Conecte-se ao Looker
Este artigo descreve como usar o Looker com um Databricks clustering ou Databricks SQL warehouse (anteriormente Databricks SQL endpoint).
Quando as tabelas derivadas persistentes (PDTs) estão ativadas, o site default Looker gera novamente as PDTs a cada 5 minutos, conectando-se ao banco de dados associado. Databricks recomenda que o senhor altere a frequência do default para evitar custos excessivos com o compute. Para obter mais informações, consulte Habilitar e gerenciar tabelas derivadas persistentes (PDTs).
Requisitos
Antes de se conectar ao Looker manualmente, o senhor precisa do seguinte:
-
Um agrupamento ou SQL warehouse em seu Databricks workspace.
-
Os detalhes da conexão para seu clustering ou SQL warehouse, especificamente os valores de Server Hostname , Port e HTTP Path .
-
Um access tokenpessoal Databricks . Para criar um access token pessoal, siga os passos em Criar access tokens pessoais para usuários workspace.
Como prática recomendada de segurança ao se autenticar com ferramentas, sistemas, scripts e aplicativos automatizados, a Databricks recomenda que você use tokens OAuth.
Se o senhor usar a autenticação de tokens de acesso pessoal, a Databricks recomenda usar o acesso pessoal tokens pertencente à entidade de serviço em vez de usuários workspace. Para criar tokens o site para uma entidade de serviço, consulte gerenciar tokens para uma entidade de serviço.
Conectar-se ao Looker manualmente
Para se conectar ao Looker manualmente, faça o seguinte:
-
No Looker, clique em Admin > Connections > Add Connection (Adicionar conexão ).
-
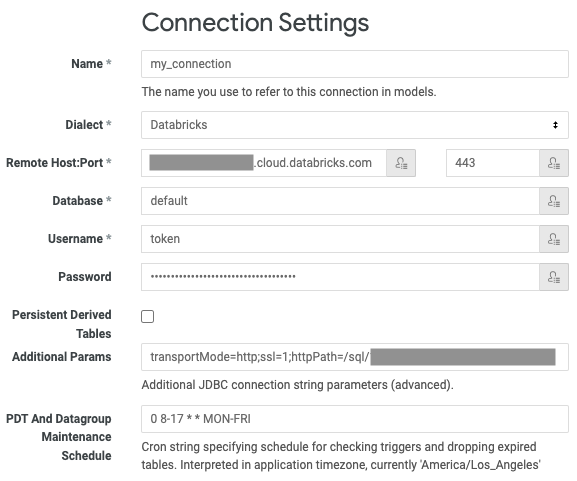
Insira um nome exclusivo para a conexão.
Os nomes das conexões devem conter apenas letras minúsculas, números e sublinhado. Outros caracteres podem ser aceitos, mas podem causar resultados inesperados posteriormente.
-
Para Dialect , selecione Databricks .
-
Para Host remoto , insira o nome do host do servidor nos requisitos.
-
Em Porta , insira a Porta a partir dos requisitos.
-
Em Database (Banco de dados ), digite o nome do banco de dados no site workspace que o senhor deseja acessar por meio da conexão (por exemplo,
default). -
Em Nome de usuário , digite a palavra
token. -
Para Password (Senha ), insira seus tokens de acesso pessoal dos requisitos.
-
Em Parâmetros adicionais , insira
transportMode=http;ssl=1;httpPath=<http-path>, substituindo<http-path>pelo valor do caminho HTTP dos requisitos.Se o Unity Catalog estiver ativado para o seu workspace, defina adicionalmente um catálogo default. Digite
ConnCatalog=<catalog-name>, substituindo<catalog-name>pelo nome de um catálogo. -
Para o programa PDT And Datagroup Maintenance , digite uma expressão
cronválida para alterar a frequência default para regenerar PDTs. A frequência do default é a cada cinco minutos. -
Se você quiser traduzir consultas para outros fusos horários, ajuste o fuso horário da consulta .
-
Para os campos restantes, mantenha o padrão, em particular:
- Mantenha o padrão de Max Connections (Máximo de conexões ) e Connection pool Timeout (Tempo limite do pool de conexões ).
- Deixe o fuso horário do banco de dados em branco (supondo que você esteja armazenando tudo em UTC).
-
Clique em Testar essas configurações .
-
Se o teste for bem-sucedido, clique em Adicionar conexão .
Modelar seu banco de dados no Looker
Esta seção cria um projeto e executa o gerador. As etapas a seguir pressupõem que haja tabelas permanentes armazenadas no banco de dados para sua conexão.
-
No menu Develop (Desenvolvimento ), ative o Development Mode (Modo de desenvolvimento ).
-
Clique em Develop > gerenciar projetos LookML .
-
Clique em Novo projeto LookML .
-
Insira um nome de projeto exclusivo.
Os nomes dos projetos devem conter apenas letras minúsculas, números e sublinhados. Outros caracteres podem ser aceitos, mas podem produzir resultados inesperados posteriormente.
-
Para Connection , selecione o nome da conexão da passo 2.
-
Em Esquemas , insira
default, a menos que você tenha outros bancos de dados para modelar por meio da conexão. -
Para os campos restantes, mantenha o padrão, em particular:
- Deixe o ponto de partida definido para gerar modelo a partir do esquema do banco de dados .
- Deixe a visualização Build From definida como All Tables .
-
Clique em Criar projeto .
Após a criação do projeto e a execução do gerador, o site Looker exibe uma interface de usuário com um arquivo .model e vários arquivos .view. O arquivo .model mostra as tabelas no esquema e quaisquer relações join descobertas entre elas, e os arquivos .view listam cada dimensão (coluna) disponível para cada tabela no esquema.
Próximas etapas
Para começar a trabalhar com seu projeto, consulte o recurso a seguir no site Looker:
Habilitar e gerenciar tabelas derivadas persistentes (PDTs)
O Looker pode reduzir o tempo de consulta e a carga do banco de dados criando tabelas derivadas persistentes (PDTs). Uma PDT é uma tabela derivada que o Looker grava em um esquema de rascunho em seu banco de dados. Looker gera novamente o PDT no programar que o senhor especificar. Para obter mais informações, consulte Tabelas derivadas persistentes (PDTs) na documentação do site Looker.
Para habilitar PDTs para uma conexão de banco de dados, selecione Tabelas derivadas persistentes para essa conexão e complete as instruções na tela. Para obter mais informações, consulte Persistent Derived Tables e Configuring Separate Login Credentials for PDT Processes na documentação Looker.
Quando os PDTs estão ativados, o site default Looker gera novamente os PDTs a cada 5 minutos, conectando-se ao banco de dados associado. O Looker reinicia o recurso Databricks associado se ele for interrompido. Databricks recomenda que o senhor altere a frequência de default definindo o campo PDT And Datagroup Maintenance programar da sua conexão de banco de dados como uma expressão cron válida. Para obter mais informações, consulte PDT e Datagroup Maintenance programar na documentação do site Looker.
Para habilitar PDTs ou alterar a frequência de regeneração de PDT para uma conexão de banco de dados existente, clique em Admin > Conexões de banco de dados , clique em Editar ao lado da sua conexão de banco de dados e siga as instruções anteriores.