Configurar um gerenciador de clientes VPC
Esta página descreve os benefícios e a implementação de um gerenciador de clientes VPC.
Visão geral
Por default, Databricks clustering são criados em uma única AWS Virtual Private Cloud (VPC) que Databricks cria e configura em seu AWS account.
Como alternativa, o senhor pode criar o seu espaço de trabalho Databricks dentro do seu próprio VPC. Esse recurso é conhecido como customer-gerenciar VPC .
Use um gerenciador de clientes VPC para:
- Controle aprimorado: exerça mais controle sobre suas configurações de rede.
- Conformidade: Cumpra os padrões específicos de segurança e governança da nuvem exigidos por sua organização.
- Políticas internas: Cumpra as políticas de segurança que impedem que os provedores criem VPCs em seu site AWS account.
- Processos de aprovação claros: Alinhe-se aos processos de aprovação internos em que as VPCs devem ser configuradas e protegidas por suas próprias equipes (por exemplo, segurança da informação, engenharia de nuvem).
- PrivateLink: É necessário AWS usar um gerenciador de clientes se o senhor VPC precisar configurar o AWS PrivateLink para qualquer tipo de conexão.
Os benefícios incluem:
-
Nível de privilégio mais baixo: Mantenha mais controle sobre seu AWS account. Databricks requer menos permissões usando o siteaccount IAM role em comparação com a configuração default, o que pode simplificar as aprovações internas.
-
Operações de rede simplificadas: Obtenha uma melhor utilização do espaço de rede configurando sub-redes menores para um workspace em comparação com o default /16 CIDR. Evite configurações de peering de VPC potencialmente complexas.
-
VPCs consolidadas: Vários espaços de trabalho Databricks podem compartilhar um único plano clássico compute VPC, que geralmente é preferido para faturamento e gerenciamento de instâncias.
-
Limitar conexões de saída: Utilize um firewall de saída ou um dispositivo proxy para limitar o tráfego de saída a uma lista de fontes de dados internas ou externas permitidas.
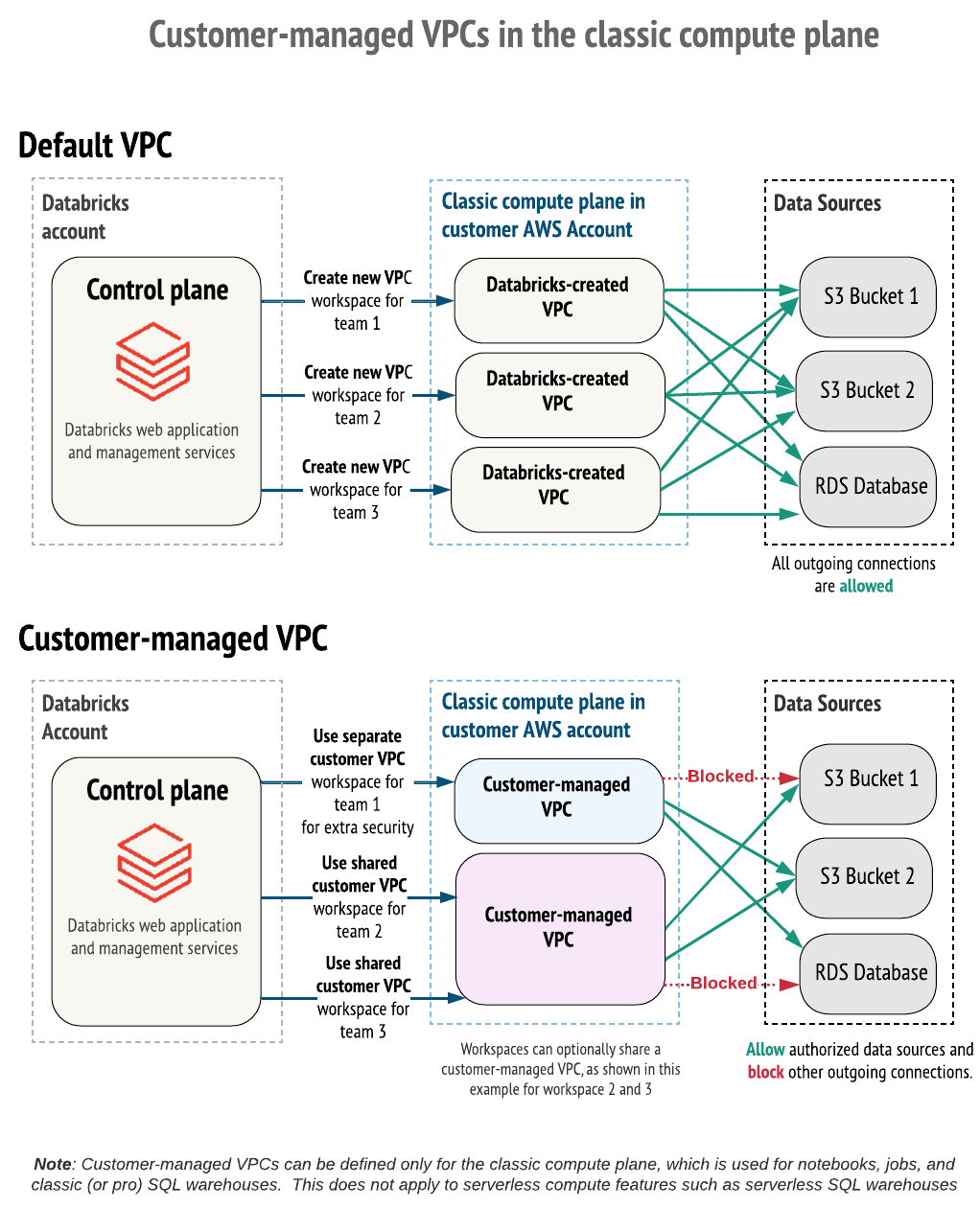
Para tirar proveito de um gerenciador de clientes VPC, o senhor deve especificar um VPC quando criar o Databricks workspace pela primeira vez. O senhor não pode mover um workspace existente com um Databricks-gerenciar VPC para usar um customer-gerenciar VPC. No entanto, o senhor pode mover um workspace existente com um cliente gerenciar VPC de um VPC para outro VPC atualizando o objeto de configuração de rede da configuração workspace. Consulte Atualizar um site em execução ou com falha workspace.
Para implantar um workspace em sua própria VPC, você deve:
-
Crie a VPC seguindo os requisitos enumerados em Requisitos da VPC.
-
Referenciar sua configuração de rede da VPC com o Databricks ao criar o workspace.
- Use o console account e escolha a configuração pelo nome
- Use a conta API e escolha a configuração por seu ID
Você deve fornecer a ID da VPC, as IDs da sub-rede e a ID do grupo de segurança ao registrar a VPC no Databricks.
Requisitos de VPC
Sua VPC deve atender aos requisitos descritos nesta seção para hospedar um workspace do Databricks.
Requisitos:
- Região da VPC
- Dimensionamento da VPC
- Intervalos de endereços IP da VPC
- DNS
- Sub-redes
- Grupos de segurança
- ACLs de rede em nível de sub-rede
- Compatibilidade do AWS PrivateLink
Região VPC
Para obter uma lista das regiões do site AWS que suportam gerenciar clientes VPC, consulte recurso com disponibilidade regional limitada.
Dimensionamento de VPC
O senhor pode compartilhar um VPC com vários espaços de trabalho em um único AWS account. No entanto, o site Databricks recomenda o uso de sub-redes e grupos de segurança exclusivos para cada workspace. Certifique-se de dimensionar sua VPC e suas sub-redes adequadamente. Databricks atribui dois endereços IP por nó, um para o tráfego de gerenciamento e outro para Apache aplicações Spark. O número total de instâncias para cada sub-rede é igual à metade do número de endereços IP disponíveis. Saiba mais em Sub-redes.
Faixas de endereços IP de VPC
Databricks não limita as máscaras de rede para workspace VPC, mas cada sub-rede de workspace deve ter uma máscara de rede entre /17 e /26. Isso significa que se o seu workspace tiver duas sub-redes e ambas tiverem uma máscara de rede de /26, a máscara de rede do seu workspace VPC deverá ser /25 ou menor.
Se você configurou blocos de CIDR secundários para sua VPC, certifique-se de que as sub-redes do workspace do Databricks estejam configuradas com o mesmo bloco de CIDR da VPC.
DNS
A VPC deve ter hostnames DNS e resolução de DNS habilitados.
Sub-redes
O Databricks deve ter acesso a pelo menos duas sub-redes para cada workspace , com cada sub-rede em uma zona de disponibilidade diferente. Não é possível especificar mais de uma sub-rede de workspace do Databricks por zona de disponibilidade em Criar chamada da API de configuração da rede. É possível ter mais de uma sub-rede por zona de disponibilidade como parte de sua configuração de rede, mas só é possível escolher uma sub-rede por zona de disponibilidade para o workspace do Databricks.
Você pode optar por compartilhar uma sub-rede em vários workspaces ou ambas as sub-redes entre workspaces. Por exemplo, você pode ter dois workspaces que compartilham o mesmo VPC. Um workspace pode usar sub-redes A e B e outros workspaces podem usar sub-redes A e C. Se você planeja compartilhar sub-redes entre vários workspaces, dimensione seu VPC e sub-redes para que sejam grandes o suficiente para escalar com o uso.
O Databricks atribui dois endereços IP por nó, um para tráfego de gerenciamento e outro para aplicativos Spark. O número total de instâncias para cada sub-rede é igual à metade do número de endereços IP disponíveis.
Cada sub-rede deve ter uma máscara de rede entre /17 e /26.
Requisitos adicionais de sub-rede
- As sub-redes devem ser privadas.
- As sub-redes devem ter acesso de saída à rede pública por meio de um gateway NAT e um gateway da Internet ou outra infraestrutura semelhante de dispositivo gerenciado pelo cliente.
- O gateway NAT deve ser configurado em sua própria sub-rede, que encaminha o tráfego quad-zero (
0.0.0.0/0) para um gateway de Internet ou outra infraestrutura de dispositivo gerenciado pelo cliente.
O espaço de trabalho deve ter acesso de saída do site VPC para a rede pública. Se você configurar listas de acesso IP, essas redes públicas devem ser adicionadas a uma lista de permissões. Consulte Configurar listas de acesso IP para o espaço de trabalho.
Tabela de rotas de sub-rede
A tabela de roteamento para sub-redes do workspace deve ter tráfego quad-zero (0.0.0.0/0) direcionado ao dispositivo de rede apropriado. O tráfego quad-zero deve ter como alvo um gateway NAT ou seu próprio dispositivo NAT gerenciado ou dispositivo proxy.
A Databricks exige que as sub-redes adicionem 0.0.0.0/0 à sua lista de permissões. Essa deve ser a primeira regra priorizada. Para controlar o tráfego de saída, use um firewall de saída ou um dispositivo proxy para bloquear a maior parte do tráfego, mas permita os URLs aos quais o Databricks precisa se conectar. Consulte Configurar um firewall e acesso externo.
Esta é apenas uma diretriz básica. Seus requisitos de configuração podem ser diferentes. Em caso de dúvidas, entre em contato com sua equipe de conta do Databricks.
Grupos de segurança
Um workspace do Databricks deve ter acesso a pelo menos um grupo de segurança da AWS e no máximo cinco grupos de segurança. Você pode reutilizar grupos de segurança existentes em vez de criar novos. No entanto, o Databricks recomenda o uso de sub-redes e grupos de segurança exclusivos para cada workspace.
Os grupos de segurança devem ter as seguintes regras:
Egresso (saída):
- Autorizar todo o acesso de TCP e UDP ao grupo de segurança do workspace (para tráfego interno)
- Autorizar o acesso de TCP a
0.0.0.0/0para estas portas:- 443: para a infraestrutura do Databricks, fontes de dados em nuvem e repositórios de bibliotecas
- 3306: para o metastore
- 53: para resolução de DNS quando você usa DNS personalizado
- 6666: para conectividade segura de clustering. Isso só é necessário se você usar o PrivateLink.
- 2443: Suporta criptografia FIPS. Necessário apenas se o senhor ativar o perfil de segurançacompliance.
- 8443: para chamadas internas do plano de computação do Databricks para a API do plano de controle do Databricks.
- 8444: para registro do Unity Catalog e transmissão de dados de linhagem para o Databricks.
- 8445 a 8451: Possibilidade de extensão futura.
Ingresso (entrada): obrigatório para todos os workspaces (podem ser regras separadas ou combinadas em uma):
- Permitir TCP em todas as portas quando a origem do tráfego usar o mesmo grupo de segurança
- Permitir UDP em todas as portas quando a origem do tráfego usar o mesmo grupo de segurança
ACLs de rede em nível de sub-rede
As ACLs de rede em nível de sub-rede não devem negar a entrada ou a saída de nenhum tráfego. O Databricks valida as seguintes regras ao criar o workspace:
Egresso (saída):
- Autorizar todo o tráfego para CIDR da VPC do workspace para tráfego interno
- Autorizar o acesso de TCP a
0.0.0.0/0para estas portas:- 443: para a infraestrutura do Databricks, fontes de dados em nuvem e repositórios de bibliotecas
- 3306: para o metastore
- 6666: necessário somente se você usar o PrivateLink
- 8443: para chamadas internas do plano Databricks compute para o plano de controle Databricks API
- 8444: para Unity Catalog registro e transmissão de dados de linhagem para Databricks
- 8445 a 8451: Extensibilidade futura
- Autorizar o acesso de TCP a
Se você configurar as regras ALLOW ou DENY adicionais para tráfego de saída, defina as regras exigidas pelo Databricks com a prioridade mais alta (os números de regra mais baixos), para que tenham precedência.
Ingresso (entrada):
ALLOW ALL from Source 0.0.0.0/0. Esta regra deve ser priorizada.
O Databricks requer ACLs de rede em nível de sub-rede para adicionar 0.0.0.0/0 à sua lista de permissões. Para controlar o tráfego de saída, use um firewall de saída ou um dispositivo proxy para bloquear a maior parte do tráfego, mas permita os URLs aos quais o Databricks precisa se conectar. Consulte Configurar um firewall e acesso externo.
Suporte ao AWS PrivateLink
Se você pretende habilitar o AWS PrivateLink no workspace com esta VPC:
- Na VPC, certifique-se de habilitar as configurações Nomes de host de DNS e Resolução de DNS .
- Consulte o artigo Configurar conectividade privada clássica com Databricks para obter orientações sobre como criar uma sub-rede extra para o endpoint VPC (recomendado, mas não obrigatório) e como criar um grupo de segurança extra para o endpoint VPC .
Criar uma VPC
Para criar VPCs, é possível usar várias ferramentas:
- Console da AWS
- AWS CLI
- Terraform
- AWS Início rápido (criar um novo cliente-gerenciar VPC e um novo workspace)
Para usar o Console da AWS, as instruções básicas para criar e configurar uma VPC e objetos relacionados estão listadas abaixo. Para obter instruções completas, consulte a documentação da AWS.
Essas instruções básicas podem não se aplicar a todas as organizações. Seus requisitos de configuração podem ser diferentes. Esta seção não cobre todas as formas possíveis de configurar NATs, firewalls ou outras infraestruturas de rede. Se você tiver dúvidas, entre em contato com a equipe de contas da Databricks antes de prosseguir.
-
Acessar a página de VPCs na AWS.
-
Veja o seletor de regiões no canto superior direito. Se necessário, mude para a região de seu workspace.
-
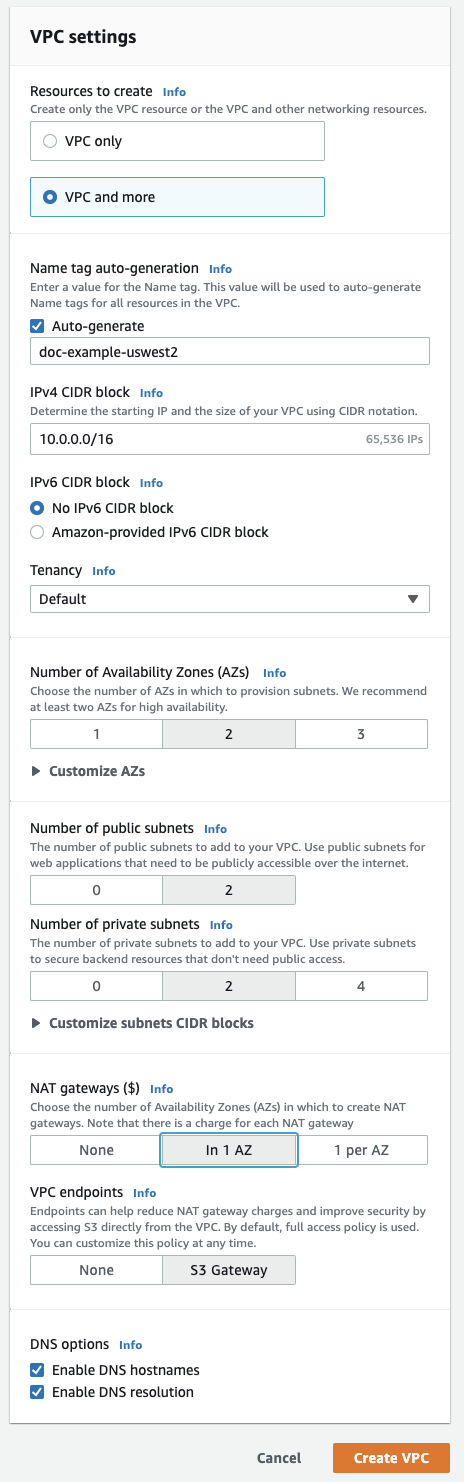
No canto superior direito, clique no botão laranja Criar VPC .
-
Clique em VPC e mais .
-
Na Geração automática de tag de nome, digite um nome para seu workspace. A Databricks recomenda incluir a região no nome.
-
É possível alterar o intervalo de endereços da VPC, se você desejar.
-
Para sub-redes públicas, clique em
2. Essas sub-redes não são usadas diretamente pelo site Databricks workspace, mas são necessárias para ativar os NATs neste editor. -
Para sub-redes privadas, clique em
2para o mínimo de sub-redes de workspaces. Você pode adicionar mais, se desejar.Seu workspace do Databricks precisa de pelo menos duas sub-redes privadas. Para redimensioná-las, clique em Personalizar blocos CIDR de sub-rede .
-
Para gateways NAT, clique em In 1 AZ .
-
Certifique-se de que os seguintes campos na parte inferior estejam ativados: Ativar hostnames de DNS e Ativar resolução de DNS .
-
Clique em Criar VPC .
-
Ao visualizar sua nova VPC, clique nos itens de navegação à esquerda para atualizar as configurações relacionadas na VPC. Para facilitar a localização de objetos relacionados, no campo Filtrar por VPC , selecione sua nova VPC.
-
Clique em Subnets e no que AWS chama de sub-redes privadas rótulo 1 e 2, que são as que o senhor usará para configurar suas sub-redes principais workspace. Modifique as sub-redes conforme especificado nos requisitos da VPC.
Se você criou uma sub-rede privada adicional para uso com o PrivateLink, configure a sub-rede privada 3 conforme especificado em Configurar conectividade privada clássica com o Databricks.
-
Clique em Grupos de segurança e modifique o grupo de segurança conforme especificado em Grupos de segurança.
Se for usar a conectividade back-end do PrivateLink, crie um grupo de segurança adicional com regras de entrada e saída, conforme especificado nos artigos do PrivateLink na seção Etapa 1: configurar objetos de rede do AWS.
-
Clique em ACLs de rede e modifique as ACLs de rede conforme especificado em ACLs de rede em nível de sub-rede.
-
Escolha se deseja executar as configurações opcionais especificadas posteriormente neste artigo.
Registre sua VPC com Databricks
Após criar sua VPC e configurar os objetos de rede necessários, você deve referenciar essa VPC— incluindo objetos de rede como VPCs, sub-redes e grupos de segurança — em uma configuração de rede para sua account Databricks . Você pode criar a configuração de rede usando o console account ou a APIda conta.
Se você planeja compartilhar uma VPC e sub-redes entre vários espaços de trabalho, certifique-se de dimensionar sua VPC e sub-redes para que sejam grandes o suficiente para escalar conforme o uso. Não é possível reutilizar um objeto de configuração de rede entre espaços de trabalho.
-
No consoleaccount, clique em Segurança .
-
Na seção Configurações de rede clássicas , clique em Adicionar configuração de rede .
-
No campo Nome da configuração de rede , digite um nome legível por humanos para a nova configuração de rede.
-
No campo ID da VPC , digite o ID da VPC.
-
No campo IDs de sub-rede , insira os IDs de pelo menos duas sub-redes da AWS na VPC. Para requisitos de configuração de rede, consulte Requisitos de VPC.
-
No campo IDs do grupo de segurança , insira o ID de pelo menos um grupo de segurança da AWS. Para requisitos de configuração de rede, consulte Grupos de segurança.
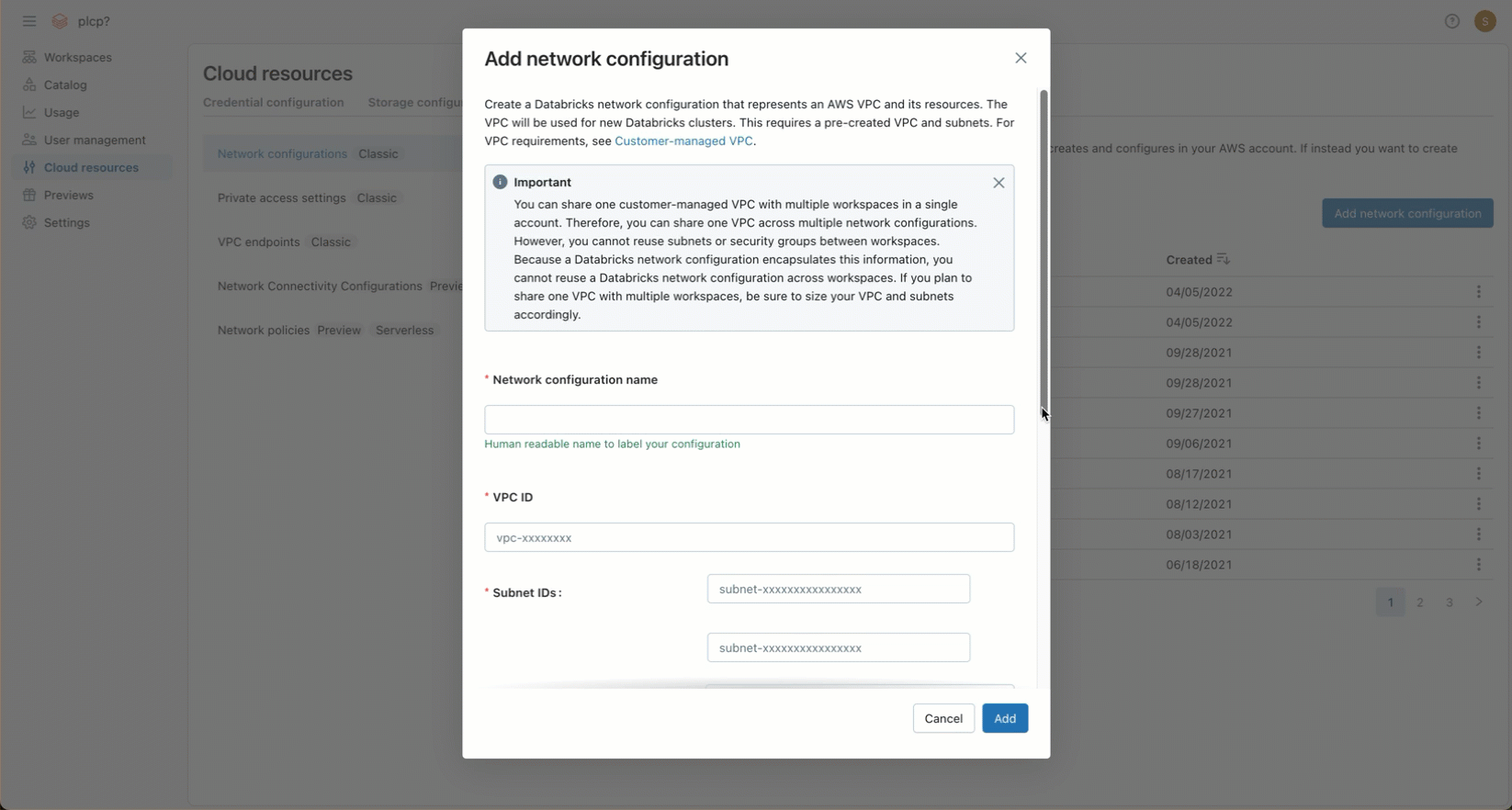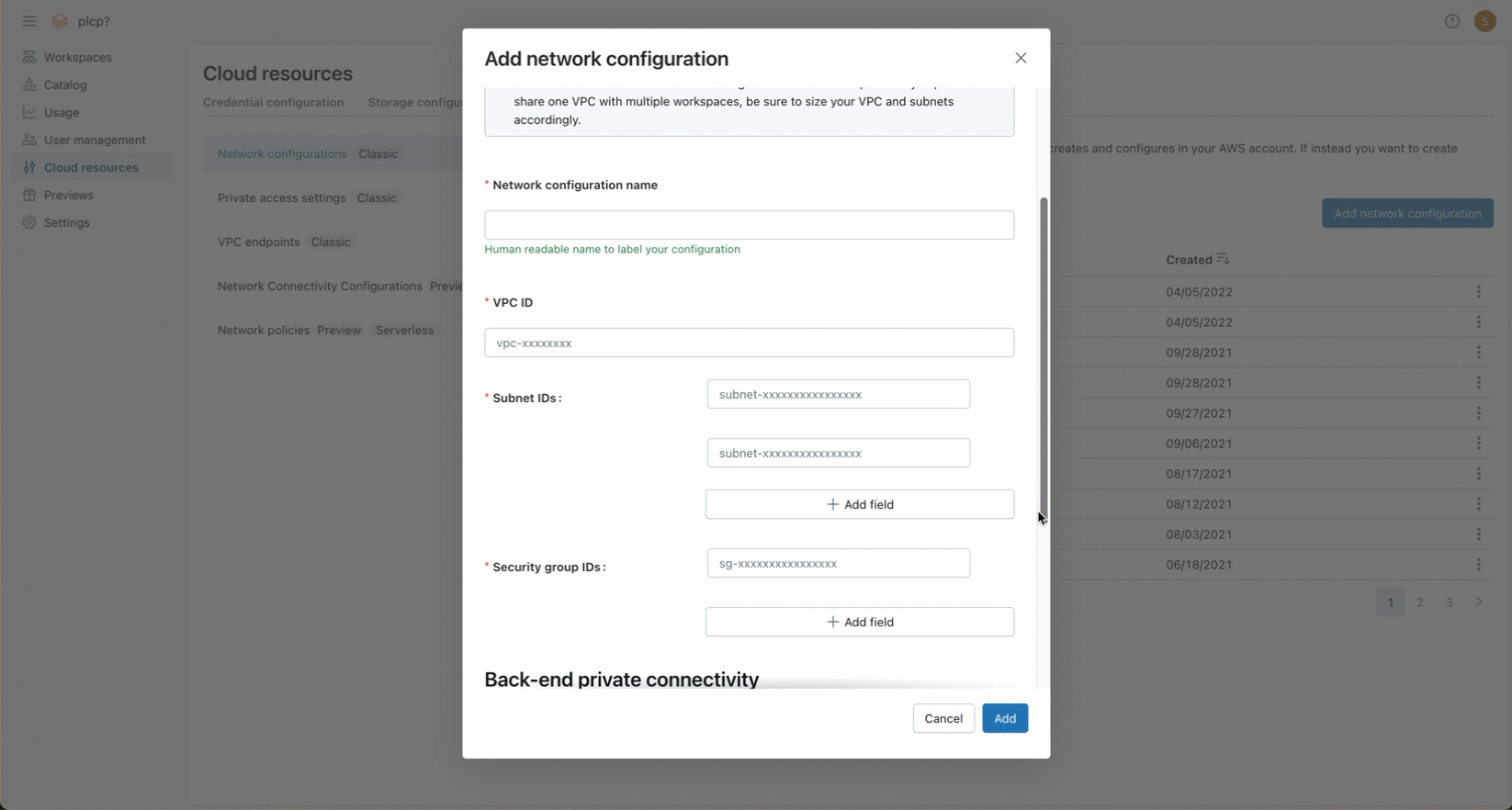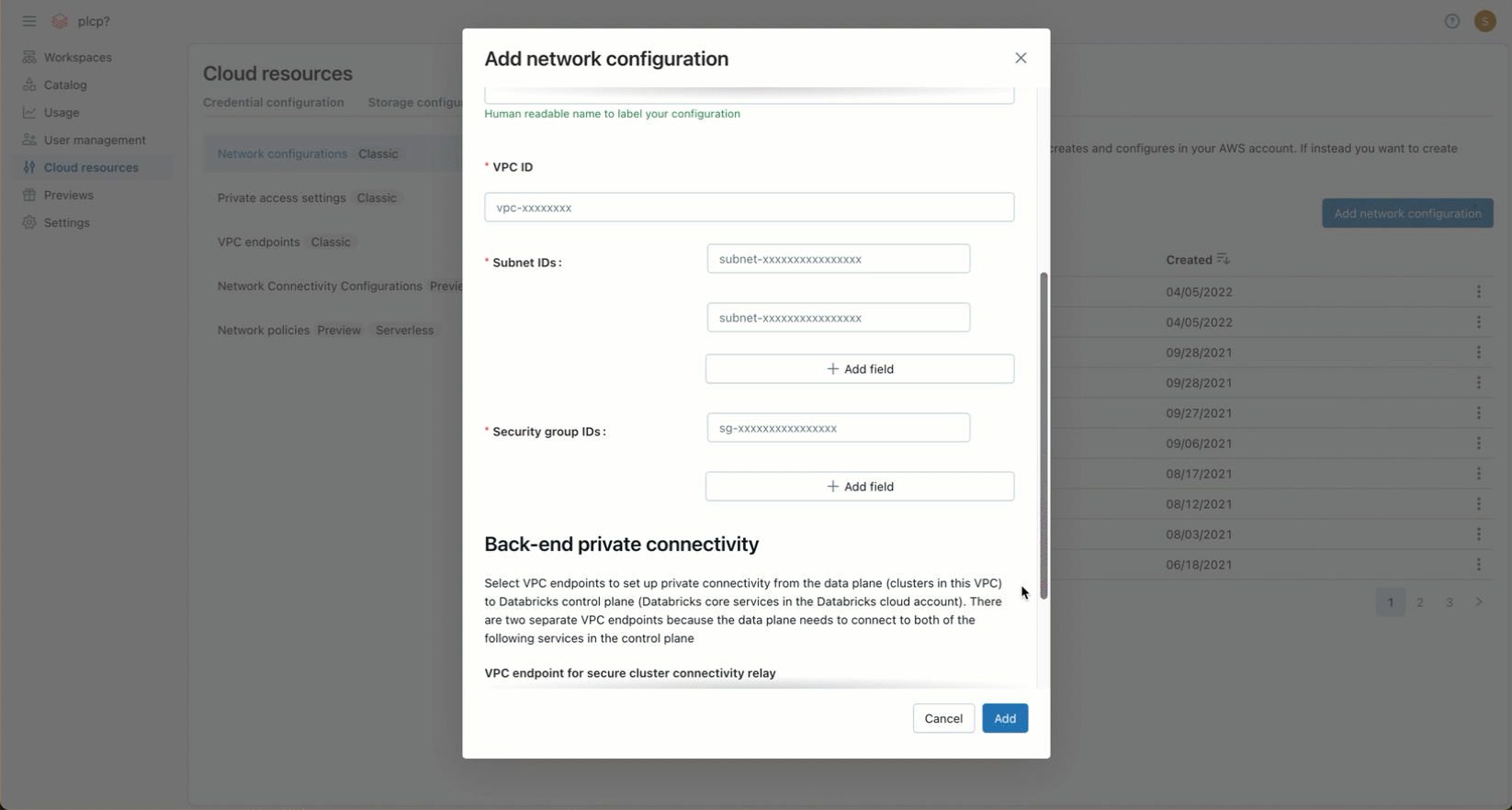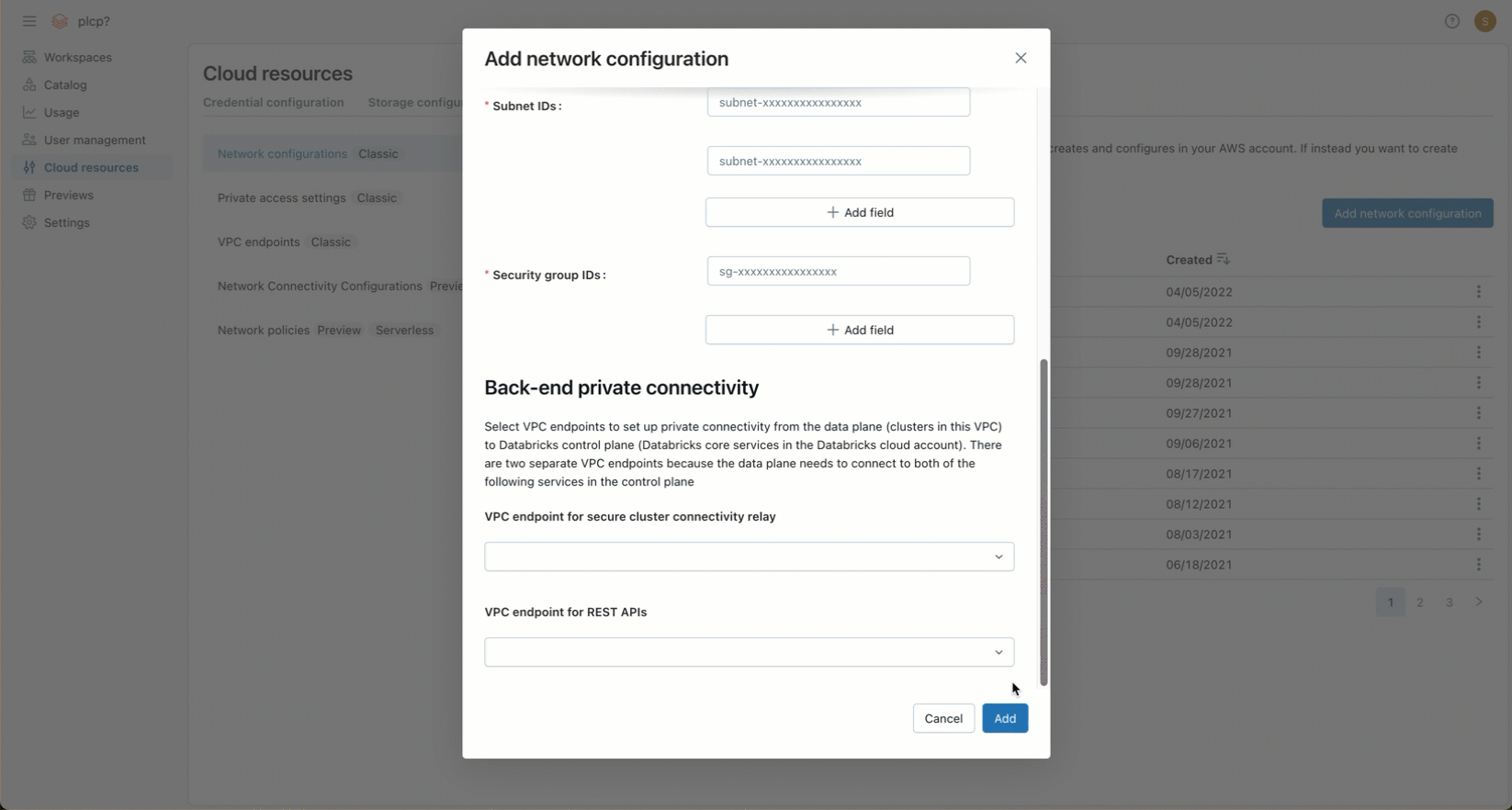
-
(Opcional) Para dar suporte à conectividade de back-end do AWS PrivateLink, você deve selecionar dois registros de endpoint de VPC nos campos sob o título Conectividade privada de back-end .
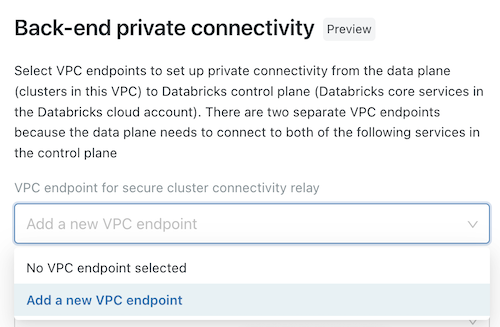
- Se você ainda não criou os dois endpoints VPC AWS específicos para a região do seu workspace , você deve fazê-lo agora. Veja o passo 2: Criar endpoint VPC. Você pode usar o Console da AWS ou diversas ferramentas de automação.
- Para cada campo, escolha registros endpoint VPC existentes ou escolha registrar um novo endpoint VPC para criar um imediatamente que faça referência ao endpoint VPC AWS que você já criou. Para obter orientações sobre os campos, consulte Gerenciar registros endpoint VPC.
-
Clique em Adicionar .
Atualizando CIDRs
Pode ser necessário, posteriormente, atualizar os CIDRs de sub-rede que se sobrepõem às sub-redes originais.
Para atualizar os CIDRs e outros objetos de workspaces:
-
Encerre todos os clusters em execução (e outros recursos de computação) em execução nas sub-redes que precisam ser atualizadas.
-
Utilizando o Console da AWS, exclua as sub-redes a serem atualizadas.
-
Recrie as sub-redes com intervalos de CIDR atualizados.
-
Atualize a associação da tabela de roteamento para as duas novas sub-redes. É possível reutilizar aquelas em cada zona de disponibilidade para as sub-redes existentes.
Se você pular essa etapa ou configurar incorretamente as tabelas de roteamento, o cluster poderá falhar ao ser iniciado.
-
Crie um novo objeto de configuração de rede com as novas sub-redes.
-
Atualize o workspace que usará esse objeto de configuração de rede recém-criado
(Recomendado) Configurar o ponto de extremidade regional
Se você usar um VPC gerenciado pelo cliente (opcional), o Databricks recomenda que configure seu VPC para usar apenas endpoints de VPC regionais para os serviços do AWS. O uso de endpoints de VPC regionais permite conexões mais diretas com os serviços da AWS e reduz o custo em comparação com os endpoints globais da AWS. Há quatro serviços do AWS que um workspace do Databricks com um customer-managed VPC deve acessar: STS, S3, Kinesis e RDS.
A conexão do seu VPC com o serviço RDS é necessária somente se o senhor usar o default Databricks legacy Hive metastore e não se aplica a Unity Catalog metastores. Embora não haja um VPC endpoint para RDS, em vez de usar o default Databricks legado Hive metastore, o senhor pode configurar seu próprio metastore externo. O senhor pode implementar um metastore externo com um Hive metastore ou AWS Glue.
Para os outros três serviços, é possível criar um gateway da VPC ou endpoints de interface de modo que o tráfego relevante na região dos clusters possa transitar pelo backbone seguro da AWS em vez de na rede pública:
-
S3 : Crie um gatewayVPC endpointque seja diretamente acessível a partir de suas sub-redes de clustering Databricks. Isso faz com que o tráfego workspace para todos os buckets S3 da região use a rota endpoint. Para acessar quaisquer buckets entre regiões, abra o acesso ao URL global do S3
s3.amazonaws.comem seu appliance de saída ou encaminhe0.0.0.0/0para um gateway de Internet da AWS.Para usar as montagensDBFS com o ponto de extremidade regional ativado:
- O senhor deve definir uma variável de ambiente na configuração de clustering para definir
AWS_REGION=<aws-region-code>. Por exemplo, se o site workspace for implantado na região de N. Virginia, definaAWS_REGION=us-east-1. Para aplicá-la em todos os clusters, use a política de cluster.
- O senhor deve definir uma variável de ambiente na configuração de clustering para definir
-
STS : crie um endpoint de interface da VPC diretamente acessível a partir das sub-redes de cluster do Databricks. É possível criar esse endpoint nas sub-redes de seu workspace. A Databricks recomenda que você use o mesmo grupo de segurança que foi criado para a VPC de seu espaço de trabalho. Essa configuração faz com que o tráfego do workspace para o STS use a rota do endpoint.
-
Kinesis : Crie uma interfaceVPC endpointdiretamente acessível a partir de suas sub-redes de clustering Databricks. O senhor pode criar esse endpoint em suas sub-redes workspace. Databricks Recomenda-se que o senhor use o mesmo grupo de segurança que foi criado para o seu workspace VPC. Essa configuração faz com que o tráfego do workspace para o Kinesis use a rota do endpoint. A única exceção a essa regra é o espaço de trabalho na região AWS
us-west-1porque a transmissão do Kinesis alvo nessa região é transversal à regiãous-west-2.
Configurar um firewall e acesso externo
Você deve usar um firewall de saída ou um dispositivo proxy para bloquear a maior parte do tráfego, mas autorize os URLs aos quais o Databricks precisa se conectar:
- Se o firewall ou dispositivo proxy estiver na mesma VPC que a VPC do workspace do Databricks, roteie o tráfego e o configure para permitir as seguintes conexões.
- Se o firewall ou dispositivo proxy estiver em outra VPC ou em uma rede on-premises, roteie
0.0.0.0/0para essa VPC ou rede primeiro e configure o dispositivo proxy para permitir as seguintes conexões.
A Databricks recomenda enfaticamente que você especifique destinos como nomes de domínio em sua infraestrutura de egresso, em vez de endereços IP.
Permita as seguintes conexões de saída. Para cada tipo de conexão, siga o link para obter endereços IP ou domínios para a região de seu workspace.
-
Aplicativo da web do Databricks : obrigatório.Também usado para chamadas de API REST para seu workspace.
-
Relé de conectividade segura de cluster (SCC) da Databricks : necessário para a conectividade segura do cluster.
-
URL global do AWS S3 : obrigatório pelo Databricks para acessar o bucket raiz do S3. Use
s3.amazonaws.com:443, independentemente da região. -
URL regional do AWS S3 : Opcional. Se o senhor usar buckets do S3 que possam estar em outras regiões, também deverá permitir o endpoint regional do S3. Embora a AWS forneça um domínio e uma porta para um endpoint regional (
s3.<region-name>.amazonaws.com:443), a Databricks recomenda que o senhor use um endpoint VPC para que esse tráfego passe pelo túnel privado no backbone da rede da AWS. Consulte (Recomendado) Configurar o ponto de extremidade regional. -
URL global do AWS STS : Obrigatório. Use o seguinte endereço e porta, independentemente da região:
sts.amazonaws.com:443 -
URL regional do AWS STS : Necessário devido à mudança esperada para o endpoint regional. Use um VPC endpoint. Consulte (Recomendado) Configurar o ponto de extremidade regional.
-
URL regional do AWS Kinesis : Necessário. O Kinesis endpoint é usado para capturar o logs necessário para gerenciar e monitorar o software. Para obter o URL de sua região, consulte Endereços do Kinesis.
-
URL regional do RDS do metastore da tabela (por região do plano de computação) : obrigatório se seu workspace do Databricks usar o Hive metastore.
O Hive metastore está sempre na mesma região que seu plano de computação, mas pode estar em uma região diferente do plano de controle.
Em vez de usar o default Hive metastore, o senhor pode optar por implementar sua própria instância de metastore de tabela e, nesse caso, é responsável pelo roteamento da rede.
-
Infraestrutura do plano de controle : obrigatório. Utilizado pelo Databricks para infraestrutura de standby do Databricks para aumentar a estabilidade dos serviços do Databricks.
Solucionar problemas de endpoint regional
Se você seguiu as instruções acima e os endpoints da VPC não funcionarem conforme o esperado, como por exemplo, se suas fontes de dados estiverem inacessíveis ou se o tráfego estiver ignorando os endpoints, você pode usar uma das duas abordagens para adicionar compatibilidade com os endpoints regionais para S3 e STS em vez de usar endpoints da VPC.
-
Adicione a variável de ambiente
AWS_REGIONna configuração de clustering e defina-a como sua região AWS. Para ativá-la para todos os clusters, use a política de cluster. Talvez o senhor já tenha configurado essa variável de ambiente para usar montagens DBFS. -
Adicione a configuração necessária do Apache Spark. Adote exatamente uma das seguintes abordagens:
- Em cada notebook de origem :
- Scala
- Python
%scala
spark.conf.set("fs.s3a.stsAssumeRole.stsEndpoint", "https://sts.<region>.amazonaws.com")
spark.conf.set("fs.s3a.endpoint", "https://s3.<region>.amazonaws.com")
%python
spark.conf.set("fs.s3a.stsAssumeRole.stsEndpoint", "https://sts.<region>.amazonaws.com")
spark.conf.set("fs.s3a.endpoint", "https://s3.<region>.amazonaws.com")
-
Ou então, na configuração do Apache Spark para o cluster *:
spark.hadoop.fs.s3a.endpoint https://s3.<region>.amazonaws.com
spark.hadoop.fs.s3a.stsAssumeRole.stsEndpoint https://sts.<region>.amazonaws.com
- Se você limitar o egresso do plano de computação clássico usando um firewall ou dispositivo de Internet, adicione esses endereços de endpoints regionais à sua lista de permissões.
Para definir esses valores para todos os clusters, configure os valores como parte de sua política de cluster.
(Opcional) Acesse S3 usando o perfil da instância
Para acessar as montagens do S3 usando o perfil da instância, defina as seguintes configurações do Spark:
- Em cada notebook de origem :
- Scala
- Python
%scala
spark.conf.set("fs.s3a.stsAssumeRole.stsEndpoint", "https://sts.<region>.amazonaws.com")
spark.conf.set("fs.s3a.endpoint", "https://s3.<region>.amazonaws.com")
%python
spark.conf.set("fs.s3a.stsAssumeRole.stsEndpoint", "https://sts.<region>.amazonaws.com")
spark.conf.set("fs.s3a.endpoint", "https://s3.<region>.amazonaws.com")
-
Ou na configuração do Apache Spark para o cluster :
spark.hadoop.fs.s3a.endpoint https://s3.<region>.amazonaws.com
spark.hadoop.fs.s3a.stsAssumeRole.stsEndpoint https://sts.<region>.amazonaws.com
Para definir esses valores para todos os clusters, configure os valores como parte de sua política de cluster.
Para o serviço S3, há limitações para aplicar configurações de endpoints regionais adicionais em nível de notebook ou de cluster. Especificamente, o acesso ao S3 entre regiões é bloqueado, mesmo que a URL global do S3 seja permitida em seu firewall de egresso ou proxy. Se sua implantação do Databricks exigir acesso S3 entre regiões, é importante que você não aplique a configuração do Spark em nível de notebook ou de cluster.
(Opcional) Restringir o acesso aos buckets S3
A maioria das leituras e gravações em S3 é autônoma no plano compute. No entanto, algumas operações de gerenciamento se originam do plano de controle, que é gerenciado por Databricks. Para limitar o acesso aos buckets do S3 a um conjunto específico de endereços IP de origem, crie uma política de bucket do S3. Na política de bucket, inclua os endereços IP na lista aws:SourceIp. Se o senhor usar um endpoint VPC, permita o acesso a ele adicionando-o ao aws:sourceVpce da política. A Databricks usa IDs de VPC para acessar buckets S3 na mesma região que o plano de controle da Databricks e IPs NAT para acessar buckets S3 em regiões diferentes do plano de controle.
Para obter mais informações sobre as políticas de bucket S3, consulte os exemplos de políticas de bucket na documentação Amazon S3 . Exemplos funcionais de políticas de bucket também estão incluídos neste tópico.
Requisitos para políticas de bucket
Sua política de buckets deve atender a esses requisitos para garantir que os clusters sejam iniciados corretamente e que você possa se conectar a eles:
-
O senhor deve permitir o acesso a partir do IP NAT do plano de controle e dos IDs de VPC da sua região.
-
Você deve permitir o acesso a partir da VPC do plano de computação, fazendo uma das coisas a seguir:
- (Recomendado) Configure um gateway VPC endpoint em seu cliente-gerenciar VPC e adicioná-lo ao
aws:sourceVpceà política de bucket, ou - Adicione o IP NAT do plano de computação à lista
aws:SourceIp.
- (Recomendado) Configure um gateway VPC endpoint em seu cliente-gerenciar VPC e adicioná-lo ao
-
Ao usar políticas de endpoints para o Amazon S3 , sua política deve incluir:
-
Para evitar a perda de conectividade de dentro de sua rede corporativa , a Databricks recomenda sempre permitir o acesso de pelo menos um endereço IP conhecido e confiável, como o IP público de sua VPN corporativa. Isso ocorre porque as condições Deny se aplicam até mesmo no Console da AWS.
Ao implantar um novo workspace com restrições de políticas de buckets do S3, você deve permitir o acesso ao NAT-IP do ambiente de controle para uma região us-west ; caso contrário, a implantação falhará. Depois que o workspace for implantado, você poderá remover as informações do us-west e atualizar o NAT-IP do painel de controle para refletir sua região.
IPs e buckets de armazenamento necessários
Para obter os endereços IP e os domínios necessários para configurar as S3 políticas de bucket e as VPC políticas de endpoint para restringir o acesso aos workspace S3 buckets do seu, consulte IPs de saída do Databricks plano de controle.
Exemplos de políticas de bucket
Esses exemplos usam texto de espaço reservado para indicar onde especificar os endereços IP recomendados e os intervalos de armazenamento necessários. Analise os requisitos para garantir que seu clustering comece corretamente e que o senhor possa se conectar a eles.
Restrinja o acesso ao plano de controle do Databricks, ao plano de computação e aos IPs confiáveis:
Essa política de buckets do S3 usa uma condição Deny para permitir seletivamente o acesso a partir do plano de controle, do gateway NAT e dos endereços IP da VPN corporativa que você especificar. Substitua o texto do espaço reservado por valores para seu ambiente. É possível adicionar qualquer número de endereços IP à política. Crie uma política por bucket do S3 que você deseja proteger.
Se o senhor usar o endpoint VPC, essa política não estará completa. Consulte Restringir o acesso ao plano de controle Databricks, ao endpoint VPC e aos IPs confiáveis.
{
"Sid": "IPDeny",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": ["arn:aws:s3:::<S3-BUCKET>", "arn:aws:s3:::<S3-BUCKET>/*"],
"Condition": {
"NotIpAddress": {
"aws:SourceIp": ["<CONTROL-PLANE-NAT-IP>", "<DATA-PLANE-NAT-IP>", "<CORPORATE-VPN-IP>"]
}
}
}
Restringir o acesso ao plano de controle do Databricks, aos endpoints da VPC e aos IPs confiáveis:
Se você usa um endpoint de VPC para acessar o S3, deverá adicionar uma segunda condição à política. Essa condição permite o acesso de seu endpoint de VPC e da ID de VPC adicionando-os à lista aws:sourceVpce.
Esse bucket permite seletivamente o acesso a partir de seu endpoint da VPC e dos endereços IP do plano de controle e da VPN corporativa que você especificar.
Ao usar o endpoint VPC, o senhor pode usar uma política de endpoint VPC em vez de uma política de bucket S3. Uma política de VPCE deve permitir o acesso ao seu bucket raiz S3 e ao artefato necessário, log, e ao bucket de conjunto de dados compartilhados para sua região. Para obter os endereços IP e os domínios de suas regiões, consulte Endereços IP e domínios para Databricks serviço e ativo.
Substitua o texto do espaço reservado por valores para seu ambiente.
{
"Sid": "IPDeny",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": ["arn:aws:s3:::<S3-BUCKET>", "arn:aws:s3:::<S3-BUCKET>/*"],
"Condition": {
"NotIpAddressIfExists": {
"aws:SourceIp": ["<CONTROL-PLANE-NAT-IP>", "<CORPORATE-VPN-IP>"]
},
"StringNotEqualsIfExists": {
"aws:sourceVpce": "<VPCE-ID>",
"aws:SourceVPC": "<VPC-ID>"
}
}
}