CI/CD com pastas Git do Databricks
As pastas Git da Databricks podem ser usadas em seus fluxos de CI/CD. Ao configurar as pastas Databricks Git no workspace, o senhor pode usar o controle de origem para trabalhar nos repositórios Git e integrá-los ao seu fluxo de trabalho de engenharia de dados. Para obter uma visão geral mais abrangente da CI/CD com a Databricks, consulte CI/CD na Databricks.
Fluxos de uso
A maior parte do trabalho de desenvolvimento da automação para as pastas do Git está na configuração inicial das pastas e na compreensão do Databricks Repos REST API que o senhor usa para automatizar as Git operações do Databricks Job. Antes de começar a criar a automação e configurar as pastas, analise os repositórios remotos do Git que serão incorporados aos fluxos de automação e selecione os repositórios certos para os diferentes estágios da automação, incluindo desenvolvimento, integração, preparação e produção.
- Fluxo do administrador : Para fluxos de produção, um administrador do Databricks workspace configura pastas de nível superior no seu workspace para hospedar as pastas git de produção. O administrador clona um repositório Git e uma ramificação ao criá-los e pode dar a essas pastas nomes significativos, como "Production", "Test" ou "Staging", que correspondem à finalidade dos repositórios Git remotos em seus fluxos de desenvolvimento. Para obter mais detalhes, consulte Pasta Git de produção.
- Fluxo do usuário : Um usuário pode criar uma pasta Git em
/Workspace/Users/<email>/com base em um repositório Git remoto. Um usuário cria uma ramificação local específica do usuário para o trabalho que o usuário commit fará nela e enviará para o repositório remoto. Para obter informações sobre como colaborar em pastas Git específicas do usuário, consulte Colaborar usando pastas Git. - fluxo de mesclagem : Os usuários podem criar solicitações pull (PRs) depois de fazer push de uma pasta Git. Quando o PR é mesclado, a automação pode puxar as alterações para as pastas de produção Git usando o Databricks Repos API.
Colaborar usando pastas Git
O senhor pode colaborar facilmente com outras pessoas usando pastas Git, obtendo atualizações e enviando alterações diretamente da interface do usuário do Databricks. Por exemplo, use um recurso ou ramo de desenvolvimento para agregar alterações feitas em vários ramos.
O fluxo a seguir descreve como colaborar usando uma ramificação de recurso:
-
Clone o repositório Git existente para o Databricks workspace .
-
Use a UI de pastas do Git para criar uma ramificação de recurso a partir da ramificação principal. O senhor pode criar e usar várias ramificações de recurso para fazer seu trabalho.
-
Faça suas modificações no Databricks Notebook e em outros arquivos do repositório.
-
Faça o commit e envie suas alterações para o repositório Git remoto.
-
Os colaboradores agora podem clonar o repositório Git em sua própria pasta de usuário.
- Trabalhando em uma nova filial, um colega de trabalho faz alterações no Notebook e em outros arquivos na pasta Git.
- O colaborador faz o commit e envia suas alterações para o repositório Git remoto.
-
Quando o senhor ou outros colaboradores estiverem prontos para merge seu código, crie um PR no site do provedor Git. Revise seu código com sua equipe antes de mesclar as alterações na ramificação de implantação.
A Databricks recomenda que cada desenvolvedor trabalhe em seu próprio ramo. Para obter informações sobre como resolver conflitos em merge, consulte Resolver conflitos em merge.
Escolha uma abordagem de CI/CD
Databricks recomenda usar Databricks ativo Bundles para empacotar e implantar seu fluxo de trabalho CI/CD . No entanto, se preferir implantar apenas os arquivos de código no workspace, você pode configurar uma pasta Git de produção. Para uma visão geral mais abrangente de CI/CD com Databricks, consulte CI/CD no Databricks.
Defina recursos como Job e pipeline em arquivos de origem usando bundles e, em seguida, crie, implante e gerencie bundles nas pastas workspace Git . Consulte Colaboração em pacotes no site workspace.
Pasta Git de produção
As pastas Git de produção têm uma finalidade diferente das pastas Git de nível de usuário localizadas na pasta do usuário em /Workspace/Users/. As pastas Git no nível do usuário funcionam como checkouts locais, onde os usuários desenvolvem e enviam alterações de código. Por outro lado, as pastas Git de produção são criadas pelos administradores da Databricks fora das pastas de usuário e contêm ramificações de implantação de produção. As pastas Production Git contêm o código-fonte do fluxo de trabalho automatizado e só devem ser atualizadas programaticamente quando as solicitações pull (PRs) são mescladas nas ramificações de implantação. Para as pastas de produção Git, limite o acesso do usuário a somente execução e permita que apenas os administradores e a Databricks entidade de serviço editem.
Para criar uma pasta de produção do Git:
-
Escolha um repositório Git e uma ramificação para a implantação.
-
Obtenha uma entidade de serviço e configure uma credencial do Git para que a entidade de serviço acesse esse repositório do Git.
-
Crie uma pasta do Databricks Git para o repositório e a ramificação do Git em uma subpasta em
Workspacededicada a um projeto, equipe e estágio de desenvolvimento. -
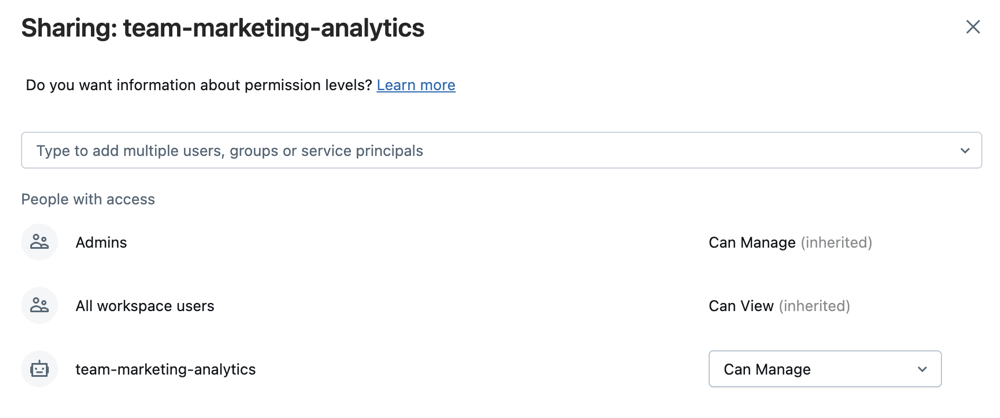
Selecione Share depois de selecionar a pasta ou Share (Permissions) clicando com o botão direito do mouse na pasta na árvore do espaço de trabalho . Configure a pasta Git com as seguintes permissões:
- Definir Can executar para qualquer usuário do projeto
- O senhor pode definir o Can Execution para qualquer conta da Databricks entidade de serviço que irá executar a automação para ela.
- Se for apropriado para o seu projeto, defina Can view para todos os usuários no site workspace para incentivar a descoberta e o compartilhamento.
-
Selecione Adicionar .
-
Configure atualizações automatizadas para as pastas Git do Databricks. O senhor pode usar a automação para manter uma pasta Git de produção sincronizada com a ramificação remota, seguindo um destes procedimentos:
- Utilize ferramentas externas CI/CD como GitHub Actions para obter o commit mais recente em uma pasta Git de produção quando uma solicitação de pull request for mesclada na branch de implantação. Para obter um exemplo GitHub Actions , consulte execução de um fluxo de trabalho CI/CD que atualiza uma pasta Git.
- Se o senhor não puder acessar as ferramentas externas do CI/CD, crie um trabalho agendado para atualizar uma pasta Git no seu workspace com a ramificação remota. Programar um Notebook simples com o seguinte código para execução periódica:
Pythonfrom databricks.sdk import WorkspaceClient
w = WorkspaceClient()
w.repos.update(w.workspace.get_status(path=”<git-folder-workspace-full-path>”).object_id, branch=”<branch-name>”)
Para obter mais informações sobre automação com o Databricks Repos API, consulte a documentaçãoDatabricks REST API para Repos.