4 LTS ML e abaixo, para experimentos de classificação e regressão, pare após 60 minutos ou após completar 200 tentativas, o que ocorrer primeiro. Para Databricks Runtime 11.0 ML e acima, o número de tentativas não é usado como uma condição de parada.
- Em Databricks Runtime 10.4 LTS ML e acima, para experimentos de classificação e regressão, AutoML incorpora a parada antecipada; ele interrompe o treinamento e o ajuste dos modelos se as métricas de validação não estiverem mais melhorando.
-
Em Databricks Runtime 10.4 LTS ML e acima, o senhor pode selecionar
time columnpara dividir os dados para treinamento, validação e teste em ordem cronológica (aplica-se somente à classificação e à regressão). -
A Databricks recomenda deixar o campo Diretório de dados vazio. Não preencher este campo aciona o comportamento " default " (Não armazenar em cache), que armazena o dataset de forma segura como um artefato MLflow. É possível especificar um caminho, mas, nesse caso, o DBFS caminho pode ser especificado, mas, nesse caso, o dataset não herda as permissões de acesso do experimento AutoML.
executar o experimento e monitorar os resultados
Para começar o experimento AutoML, clique em começar AutoML . O experimento começa a ser executado, e a página AutoML treinamento é exibida. Para acessar refresh a tabela de execução, clique em ![]() .
.
visualizar o progresso do experimento
Nessa página, você pode:
- Pare o experimento a qualquer momento.
- Abra o Notebook de exploração de dados.
- Monitorar a execução.
- Navegue até a página de execução de qualquer execução.
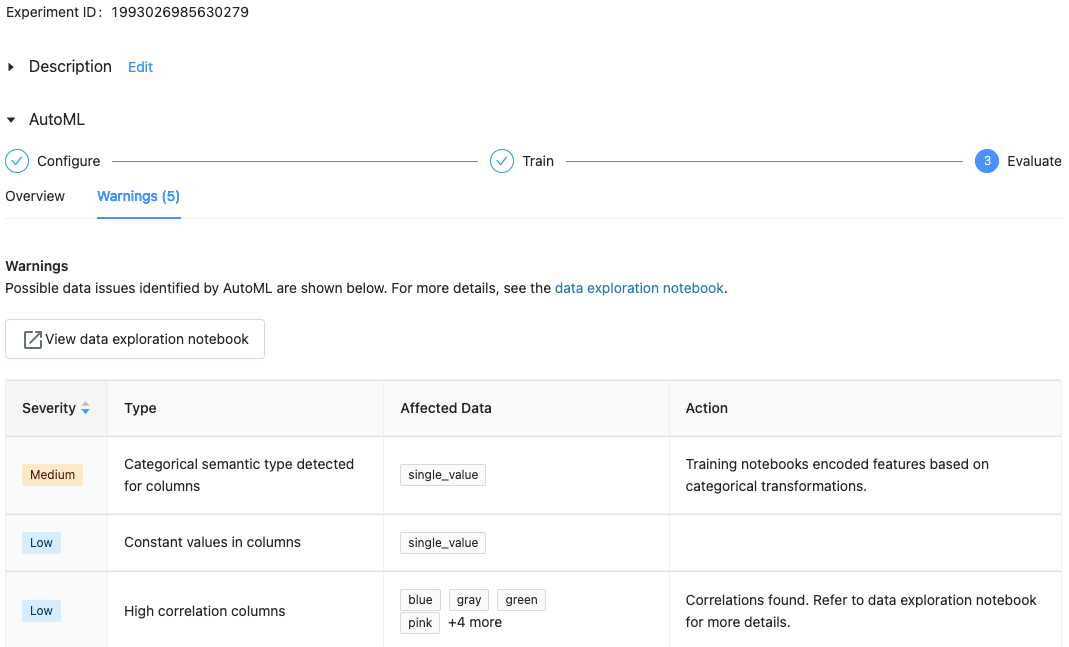
Com o Databricks Runtime 10.1 MLe acima, o AutoML exibe avisos para possíveis problemas com o dataset, como tipos de coluna sem suporte ou colunas de alta cardinalidade.
A Databricks faz o possível para indicar possíveis erros ou problemas. No entanto, isso pode não ser abrangente e pode não capturar os problemas ou erros que você pode estar procurando.
Para ver os avisos do site dataset, clique em Warnings (Avisos ) tab na página de treinamento ou na página do experimento após a conclusão do experimento.
ver resultados
Quando o experimento for concluído, você poderá:
- registro e implantado um dos modelos com MLflow.
- Selecione view Notebook for best model para revisar e editar o Notebook que criou o melhor modelo.
- Selecione view Notebook de exploração de dados para abrir o Notebook de exploração de dados.
- O senhor pode pesquisar, filtrar e classificar a execução na tabela de execução.
- Veja os detalhes para qualquer execução:
- O Notebook gerado contendo o código-fonte de uma execução de teste pode ser encontrado clicando no endereço MLflow execução. O Notebook é salvo na seção Artifacts (Artefatos ) da página de execução. O senhor pode download esse Notebook e importá-lo para o workspace, se os downloads de artefatos estiverem ativados pelos administradores do workspace.
- Para view os resultados da execução, clique na coluna Models ou na coluna Come Time . A página de execução é exibida, mostrando informações sobre a execução do teste (como parâmetros, métricas e tags) e artefatos criados pela execução, incluindo o modelo. Essa página também inclui trechos de código que você pode usar para fazer previsões com o modelo.
Para retornar a esse experimento do AutoML posteriormente, localize-o na tabela da página Experimentos. Os resultados de cada experimento do AutoML, inclusive a exploração de dados e o treinamento do Notebook, são armazenados em uma pasta databricks_automl na pasta home do usuário que executou o experimento.
registro e implantação de um modelo
Registre e implante seu modelo utilizando a interface do usuário AutoML. Quando a execução é concluída, a linha superior exibe o melhor modelo com base nas métricas primárias.
-
Selecione o link na coluna Modelos para o modelo que deseja registrar.
-
Selecione “
 ” para registrá-lo em Unity Catalog ou Model Registry.
” para registrá-lo em Unity Catalog ou Model Registry.
Databricks Recomendamos que registre os modelos em Unity Catalog para obter os recursos mais recentes.
- Após o registro, é possível implantar o modelo em um modelo personalizado, utilizando o link endpoint.
Nenhum módulo chamado 'pandas.core.indexes.numeric'
Ao servir um modelo criado usando AutoML com servindo modelo, o senhor pode receber o erro: No module named 'pandas.core.indexes.numeric.
Isso se deve a uma versão pandas incompatível entre AutoML e o ambiente servindo modelo endpoint. Você pode resolver esse erro executando o script add-pandas-dependency.py. O script edita requirements.txt e conda.yaml para o seu modelo registrado para incluir a versão apropriada da dependência pandas: pandas==1.5.3
- Modifique o script para incluir o
run_idda execução MLflow em que seu modelo foi registrado. - Registre novamente o modelo em Unity Catalog ou no registro de modelo.
- Tente usar a nova versão do modelo MLflow.