April 2018
Releases are staged. Your Databricks account may not be updated until a week after the initial release date.
We are now providing Databricks Runtime deprecation notices in Databricks Runtime release notes versions and compatibility.
AWS account updates
April 24 - May 1, 2018: Version 2.70
You can now change the AWS account associated with your Databricks account.
See Configure your AWS cross-account IAM role (legacy).
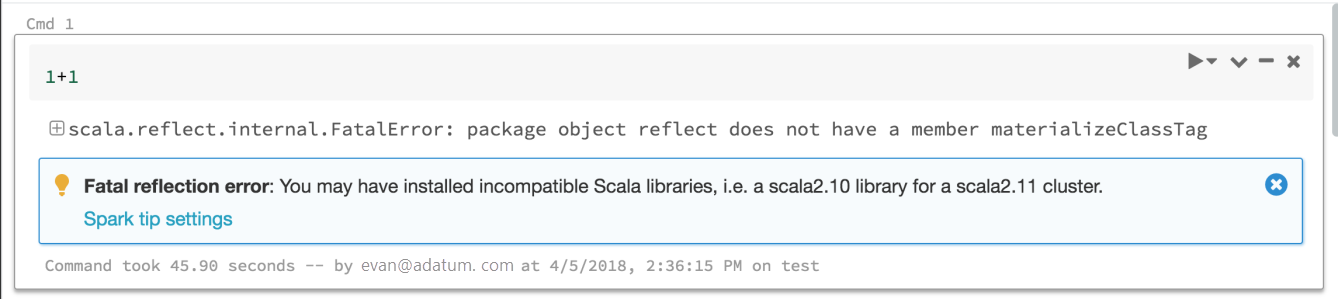
Spark error tips
April 24 - May 1, 2018: Version 2.70
Databricks now provides tips to help you interpret and troubleshoot many of the errors you might see when you run Spark commands. And we'll keep adding more.
Databricks CLI 0.7.0
April 24, 2018
Databricks CLI 0.7.0 includes bug fixes.
Increase init script output truncation limit
April 24 - May 1, 2018: Version 2.70
We have increased the output truncation limit for init scripts to 500,000 characters.
Clusters API: added UPSIZE_COMPLETED event type
April 24 - May 1, 2018: Version 2.70
The new UPSIZE_COMPLETED cluster event type indicates that nodes have finished being added to a cluster.
See Clusters API in the Clusters API reference.
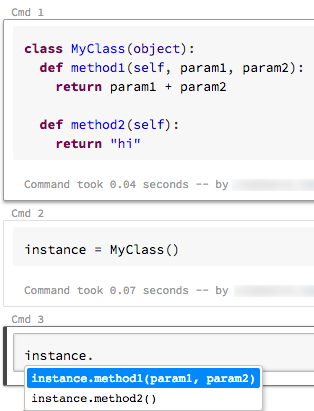
Command autocomplete
April 10 - 17, 2018: Version 2.69
Databricks now supports two types of autocomplete in your notebooks: local and server. Local autocomplete completes words that exist in the notebook. Server autocomplete is more powerful because it accesses the cluster for defined types, classes, and objects, as well as SQL database and table names. To activate server autocomplete you must attach your notebook to a running cluster and run all cells that define completable objects.
Serverless pools upgraded to Databricks Runtime 4.0
April 10, 2018
The serverless pools runtime version has been upgraded from Databricks Runtime 3.5 (which includes Apache Spark 2.2.1) to Databricks Runtime 4.0 (which includes Apache Spark 2.3.0). You must restart your clusters to pick up this change.
The upgrade represents a minor Apache Spark version update and is backwards compatible.