Prepare seus dados para compliance GDPR
O Regulamento Geral de Proteção de Dados (GDPR) (GDPR) e a Lei de Privacidade do Consumidor da Califórnia (CCPA) são regulamentações de privacidade e segurança de dados que exigem que as empresas excluam de forma permanente e completa todas as informações de identificação pessoal (PII) coletadas sobre um cliente mediante solicitação explícita. Também conhecidas como “direito de ser esquecido” (RTBF) ou “direito à exclusão de dados”, as solicitações de exclusão devem ser executadas durante um período específico (por exemplo, dentro de um mês civil).
Este artigo orienta o senhor sobre como implementar o RTBF em dados armazenados em Databricks. O exemplo incluído neste artigo modela o conjunto de dados de uma empresa de comércio eletrônico e mostra como excluir dados em tabelas de origem e propagar essas alterações para tabelas posteriores.
Plano para implementar o “direito de ser esquecido”
O diagrama a seguir ilustra como implementar o “direito de ser esquecido”.
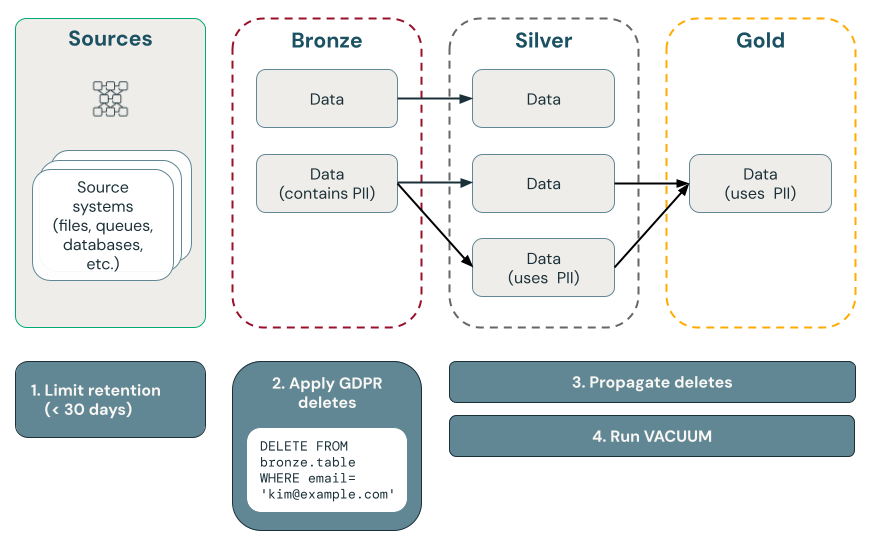
O ponto exclui com Delta Lake
Delta Lake acelera a exclusão de pontos em grandes data lake com transações ACID, permitindo que o senhor localize e remova informações de identificação pessoal (PII) em resposta a solicitações do consumidor GDPR ou da CCPA.
Delta Lake mantém o histórico da tabela e o disponibiliza para consultas e reversões em um ponto específico no tempo. A função vacuum remove arquivos de dados que não são mais referenciados por uma tabela Delta e que são mais antigos que um limite de retenção especificado, excluindo os dados permanentemente. Para saber mais sobre padrões e recomendações, consulte Trabalhar com a história da tabela.
Garanta que os dados sejam excluídos ao usar vetores de exclusão
Nas tabelas com vetores de exclusão ativados, após excluir os registros, o senhor também deve executar REORG TABLE ... APPLY (PURGE) para excluir permanentemente os registros subjacentes. Isso inclui as tabelas Delta Lake, a visualização materializada e as tabelas de transmissão. Consulte Aplicar alterações nos arquivos de dados do Parquet.
Excluir dados em fontes upstream
O GDPR e a CCPA se aplicam a todos os dados, inclusive dados em fontes fora do Delta Lake, como Kafka, arquivos e bancos de dados. Além de excluir dados no Databricks, o senhor também deve se lembrar de excluir dados em fontes upstream, como filas e armazenamento em nuvem.
Antes de implementar a exclusão de dados no fluxo de trabalho, você pode precisar exportar os dados workspace para fins compliance ou backup. Consulte Exportar dados workspace.
A exclusão completa é preferível à ofuscação
Você precisa escolher entre excluir dados e ofuscá-los. A ofuscação pode ser implementada usando pseudonimização, mascaramento de dados, etc. No entanto, a opção mais segura é a exclusão completa porque, na prática, eliminar o risco de reidentificação geralmente exige a exclusão completa dos dados de PII.
Excluir dados na camada bronze e, em seguida, propagar as exclusões para as camadas prata e ouro
Recomendamos que você inicie compliance GDPR e o CCPA excluindo primeiro os dados na camada bronze, por meio de uma tarefa agendada que consulta uma tabela de solicitações de exclusão. Após a exclusão dos dados da camada de bronze, as alterações podem ser propagadas para as camadas de prata e ouro.
Mantenha tabelas regularmente para remover dados de arquivos históricos
Por default, Delta Lake retém o histórico da tabela, incluindo registros excluídos, por 30 dias, e o disponibiliza para viagens no tempo e reversões. Mas mesmo que as versões anteriores dos dados sejam removidas, os dados ainda são mantidos no armazenamento cloud . Portanto, você deve realizar a manutenção regular do conjunto de dados para remover versões anteriores dos dados. A forma recomendada é a otimização preditiva para tabelas de gerenciamento Unity Catalog, que mantém de forma inteligente tanto as tabelas de transmissão quanto a visão materializada.
- Para tabelas gerenciadas por otimização preditiva, o pipeline declarativo LakeFlow Spark mantém de forma inteligente tanto as tabelas de transmissão quanto a visão materializada, com base em padrões de uso.
- Para tabelas sem otimização preditiva habilitada, o pipeline declarativo LakeFlow Spark executa automaticamente tarefas de manutenção em até 24 horas após a atualização das tabelas de transmissão e da visão materializada.
Se você não estiver usando otimização preditiva ou pipeline declarativo LakeFlow Spark , você deve executar um comando VACUUM nas tabelas Delta para remover permanentemente as versões anteriores dos dados. Por default, isso reduzirá a capacidade de "viagem do tempo" para 7 dias, que é uma configuração configurável, e também removerá as versões históricas dos dados em questão do armazenamento cloud .
Exclua dados de PII da camada de bronze
Dependendo do design do seu site lakehouse, talvez seja possível cortar o vínculo entre os dados de usuário PII e não PII. Por exemplo, se o senhor estiver usando um key não natural, como user_id, em vez de um key natural, como email, poderá excluir os dados de PII, deixando os dados não PII no lugar.
O restante deste artigo lida com o RTBF excluindo completamente os registros de usuários de todas as tabelas bronze. O senhor pode excluir dados executando um comando DELETE, conforme mostrado no código a seguir:
spark.sql("DELETE FROM bronze.users WHERE user_id = 5")
Ao excluir um grande número de registros de uma só vez, recomendamos o uso do comando MERGE. O código abaixo pressupõe que o senhor tenha uma tabela de controle chamada gdpr_control_table que contém uma coluna user_id. Você insere um registro nessa tabela para cada usuário que solicitou o “direito de ser esquecido” nessa tabela.
O comando MERGE especifica a condição para a correspondência de linhas. Neste exemplo, ele combina registros de target_table com registros em gdpr_control_table com base no user_id. Se houver uma correspondência (por exemplo, user_id em target_table e gdpr_control_table), a linha em target_table será excluída. Depois que esse comando MERGE for bem-sucedido, atualize a tabela de controle para confirmar que a solicitação foi processada.
spark.sql("""
MERGE INTO target
USING (
SELECT user_id
FROM gdpr_control_table
) AS source
ON target.user_id = source.user_id
WHEN MATCHED THEN DELETE
""")
Propagar mudanças das camadas de bronze para prata e ouro
Depois que os dados forem excluídos na camada bronze, o senhor deverá propagar as alterações para as tabelas nas camadas prata e ouro.
Visualização materializada: Manipular automaticamente as exclusões
A visualização materializada trata automaticamente as exclusões em fontes. Portanto, o senhor não precisa fazer nada de especial para garantir que um site materializado view não contenha dados que tenham sido excluídos de uma fonte. O senhor deve refresh a materialized view e executar a manutenção para garantir que as exclusões sejam completamente processadas.
Um view materializado sempre retorna o resultado correto porque usa computação incremental se for mais barato do que a recomputação completa, mas nunca à custa da correção. Em outras palavras, a exclusão de dados de uma fonte pode fazer com que um view materializado seja totalmente recomputado.
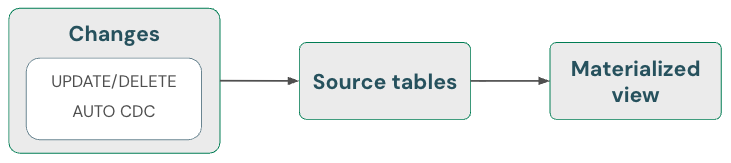
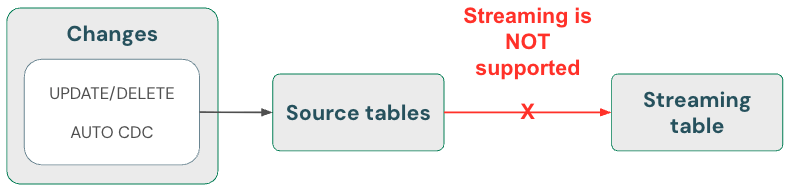
tabelas de transmissão: Excluir dados e ler a fonte de transmissão usando skipChangeCommits
As tabelas oferecem processamento de dados somente para anexação quando são oferecidas a partir de fontes de tabela Delta . Quaisquer outras operações, como atualizar ou excluir um registro de uma fonte de transmissão, não são suportadas e interrompem a transmissão.
Para uma implementação de transmissão mais robusta, utilize os feeds de alterações das tabelas Delta e lide com as atualizações e exclusões no seu código de processamento. Veja Opção 1: transmissão de um feed de captura de dados de alterações (CDC) (CDC).
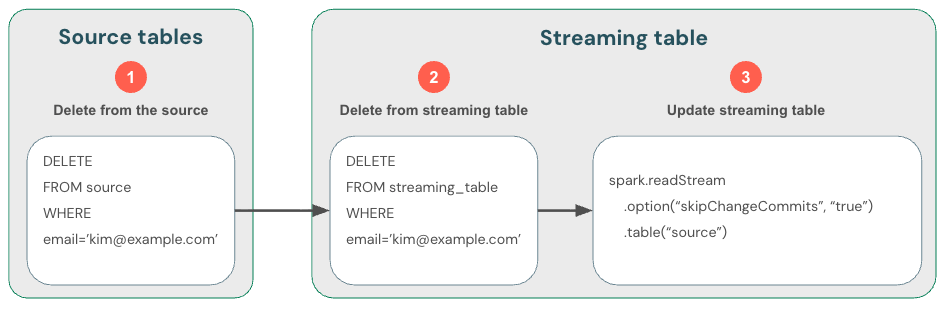
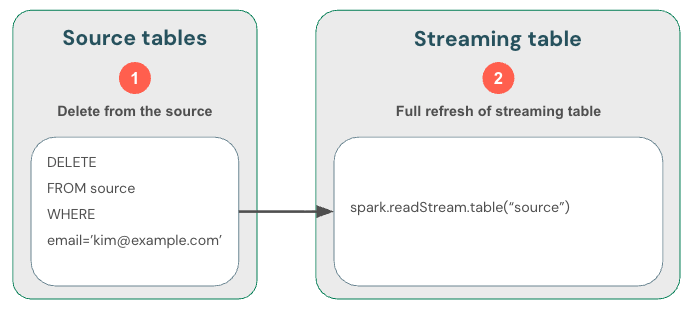
Como a transmissão de tabelas Delta lida apenas com dados novos, você deve gerenciar as alterações nos dados por conta própria. O método recomendado é: (1) excluir dados nas tabelas Delta de origem usando DML, (2) excluir dados da tabela de transmissão usando DML e, em seguida, (3) atualizar a leitura de transmissão para usar skipChangeCommits. Essa flag indica que a tabela de transmissão deve ignorar tudo que não seja uma inserção, como atualizações ou exclusões.
Alternativamente, você pode (1) excluir dados da fonte e, em seguida, (2) refresh completamente a tabela de transmissão. Ao refresh completamente uma tabela de transmissão, o estado de transmissão da tabela é limpo e todos os dados são reprocessados. Qualquer fonte de dados upstream que tenha ultrapassado seu período de retenção (por exemplo, um tópico Kafka que exclui dados após 7 dias) não será processada novamente, o que pode causar perda de dados. Recomendamos esta opção para tabelas de transmissão apenas no cenário em que os dados históricos estejam disponíveis e o seu processamento posterior não seja dispendioso.
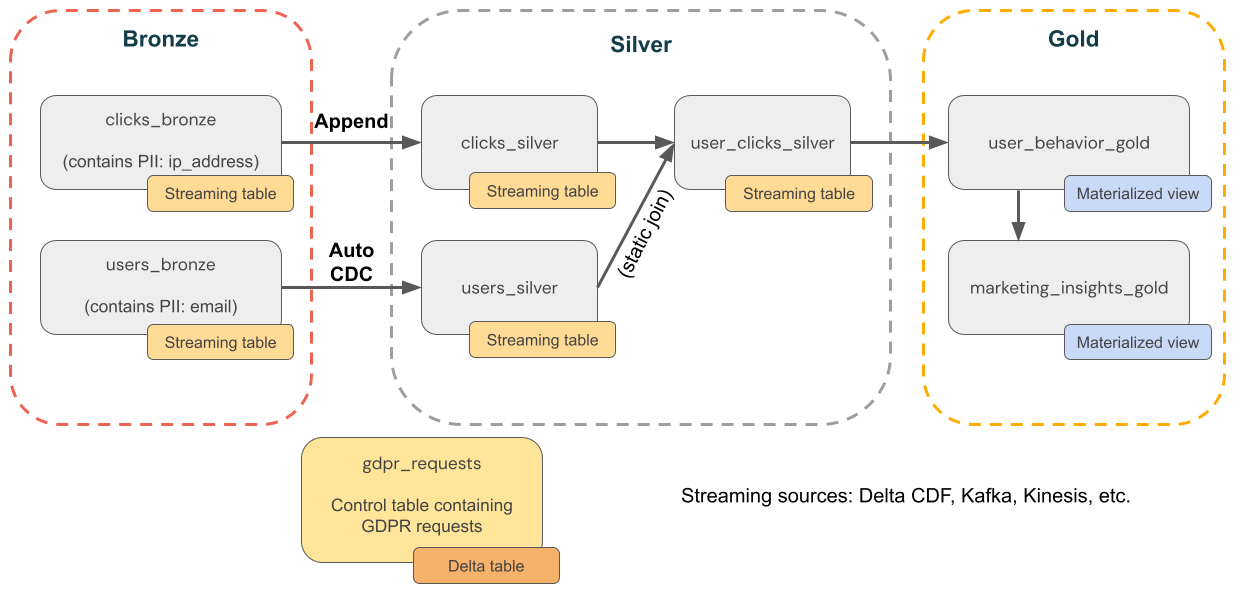
Exemplo: GDPR e CCPA compliance para uma empresa de comércio eletrônico
O diagrama a seguir mostra uma arquitetura de medalhão para uma empresa de comércio eletrônico em que GDPR & CCPA compliance precisa ser implementado. Mesmo que os dados de um usuário sejam excluídos, talvez você queira contar suas atividades em agregações posteriores.
-
Tabelas de origem
source_users- Uma tabela de origem de usuários do Transparency (criada aqui, para fins de exemplo). Os ambientes de produção normalmente utilizam Kafka, Kinesis ou plataformas de transmissão semelhantes.source_clicks- Uma tabela de origem de cliques do Transparency (criada aqui, para fins de exemplo). Os ambientes de produção normalmente utilizam Kafka, Kinesis ou plataformas de transmissão semelhantes.
-
Tabela de controle
gdpr_requests- Tabela de controle contendo IDs de usuários sujeitos ao “direito ao esquecimento”. Quando um usuário solicitar a remoção, adicione-o aqui.
-
Camada de bronze
users_bronze- Dimensões do usuário. Contém PII (por exemplo, endereço email ).clicks_bronze- Clique em eventos. Contém PII (por exemplo, endereço IP).
-
Camada de prata
clicks_silver- Dados de cliques limpos e padronizados.users_silver- Dados do usuário limpos e padronizados.user_clicks_silver- junteclicks_silver(transmissão) com um Snapshot deusers_silver.
-
Camada de ouro
user_behavior_gold- Métricas agregadas de comportamento do usuário.marketing_insights_gold- Segmentação de usuários para percepções de mercado.
Etapa 1: preencher tabelas com dados de amostra
O código a seguir cria essas duas tabelas para este exemplo e as preenche com dados de amostra:
source_userscontém dados dimensionais sobre os usuários. Essa tabela contém uma coluna de PII chamadaemail.source_clickscontém dados de eventos sobre atividades realizadas pelos usuários. Ele contém uma coluna de PII chamadaip_address.
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, MapType, DateType
catalog = "users"
schema = "name"
# Create table containing sample users
users_schema = StructType([
StructField('user_id', IntegerType(), False),
StructField('username', StringType(), True),
StructField('email', StringType(), True),
StructField('registration_date', StringType(), True),
StructField('user_preferences', MapType(StringType(), StringType()), True)
])
users_data = [
(1, 'alice', 'alice@example.com', '2021-01-01', {'theme': 'dark', 'language': 'en'}),
(2, 'bob', 'bob@example.com', '2021-02-15', {'theme': 'light', 'language': 'fr'}),
(3, 'charlie', 'charlie@example.com', '2021-03-10', {'theme': 'dark', 'language': 'es'}),
(4, 'david', 'david@example.com', '2021-04-20', {'theme': 'light', 'language': 'de'}),
(5, 'eve', 'eve@example.com', '2021-05-25', {'theme': 'dark', 'language': 'it'})
]
users_df = spark.createDataFrame(users_data, schema=users_schema)
users_df.write.mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_users")
# Create table containing clickstream (i.e. user activities)
from pyspark.sql.types import TimestampType
clicks_schema = StructType([
StructField('click_id', IntegerType(), False),
StructField('user_id', IntegerType(), True),
StructField('url_clicked', StringType(), True),
StructField('click_timestamp', StringType(), True),
StructField('device_type', StringType(), True),
StructField('ip_address', StringType(), True)
])
clicks_data = [
(1001, 1, 'https://example.com/home', '2021-06-01T12:00:00', 'mobile', '192.168.1.1'),
(1002, 1, 'https://example.com/about', '2021-06-01T12:05:00', 'desktop', '192.168.1.1'),
(1003, 2, 'https://example.com/contact', '2021-06-02T14:00:00', 'tablet', '192.168.1.2'),
(1004, 3, 'https://example.com/products', '2021-06-03T16:30:00', 'mobile', '192.168.1.3'),
(1005, 4, 'https://example.com/services', '2021-06-04T10:15:00', 'desktop', '192.168.1.4'),
(1006, 5, 'https://example.com/blog', '2021-06-05T09:45:00', 'tablet', '192.168.1.5')
]
clicks_df = spark.createDataFrame(clicks_data, schema=clicks_schema)
clicks_df.write.format("delta").mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_clicks")
Etapa 2: Criar um pipeline que processe dados de PII
O código a seguir cria camadas de bronze, prata e ouro da arquitetura do medalhão mostrada acima.
from pyspark import pipelines as dp
from pyspark.sql.functions import col, concat_ws, count, countDistinct, avg, when, expr
catalog = "users"
schema = "name"
# ----------------------------
# Bronze Layer - Raw Data Ingestion
# ----------------------------
@dp.table(
name=f"{catalog}.{schema}.users_bronze",
comment='Raw users data loaded from source'
)
def users_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_users")
)
@dp.table(
name=f"{catalog}.{schema}.clicks_bronze",
comment='Raw clicks data loaded from source'
)
def clicks_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_clicks")
)
# ----------------------------
# Silver Layer - Data Cleaning and Enrichment
# ----------------------------
@dp.create_streaming_table(
name=f"{catalog}.{schema}.users_silver",
comment='Cleaned and standardized users data'
)
@dp.view
@dp.expect_or_drop('valid_email', "email IS NOT NULL")
def users_bronze_view():
return (
spark.readStream
.table(f"{catalog}.{schema}.users_bronze")
.withColumn('registration_date', col('registration_date').cast('timestamp'))
.dropDuplicates(['user_id', 'registration_date'])
.select('user_id', 'username', 'email', 'registration_date', 'user_preferences')
)
@dp.create_auto_cdc_flow(
target=f"{catalog}.{schema}.users_silver",
source="users_bronze_view",
keys=["user_id"],
sequence_by="registration_date",
)
@dp.table(
name=f"{catalog}.{schema}.clicks_silver",
comment='Cleaned and standardized clicks data'
)
@dp.expect_or_drop('valid_click_timestamp', "click_timestamp IS NOT NULL")
def clicks_silver():
return (
spark.readStream
.table(f"{catalog}.{schema}.clicks_bronze")
.withColumn('click_timestamp', col('click_timestamp').cast('timestamp'))
.withWatermark('click_timestamp', '10 minutes')
.dropDuplicates(['click_id'])
.select('click_id', 'user_id', 'url_clicked', 'click_timestamp', 'device_type', 'ip_address')
)
@dp.table(
name=f"{catalog}.{schema}.user_clicks_silver",
comment='Joined users and clicks data on user_id'
)
def user_clicks_silver():
# Read users_silver as a static DataFrame - each refresh
# will use a snapshot of the users_silver table.
users = spark.read.table(f"{catalog}.{schema}.users_silver")
# Read clicks_silver as a streaming DataFrame.
clicks = spark.readStream \
.table('clicks_silver')
# Perform the join - join of a static dataset with a
# streaming dataset creates a streaming table.
joined_df = clicks.join(users, on='user_id', how='inner')
return joined_df
# ----------------------------
# Gold Layer - Aggregated and Business-Level Data
# ----------------------------
@dp.materialized_view(
name=f"{catalog}.{schema}.user_behavior_gold",
comment='Aggregated user behavior metrics'
)
def user_behavior_gold():
df = spark.read.table(f"{catalog}.{schema}.user_clicks_silver")
return (
df.groupBy('user_id')
.agg(
count('click_id').alias('total_clicks'),
countDistinct('url_clicked').alias('unique_urls')
)
)
@dp.materialized_view(
name=f"{catalog}.{schema}.marketing_insights_gold",
comment='User segments for marketing insights'
)
def marketing_insights_gold():
df = spark.read.table(f"{catalog}.{schema}.user_behavior_gold")
return (
df.withColumn(
'engagement_segment',
when(col('total_clicks') >= 100, 'High Engagement')
.when((col('total_clicks') >= 50) & (col('total_clicks') < 100), 'Medium Engagement')
.otherwise('Low Engagement')
)
)
Etapa 3: excluir dados nas tabelas de origem
Neste passo, você exclui os dados de todas as tabelas onde são encontradas informações pessoais identificáveis (PII). A função a seguir remove todas as instâncias de informações pessoais identificáveis (PII) de um usuário das tabelas que contêm PII.
catalog = "users"
schema = "name"
def apply_gdpr_delete(user_id):
tables_with_pii = ["clicks_bronze", "users_bronze", "clicks_silver", "users_silver", "user_clicks_silver"]
for table in tables_with_pii:
print(f"Deleting user_id {user_id} from table {table}")
spark.sql(f"""
DELETE FROM {catalog}.{schema}.{table}
WHERE user_id = {user_id}
""")
Etapa 4: Adicionar skipChangeCommits às definições das tabelas de transmissão afetadas
Neste passo, você deve instruir o pipeline declarativo LakeFlow Spark a ignorar as linhas que não são de acréscimo. Adicione a opção skipChangeCommits aos seguintes métodos. Você não precisa atualizar as definições da visão materializada, pois elas lidarão automaticamente com atualizações e exclusões.
users_bronzeusers_silverclicks_bronzeclicks_silveruser_clicks_silver
O código a seguir mostra como atualizar o método users_bronze:
def users_bronze():
return (
spark.readStream.option('skipChangeCommits', 'true').table(f"{catalog}.{schema}.source_users")
)
Quando o senhor executar o site pipeline novamente, ele será atualizado com sucesso.