RStudio na Databricks
O senhor pode usar o RStudioum popular ambiente de desenvolvimento integrado (IDE) para R, para se conectar a Databricks compute recurso no espaço de trabalho Databricks. Use o RStudio Desktop para se conectar a um Databricks cluster ou a um SQL warehouse a partir de sua máquina de desenvolvimento local.
O senhor também pode usar o navegador da Web para entrar no site Databricks workspace e, em seguida, conectar-se a um site Databricks cluster que tenha o servidorRStudio instalado, dentro desse site workspace.
Conecte-se usando o RStudio Desktop
Use oRStudio Desktop para se conectar a um clustering Databricks remoto ou SQL warehouse a partir de sua máquina de desenvolvimento local. Para se conectar nesse cenário, use uma conexão ODBC e chame as funções do pacote ODBC para o R, que são descritas nesta seção.
O senhor não pode usar pacotes como SparkR ou Sparklyr neste cenário do RStudio Desktop, a menos que o senhor também use o Databricks Connect.
Para configurar o RStudio Desktop em seu computador de desenvolvimento local:
- Faça o download e instale o R 3.3.0 ou superior.
- Faça o download e instale o RStudio Desktop.
- RStudio Desktop.
(Opcional) Para criar um projeto do RStudio:
- RStudio Desktop.
- Clique em Arquivo > Novo projeto .
- Selecione Novo diretório > Novo projeto .
- Escolha um novo diretório para o projeto e clique em Criar projeto .
Para criar um script R:
- Com o projeto aberto, clique em Arquivo > Novo Arquivo > R Script .
- Clique em Arquivo > Salvar como .
- Dê um nome ao arquivo e clique em Salvar .
Para se conectar ao clustering remoto Databricks ou SQL warehouse por meio de ODBC para R:
-
Obtenha o nome do host do servidor , a porta e os valores do caminho HTTP para seu cluster remoto ou SQL warehouse. Para um clustering, esses valores estão em JDBC/ODBC tab de opções avançadas . Para um SQL warehouse, esses valores estão nos detalhes da conexão tab.
-
Obtenha um Databricks tokens de acesso pessoal.
Como prática recomendada de segurança ao se autenticar com ferramentas, sistemas, scripts e aplicativos automatizados, a Databricks recomenda que você use tokens OAuth.
Se o senhor usar a autenticação de tokens de acesso pessoal, a Databricks recomenda usar o acesso pessoal tokens pertencente à entidade de serviço em vez de usuários workspace. Para criar tokens o site para uma entidade de serviço, consulte gerenciar tokens para uma entidade de serviço.
-
Instale e configure o driver ODBC da Databricks para Windows, macOS ou Linux, com base no sistema operacional de sua máquina local.
-
Configure um ODBC fonte de dados Name (DSN) para seu clustering remoto ou SQL warehouse para WindowsO senhor pode configurar um DSN para o cluster remoto ou para macOS, macOS ou Linux, com base no sistema operacional de sua máquina local.
-
No console RStudio (view > Move Focus to Console ), instale o pacote ODBC e o pacote DBI de CRAN:
Rrequire(devtools)
install_version(
package = "odbc",
repos = "http://cran.us.r-project.org"
)
install_version(
package = "DBI",
repos = "http://cran.us.r-project.org"
) -
De volta ao seu script R (veja > Move Focus to Source ), carregue os pacotes
odbceDBIinstalados:Rlibrary(odbc)
library(DBI) -
Chame a versão ODBC da função dbConnect no pacote
DBI, especificando o driverodbcno pacoteodbc, bem como o DSN ODBC que o senhor criou, por exemplo, um DSN ODBC deDatabricks.Rconn = dbConnect(
drv = odbc(),
dsn = "Databricks"
) -
Chame uma operação por meio do ODBC DSN, por exemplo, uma instrução
SELECTpor meio da função dbGetQuery no pacoteDBI, especificando o nome da variável de conexão e a própria instruçãoSELECT, por exemplo, de uma tabela chamadadiamondsem um esquema (banco de dados) chamadodefault:Rprint(dbGetQuery(conn, "SELECT * FROM default.diamonds LIMIT 2"))
O script R completo é o seguinte:
library(odbc)
library(DBI)
conn = dbConnect(
drv = odbc(),
dsn = "Databricks"
)
print(dbGetQuery(conn, "SELECT * FROM default.diamonds LIMIT 2"))
Para executar o script, na fonte view, clique em Source . Os resultados do script R anterior são os seguintes:
_c0 carat cut color clarity depth table price x y z
1 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
Conecte-se a um RStudio Server hospedado pela Databricks
Databricks-hosted RStudio Server está obsoleto e só está disponível nas versões 15.4 e abaixo do Databricks Runtime.
Use o navegador da Web para fazer login no site Databricks workspace e, em seguida, conecte-se a um site Databricks compute que tenha o servidor RStudio instalado nesse site workspace.
Para obter mais informações, consulte Conectar-se a Databricksum RStudio servidor -hosted
Arquitetura de integração do RStudio
Quando o senhor usa o RStudio Server em Databricks, o RStudio Server Daemon é executado no nó do driver de um cluster Databricks. A interface de usuário da Web RStudio é proxy por meio do aplicativo da Web Databricks, o que significa que o senhor não precisa fazer nenhuma alteração na configuração da rede de clustering. Este diagrama demonstra a arquitetura do componente de integração do RStudio.
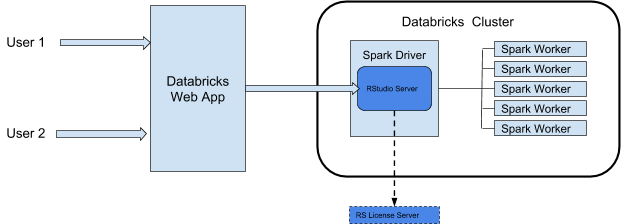
Databricks faz proxy do serviço da Web RStudio a partir da porta 8787 no driver Spark do clustering. Esse proxy da Web foi projetado para ser usado somente com o RStudio. Se o senhor lançar outro serviço da Web na porta 8787, poderá expor seus usuários a possíveis explorações de segurança. Databricks não se responsabiliza por nenhum problema resultante da instalação de um software sem suporte em um cluster.
Requisitos
-
O clustering deve ser um clusters todo-propósito.
-
O senhor deve ter permissão CAN ATTACH TO para esse clustering. O administrador do clustering pode conceder essa permissão ao senhor. Consulte permissões de computação.
-
O clustering não deve ter o controle de acesso da tabela, o encerramento automático ou a passagem de credenciais ativados.
-
O clustering não deve usar o modo de acesso Standard.
-
O clustering não deve ter a configuração Spark
spark.databricks.pyspark.enableProcessIsolationdefinida comotrue. -
O senhor deve ter uma licença Pro flutuante do RStudio Server para usar a edição Pro.
Embora o clustering possa usar um modo de acesso compatível com Unity Catalog, o senhor não pode usar o servidor RStudio desse clustering para acessar dados em Unity Catalog.
Obter começar: RStudio Server OS Edition
RStudio O Server código aberto Edition é pré-instalado no Databricks clustering que usa o Databricks Runtime para Machine Learning (Databricks Runtime ML).
Para abrir o RStudio Server OS Edition em um clustering, faça o seguinte:
-
Abra a página de detalhes do clustering.
-
Inicie o clustering e clique em Apps tab:
-
Em Apps tab, clique no botão Set up RStudio (Configurar ). Isso gera uma senha de uso único para você. Clique no link mostrar para exibi-lo e copiar a senha.
-
Clique no link Open RStudio para abrir a interface do usuário em um novo tab. Digite seu nome de usuário e senha no formulário de login e faça login.
-
Na interface do usuário RStudio, o senhor pode importar o pacote
SparkRe configurar uma sessãoSparkRpara iniciar o Spark Job em seu cluster.Rlibrary(SparkR)
sparkR.session()
# Query the first two rows of a table named "diamonds" in a
# schema (database) named "default" and display the query result.
df <- SparkR::sql("SELECT * FROM default.diamonds LIMIT 2")
showDF(df)
-
O senhor também pode anexar o Sparklyr pacote e configurar uma conexão Spark.
Rlibrary(sparklyr)
sc <- spark_connect(method = "databricks")
# Query a table named "diamonds" and display the first two rows.
df <- spark_read_table(sc = sc, name = "diamonds")
print(x = df, n = 2)
Começar: RStudio Bancada de trabalho
Esta seção mostra como configurar e começar a usar o RStudio Workbench (anteriormente RStudio Server Pro) em um cluster Databricks. Dependendo de sua licença, o RStudio Workbench pode incluir o RStudio Server Pro.
Configurar o servidor de licenças do RStudio
Para usar o RStudio Workbench no Databricks, você precisa converter sua licença Pro em uma licença flutuante. Para obter ajuda, entre em contato com help@rstudio.com. Após a conversão da sua licença, você deverá configurar um servidor de licenças para o RStudio Workbench.
Para configurar um servidor de licenças:
- Inicie uma pequena instância na rede do seu provedor de nuvem; o daemon do servidor de licenças é muito leve.
- Faça o download e instale a versão correspondente do RStudio License Server em sua instância e inicie o serviço. Para obter instruções detalhadas, consulte o guiaRStudio Workbench Admin.
- Certifique-se de que a porta do servidor de licenças esteja aberta para as instâncias do Databricks.
Instalar o RStudio Workbench
Para configurar o RStudio Workbench em um cluster Databricks, o senhor deve criar um init script para instalar o pacote binário do RStudio Workbench e configurá-lo para usar o servidor de licenças para a concessão de licenças.
Se o senhor planeja instalar o RStudio Workbench em uma versão do Databricks Runtime que já inclua o pacote RStudio Server código aberto Edition, será necessário primeiro desinstalar esse pacote para que a instalação seja bem-sucedida.
A seguir, um exemplo de arquivo .sh que o senhor pode armazenar como init script em um local como o seu diretório pessoal como um arquivo workspace, em um volume Unity Catalog ou no armazenamento de objetos. Para obter mais informações, consulte Script de inicialização com escopo de cluster. O script também executa configurações adicionais de autenticação que simplificam a integração com o Databricks.
em DBFS estão no fim da vida útil. O armazenamento do script de inicialização em DBFS existe em alguns espaços de trabalho para dar suporte a cargas de trabalho legadas e não é recomendado. Todos os scripts de inicialização armazenados em DBFS devem ser migrados. Para obter instruções de migração, consulte Migrar script de inicialização de DBFS.
#!/bin/bash
set -euxo pipefail
if [[ $DB_IS_DRIVER = "TRUE" ]]; then
sudo apt-get update
sudo dpkg --purge rstudio-server # in case open source version is installed.
sudo apt-get install -y gdebi-core alien
## Installing RStudio Workbench
cd /tmp
# You can find new releases at https://rstudio.com/products/rstudio/download-commercial/debian-ubuntu/.
wget https://download2.rstudio.org/server/bionic/amd64/rstudio-workbench-2022.02.1-461.pro1-amd64.deb -O rstudio-workbench.deb
sudo gdebi -n rstudio-workbench.deb
## Configuring authentication
sudo echo 'auth-proxy=1' >> /etc/rstudio/rserver.conf
sudo echo 'auth-proxy-user-header-rewrite=^(.*)$ $1' >> /etc/rstudio/rserver.conf
sudo echo 'auth-proxy-sign-in-url=<domain>/login.html' >> /etc/rstudio/rserver.conf
sudo echo 'admin-enabled=1' >> /etc/rstudio/rserver.conf
sudo echo 'export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin' >> /etc/rstudio/rsession-profile
# Enabling floating license
sudo echo 'server-license-type=remote' >> /etc/rstudio/rserver.conf
# Session configurations
sudo echo 'session-rprofile-on-resume-default=1' >> /etc/rstudio/rsession.conf
sudo echo 'allow-terminal-websockets=0' >> /etc/rstudio/rsession.conf
sudo rstudio-server license-manager license-server <license-server-url>
sudo rstudio-server restart || true
fi
- Substitua
<domain>pelo URL do Databricks e<license-server-url>pelo URL do servidor de licença flutuante. - Armazene esse arquivo
.shcomo um init script em um local como, por exemplo, em seu diretório pessoal como um arquivo workspace, em um volume Unity Catalog ou no armazenamento de objetos. Para obter mais informações, consulte Script de inicialização com escopo de cluster. - Antes de iniciar um clustering, adicione esse arquivo
.shcomo um init script a partir do local associado. Para obter instruções, consulte Script de inicialização com escopo de cluster. - Inicie o clustering.
Use o RStudio Server Pro
-
Abra a página de detalhes do clustering.
-
Comece o clustering e clique em Apps tab:
-
Em Apps tab, clique no botão Set up RStudio (Configurar ).
-
Você não precisa da senha de uso único. Clique no link Open RStudio UI e ele abrirá uma sessão autenticada do RStudio Pro para o senhor.
-
Na interface do usuário RStudio, o senhor pode anexar o pacote
SparkRe configurar uma sessãoSparkRpara iniciar o Spark Job em seu cluster.Rlibrary(SparkR)
sparkR.session()
# Query the first two rows of a table named "diamonds" in a
# schema (database) named "default" and display the query result.
df <- SparkR::sql("SELECT * FROM default.diamonds LIMIT 2")
showDF(df)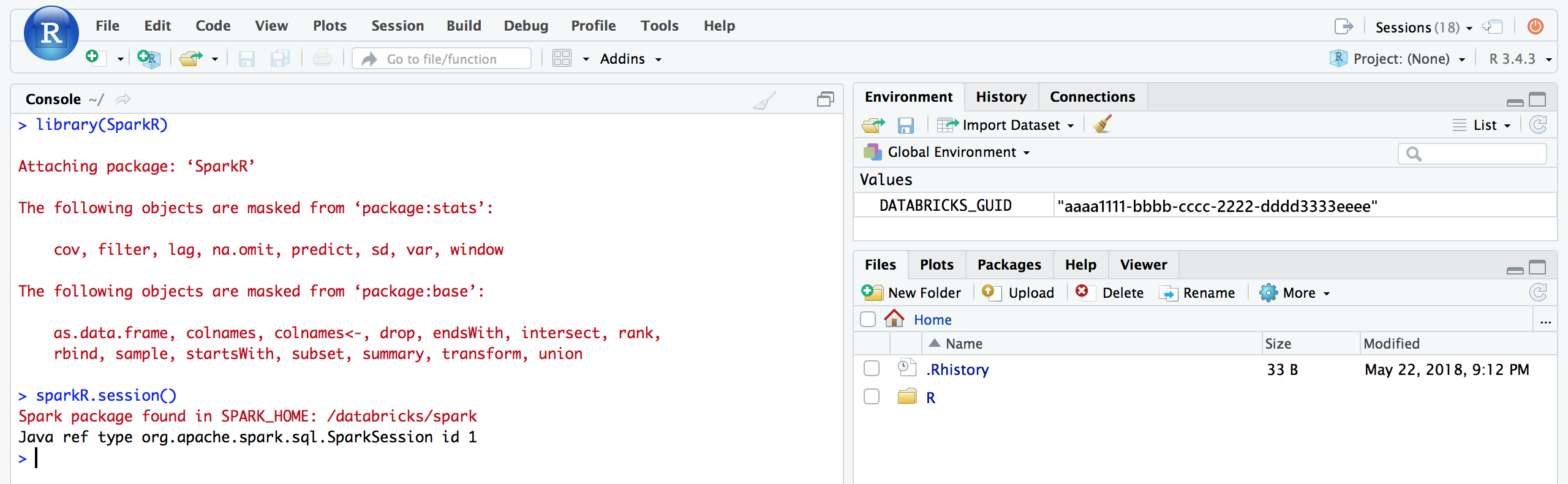
-
O senhor também pode anexar o Sparklyr pacote e configurar uma conexão Spark.
Rlibrary(sparklyr)
sc <- spark_connect(method = "databricks")
# Query a table named "diamonds" and display the first two rows.
df <- spark_read_table(sc = sc, name = "diamonds")
print(x = df, n = 2)
Perguntas frequentes sobre o RStudio Server
Qual é a diferença entre o RStudio Server código aberto Edition e o RStudio Workbench?
RStudio O Workbench oferece suporte a uma ampla gama de recursos empresariais que não estão disponíveis na código aberto Edition. O senhor pode ver a comparação de recursos no siteRStudio.
Além disso, o RStudio Server código aberto Edition é distribuído sob a GNU Affero General Public License (AGPL), enquanto a versão Pro vem com uma licença comercial para organizações que não podem usar a AGPL software.
Por fim, o RStudio Workbench vem com suporte profissional e empresarial da RStudio, PBC, enquanto o RStudio Server código aberto Edition não vem com suporte.
Posso usar minha licença do RStudio Workbench / RStudio Server Pro na Databricks?
Sim, se o senhor já tiver uma licença Pro ou Enterprise do RStudio Server, poderá usar essa licença no Databricks. Consulte Get começar: RStudio Workbench para saber como configurar o RStudio Workbench em Databricks.
Onde o site RStudio Server executa? Preciso gerenciar algum serviço/servidor adicional?
Como o senhor pode ver no diagrama da arquitetura de integração doRStudio, o daemon do servidor RStudio é executado no nó do driver (mestre) do cluster Databricks. Com o RStudio Server código aberto Edition, o senhor não precisa executar nenhum servidor/serviço adicional. Entretanto, para o RStudio Workbench, o senhor deve gerenciar uma instância separada que execute o RStudio License Server.
Posso usar o RStudio Server em um clustering padrão?
Este artigo descreve a interface de usuário de clustering herdada. Para obter informações sobre a nova UI de clustering (em visualização), incluindo alterações de terminologia para modos de acesso de clustering, consulte a referência de configuração de computação. Para obter uma comparação dos tipos de clustering novos e antigos, consulte alterações na interface do usuário do clustering e modos de acesso ao clustering.
Sim, você pode.
Posso usar o servidor RStudio em um clustering com terminação automática?
Não, o senhor não pode usar o RStudio quando a terminação automática está ativada. O encerramento automático pode limpar scripts e dados de usuário não salvos em uma sessão do RStudio. Para proteger os usuários contra esse cenário de perda de dados não intencional, o RStudio é desativado nesse clustering pelo default.
Para os clientes que precisam limpar o recurso de clustering quando ele não é usado, o site Databricks recomenda o uso do recurso de clustering APIs para limpar o recurso de clustering RStudio com base em um programa.
Como devo manter meu trabalho no RStudio?
É altamente recomendável que o senhor mantenha seu trabalho usando um sistema de controle de versão do RStudio. RStudio tem excelente suporte para vários sistemas de controle de versão e permite que o usuário faça check-in e gerencie seus projetos. Se o código não for mantido por meio de um dos métodos a seguir, o usuário corre o risco de perder o trabalho se um administrador do workspace reiniciar ou encerrar o clustering.
Um dos métodos é salvar seus arquivos (código ou dados) no servidor de arquivos DBFS. Por exemplo, se o senhor salvar um arquivo em /dbfs/, os arquivos não serão excluídos quando o clustering for encerrado ou reiniciado.
Outro método é salvar o R Notebook no sistema de arquivos local, exportando-o como Rmarkdown e, posteriormente, importando o arquivo para a instância RStudio. Os blogs que compartilham o R Notebook usando rmarkdown descrevem as etapas em mais detalhes.
Outro método é montar um volume do Amazon Elastic File System (Amazon EFS) em seu clustering, para que, quando o clustering for desligado, o senhor não perca seu trabalho. Quando o clustering for reiniciado, o site Databricks remontará o volume Amazon EFS e o senhor poderá continuar de onde parou. Para montar um volume EFS existente Amazon em um cluster, chame as operações create clustering (POST /api/2.0/clusters/create) ou edit clustering (POST /api/2.0/clusters/edit) no cluster API 2.0, especificando as informações de montagem do volume EFS Amazon na matriz cluster_mount_infos das operações.
Certifique-se de que o clustering que o senhor cria ou usa não tenha Unity Catalog, terminação automática ou escalonamento automático ativados. Certifique-se também de que o clustering tenha acesso de gravação ao volume montado, por exemplo, executando o comando chmod a+w </path/to/volume> no clustering. O senhor pode executar esse comando em um cluster existente por meio do terminal da Web do cluster ou em um novo cluster usando um que o init script senhor especifica na init_scripts matriz das operações anteriores.
Se o senhor não tiver um volume Amazon EFS existente, poderá criar um. Primeiro, entre em contato com o administrador do Databricks e obtenha o ID do VPC, o ID da sub-rede pública e o ID do grupo de segurança do seu Databricks workspace. Em seguida, use essas informações, juntamente com o AWS Management Console, para criar um sistema de arquivos com configurações personalizadas usando o console Amazon EFS. Na última etapa desse procedimento, clique em Anexar e copie o nome DNS e as opções de montagem, que você especifica na matriz cluster_mount_infos anterior.
Como faço para começar uma sessão do SparkR?
SparkR está contido no Databricks Runtime, mas o senhor deve carregá-lo no RStudio. Execute o seguinte código em RStudio para inicializar uma sessão SparkR.
library(SparkR)
sparkR.session()
Se houver um erro ao importar o pacote SparkR, execute .libPaths() e verifique se /home/ubuntu/databricks/spark/R/lib está incluído no resultado.
Se não estiver incluído, verifique o conteúdo de /usr/lib/R/etc/Rprofile.site. Liste /home/ubuntu/databricks/spark/R/lib/SparkR no driver para verificar se o pacote SparkR está instalado.
Como faço para começar uma sessão do sparklyr?
O pacote sparklyr deve ser instalado no clustering. Use um dos métodos a seguir para instalar o pacote sparklyr:
- Como uma biblioteca da Databricks
install.packages()Comando- RStudio UI de gerenciamento de pacotes
library(sparklyr)
sc <- spark_connect(method = “databricks”)
Como o site RStudio se integra ao Databricks R Notebook?
O senhor pode mover seu trabalho entre o Notebook e o site RStudio por meio do controle de versão.
O que é o diretório de trabalho?
Ao iniciar um projeto em RStudio, o senhor escolhe um diretório de trabalho. Em default, esse é o diretório inicial no contêiner do driver (mestre) em que o servidor RStudio está em execução. Você pode alterar esse diretório se quiser.
Posso iniciar aplicativos Shiny a partir do RStudio em execução no Databricks?
Sim, o senhor pode desenvolver e view aplicativos Shiny dentro do servidor RStudio em Databricks.
Não consigo usar o terminal ou o git dentro do RStudio no Databricks. Como posso corrigir isso?
Verifique se você desativou os websockets. No RStudio Server código aberto Edition, o senhor pode fazer isso na interface do usuário.
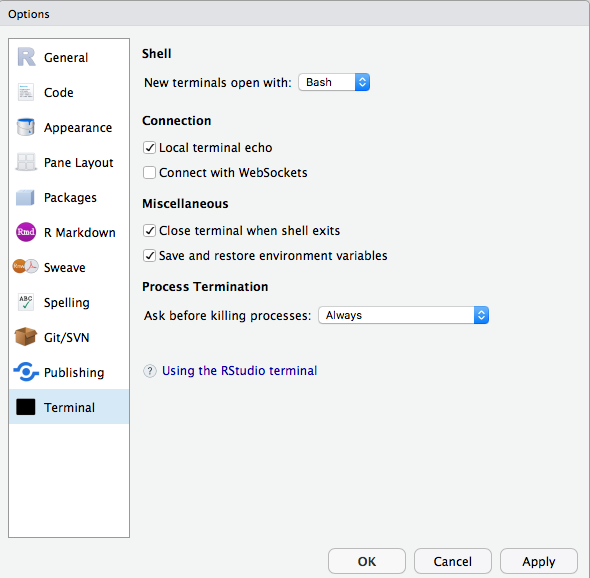
No RStudio Server Pro, é possível adicionar allow-terminal-websockets=0 a /etc/rstudio/rsession.conf para desativar os websockets para todos os usuários.
Não vejo os Apps tab em detalhes de clustering.
Este recurso não está disponível para todos os clientes. Você deve estar no plano Premium ouacima.