Treine modelos recomendadores
Este artigo inclui dois exemplos de modelos de recomendação baseados em aprendizagem profunda em Databricks. Em comparação com os modelos de recomendação tradicionais, os modelos de aprendizagem profunda podem alcançar resultados de maior qualidade e escalar para quantidades maiores de dados. À medida que esses modelos continuam a evoluir, a Databricks fornece uma estrutura para o treinamento eficaz de modelos de recomendação em larga escala, capazes de lidar com centenas de milhões de usuários.
Um sistema de recomendação geral pode ser visto como um funnel com os estágios mostrados no diagrama.
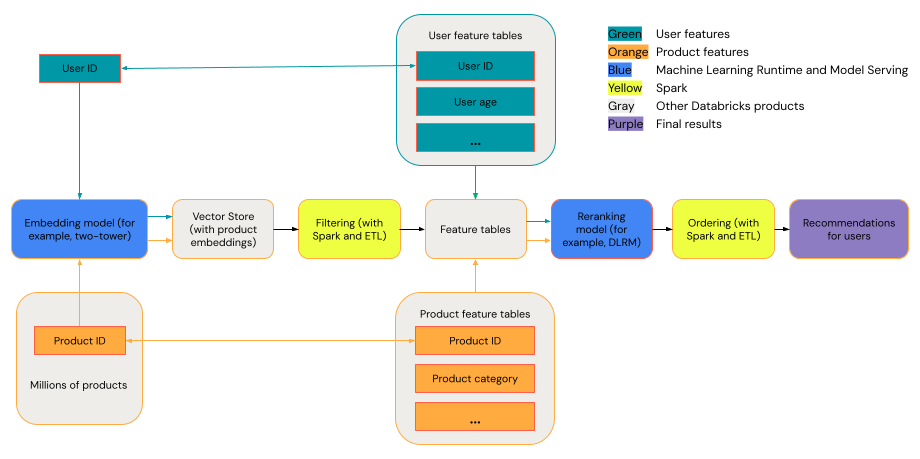
Alguns modelos, como o modelo de duas torres, funcionam melhor como modelos de recuperação. Esses modelos são menores e podem operar efetivamente com milhões de pontos de dados. Outros modelos, como DLRM ou DeepFM, funcionam melhor como modelos de reclassificação. Esses modelos podem absorver mais dados, são maiores e podem fornecer recomendações detalhadas.
Requisitos
Databricks Runtime 14.3 LTS ML
Ferramentas
Os exemplos neste artigo ilustram as seguintes ferramentas:
- TorchDistributorTorchDistributor é uma estrutura que permite ao senhor executar treinamento de modelos de grande escala PyTorch em Databricks. Ele usa o site Spark para orquestração e pode escalar para quantas GPUs estiverem disponíveis em seu clustering.
- Mosaic StreamingDataset: O StreamingDataset melhora o desempenho e a escalabilidade do treinamento em grandes conjuntos de dados em Databricks usando recursos como prefetching e interleaving.
- MLflow: O MLflow permite que o senhor rastreie parâmetros, métricas e pontos de verificação do modelo.
- TorchRec: Os sistemas de recomendação modernos usam tabelas de pesquisa incorporadas para lidar com milhões de usuários e itens para gerar recomendações de alta qualidade. Tamanhos maiores de incorporação melhoram o desempenho do modelo, mas exigem memória de GPU substancial e configurações de várias GPUs. O TorchRec fornece uma estrutura para escalonar modelos de recomendação e tabelas de pesquisa em várias GPUs, o que o torna ideal para grandes embeddings.
Exemplo: recomendações de filmes usando uma arquitetura de modelo de duas torres
O modelo de duas torres foi projetado para lidar com tarefas de personalização de grande escala, processando os dados do usuário e do item separadamente antes de combiná-los. Ele é capaz de gerar com eficiência centenas ou milhares de recomendações de qualidade decentes. O modelo geralmente espera três entradas: Um recurso user_id, um recurso produto e um rótulo binário que define se a interação <user, produto> foi positiva (o usuário comprou o produto) ou negativa (o usuário deu ao produto uma classificação de uma estrela). Os resultados do modelo são embeddings para usuários e itens, que geralmente são combinados (geralmente usando um produto de ponto ou similaridade de cosseno) para prever as interações entre usuário e item.
Como o modelo de duas torres fornece embeddings para usuários e produtos, o senhor pode colocar esses embeddings em um índice vetorial, como Mosaic AI Vector Searche executar operações do tipo busca por similaridade nos usuários e itens. Por exemplo, você pode colocar todos os itens em uma loja vetorial e, para cada usuário, consultar a loja vetorial para encontrar os cem principais itens cujas incorporações são semelhantes às do usuário.
O exemplo de Notebook a seguir implementa o treinamento do modelo de duas torres usando o "Learning from Sets of Items" dataset para prever a probabilidade de um usuário classificar um determinado filme como alto. Ele usa o Mosaic StreamingDataset para carregamento de dados distribuídos, TorchDistributor para treinamento de modelos distribuídos e MLflow para acompanhamento e registro de modelos.
Notebook com modelo de recomendação de duas torres
Este notebook também está disponível no site Databricks Marketplace: Notebook modelo de duas torres
- Os inputs para o modelo de duas torres são, na maioria das vezes, o recurso categórico user_id e produto. O modelo pode ser modificado para suportar vários vetores de recurso para usuários e produtos.
- Os resultados do modelo de duas torres são geralmente valores binários que indicam se o usuário terá uma interação positiva ou negativa com o produto. O modelo pode ser modificado para outros aplicativos, como regressão, classificação multiclasse e probabilidades de várias ações do usuário (por exemplo, dispensar ou comprar). Saídas complexas devem ser implementadas com cuidado, pois objetivos concorrentes podem degradar a qualidade das incorporações geradas pelo modelo.
Exemplo: Treinar uma arquitetura DLRM usando um dataset
O DLRM é uma arquitetura de rede neural de última geração projetada especificamente para sistemas de personalização e recomendação. Ele combina entradas categóricas e numéricas para modelar com eficácia as interações entre usuários e prever as preferências do usuário. Em geral, os DLRMs esperam inputs que incluam tanto recursos esparsos (como ID do usuário, ID do item, localização geográfica ou categoria do produto) quanto recursos densos (como idade do usuário ou preço do item). A saída de um DLRM geralmente é uma previsão do engajamento do usuário, como taxas de cliques ou probabilidade de compra.
Os DLRMs oferecem uma estrutura altamente personalizável que pode lidar com dados de grande escala, tornando-a adequada para tarefas de recomendação complexas em vários domínios. Por ser um modelo maior do que a arquitetura de duas torres, esse modelo é frequentemente usado na fase de reclassificação.
O exemplo de Notebook a seguir cria um modelo DLRM para prever o rótulo binário usando recurso denso (numérico) e recurso esparso (categórico). Ele usa um dataset sintético para ensinar o modelo, o Mosaic StreamingDataset para carregamento de dados distribuídos, TorchDistributor para treinamento de modelos distribuídos e MLflow para acompanhamento e registro de modelos.
Caderno DLRM
Esse notebook também está disponível no site Databricks Marketplace: DLRM Notebook.
Exemplo: Ajuste fino de modelos de incorporação com llm-foundry em computeGPU serverless
Os modelos de incorporação são um componente crítico dos sistemas de recomendação modernos, particularmente na fase de recuperação, onde permitem uma busca eficiente por similaridade em milhões de itens. Embora o modelo de duas torres gere incorporações específicas para cada tarefa, os modelos de incorporação pré-treinados podem ser ajustados para aplicações específicas de domínio, a fim de melhorar a qualidade da recuperação de dados.
O seguinte exemplo de Notebook demonstra como usar o aprendizado contrastivo para ajustar um modelo de incorporação no estilo BERT em compute GPU serverless (SGC). Ele usa o framework llm-foundry com o trainer do Composer para ajustar modelos como o gte-large-en-v1.5, trabalhando com dados armazenados em tabelas Delta. Este exemplo utiliza o Mosaic Transmission para converter dados para o formato Mosaic Data Shard (MDS) para carregamento distribuído de dados e MLflow para acompanhamento e registro do modelo.
Notebook para ajuste fino do modelo de incorporação
- O modelo de incorporação espera dados com colunas para
query_text,positive_passagee opcionalmentenegative_passages. - Os embeddings ajustados podem ser usados em armazenamentos vetoriais para operações de busca por similaridade, permitindo a recuperação eficiente de itens relevantes para sistemas de recomendação.
- Essa abordagem é particularmente útil quando você precisa adaptar um modelo de incorporação de propósito geral ao seu domínio ou caso de uso específico.
Comparação de modelos de duas torres e DLRM
A tabela mostra algumas diretrizes para selecionar qual modelo de recomendação usar.
Tipo de modelo | tamanho do conjunto de dados necessário para o treinamento | Tamanho do modelo | Tipos de entrada suportados | Tipos de saída suportados | Casos de uso |
|---|---|---|---|---|---|
Duas torres | Menor | Menor | Normalmente, dois recursos (user_id, produto) | Principalmente classificação binária e geração de incorporações | Gerando centenas ou milhares de recomendações possíveis |
DORMÊNCIA | Maior | Maior | Vários recursos categóricos e densos (user_id, gender, geographic_location, produto, produto, ...) | Classificação multiclasse, regressão, outras | Recuperação refinada (recomendando dezenas de itens altamente relevantes) |
Em resumo, o modelo de duas torres é melhor usado para gerar milhares de recomendações de boa qualidade com muita eficiência. Um exemplo pode ser a recomendação de filmes de um provedor de TV a cabo. O modelo DLRM é melhor usado para gerar recomendações muito específicas com base em mais dados. Um exemplo pode ser um varejista que deseja apresentar a um cliente um número menor de itens que ele provavelmente comprará.