provisionamento Taxa de transferência Foundation Model APIs
Este artigo demonstra como implantar modelos usando o Foundation Model APIs provisionamento Taxa de transferência. Databricks recomenda o provisionamento de taxas de transferência para cargas de trabalho de produção e fornece inferência otimizada para modelos de fundação com garantias de desempenho.
O que é provisionamento Taxa de transferência?
Ao criar um provisionamento Taxa de transferência servindo o modelo endpoint em Databricks, o senhor aloca capacidade de inferência dedicada para garantir uma Taxa de transferência consistente para o modelo de fundação que deseja servir. O endpoint servindo modelo que serve modelos de fundação pode ser provisionado em pedaços de unidades de modelo. O número de unidades do modelo que o senhor aloca permite adquirir exatamente a taxa de transferência necessária para dar suporte confiável à sua aplicação GenAI de produção.
Para obter uma lista das arquiteturas de modelo suportadas para o endpoint de provisionamento Taxa de transferência, consulte Modelos de base suportados no Mosaic AI Model Serving.
Requisitos
Consulte os Requisitos.
[Recomendado] implantado modelos de fundação de Unity Catalog
A Databricks recomenda o uso dos modelos básicos que estão pré-instalados no Unity Catalog. Você pode encontrar esses modelos no catálogo system no esquema ai (system.ai).
Implantar um modelo de fundação:
- Navegue até
system.aino Catalog Explorer. - Clique no nome do modelo a ser implantado.
- Na página do modelo, clique no botão Servir este modelo .
- A página Create serving endpoint é exibida. Consulte Criar seu provisionamento Taxa de transferência endpoint usando a UI.
Para implantar um modelo Meta Llama de system.ai em Unity Catalog, o senhor deve escolher a versão do Instruct aplicável. As versões básicas dos modelos Meta Llama não são compatíveis com a implantação a partir do Unity Catalog. Consulte os modelos Foundation hospedados na Databricks para saber quais são as variantes do modelo Meta Llama suportadas.
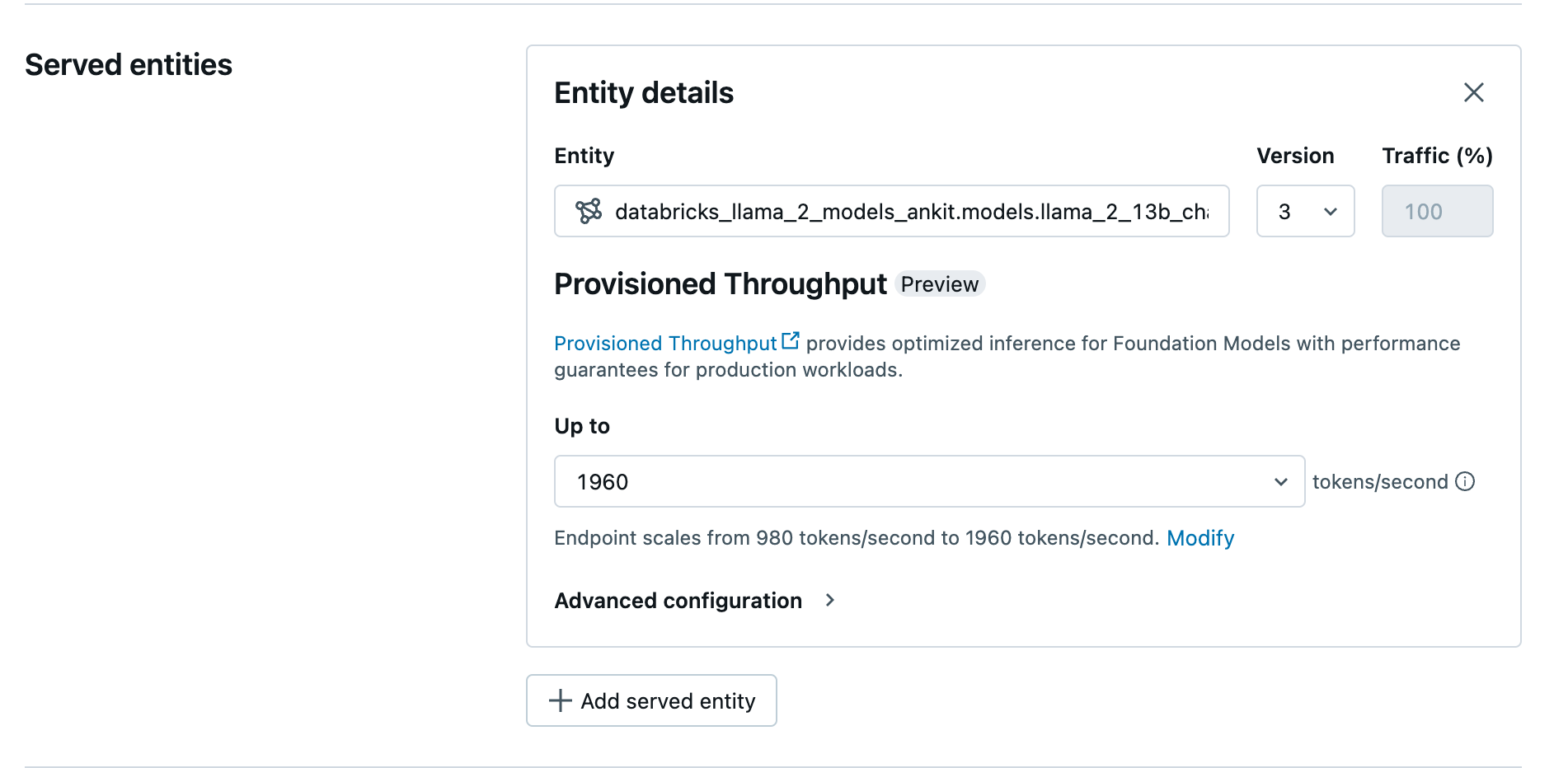
Crie seu provisionamento Taxa de transferência endpoint usando a UI.
Depois que os modelos registrados estiverem em Unity Catalog, crie um provisionamento da Taxa de transferência que atenda a endpoint com as seguintes etapas:
- Navegue até a UI de serviço em seu site workspace.
- Selecione Criar endpoint de serviço .
- No campo Entity (Entidade ), selecione seu modelo no Unity Catalog. Para modelos elegíveis, a interface do usuário da entidade atendida mostra a tela de provisionamento Taxa de transferência .
- Em Up to dropdown o senhor pode configurar o máximo de tokens por segundo Taxa de transferência para o seu endpoint.
- provisionamento O ponto de extremidade da taxa de transferência escala automaticamente, de modo que o senhor pode selecionar Modify para view o mínimo de tokens por segundo que seu endpoint pode escalar.
Crie seu provisionamento Taxa de transferência endpoint usando o site REST API
Para implantar seu modelo no modo de provisionamento Taxa de transferência usando o site REST API, o senhor deve especificar os campos min_provisioned_throughput e max_provisioned_throughput em sua solicitação. Se preferir o Python, o senhor também pode criar um endpoint usando o MLflow Deployment SDK.
Para identificar a faixa adequada de provisionamento da Taxa de transferência para seu modelo, consulte Obter provisionamento da Taxa de transferência em incrementos.
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "prov-throughput-endpoint"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.foundation-model"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = "<YOUR-API-URL>"
API_TOKEN = "<YOUR-API-TOKEN>"
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
probabilidade logarítmica de conclusão do chat tarefa
Para a tarefa de conclusão do chat, você pode usar o parâmetro logprobs para fornecer a probabilidade log de um token ser amostrado como parte do processo de geração do modelo de linguagem em larga escala. Você pode usar logprobs para uma variedade de cenários, incluindo classificação, avaliação da incerteza do modelo e execução de métricas de avaliação. Consulte a API de Complementações de Chat para obter detalhes sobre os parâmetros.
Obter provisionamento Taxa de transferência em incrementos
O provisionamento Taxa de transferência está disponível em incrementos de tokens por segundo, com incrementos específicos que variam de acordo com o modelo. Para identificar a faixa adequada às suas necessidades, o site Databricks recomenda o uso das informações de otimização do modelo API na plataforma.
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
A seguir, um exemplo de resposta da API:
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 980
}
{
"optimizable": true,
"model_type": "gte",
"throughput_chunk_size": 980
}
Limitação
- A implantação do modelo pode falhar devido a problemas de capacidade da GPU, o que resulta em um tempo limite durante a criação ou atualização do endpoint. Entre em contato com a equipe do Databricks account para ajudar a resolver o problema.